







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
竞争条件的版本:
up(&lock){
while(!cas(&lock, lock, lock+1)) { }
}
down(&lock) {
while(!cas(&lock, lock, lock - 1) || lock == 0){}
}
//up和down。up将lock增 1,down将lock减 1。
int lock = 2;
down(&lock);
// 临界区
up(&lock);
//lock等于 1,第 2 个线程还可以进入。
- 当lock初始值为 1 的时候,这个模型就是实现互斥(mutex)。如果 lock 大于 1,那么就是同时允许 多个线程进入临界区。这种方法,我们称为信号量(semaphore)
信号量实现生产者消费者模型
int empty = N; // 当前空位置数量
int mutex = 1; // 锁
int full = 0; // 当前的等待的线程数
wait(){ down(&empty); down(&mutex); insert(); up(&mutex); up(&full);} // 生产者
notify(){ down(&full); down(&mutex); remove(); up(&mutex); up(&empty)}// 消费者
insert(){
wait_queue.add(currentThread);
yield(); //交出当前线程的控制权,当前线程休眠
}
remove(){
thread = wait_queue.dequeue();
thread.resume(); // 恢复
}
死锁问题
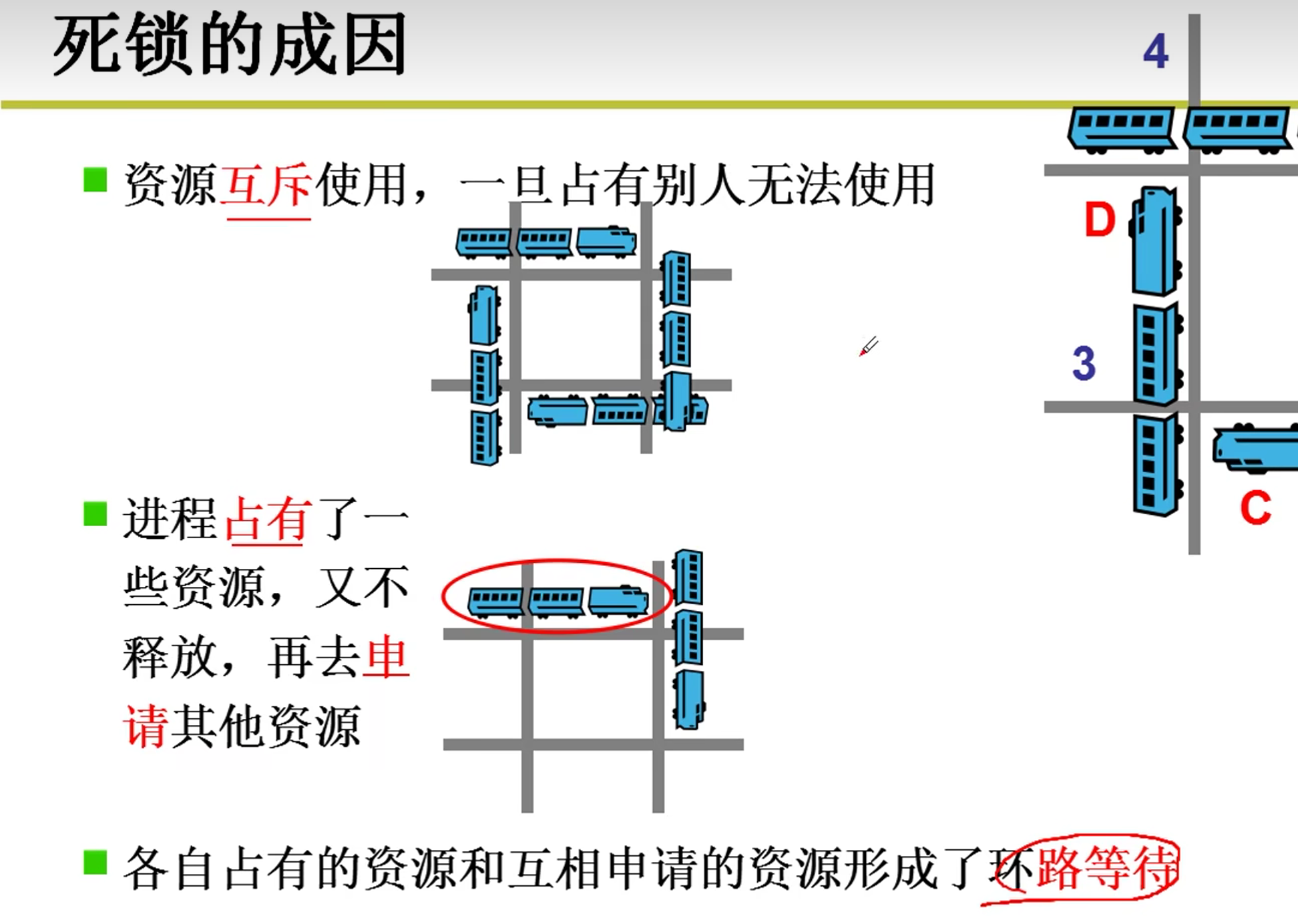
- 两个线程互相等待对方获得的锁,就会发生死锁。可以理解成一个环状的依赖关系。
int lock1 = 0;
int lock2 = 0;
// 线程1
enter(&lock1); enter(&lock2); leave(&lock1); leave(&lock2);
// 线程2
enter(&lock2); enter(&lock1); leave(&lock1); leave(&lock2)
//上面的程序,如果是按照下面这个顺序执行,就会死锁:
线程1: enter(&lock1);
线程2: enter(&lock2);
线程1: enter(&lock2)
线程2: enter(&lock1) // 死锁发生,线程1、2陷入等待
上面程序线程 1 获得了lock1,线程 2 获得了lock2。接下来线程 1 尝试获得lock2,线程 2 尝试获 得lock1,于是两个线程都陷入了等待。这个等待永远都不会结束,我们称之为死锁
分布式环境的锁
- 当用户并发的访问这个接口,是会发生竞争条件的。 因为程序已经不是在同一台 机器上执行了,解决方案就是分布式锁。实现锁,我们需要原子操作。 在分布式的环境下,需要其他工具 提供分布式的原子操作
- 1.从 Redis 读出当前库存; 2. 计算库存 -1; 3. 更新 Redis 库存。
除了上锁还有哪些并发控制方法? ——> 悲观锁和乐观锁
同步的一种方式,就是让临界区互斥。 这种方式,每次只有一个线程可以进入临界区.
+悲观锁: 让临界区互斥的方法(对临界区上锁),具有强烈 的排他性,对修改持保守态度,我们称为悲观锁(Pressimistic Lock) ,通常的上锁就是指悲观锁。MySQL 的表锁、行锁、Java 的锁,本质是互斥 (mutex)。
- 乐观锁: 与悲观锁相反,基于 乐观锁的应用就是版本控制工具 Git,Git 允许大家一起编辑,将结果先存在本地,然后都可以向远程仓 库提交,如果没有版本冲突,就可以提交上去。这就是一种典型的乐观锁的场景,或者称为基于版本控 制的场景。


