






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
swap存在的问题 :
- 碎片问题:进程来回分配、回收交换,内存之间会产生很多缝隙。经过反反复复使用,内存的情况会变得十分复杂,导致整体性能下降。
- 频繁切换问题:如果进程过多,内存较小,会频繁触发交换。
- swap需要明确应用需要多少内存。

虚拟内存
- 虚拟化技术中,操作系统设计了虚拟内存(理论上可以无限大的空间),受限于
CPU的处理能力,通常64bit CPU,就是264个地址。
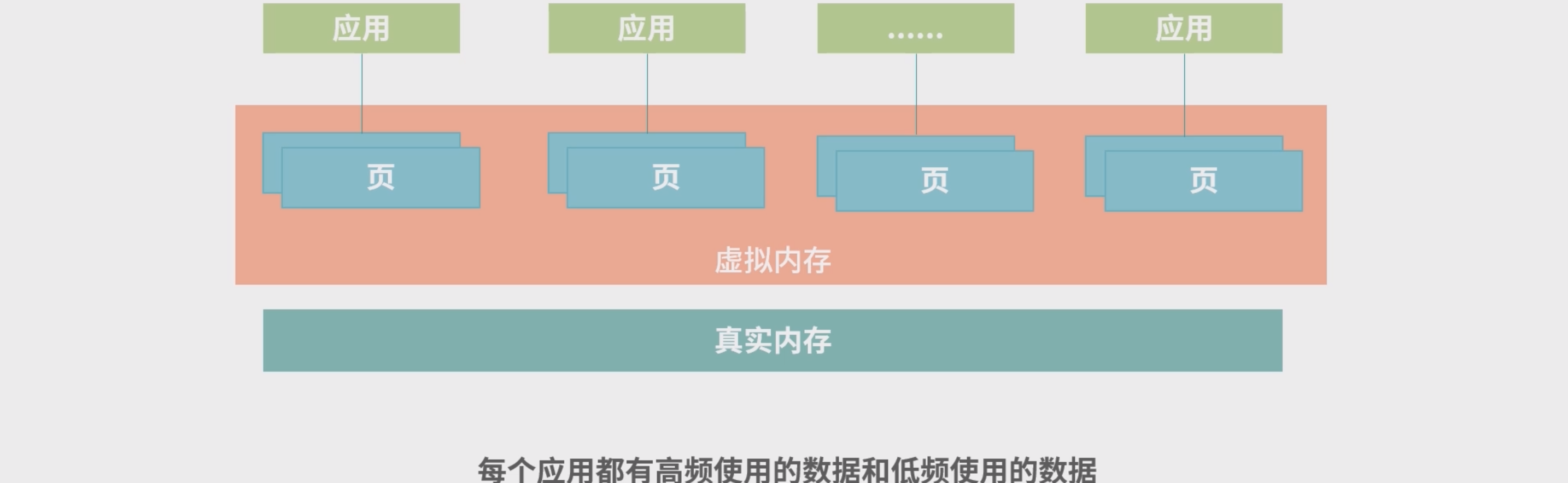
- 虚拟化技术中,应用使用的是虚拟内存,操作系统管理虚拟内存和真实内存之间的映射。操作系统将虚拟内存分成整齐小块,每个小块称为一个页(Page)
- 作用: 可以避免面内存碎片的问题。 低频使用的页存放在硬盘上,高配使用的页存放在内存上。
- 如果一个应用需要非常大的内存,应用申请的是虚拟内存中的很多个页,真实内存不一定需要够用。
页(Page)和页表
