







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
3. 饥饿(hunger)
贪婪的work抢占共享锁以完成整个工作循环,而和平的work则试图只在需要使用的时候才锁定。相同的时间间隔内,和平的work比贪婪的work少处理一半的工作量。
贪婪的work不必要扩大对临界区持有时间,并阻止了和平的work高效工作。
可以通过记录进程速度是否达到预期,检测某个进程是否饥饿。
饥饿会导致程序表现低效。
1.2.5. 确定并发安全
在编写函数的时候,需要对函数做一些注解,提醒使用者需要考虑以下问题:
- 谁负责并发?
- 如何利用并发原语解决这个问题的?
- 谁负责同步?
1.2.6. 面对复杂性的简单性
golang的gc在1.8版本开始,gc暂停一般都是 10~100μs
2.对你的代码建模:通信顺序进程
并发于并行的区别
宣讲概念,容易让人觉得好为人师,矫情的不谦逊。
Erlang作者Joe Armstrong举例子:
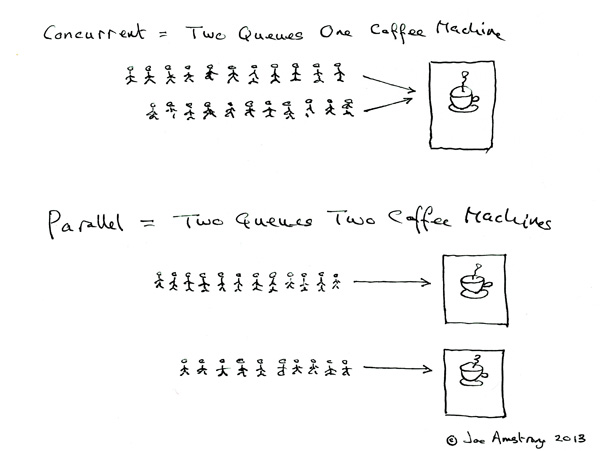
Concurrent
Two queues and one coffee machine.
Parallel
Two queues and two coffee machines.
什么是CSP
communicating sequential processes(通讯顺序进程)。
CSP 并发模型是上个世纪七十年代提出的,用于描述两个独立的并发实体通过共享 channel(管道)进行通信的并发模型。
Go语言就是借用 CSP 并发模型的一些概念为之实现并发的,但是Go语言并没有完全实现了 CSP 并发模型的所有理论,仅仅是实现了 process 和 channel 这两个概念。
process 就是Go语言中的 goroutine,每个 goroutine 之间是通过 channel 通讯来实现数据共享。
Go语言的并发哲学
分辨使用传统锁、channel;
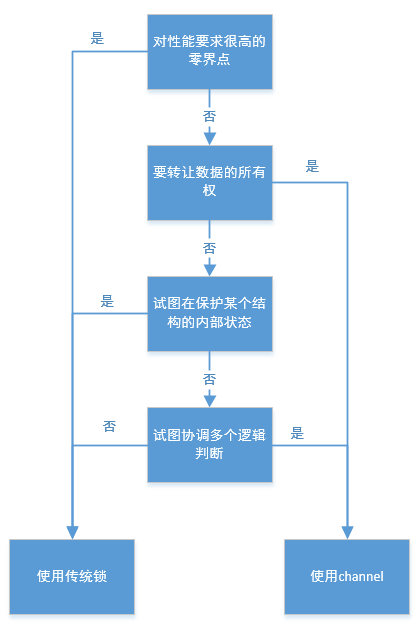
总结:追求简洁,尽量使用channel,并且认为gorountine的使用是没有成本的。
3.Go语言并发组件
goroutine
开启一个golang的协程。作者8G内存的机器,理论上可以创建数百万个goroutine。而且协程切换上下文的时候,成本比较低。
sync包
WaitGroup
可以把它当作线程安全的计数器。Add函数增加计数,Done函数减少计数,Wait函数阻塞,直到计数为0.