购物车的类比

去中心化方案:区块链的类比
- DNS系统:使用一个分级缓存的策略。

解决最基本的信用问题

解决货币和库存的问题
- 区块链结构 : 区块链构成了一个基于历史版本的事实链,前一个版本是后一个版本的历史。
- 每个 Block 下面可以存一些数据,每个 Block 知道上一个节点是谁。每 个 Block 有上一个节点的摘要签名。当一个节点被删除 , 那么它会影响对应的节点。区块链一旦写入就不能修改,这样可以防止很多欺诈行为。
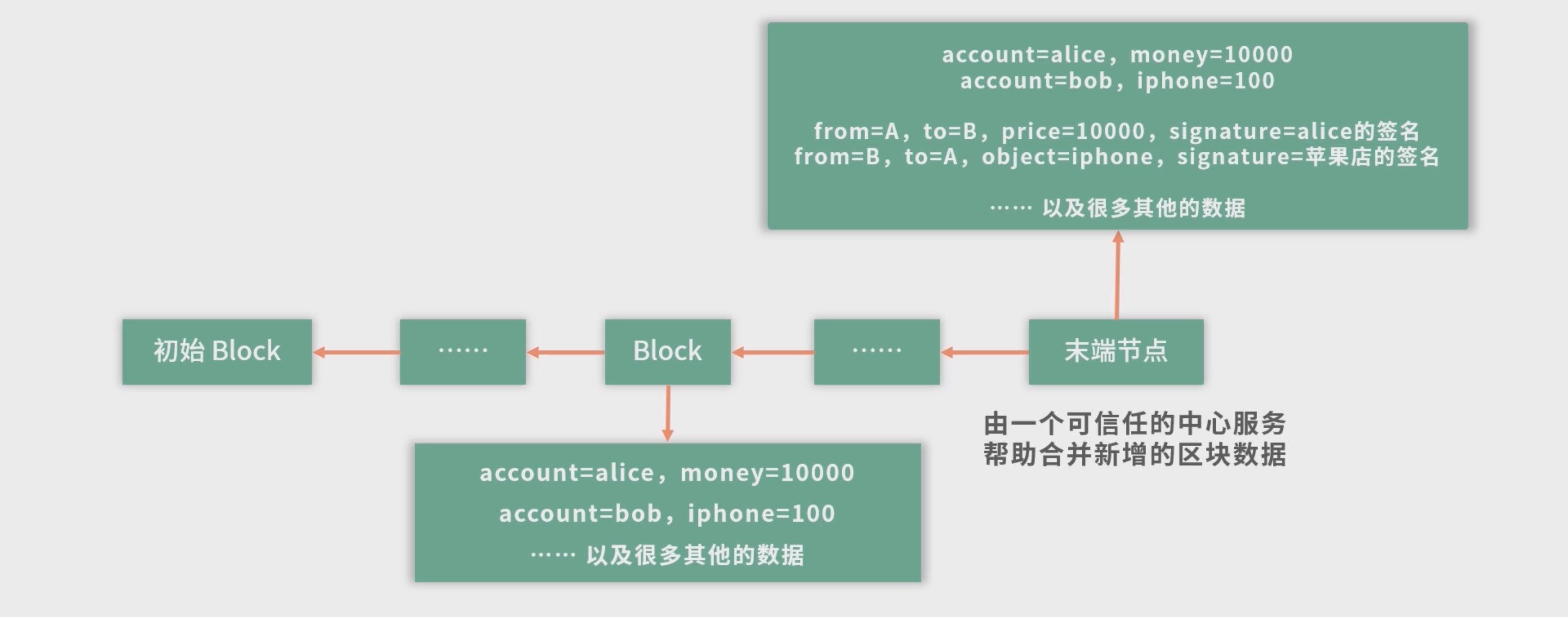
解决并发问题
假设全球有几十亿人都在下单。那么每次下单,需要创建新的一个 Block。这种情况,会导致最后面的 Block,开很多分支。
- 最傻的方案就是用锁解决,比如用一个集中式的办法,去 接收所有的请求,这样就又回到中心化的设计。
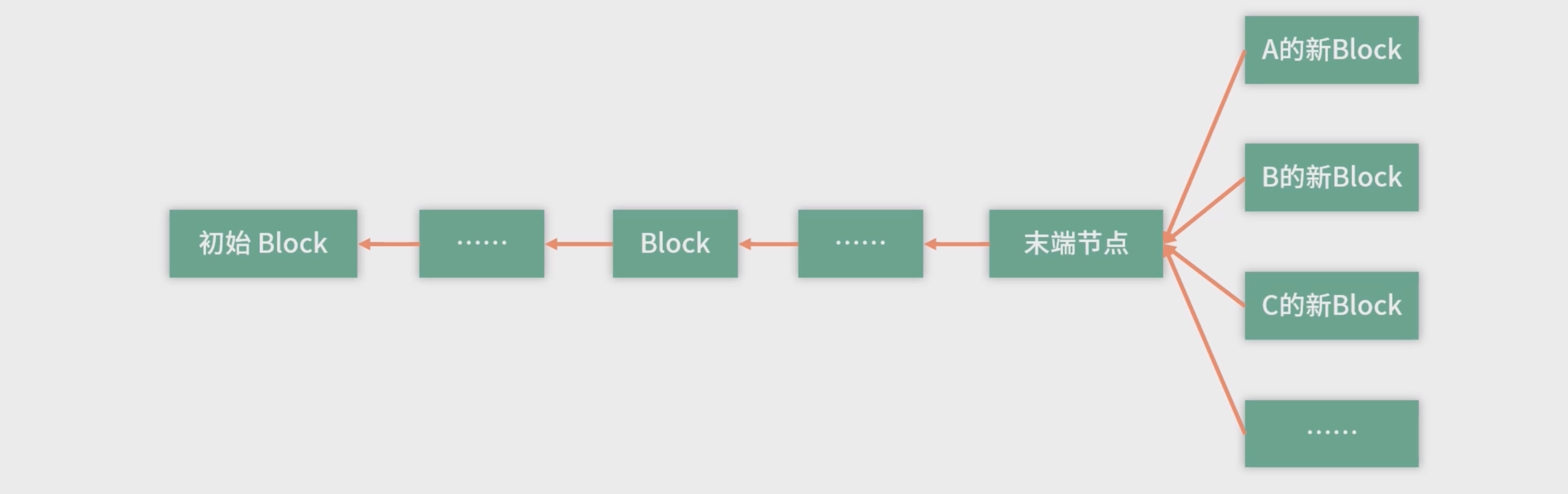
- 高明的办法,就是开一个分支,这个分支只管理它该管理的地方。先维护自己的 Block-Chain,等待合适的时机,再去合并到主分支上;如果合并不进去就废除该分支。