- 操作系统将虚拟内存分块,每个小块称为一个页(
Page);真实内存也需要分块,每个小块我们称为一个Frame。Page到Frame的映射,需要一种叫作页表的结构。
**Page、Frame 和页表 (PageTable)三者之间的关系:**比如虚拟内存大小为 10G, Page 大小是 4K,那么需要 10G/4K = 2621440 个条目。如果每个条目是 64bit,那么一共需要 20480K = 20M 页表。操作系统在内存中划分出小块区域给页表,并负责维护页表。
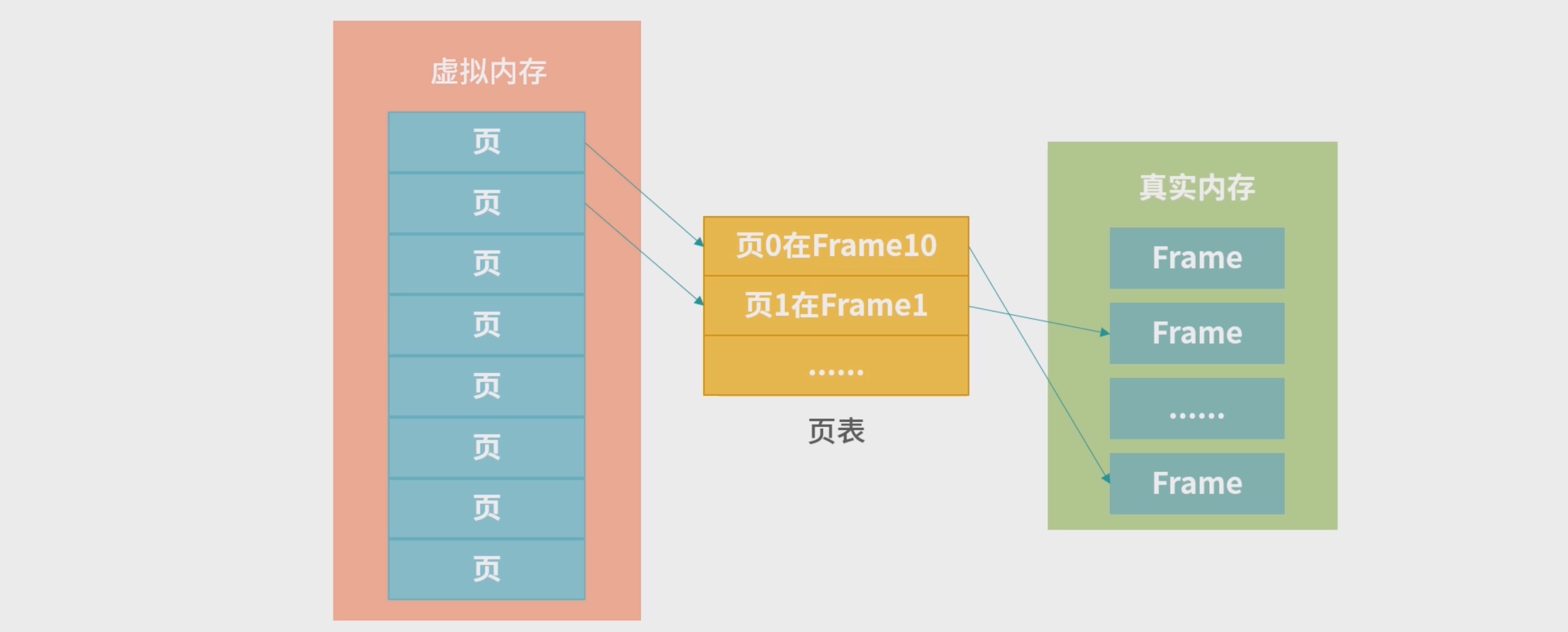
- Page 大小和 Frame 大小通常相等,页表中记录的某个 Page 对应的 Frame 编号。页表也需要存储空间,操作系统在内存中划分出小块区域给页表,并负责维护页表。
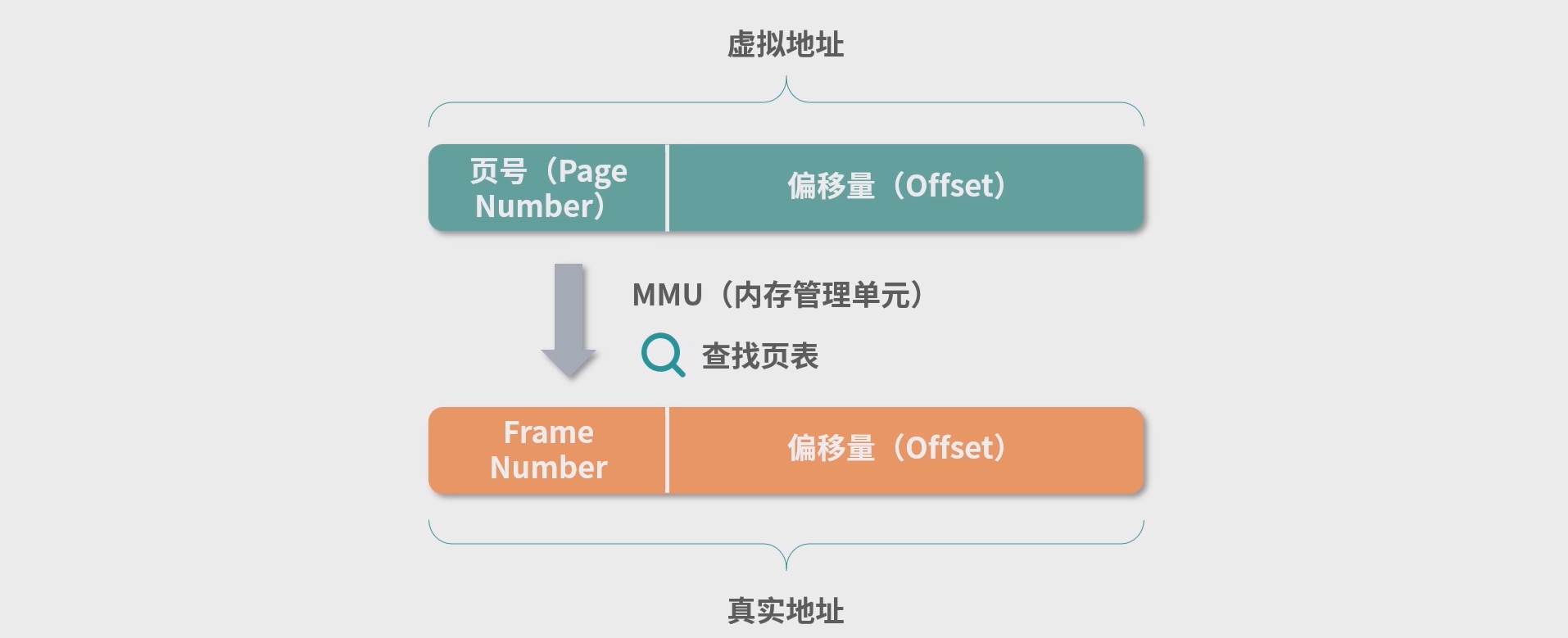
- 虚拟地址到真实地址的映射转换过程:1. 通过虚拟地址计算 Page 编号; 2. 查页表,根据 Page 编号,找到 Frame 编号; 3. 将虚拟地址换算成物理地址。
比如:

Memory Management Unit, MMU
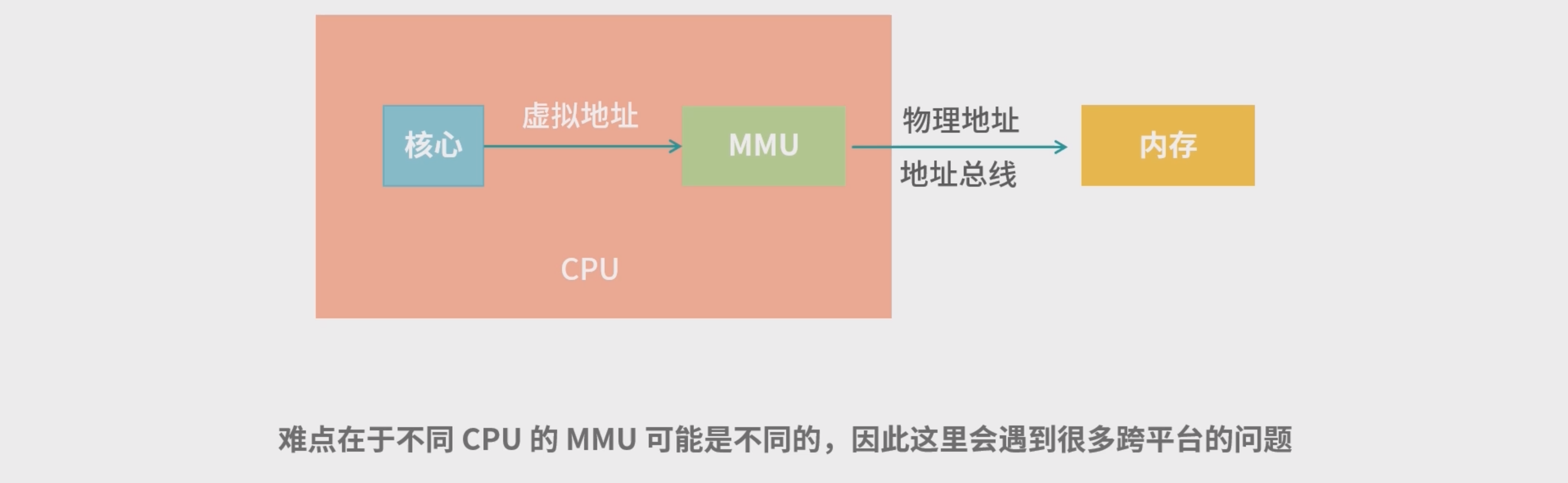
上面的过程发生在 CPU 中一个小型的设备——内存管理单元(Memory Management Unit, MMU) 中。如下图所示:
- 当 CPU 需要执行一条指令时,如果指令中涉及内存读写操作,CPU 会把虚拟地址给 MMU,MMU 自动 完成虚拟地址到真实地址的计算;然后,MMU 连接了地址总线,帮助 CPU 操作真实地址
页表条目
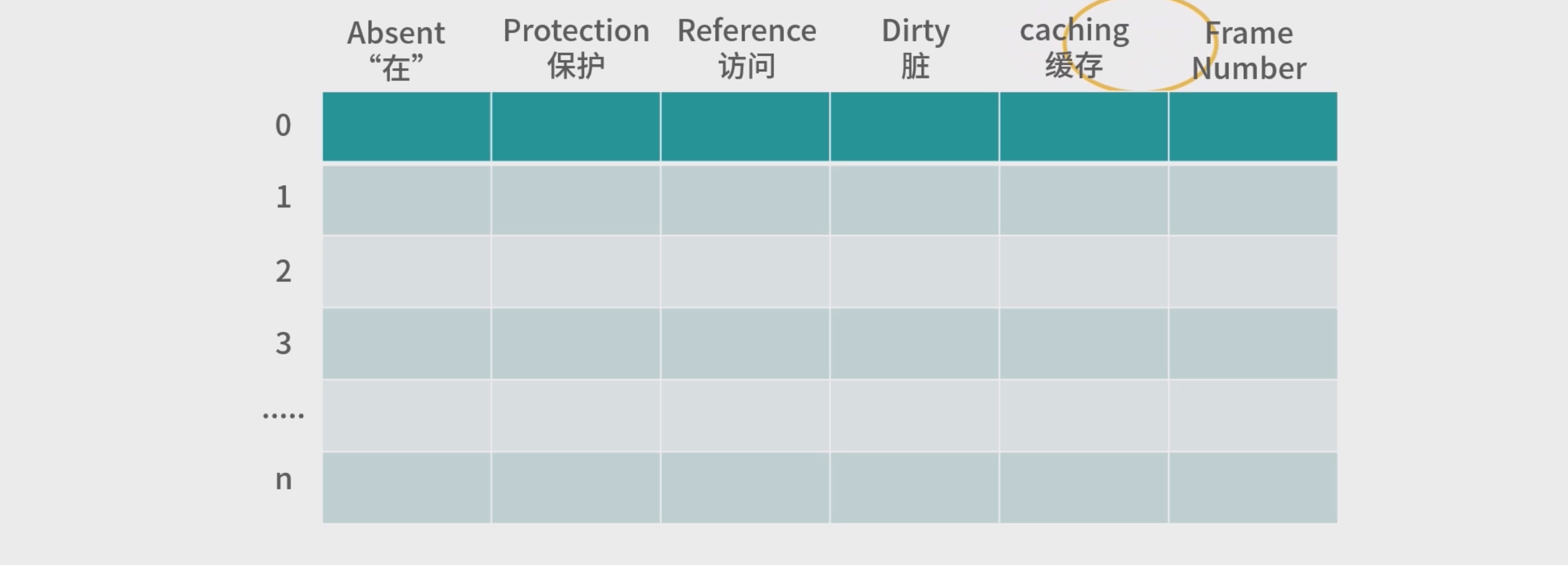
- Absent(“在”)位,是一个 bit。0 表示页的数据在磁盘中(不再内存中),1 表示在内存中。如果 读取页表发现 Absent = 0,那么会触发缺页中断,去磁盘读取数据。
- Protection(保护)字段可以实现成 3 个 bit,它决定页表用于读、写、执行。比如 000 代表什么 都不能做,100 代表只读等。
- Reference(访问)位,代表这个页被读写过,这个记录对回收内存有帮助。
- Dirty(“脏”)位,代表页的内容被修改过,如果 Dirty =1,那么意味着页面必须回写到磁盘上才能 置换(Swap)。如果 Dirty = 0,如果需要回收这个页,可以考虑直接丢弃它(什么也不做,其他程 序可以直接覆盖)。
- Caching(缓存位),描述页可不可以被 CPU 缓存。CPU 缓存会造成内存不一致问题,在上个模 块的加餐中我们讨论了内存一致性问题。
- Frame Number(Frame 编号),这个是真实内存的位置。用 Frame 编号乘以页大小,就可以得 到 Frame 的基地址。
大页面问题
- 应用分为3个区域(3个段) : 正文段(程序)、数据段(常量、变量)、堆栈段(随着程序的执行而增加、上不封顶)。
- 为了减少条目的创建,进程内部可以使用一个更大的页表(形成二级页表)