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
}()
wg.Wait()
互斥锁和读写锁
互斥锁用于保护临界区资源
var lock sync.Mutex
lock.Lock()
lock.Unlock()
读写锁
var m = sync.RWMutex
m.RLocker()
RWMutex提供了四个方法:
func (*RWMutex) Lock // 写锁定
func (*RWMutex) Unlock // 写解锁
func (*RWMutex) RLock // 读锁定
func (*RWMutex) RUnlock // 读解锁
cond
var locker = new(sync.Mutex)
var cond = sync.NewCond(locker)
func test(x int) {
cond.L.Lock() //获取锁
fmt.Println("aaa: ", x)
cond.Wait()//等待通知 暂时阻塞
fmt.Println("bbb: ", x)
time.Sleep(time.Second * 2)
cond.L.Unlock()//释放锁
}
func main() {
for i := 0; i < 5; i++ {
go test(i)
}
fmt.Println("start all")
time.Sleep(time.Second * 1)
fmt.Println("broadcast")
cond.Signal() // 下发一个通知给已经获取锁的goroutine
time.Sleep(time.Second * 1)
cond.Signal()// 3秒之后 下发一个通知给已经获取锁的goroutine
time.Sleep(time.Second * 1)
cond.Broadcast()//3秒之后 下发广播给所有等待的goroutine
time.Sleep(time.Second * 10)
fmt.Println("finish all")
}
once
让一个操作只调用一次,就可以使用这个方式来制作。
package main
import (
"fmt"
"sync"
"time"
)
var once sync.Once
func main() {
for i, v := range make([]string, 10) {
once.Do(onces)
fmt.Println("count:", v, "---", i)
}
for i := 0; i < 10; i++ {
go func() {
once.Do(onced)
fmt.Println("213")
}()
}
time.Sleep(4000)
}
func onces() {
fmt.Println("onces")
}
func onced() {
fmt.Println("onced")
}
池
池是对于Pool模式的一种并发安全实现。
对外提供Get方法,如果发现池子里面没有空闲的元素,将会新建一个元素出来。
当使用完成了之后,将会需要调用Put方法将内存归还。
在构建池的时候,需要提供给它一个构造元素的函数。这个函数是线程安全的。
使用场景是这些东西是需要被多个线程共用,而且需求的东西是非常同质化,需要考虑的事情就是new出来,初始化的成本。打个比方:如果需要新建一个db的连接,今后其他的进程还需要使用,这样的情况使用Pool。如果找程序申请一段边长的内存块,那就最好使用new直接搞定。
需要注意的点:
- 当实例化sync.Pool,使用new方法创建一个成员变量,在调用时是线程安全的。
- 当你收到了一个来自Get的实例时,不要对所接受的对象的状态做任何的假设。
- 当你用完了一个Pool中取出来的对象时,一定要调用Put,否则,Pool无法复用这个实例。
- Pool内的分布必须大致均匀。
channel
channel是由Hoare的CSP派生出来的同步原语之一。
channel通常使用Stream来命名这种变量。
var dataStream chan interface{}
dataStream = make(chan interface{})
var recvChan <-chan interface{}
var sendChan <-chan interface{}
recvChan = dataStream
sendChan = dataStream
<-writeStream
// invaslid operation: <- writeStream (receive from send-only type)
上述的例子是构建了一个双向链表,recvChan和sendChan是为了约束数据的流向,防止在生产者场景下读取了数据。
channel里面读取数据的写法如下:
salutation,ok := <-stringStream
当channel被关闭了,返回的ok也是失败的。
| 操作 | Channel状态 | 结果 |
|---|---|---|
| Read | nil | 阻塞 |
| 打开且非空 | 输出值 | |
| 关闭的 | <默认值>,false | |
| 只读 | 编译报错 | |
| Write | nil | 阻塞 |
| 打开的但填满 | 阻塞 | |
| 打开,但不满 | 写入值 | |
| 关闭的 | panic | |
| 只读 | 编译报错 | |
| close | nil | panic |
| 打开且非空 | 关闭channel;读取成功,直到通道耗尽,然后读取产生值的默认值 | |
| 打开但空 | 关闭channel;读到生产者的默认值 | |
| 关闭的 | panic | |
| 只读 | 编译报错 |
如果关闭了channel,其实还是会将里面的内容都读取出来的。
var stringStream chan string
stringStream = make(chan string, 1)
var recvStream <-chan string
var sendStream chan<- string
recvStream = stringStream
sendStream = stringStream
go func() {
time.Sleep(2 \* time.Second)
for {
if val, ok := <-recvStream; ok {
fmt.Println(val)
} else {
fmt.Println("no data")
break
}
}
}()
sendStream <- "hh"
sendStream <- "hh"
close(stringStream)
time.Sleep(8 \* time.Second)
对于channel来说,生产者负责发送数据,并且负责销毁。消费者只负责读取,当无法读取的时候,就说明关闭了。
channel是goroutine的黏合剂
select语句
select是将channel绑定到一块的黏合剂。
select将会选择在其语句段内的某个可工作的通道工作一次。
GOMAXPROCES控制
runtime.GOMAXPROCS(runtime.NumCPU())
在1.5之前版本,这个值都是设置成1。后面的版本好像都是已经按照cpu个数来决定多少个线程。2
4.Go语言的并发模型
本章主要是使用3章节中学习到的原语,构建模型出来。
约束
使用词法阅书将channel从生产者传给消费者的时候,只给只读的接口。
for-select循环
按照类似这种结构来组织代码
for {
select{
case str <- recvStream:
// ...