线程的调度
先到先服务 First Come First Service
每处理一个称为一个作业
(Job)。处 理作业最容易想到的就是先到先服务(First Come First Service,FCFS),也就是先到的作业先被计 算,后到的作业,排队进行。用到一个叫作队列的数据结构,具有先入先出(First In First Out,FIFO)性质。先进入队列 的作业,先处理,因此从公平性来说,这个算法非常朴素。另外,一个作业完全完成才会进入下一个作 业,作业之间不会发生切换,从吞吐量上说,是最优的——因为没有额外开销
短作业优先Shortest Job First, SJF
从另外一个角度来审视短作业优先 的优势,就是平均等待时间:平均等待时间 = 总等待时间/任务数
优先级队列(PriorityQueue)
优先级队列的一种实现方法就是用到了堆(Heap)这种数据结构,更最简单的实现方法,就是每次扫描 一遍整个队列找到优先级最高的任务。也就是说,堆(Heap)可以帮助你在 O(1) 的时间复杂度内查找到最大优先级的元素。
例如应急的任务可以赋予一个更高的优先级,普通任务可以在等待时间(W) 和预估执行时间 (P)中,找一个数学关系来描述。优先级 = W/P
抢占
抢占就是把执行能力分时,分成时间片段。 让每个任务都执行一个时间片段。如果在时间片段内,任务完成,那么就调度下一个任务。如果任务没有执行完成,则中断任务,让任务重新排队,调度下一个任务。
抢占结合优先级队列能力,这就构成了一个基本的线程调度模型。线程相对于操作系统是排队到来的,操作系统为每个到来的线程分配一个优先级,然后把它们放入一个优先级队列中,优先级最高的线程下一个执行。
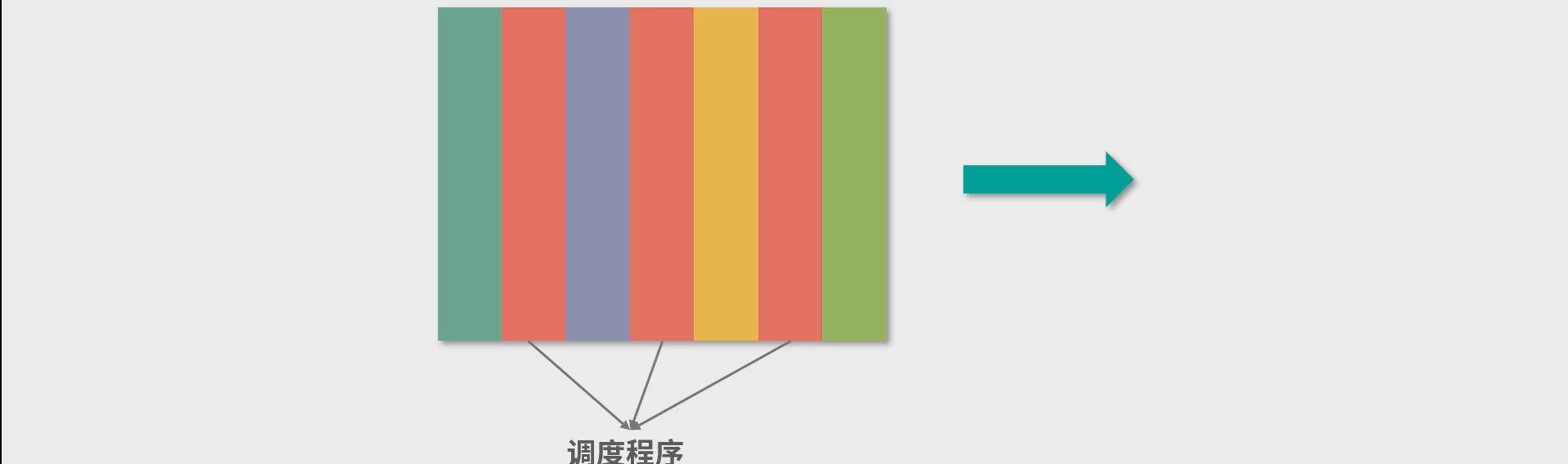
颜色代表被调度线程的时间片段。调度程序可以考虑实现为一个单线程模型,这样不需要考虑竞争条件。
缺点 : 如果一个线程优先级非常高,其实没必要再抢占。无法处理最短优先的抢占。
多级队列模型
多级队列,就是多个队列执行调度
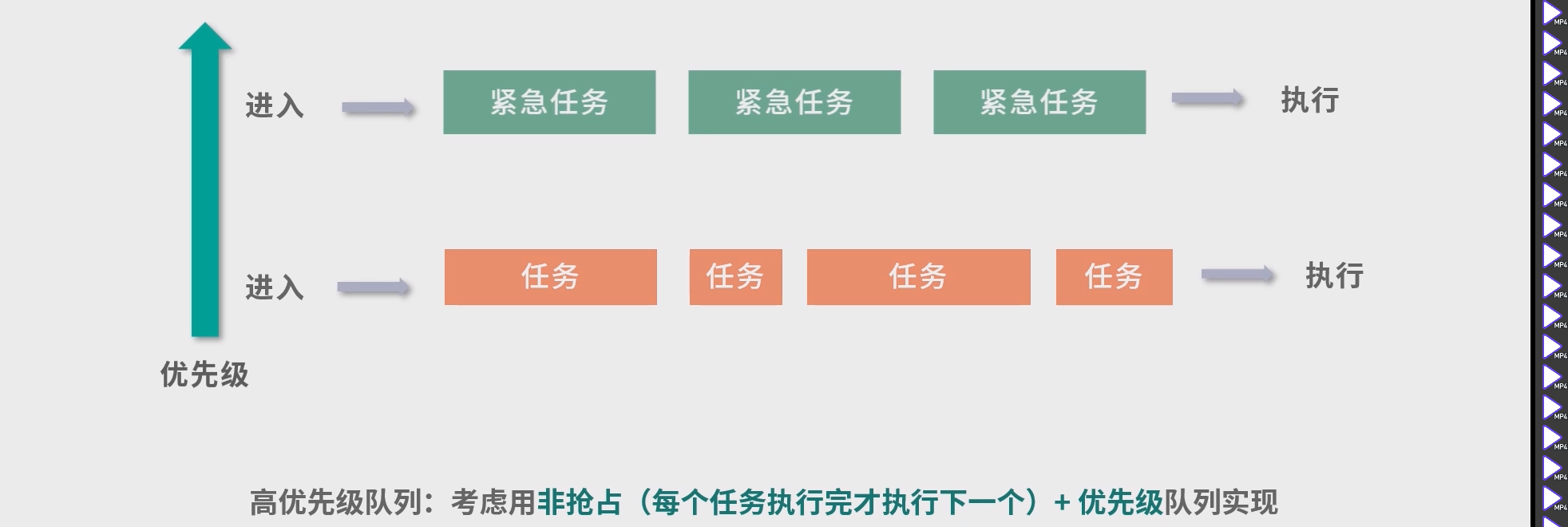
- 只要上层队列有任务,下层队列就会让出执行权限。
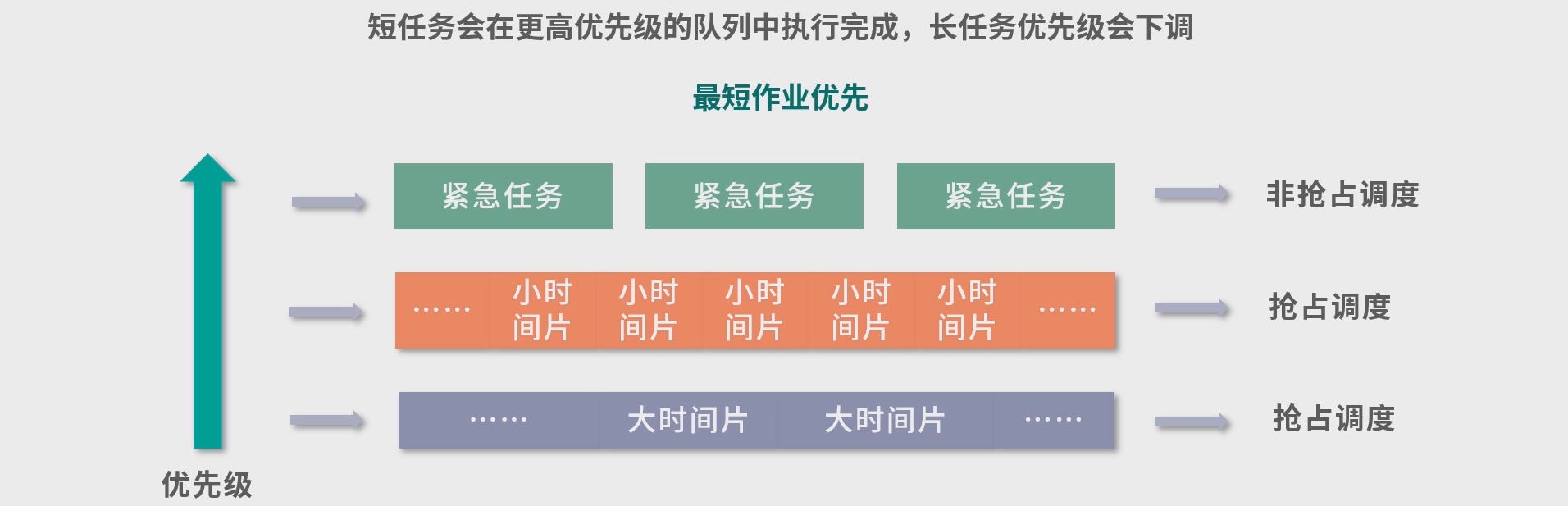
- 实际操作中,可以有
n层,一层层把大任务筛选出来。 最长的任务,放到最闲的时间去执行。要知道, 大部分时间CPU不是满负荷的。
死锁 与饥饿
哲学家就餐问题
圆桌上有 5 份意大利面和 5 份叉子。哲学家比较 笨,他们必须拿到左手和右手的 2 个叉子才能吃面。哲学不饿的时候就在思考,饿了就去吃面,吃面的 必须前提是拿到 2 个叉子,吃完面哲学家就去思考。

问题的抽象

enum PHIS { THINKING, HUNGRY, EATING } // 枚举 状态
void think() throws InterruptedException { // 思考
System.out.println(String.format("Philosopher %d thinking...", id));
Thread.sleep((long) Math.floor(Math.random()\*1000));
this.state = PHIS.HUNGRY;
}
void eat() throws InterruptedException {
synchronized (forks) { // eat方法依赖于forks对象的锁,相当于eat方法这里会同步——因为这里有读取临界区操作做。
if(forks[LEFT(id)] == id && forks[id] == id) { this.state = PHIS.EATING;
} else {
return;
}
} Thread.sleep((long) Math.floor(Math.random()\*1000)); // Thread.sleep依然用于描述eat方法的时间开销
}
synchronized 关键字 : 加锁
sleep方法没有放到synchronized内是因为在并发控制时,应该尽量较少锁的范围,这样可以增加更大的并发量。

死锁(DeadLock)和活锁(LiveLock)
//每个哲学家用一个while循环表示,
while(true){
think();
\_take(LEFT(id));
\_take(id);
eat();
\_put(LEFT(id));
\_put(id);
}
void \_take(id){
while(forks[id] != -1) {
Thread.yield();
}
Thread.sleep(10); // 模拟I/O用时
}
_take可以考虑阻塞,直到哲学家得到叉子。上面程序我们还没有进行并发控制,会发生竞争条件。