MMU 会先查询 1 级页表,再查询 2 级页表。在这个模型下,进程如果需要 1G 空间,也只需要 1024 个条目。比如 1 级页编号是 2, 那么对应 2 级页表中 [2* 1024, 3*1024-1] 的部分条目。而访问一 个地址,需要同时给出一级页编号和二级页编号。

- 多页面对空间的利用会提高,但是也会带来一定的开销,但这对大应用来说是非常划算的,从 256K 个条目到 3 个,这就大大减少了进程创建的成本。
内存管理单元
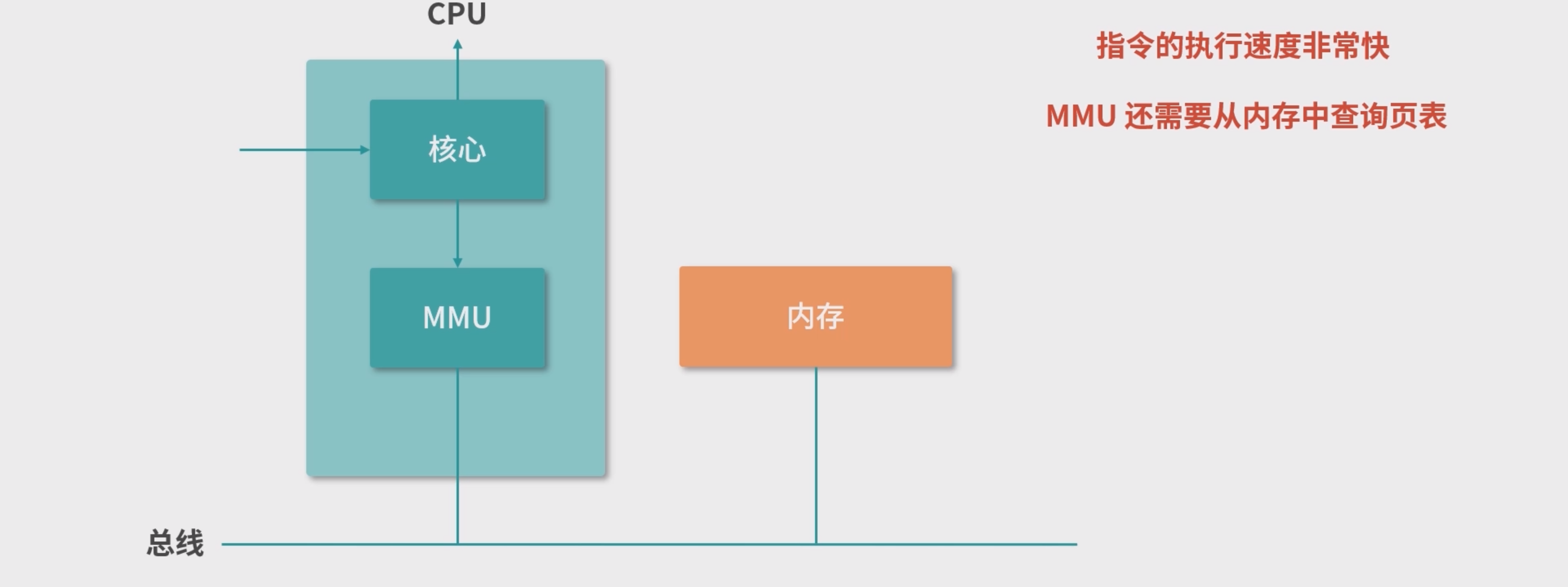
TLB 和 MMU 的性能问题
CPU指令周期:
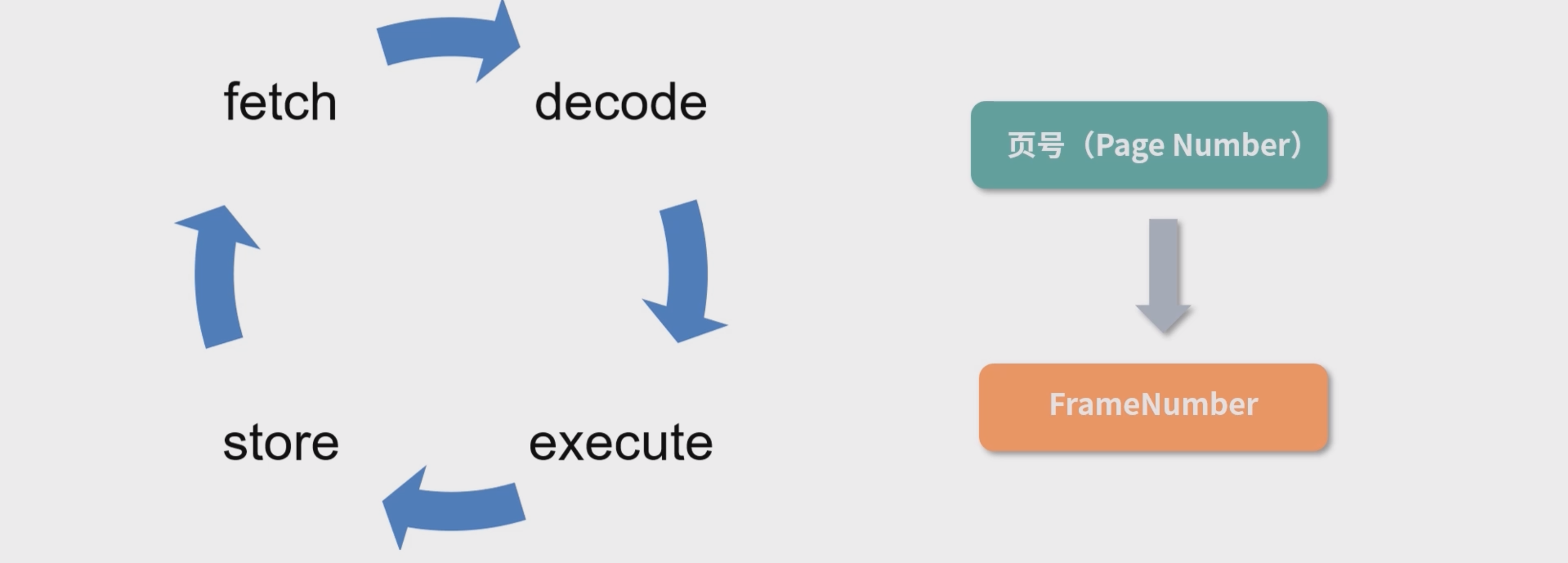
- 在
fetch、execute 和 store这 3 个环节中都有可能发生内存操作,因此内存操作最好能在非常短的时间内完成,尤其是Page Number 到 Frame Number 的映射,我们希望尽快可以完成,最好不到 0.2 个 CPU 周期,这样就不会因为地址换算而增加指令的 CPU 周期。
+在 MMU 中往往还有一个微型的设备,叫作**转置检测缓冲区(Translation Lookaside Buffer, TLB)**其作用是根据输入的Page Number,找到对应的Frame Number。 - 每一行是一个 Page Number 和一个 Frame Number。 我们把这样的每一行称为一个缓存行(Cache Line),或者缓存条目(Entry)。
- TLB是硬件实现的,因此速度很快