}
}
for _, s := range[]string{"a","b","c"}{
select {
case <-done:
return
case stringStream <- e:
}
}
防止goroutine泄露
goroutine是存在泄露风险,且会造成内存增长。
goroutine有3中情况下种植
完成工作。
由于不可恢复的错误,造成不能工作。
当它被告知需要关闭。
设计原则就是谁创建channel,谁负责将channel关闭。
or-channel
将一个或多个完成的channel合并到一个完成channel,任何channel关闭时自己也关闭。
func main() {
var or func(channels ...<-chan interface{}) <-chan interface{}
or = func(channels ...<-chan interface{}) <-chan interface{} { // <1>
switch len(channels) {
case 0: // <2>
return nil
case 1: // <3>
return channels[0]
}
orDone := make(chan interface{})
go func() { // <4>
defer close(orDone)
switch len(channels) {
case 2: // <5>
select {
case <-channels[0]:
case <-channels[1]:
}
default: // <6>
select {
case <-channels[0]:
case <-channels[1]:
case <-channels[2]:
case <-or(append(channels[3:], orDone)...): // <6>
}
}
}()
return orDone
}
sig := func(after time.Duration) <-chan interface{} { // <1>
c := make(chan interface{})
go func() {
defer close(c)
time.Sleep(after)
}()
return c
}
start := time.Now() // <2>
<-or(
sig(2\*time.Hour),
sig(5\*time.Minute),
sig(1\*time.Second),
sig(1\*time.Hour),
sig(1\*time.Minute),
)
fmt.Printf("done after %v", time.Since(start)) // <3>
}
这样就能将多个channel的结束,合并到一个channel中,任意一个channel结束了就结束。
后续使用"context包"也能做这个事情。
错误处理
错误处理核心问题是“谁负责处理错误”?
谁有全景呈现问题的完整信息,就交付给谁来发起对于错误的报告。
pipeline
不要编写大函数,看待程序应该从两个方面来看待:1.流程;2.处理细节。
构建pipeline的最佳实践
代码中使用了之前防止goroutine泄露写法,防止goroutine无法正常退出。
使用pipeline封装每个stage的处理,可以方便让其能分离出多端独立的逻辑来,然后就能做一些并发的事务了。并且这样做是比较安全的。
一些便利的生成器
这章节的实例也是编写了两个stage来处理生成器,一个负责发生随机字符,另一个控制需要拿多少个。
本章还通过对比测试,其实在多核的时候,并行计算将会更加快速。
扇入,扇出
fan-out,fan-in技术。
本章节其实讨论的问题就是,如何处理多个stage里面不能畅快的跑的问题。
扇入其实就是多个流汇成一个流来处理。
扇出就是将一个流分派给多个流来处理了。
一个处理的pipeline,中间有很重的处理过程,这样只能拓宽这个处理的stage,而负载轻的可以使用少量的stage来处理。
注意:
如果结果到达的顺序不重要,循环独立运行性很重要。
or-done-channel
用于处理已经发起了退出操作,但是channel的数据需要处理完。普通写法比较直观,但是最好还是将代码封装出来,返回一个输出式的channel,外层处理逻辑者比较好写。
tee-channel
类似Unix系统中的tee函数,输入的内容可以在屏幕上输出,并且也输出到一些设定好的文件里面。这种模式其实就是将一份数据并发的分配给两个channel,然后出发后续他们的处理。
桥接channel模式
需要从这个结构里面将其中的channel拿出来,直接写逻辑。使用这个模式就式为了完成这项工作。
<- chan <- chan interface{}
里面也使用了orDone方式读取 <- chan interface{}
队列排队
有时候,在队列没有准备好的时候,就开始接受请求很有用,这种情况叫做队列。
队列的真正用途是将stage分离,以便一个stage的运行时间不会影响另一个stage的运行时间。以这种方式解耦stage,然后级联以改变整个系统的运行时行为。
这里文中举了个例子,写文件io的,先大量的调用bufio.Writer将内容写入到缓冲区,直到累积到一定程度开始写入硬盘。这个速度提升大概有3倍。但是这样有一些让内存消耗大一些。
利特尔法则
- L = 系统中平均负载数。
- λ
\lambda
λ = 负载的平均到达率。
- W = 负载在系统中花费的平均时间。
L =
λ
W
\lambda W
λW
这个等式应用于稳定系统,稳定系统的定义就是输入管道的速率和输出的速率相等。
n
L
=
λ
n
W
nL = \lambda nW
nL=λnW
L
=
λ
∑
i
=
1
∞
W
i
L = \lambda \sum_{i=1}^{\infty} Wi
L=λ∑i=1∞Wi
通过利特尔法则,我们已经证明了队列不会有助于减少在系统中所花费的时间。你的管道只会和最慢的stage一样快。
利特尔法则无法预知处理请求的失败。
队列可能会很有用,但是它是复杂的,作者建议作为最后的优化手段。
context包
由于某种原因(超时,或者强制退出)我们希望中止这个goroutine的计算任务,那么就用得到这个Context了。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
n
W
nL = \lambda nW
nL=λnW
L
=
λ
∑
i
=
1
∞
W
i
L = \lambda \sum_{i=1}^{\infty} Wi
L=λ∑i=1∞Wi
通过利特尔法则,我们已经证明了队列不会有助于减少在系统中所花费的时间。你的管道只会和最慢的stage一样快。
利特尔法则无法预知处理请求的失败。
队列可能会很有用,但是它是复杂的,作者建议作为最后的优化手段。
context包
由于某种原因(超时,或者强制退出)我们希望中止这个goroutine的计算任务,那么就用得到这个Context了。
[外链图片转存中…(img-iKK97t2M-1715527188524)]
[外链图片转存中…(img-5HW9Uvsr-1715527188524)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