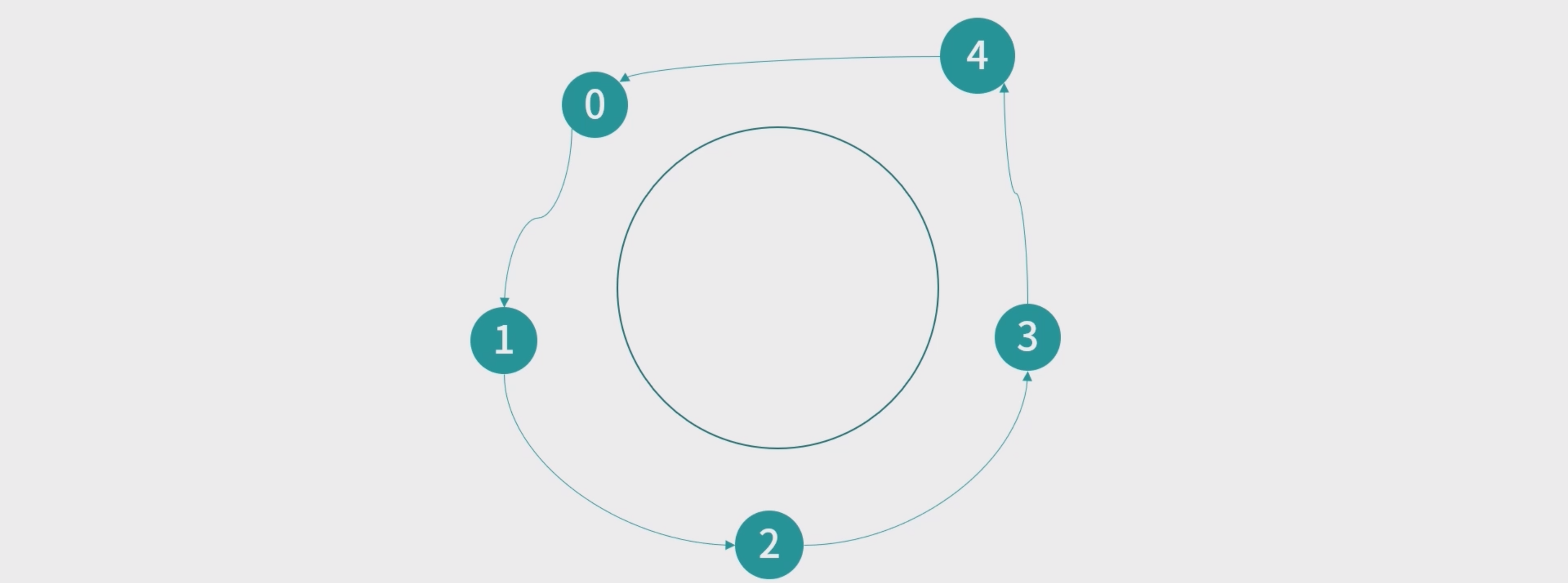

- 死锁(
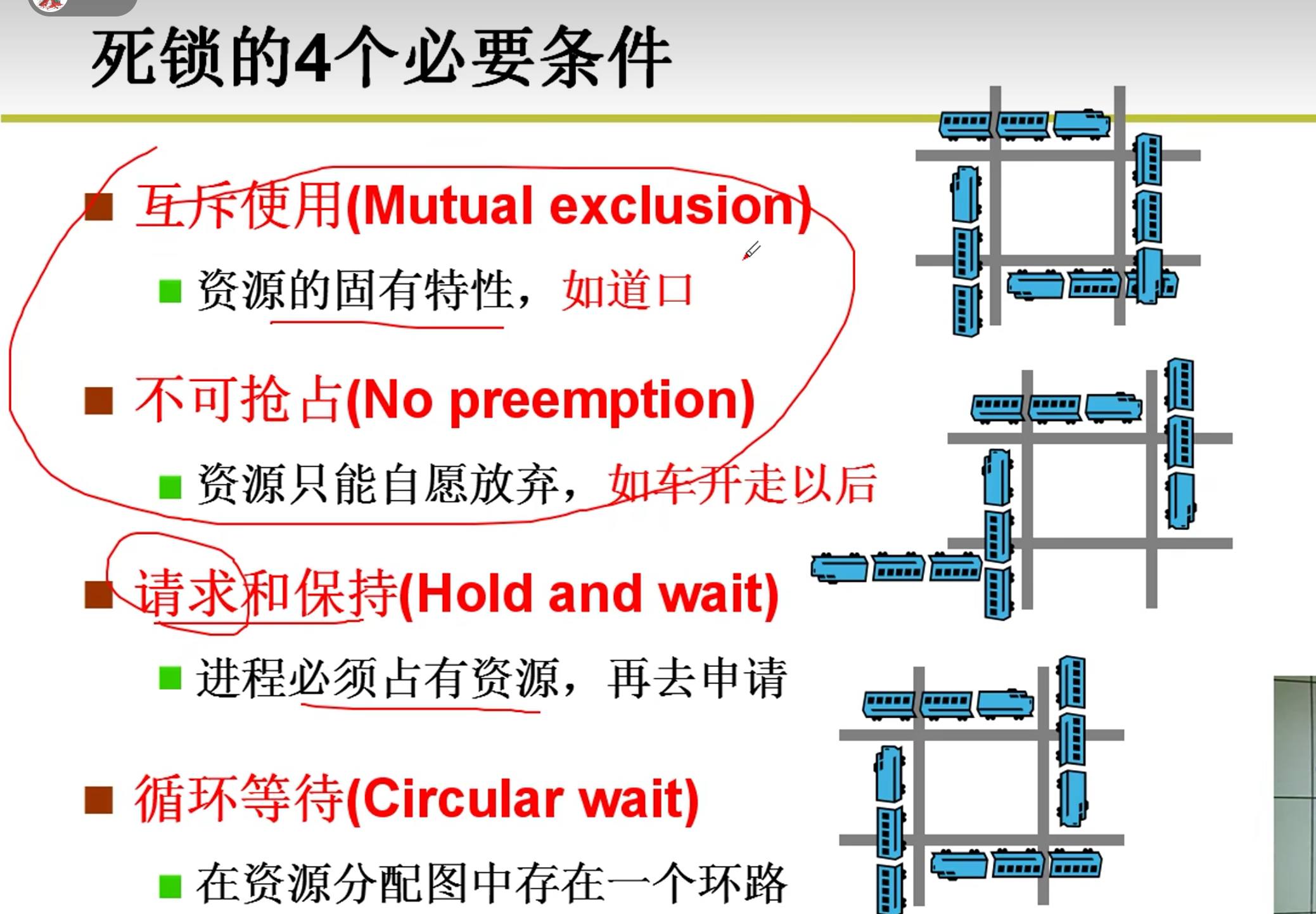
Deadlock),这是一种饥饿(Starvation)**的形式。从概念上说,死锁是线程间互相等待资源,但是没有一个线程可以进行下一步操作。饥饿就是因为某种原因导致线程得不到需要的资源,无法继续工作。死锁是饥饿的一种形式,因为循环等待无法得到资源。哲学家就餐问题,会形成一种环状的死锁(循环依赖). - 死锁有 4 个基本条件。
-
- 资源存在互斥逻辑:每次只有一个线程可以抢占到资源。这里是哲学家抢占叉子。
-
- 持有等待:这里哲学家会一直等待拿到叉子。
-
- 禁止抢占:如果拿不到资源一直会处于等待状态,而不会释放已经拥有的资源。
-
- 循环等待:这里哲学家们会循环等待彼此的叉子。
-
- 饥饿 : 线程长期拿不到需要的资源, 无法进行下一步操作。
- 要解决死锁的问题,可以考虑哲学家拿起 1 个叉子后,如果迟迟没有等到下一个叉子,就放弃这次操作。 如Java 提供
tryLock的方法是拿不到锁,就报异常,并可以依据这个能力开发释放已获得资源的能力。 - 我们会碰到一个叫作活锁
(LiveLock)的问题。LiveLock也是一种饥饿。可能在某个时刻,所有哲学及都拿起了左手的叉子,然后发现右手的叉子拿不到,就放下了左手的叉子——如此周而复 始,这就是一种活锁。所有线程都在工作,但是没有线程能够进一步——解决问题。
解决方案
//我们用synchronized构造了一种排队的逻辑。而 哲学家,每次必须拿起所有的叉子,吃完,/
//再到下一哲学家。 这样并发度是 1,同时最多有一个线程在 执行。
//这样的方式可以完成任务,但是性能太差。
while(true) {
synchronized(someLock) {
think();
\_take(LEFT(id));
\_take(id);
eat();
\_put(LEFT(id));
\_put(id);
}
}
// 同时拿起,放下过程也同时放下
while(true){ think(); synchronized(someLock) { \_takeForks();
} eat(); synchronized(someLock) { \_puts();
}
}
void \_takeForks(){ if( forks[LEFT(id)] == -1 && forks[id] == -1 ) { forks[LEFT(id)] = id; forks[id] = id;
}
}
void \_puts(){ if(forks[LEFT(id)] == id) forks[LEFT(id)] = -1;
if(forks[id] == id) forks[id] = -1;
}
//think函数没有并发控制,一个哲学家要么拿起两个叉子,要么不拿起,这样并发度最 高为 2(最多有两个线程同时执行)。
//而且,这个算法中只有一个锁,因此不存在死锁和饥饿问题。
// 优化 直接把叉子转让给另一个哲学家
void \_transfer(int fork, int philosopher) {
forks[fork] = philosopher; dirty[fork] = false;
}
//只要对方不在EATING,就可以考虑转让叉子。
//最后是对 LiveLock 的思考,为了避免叉子在两个哲学家之间来回转让,我们为每个叉子增加了一个 dirty属性。
进程间通信
什么是进程间通信?
进程间通信(Intermediate Process Communication,IPC)。所谓通信就是交换数据。

管道
- 管道提供一种重要的能力 : 组织计算 。 进程不用知道管道存在,因此管道的设计是非侵入的。程序员可以先着重在程序本身的设计,只需要预留响应管道的接口,就可以利用管道的能力。
匿名管道
进程1 | 进程2 | 进程3 | mysql -u... -p | 爬虫进程
用管道构建一个微型 爬虫然后把结果入库 达到用shell执行MySQL语句