TLB Miss 问题
- TLB 失效(Miss)
- 软失效(Soft Miss),这种情况 Frame 还在内存中,只不过 TLB 缓存中没有。那么这个时候需 要刷新 TLB 缓存。如果 TLB 缓存已经满了,就需要选择一个已经存在的缓存条目进行覆盖。具体选择哪 个条目进行覆盖,我们称为缓存置换(缓存不够用了,需要置换)。缓存置换时,通常希望高频使用的数据保留,低频使用的数据被替换。比如常用的 **LRU(Least Recently Used)**算法就是基于这种考虑, 每次置换最早使用的条目。
- 硬失效(Hard Miss),这种情况下对应的 Frame 没有在内存中,需要从磁盘加载。这种 情况非常麻烦,首先操作系统要触发一个缺页中断(原有需要读取内存的线程被休眠),然后中断响应 程序开始从磁盘读取对应的 Frame 到内存中,读取完成后,再次触发中断通知更新 TLB,并且唤醒被休眠的线程去排队。注意,线程不可能从休眠态不排队就进入执行态,因此 Hard Miss 是相对耗时的。
- TLB Miss 都会带来性能损失.
TLB缓存设计
每个缓存行可以看作一个映射,TLB 的缓存行将 Page Number 映射到 Frame Number,通常我们设计 这种基于缓存行(Cache Line)的缓存有 3 种映射方案:
- 全相联映射(Fully Associative Mapping)
- 直接映射(Direct Mapping)
- n 路组相联映射(n-way Set-Associative Mapping)
- 所谓相联(Associative),讲的是缓存条目和缓存数据之间的映射范围。如果是全相联,那么一个数据,可能在任何条目。如果是组相联(Set-Associative),意味对于一个数据,只能在一部分缓存条目 中出现(比如前 4 个条目)。
方案一:全相联映射(Fully Associative Mapping)
- 因为在给定的空间下,最容易想到的就是把缓存数据都放进一个数组里。
- 对于 TLB 而言,如果是全相联映射,给定一个具体的 Page Number,想要查找 Frame,需要遍历整个 缓存。当然作为硬件实现的缓存,如果缓存条目少的情况下,可以并行查找所有行。这种行为在软件设 计中是不存在的,软件设计通常需要循环遍历才能查找行,但是利用硬件电路可以实现这种并行查找到 过程。可是如果条目过多,比如几百个上千个,硬件查询速度也会下降。所以,全相联映射,有着明显 性能上的缺陷。我们不考虑采用。
方案二:直接映射(Direct Mapping)
- 缓存行号 = Page Number % 64。 与全相联映射区别不大
方案三:n 路组相联映射(n-way Set-Associative Mapping)
- 组相联映射允许一个虚拟页号(Page Number)映射到固定数量的 n 个位置。

大内存分页
当一个应用(进程)对内存的需求比较大的时候,可以考虑采用大内存分页(Large Page 或 Huge Page)
- 例如把大小为
4K的页修改为大小为4M的页 - 命令
sudo sysctl -w vm.nr_hugepages=2048
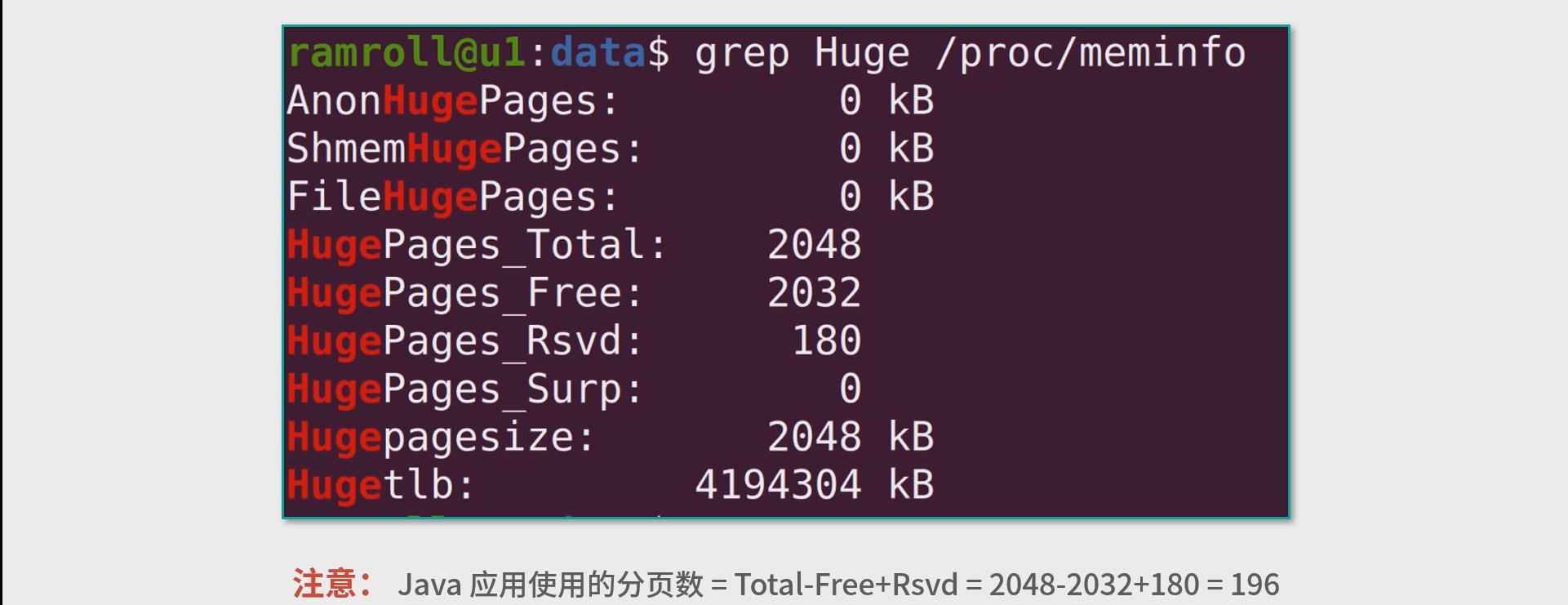
Total 就是总共的分 页数,Free 代表空闲的(包含 Rsvd,Reserved 预留的)
缓存置换算法
理想状态
- 在缓存中找到数据叫作一次命中(Hit),没有找到叫作穿透(Miss)。
- 穿透的概率为 M,缓存的访问时间(通常叫作延迟)是 L,穿透的代价(访问到原始数据,比如 Redis 穿透,访问到 DB)也就是穿透后获取数据的平均时间是 T 。 我们希望把M尽可能的少。

