







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
在最坏情况下,每趟都要比较 ‘满’,那么从第二个开始,就要依次比较 1 2 3 4 … n ,累加得:量级为 N^2。但在最好情况下(有序),这个人排序只需要遍历一次就可以完成排序了,量级为 N,所以在这个序列接近有序的时候,直接插入排序的效率可以接近O(N)
插入排序没有开额外的空间。并且从后往前按顺序排,遇到等于的就停下,所以这个排序很稳定。
时间复杂度:O(N^2)
空间复杂度:O(1)
稳定性:不稳定
希尔排序
插入排序是一个非常好的排序,特别是在序列接近有序的情况下,效率甚至可以达到接近 O(N),那么如何能设计一个算法先对数据先进行预排序,使序列在整体进行插入排序之前能够达到一个接近有序的状态呢?
希尔排序
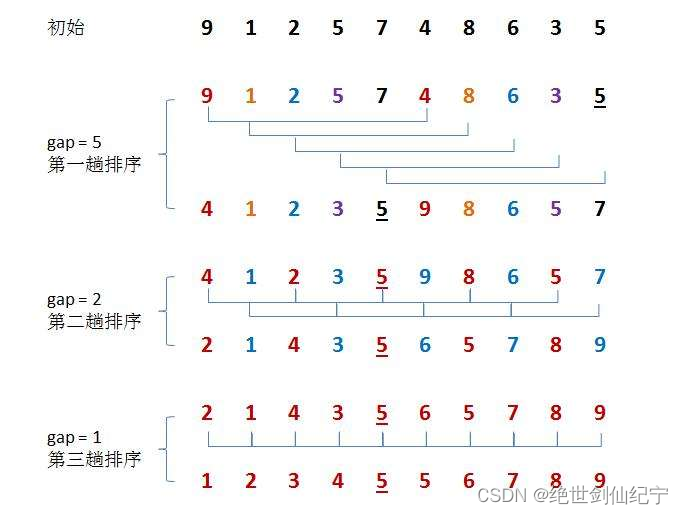
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数,把待排序文件中所有记录分成个组,所有距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重复上述分组和排序的工作。当到达=1时,所有记录在统一组内排好序。
具体步骤就是将这个数据分为多组,每组成员之间间隔 gap个数据,每组进行插入排序,这样可以使小的数尽量在前面,大的数尽量在后面;然后使 gap按规模递减,重复上面的步骤,最后当gap等于1的时候,就是直接插入排序,并且此时的序列已经是非常接近有序的状态了。
代码实现
第一种,分组,对每一组进行分别排序。
void ShellSort(int\* a, int n)//希尔排序
{
int gap = n / 3;
while (gap >= 1)
{
for (int z = 0; z < gap; z++)//gap组数据
{
for (int i = z; i < n - gap; i += gap)//对一组进行直接插入排序
{
int end = i;
int tmp = a[end + gap];
for (int j = end; j < n-gap; j += gap)
{
while (end>=0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
}
else
{
break;
}
end -= gap;
}
a[end + gap] = tmp;
}
}
}
gap /= 2;//调整gap的值
}
}
特点:思路较为简单,但循环较多,代码较复杂。
第二种,分组,但整体顺序是从头开始依次往下,插入排序的时候每次跳过 gap 个数据。
void ShellSort(int\* a, int n)//希尔排序
{
int gap = n / 3;
while (gap >= 1)
{
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
for (int j = end; j < n-gap; j += gap)
{
while (end>=0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
}
else
{
break;
}
end -= gap;
}
a[end + gap] = tmp;
}
}
gap /= 2;
}
}
初学者不好思考,但是理解之后代码更简单好控制,不易出错。
复杂度分析
时间复杂度:O(N^1.3) 接近于O(N*logN)
空间复杂度:O(1)
稳定性:不稳定
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