- 上面的程序将两个进程的临时结果都同时重定向到 namedpipe,相当于把内容合并了再找机会处理。再 比如说,你的进程要不断查询本地的 MySQL,也可以考虑用命名管道将查询传递给 MySQL,再用另一 个命名管道传递回来。这样可以省去和 localhost 建立 TCP 3 次握手的时间。
- 管道的核心是不侵入、灵活,不会增加程序设计负担,又能组织复杂的计算过程。
本地内存共享
- 同一个进程的多个线程本身是共享进程内存的。 这种情况不需要特别考虑共享内存。如果是跨进程的线 程(或者理解为跨进程的程序),可以考虑使用共享内存。内存共享是现代操作系统提供的能力, Unix 系操作系统,包括 Linux 中有 POSIX 内存共享库——shmem
- 共享内存的方式,速度很快,但是程序不是很好写,因为这是一种侵入式的开发。 如果考虑并发控制,还要处理同步的问题,只要不是高性能场景,进程间通信通常不考虑共享内存的方式。
远程调用
内存共享不太好用,因此本地消息有两种常见的方法 远程调用 和 消息队列
- 远程调用(Remote Procedure Call,RPC)是一种通过本地程序调用来封装远程服务请求的方法。
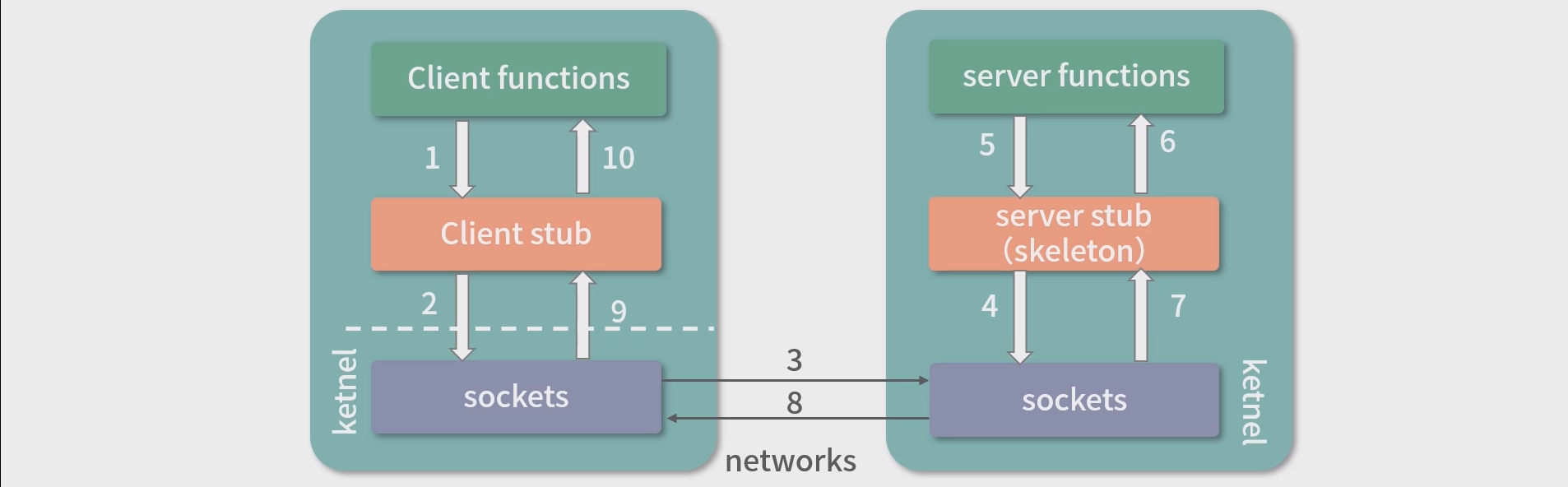
1.客户端调用函数(方法); 2. stub 将函数调用封装为请求; 3. 客户端 socket 发送请求,服务端 socket 接收请求; 4. 服务端 stub 处理请求,将请求还原为函数调用;5. 执行服务端方法; 6. 返回结果传给 stub; 7. stub 将返回结果封装为返回数据; 8. 服务端 socket 发送返回数据,客户端 socket 接收返回数据; 9. 客户端 socket 将数据传递给客户端 stub; 10. 客户端 stub 把返回数据转义成函数返回值。
- 实战的时候 ,通常的做法是使用框架,
RPC调用的方式比较适合微服务环境的开发,当然RPC通常需要专业团队的框架以支持高并发、低延迟 的场景。 - RPC 真正的缺陷是增加了系统间的耦合。当系统主动调用另一个系统的方法时,就意味着在增加 两个系统的耦合。长期增加 RPC 调用,会让系统的边界逐渐腐化
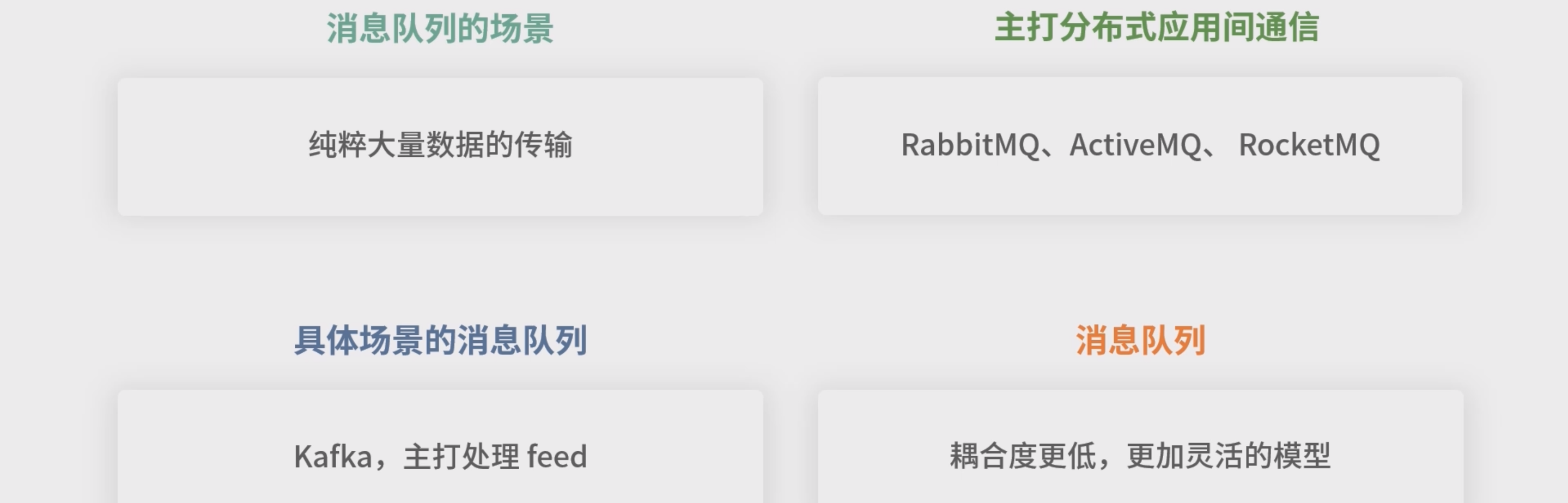
消息队列
- 事件不会增加耦合,如果一个系统订阅了另一个系统的事件,那么将来无论谁提供同类型的事件,自己都可以正常工作。系统依赖的不是另一个系统,而是某种事件。如果哪天另一个系统不存在了,只要事件由其他系统提供,系统仍然可以正常运转。
- 实现事件可以用消息队列。 ( Domain Drive Design 这个方向的知识。)
- 另一个用到消息队列的场景是纯粹大量数据的传输。 比如日志的传输,中间可能还会有收集、清洗、筛 选、监控的节点,这就构成了一个庞大的分布式计算网络。
进程线程管理
计算密集型和 I/O 密集型
- 计算,就是利用 CPU 处理算数运算。
- 如果一个应用的主要开销在计算上, 我们称为计算密集型。
- I/O 本质是对设备的读写。读取键盘的输入是 I/O,读取磁盘(SSD)的数据是 I/O.
- 如果操作对 I/O 的依 赖强,比如频繁的文件操作(写日志、读写数据库等),可以看作I/O 密集型
- **读取硬盘数据到内存中这个过程,CPU 需不需要一个个字节处理 ? **通常是不用的,因为在今天的计算机中有一个叫作 Direct Memory Access(DMA)的模块,这个模块 允许硬件设备直接通过 DMA 写内存,而不需要通过 CPU(占用 CPU 资源)。
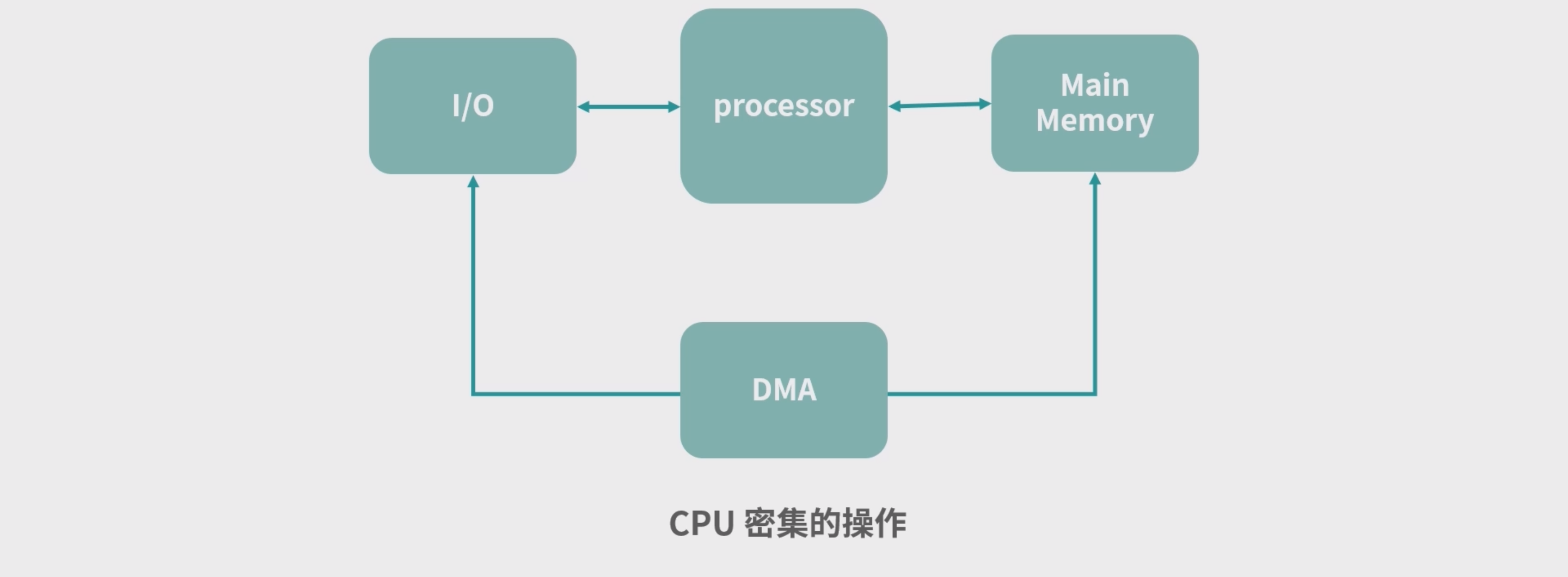
- 一般DMA区域是无法使用的,如果说你想把一个数组拷贝到另一个数组内,执行的 memcpy 函数内 部实现就是一个个 byte 拷贝,这种情况也是一种CPU 密集的操作。
衡量 CPU 的工作情况的指标
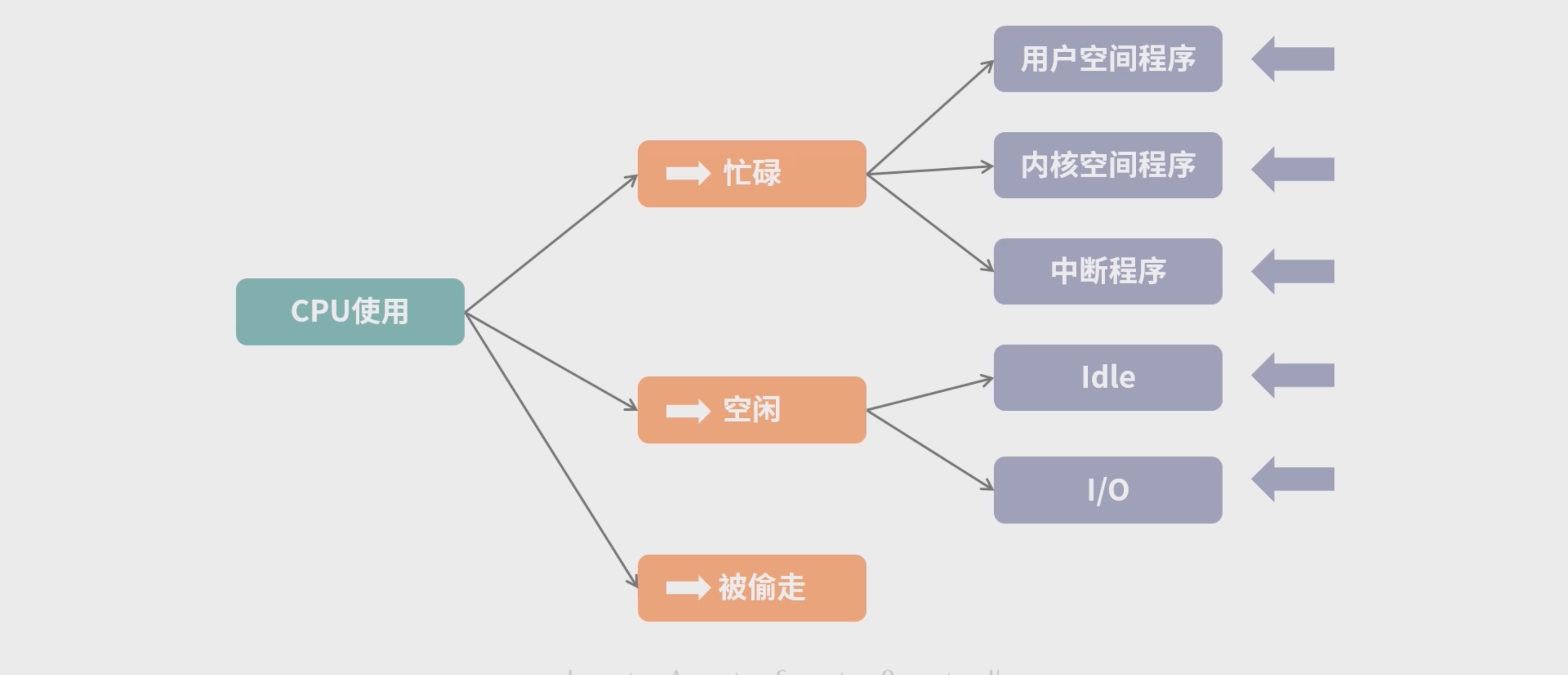
CPU 忙碌有 3 种情况: 1.
执行用户空间程序; 2. 执行内核空间程序; 3. 执行中断程序。
CPU 空闲有 2 种情况。 1.CPU 无事可做,执行空闲指令(注意,不能让 CPU 停止工作,而是执行能耗更低的空闲指令)。 2. CPU 因为需要等待 I/O 而空闲,比如在等待磁盘回传数据的中断,这种我们称为 I/O Wait。
top指令 查看当前机器状态的快照