随机/FIFO/FILO
- 随机置换,一个新条目被写入,随机置换出去一个旧条目。这种设计,具有非常朴素的公平,但 是性能会很差(穿透概率高),因为可能置换出去未来非常需要的数据。
- FIFO / FILO 利用天然的数据结构队列 / 栈。
最近未使用(NRU)(Not Recently Used)
- 缓存设计本身也是基于概率的,一种方案有没有价值必须经过实践验证——在内存缺页中断后,如果采用 NRU 置换页面,可以 提高后续使用内存的命中率,这是实践得到的结论。
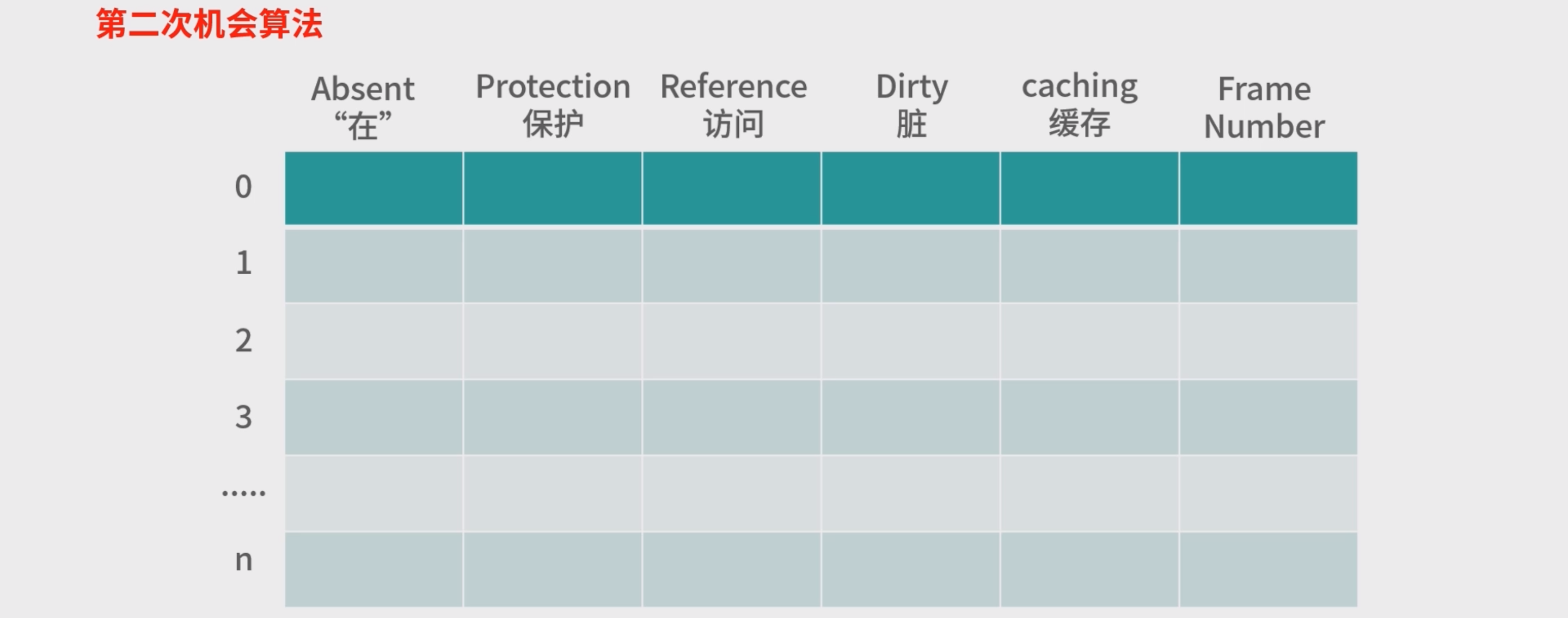
- 在页表中有一个访问位,代表页表有被读取过。
- 脏位,代表页表被写入过。无论是读还是写, 我们都可以认为是访问过。 为了提升效率,一旦页表被使用,可以用硬件将读位置 1,然后再设置一个定时器,比如 100ms 后,再将读位清 0。当有内存写入时,就将写位置 1。过一段时间将有内存写入的 页回写到磁盘时,再将写位清 0。这样读写位在读写后都会置为 1,过段时间,也都会回到 0。
- NRU算法, 每次置换的时候,操作系统尽量选择读、写位都是 0 的页面。而一个页面如果在内存中停留太久,没有新的读写,读写位会回到 0,就可能会被置换。
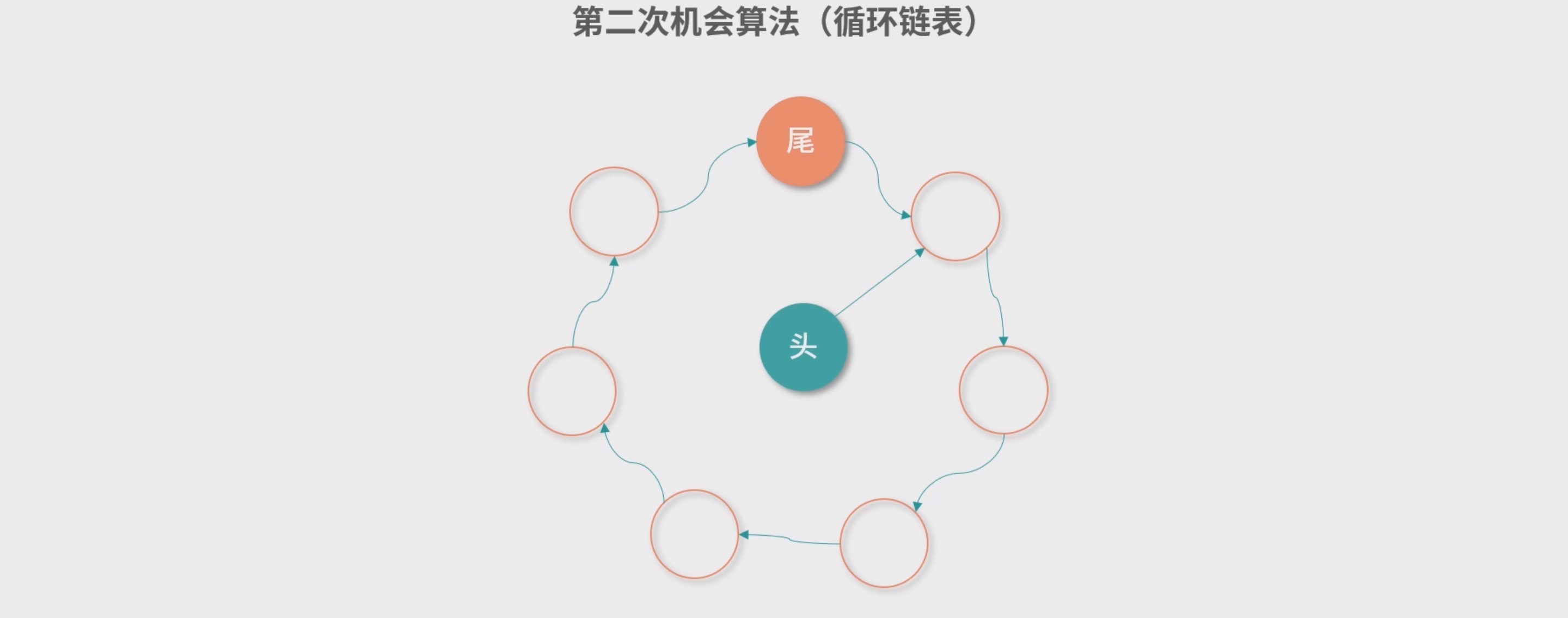
- NRU算法结合 FIFO算法 : 每次 FIFO 从队列尾部找到一个条目要置换出去的时候,就检查一下这个条目的读位。如果读位是 0,就 删除这个条目。如果读位中有 1,就把这个条目从队列尾部移动到队列的头部,并且把读位清 0,相当 于多给这个条目一次机会,因此也被称为第二次机会算法。
- 也可以考虑使用循环链表 , 这个实现可以帮助我们节省元素从链表尾 部移动到头部的开销。
- 优点: 简单有效,性能好 。 缺点 : 没有考虑最近用没用的情况,考虑不周。
最近使用最少 (LRU) Least Recently Used, LRU)算法