- us(user),即用户空间 CPU 使用占比。
- sy(system),即内核空间 CPU 使用占比。
3.ni(nice),nice 是 Unix 系操作系统控制进程优先级用的。-19 是最高优先级, 20 是最低优先 级。这里代表了调整过优先级的进程的 CPU 使用占比。 - id(idle),闲置的 CPU 占比。
5.wa(I/O Wait),I/O Wait 闲置的 CPU 占比。
6.hi(hardware interrupts),响应硬件中断 CPU 使用占比。
7.si(software interrrupts),响应软件中断 CPU 使用占比。
8.st(stolen),如果当前机器是虚拟机,这个指标代表了宿主偷走的 CPU 时间占比。对于一个宿主 多个虚拟机的情况,宿主可以偷走任何一台虚拟机的 CPU 时间。
- 上面我们用
top看的是一个平均情况,如果想看所有CPU的情况可以top之后,按一下1键
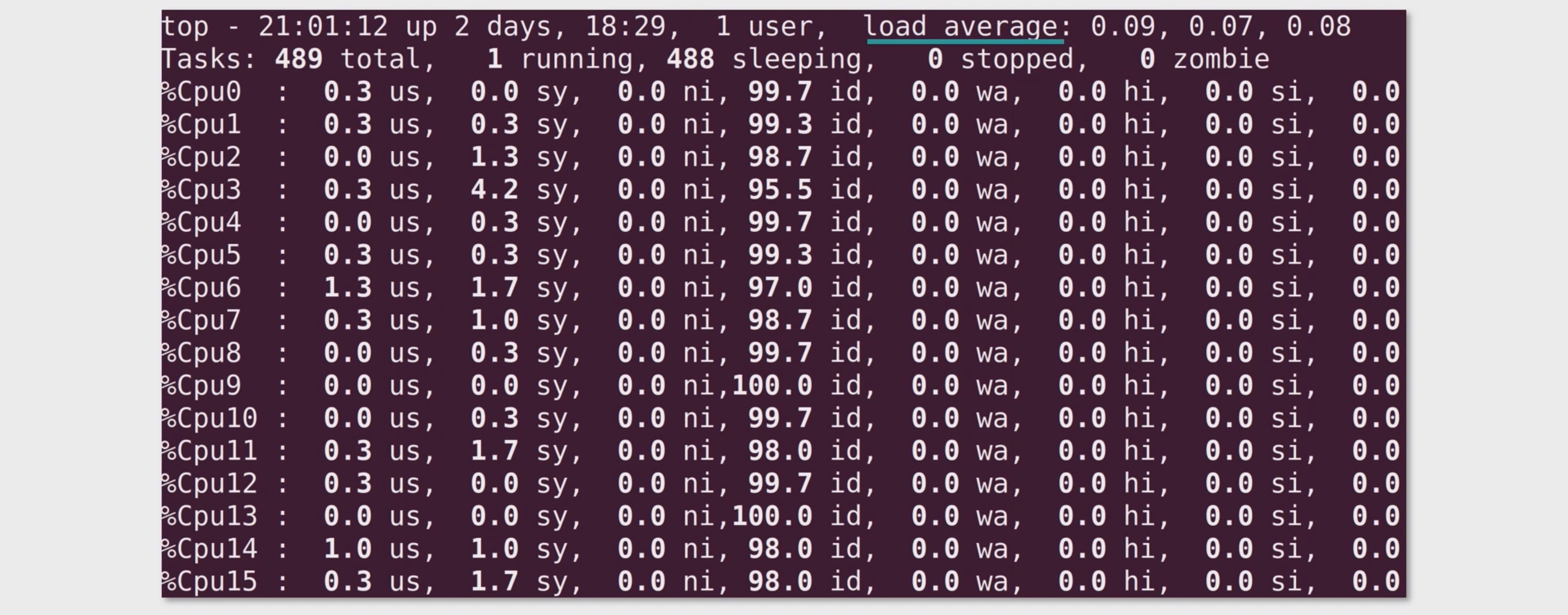
负载指标
load average——平均负载. 如果这个值大于1,说明CPU相当忙碌。因此如果你想发现问题,可以先检查这个指标。
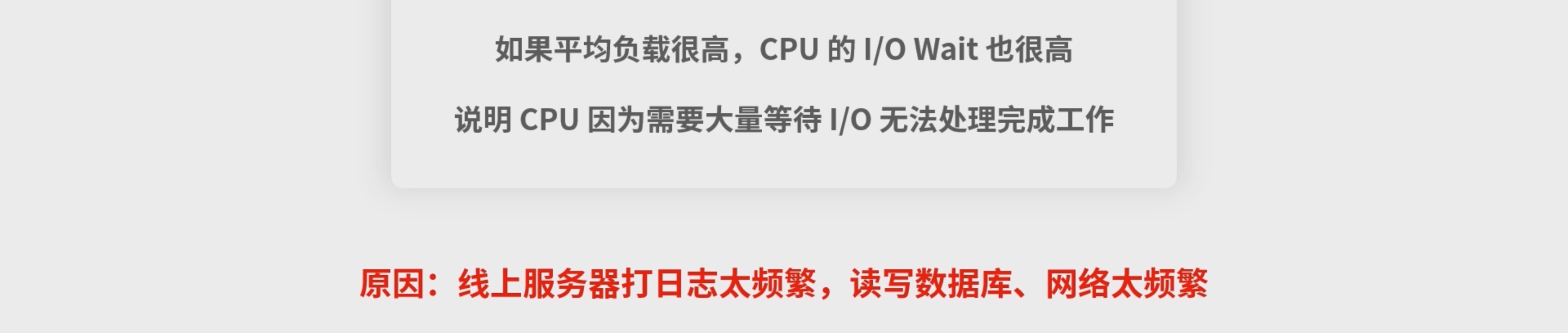
- load average,你可以看/proc/loadavg文件。
通信量(Traffic)
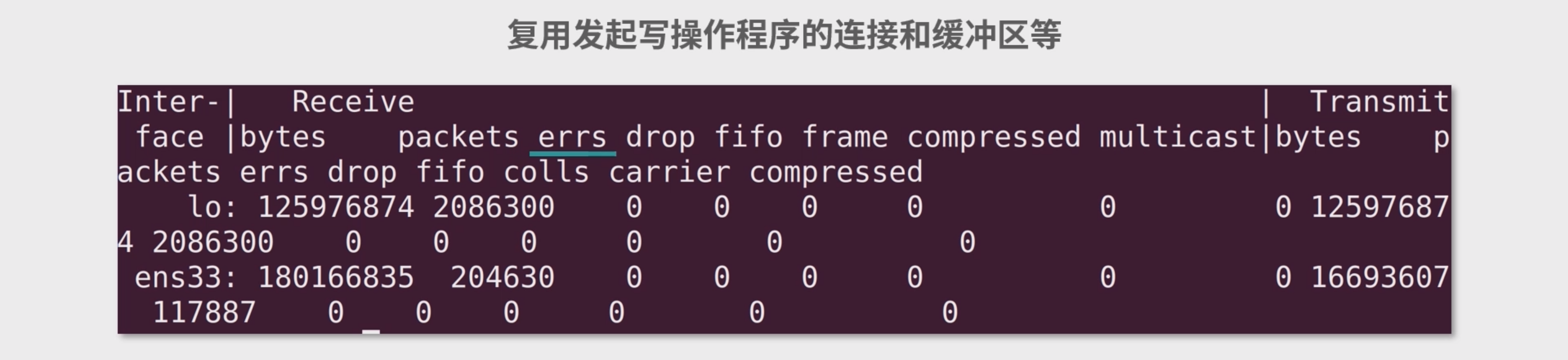
网络状况 : 查看/proc/net/dev
Interface(网络接口),可以理解成网卡
Receive:接收的数据
Transmit:发送的数据
byte 是字节数
package 是封包数
erros 是错误数
drop 是主动丢弃的封包,比如说时间窗口超时了
fifo: FIFO 缓冲区错误
frame: 底层网络发生了帧错误,代表数据出错了
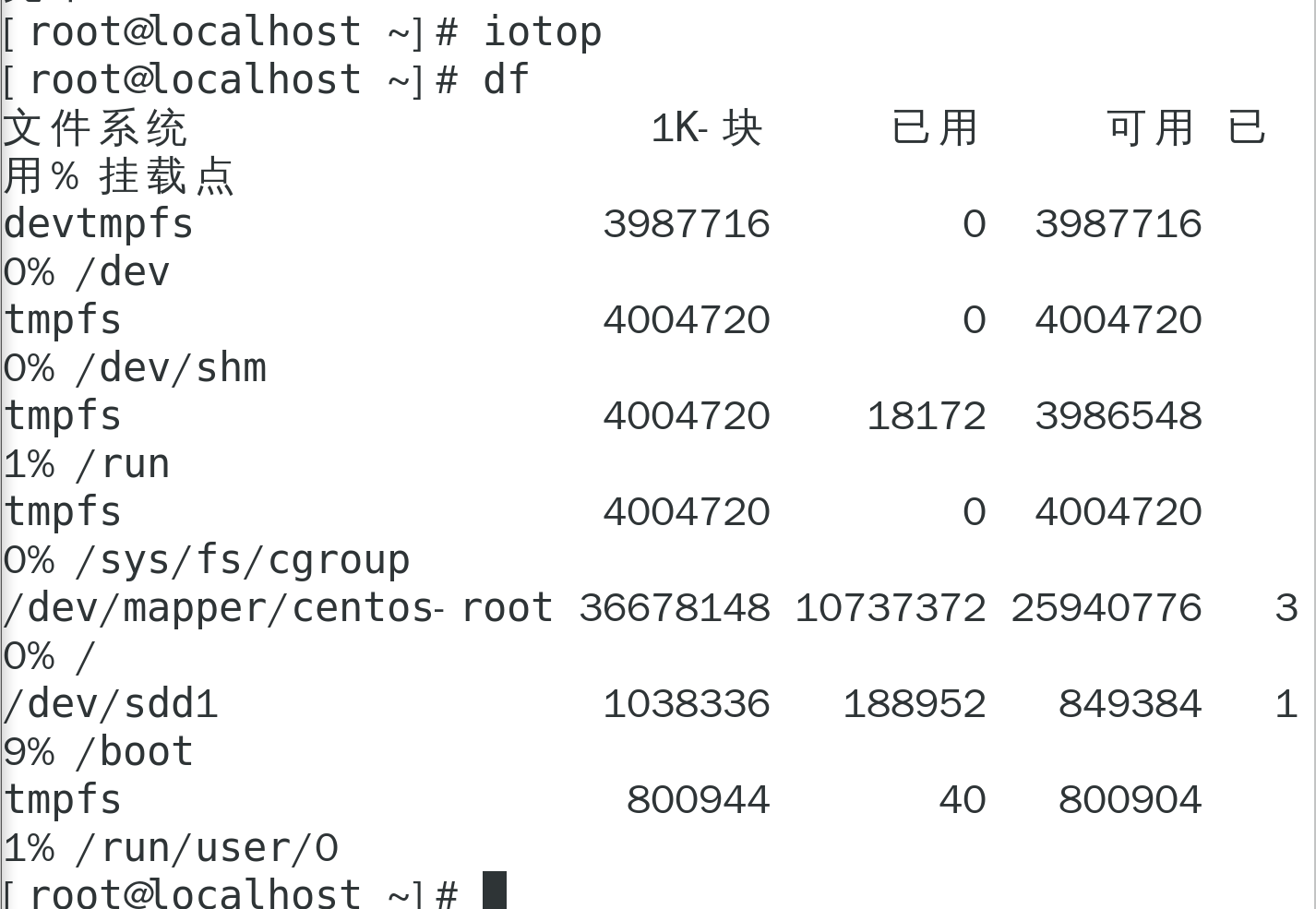
衡量磁盘工作情况
io问题查看命令 :iotop 没有的话 yum install iotop -y
磁盘空间查看可以用df指令
决定进程/线程数量
因此在实际工作中,开的线程、进程数往往是超过 CPU 核数的。具体需要 然后进行模拟真实线上压力的测试,分析压测的结果。