- 最近一段时间最少使用到的数据应该被淘汰,把空间让给最近频繁使用的数据。这样 的设计,即便数据都被使用过,还是会根据使用频次多少进行淘汰。
- LRU 的一种常见实现是链表 :
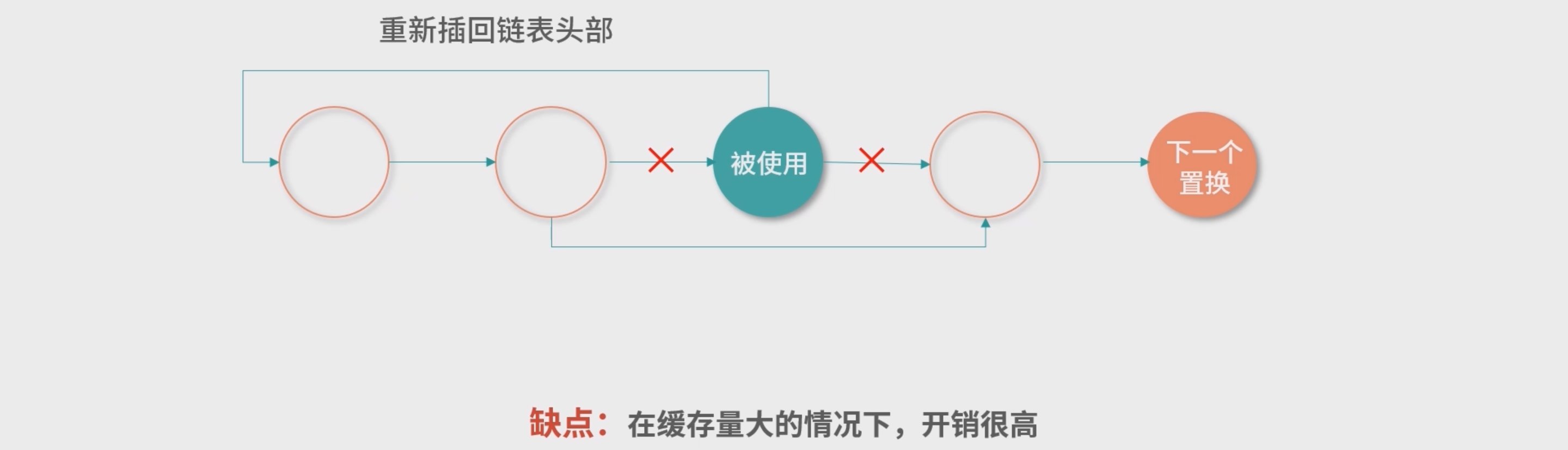
- 双向链表 维护缓存条目 , 如果链表中某个缓存条目被用到,这个条目直接重新移动到表头。 因此需要有哈希表来进行映射达到查询的能力
- 但是这种方案在缓存访问量非常大的情况下,需要同时维护一个链表和一个哈 希表,因此开销较高。
最近使用次数实现
- 次数可以有:最少使 用(Least Frequently Used,,LFU)算法。,其劣势在于不会忘记数据,累计值不会减少。
- “老化”(Aging)的算法 Aging 算法的执行,有访问操作的时候 A 的值上升,没有访问操作的时候,A的值逐渐 减少。如果一直没有访问操作,A 的值会回到 0。