我的服务应该开多少个进程、多少个线程?
- 【解析】 计算密集型一般接近核数,如果负载很高,建议留一个内核专门给操作系统。I/O 密集型一般 都会开大于核数的线程和进程。 但是无论哪种模型,都需要实地压测,以压测结果分析为准;另一方 面,还需要做好监控,观察服务在不同并发场景的情况,避免资源耗尽。
然后具体语言的特性也要考虑,Node.js 每个进程内部实现了大量类似协程的执行单元,因此 Node.js 即便在 I/O 密集型场景下也可以考虑长期使用核数 -1 的进程模型。而 Java 是多线程模型,线程池通常 要大于核数才能充分利用 CPU 资源。
所以核心就一句,眼见为实,上线前要进行压力测试。
思考题
进程的开销比线程大在了哪里?
Linux 中创建一个进程自然会创建一个线程,也就是主线程。创建进程需要为进程划分出一块 完整的内存空间,有大量的初始化操作,比如要把内存分段(堆栈、正文区等)。创建线程则简单得 多,只需要确定 PC 指针和寄存器的值,并且给线程分配一个栈用于执行程序,同一个进程的多个线程 间可以复用堆栈。因此,创建进程比创建线程慢,而且进程的内存开销更大。
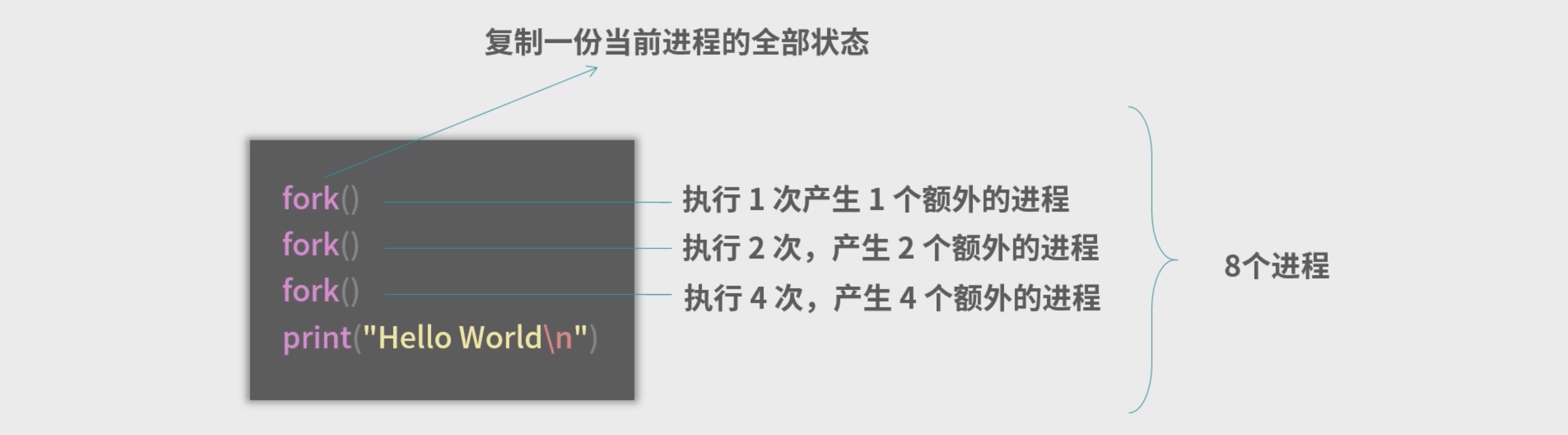
fork问题
fork() fork() fork() print("Hello World\n")请问这个程序执行后, 输出结果Hello World会被打印几次?print("Hello World\n")请问这个程序执行后, 输出结果Hello World会被打印几次?
八次


如何控制同一时间只有 2 个线程 运行?
- 同时控制两个线程进入临界区
- 一种方式可以考虑用信号量(semaphore)。
另一种方式是考虑生产者、消费者模型。想要进入临界区的线程先在一个等待队列中等待,然后由消费者每次消费两个。这种实现方式,类似于实现一个线程池,所以也可以考虑实现一个 ThreadPool 类, 然后再实现一个调度器类,最后实现一个每次选择两个线程执行的调度算法。
如果考虑到 CPU 缓存的存在,会对上面我们讨论的算法有什么影响?

在同一时刻,多线程之间,对内存中某个地址的数据认知是否一致(简单理解,就是多个线程读取同一个内存地址能不能读到一致的值)。
对某个地址,和任意时刻,如果所有线程读取值,得到的结果都一样,是一种强一致性,我们称为线性 一致性(Sequencial Consistency),含义就是所有线程对这个地址中数据的历史达成了一致,历史没 有分差,有一条大家都能认可的主线,因此称为线性一致。 如果只有部分时刻所有线程的理解是一致 的,那么称为弱一致性(Weak Consistency)。
int lock = 0
void lock() {
while(!cas(&lock, 0, 1)){
// CPU降低功耗的指令
}
}
上述程序构成了一个简单的自旋锁(spin-lock)。如果考虑到内存一致性模型,线程 1 通过 cas 操作将 lock 从 0 置 1。这个操作会先发生在线程所在 CPU 的 L1 缓存中。cas 函数通过底层 CPU 指令保证了原 子性,cas 执行完成之前,线程 2 的 cas 无法执行。当线程 1 开始临界区的时候,假设这个时候线程 2 开始执行,尝试获取锁。如果这个过程切换非常短暂,线程 2 可能会从内存中读取 lock 的值(而这个值 可能还没有写入,还在 Thread 所在 CPU 的 L1、L2 中),线程 2 可能也会通过 cas 拿到锁。两个线程 同时进入了临界区,造成竞争条件。这个时候,就需要强制让线程 2的读取指令一定等到写入指令彻底完成之后再执行,避免使用 CPU 缓存。
除了上锁还有哪些并发控制方法?
【解析】 基于乐观锁的版本控制、区块链技术。 (非OS ) 处理并发还可以考虑 Lock-Free数据结构。比如 Lock-Free 队列,是基于 cas 指令实现的,允许多个线程使用这个队列。再比如 ThreadLocal,让每个线程访问不同的资源,旨在用空间换时间,也是避免锁的一种方案。
举例各 2 个悲观锁和乐观锁的应用场景?
- 乐观锁、悲观锁都能够实现避免竞争条件,实现数据的一致性。 比如减少库存的操作,无论是 乐观锁、还是悲观锁都能保证最后库存算对(一致性)。 但是对于并发减库存的各方来说,体验是不一 样的。悲观锁要求各方排队等待。 乐观锁,希望各方先各自进步。所以进步耗时较长,合并耗时较短的 应用,比较适合乐观锁。 比如协同创作(写文章、视频编辑、写程序等),协同编辑(比如共同点餐、 修改购物车、共同编辑商品、分布式配置管理等),非常适合乐观锁,因为这些操作需要较长的时间进 步(比如写文章要思考、配置管理可能会连续修改多个配置)。乐观锁可以让多个协同方不急于合并自 己的版本,可以先
focus在进步上。 - 相反,悲观锁适用在进步耗时较短的场景,比如锁库存刚好是进步(一次库存计算)耗时少的场景。这种场景使用乐观锁,不但没有足够的收益,同时还会导致各个等待方(线程、客户端等)频繁读取库存 ——而且还会面临缓存一致性的问题(类比内存一致性问题)。这种进步耗时短,频繁同步的场景,可 以考虑用悲观锁。类似的还有银行的交易,订单修改状态等。
再比如抢购逻辑,就不适合乐观锁。抢购逻辑使用乐观锁会导致大量线程频繁读取缓存确认版本(类似 cas 自旋锁),这种情况下,不如用队列(悲观锁实现)。
线程调度都有哪些方法?
解析: 非抢占的先到先服务的模型是最朴素的,公平性和吞吐量可以保证。但是因为希望减少用户的平均等待时间,操作系统往往需要实现抢占。操作系统实现抢占,仍然希望有优先级,希望有最短任务优先。但是这里有个困难,操作系统无法预判每个任务的预估执行时间,就需要使用分级队列。最高优先级的任务可以考虑非抢占的优先级队列。 其他任务放到分级队列模型中执行,从最高优先级时间片段最小向 最低优先级时间片段最大逐渐沉淀。这样就同时保证了小任务先行和高优任务最先执行。
什么情况下会触发饥饿和死锁? (“什么情况下”的时候,面试官实际想听的是你经过理解,整理 得到的认知。回答应该是概括的、简要的)
【解析】 线程需要资源没有拿到,无法进行下一步,就是饥饿。死锁
(Deadlock)和活锁(Livelock)都是饥饿的一种形式。 非抢占的系统中,互斥的资源获取,形成循环依赖就会产生死锁。死锁发生后, 如果利用抢占解决,导致资源频繁被转让,有一定概率触发活锁。死锁、活锁,都可以通过设计并发控 制算法解决,比如哲学家就餐问题。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
段最大逐渐沉淀。这样就同时保证了小任务先行和高优任务最先执行。
什么情况下会触发饥饿和死锁? (“什么情况下”的时候,面试官实际想听的是你经过理解,整理 得到的认知。回答应该是概括的、简要的)
【解析】 线程需要资源没有拿到,无法进行下一步,就是饥饿。死锁
(Deadlock)和活锁(Livelock)都是饥饿的一种形式。 非抢占的系统中,互斥的资源获取,形成循环依赖就会产生死锁。死锁发生后, 如果利用抢占解决,导致资源频繁被转让,有一定概率触发活锁。死锁、活锁,都可以通过设计并发控 制算法解决,比如哲学家就餐问题。
[外链图片转存中…(img-4lX4iTzt-1715591536938)]
[外链图片转存中…(img-6NkQfmp6-1715591536938)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