- 然后操作系统每次页面置换的时候,都从 A 值最小的集合中 取出一个页面放入磁盘。这个算法是对 LRU 的一种模拟,也被称作 LFUDA(动态老化最少使用,其中 D 是 Dynamic,,A 是 Aging)。

- 是否采用 LRU,一方面要看你所在场景的性能要求,有没有足够的优化措施(比如硬件提速);另一方面,就要看最终的结果是否能够达到期望的命中率和期望的使用延迟了。
内存回收 (上)
所以我们观察到的系统性能下降,往往是一种突然的崩溃,因为一旦内存被占满,系统性能 就开始雪崩式下降。特别是有时候程序员不懂内存回收的原理,错误地使用内存回收器,导致部分对象没有被回收。而在高并发场景下,每次并发都产生一点不能回收的内存,不用太长时间内存就满了,这就是泄漏通常的成因。
垃圾回收器(Garbage Collector,GC)
- 程序语言提供的 GC 往往是应用的实际内存管理者。

GC 承担的工作:

GC指标 : - **吞吐量(Throughput)😗*执行程序(不包括 GC 执行的时间)和总是间的占比。注意这个吞吐量 和通常意义上应用去处理作业的吞吐量是不一样的,这是从 GC 的角度去看应用。只要不在 GC, 就认为是吞吐量的一部分。
- 足迹(FootPrint): 一个程序使用了多少硬件的资源,也称作程序在硬件上的足迹。GC 里面说 的足迹,通常就是应用对内存的占用情况。比如说应用运行需要 2G 内存,但是好的 GC 算法能够 帮助我们减少 500MB 的内存使用,满足足迹这个指标。
- 暂停时间(Pause Time): GC 执行的时候,通常需要停下应用(避免同步问题),这称为 Stop The World,或者暂停。不同应用对某次内存回收可以暂停的时间需求是不同的,比如说一个游戏 应用,暂停了几毫秒用户都可能有很大意见;而看网页的用户,稍微慢了几毫秒是没有感觉的。
GC目标思考

(简化版)阿姆达定律S = 1 / (1 - P),这个定律用来衡量并行计算 对原有算法的改进 , P 是任务中可以并发执行部分的占比,S 是并行带来的理论 提速倍数的极限。

引用计数算法(Reference Counter)
- GC 不断扫描引用计数为 0 的节点进行回收,就构成了最简单的一个内存回收算法。
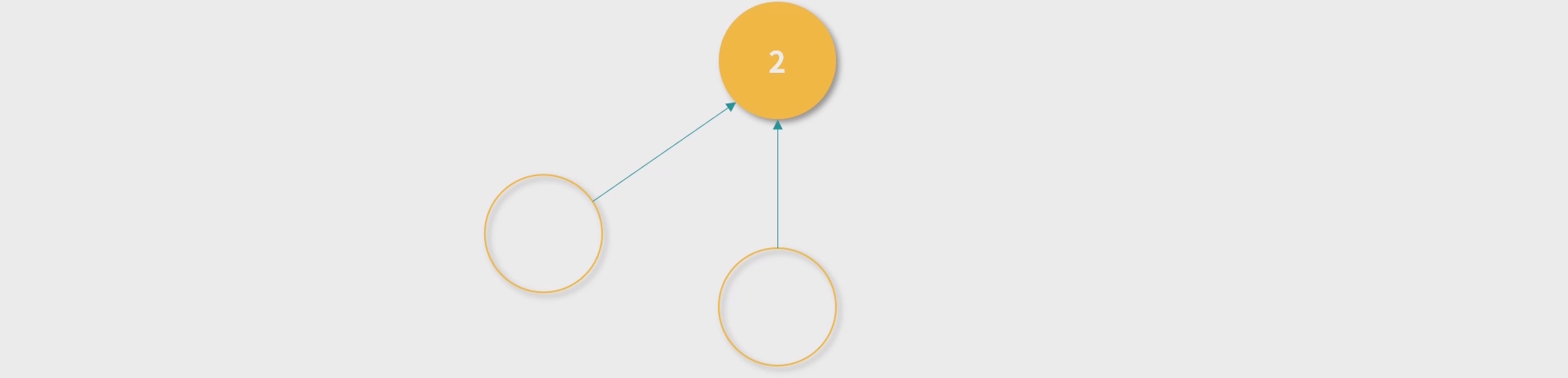
- 循环引用,引用计数都是 1
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
)]
[外链图片转存中…(img-IlJ8jRg6-1715755086316)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 6864
6864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









