







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
D
D维的点组成,当这个
D
=
3
D=3
D=3的时候一般代表着
(
x
,
y
,
z
)
(x,y,z)
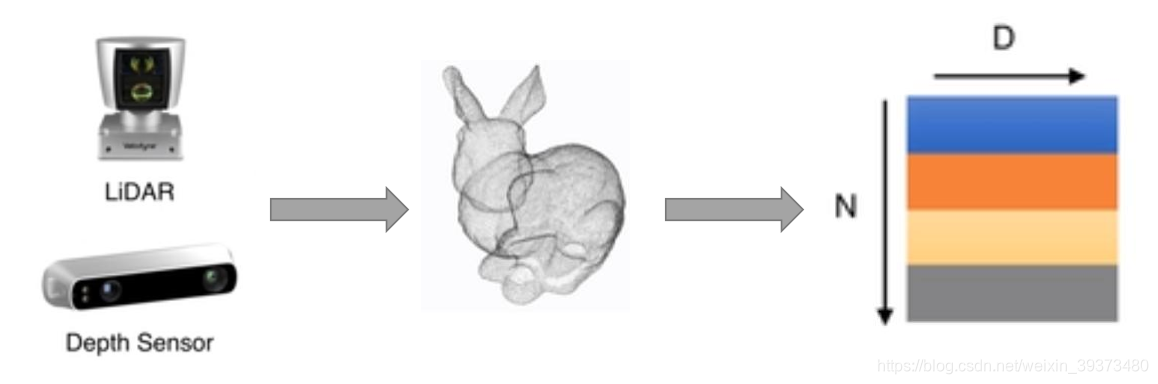
(x,y,z)的坐标,当然也可以包括一些法向量、强度等别的特征。这是今天主要讲述的数据类型。
- Mesh:由三角面片和正方形面片组成。
- 体素:由三维栅格将物体用0和1表征。
- 多角度的RGB图像或者RGB-D图像
1.2 为什么使用点云
点云由很多优势,也越来越受到雷达自动驾驶的青睐。
- 点云更接近于设备的原始表征(即雷达扫描物体直接产生点云)
- 点云的表达方式更加简单,一个物体仅用一个
N
×
D
N \times D
N×D的矩阵表示
1.3 点云上以往的相关工作
在PointNet出现以前,点云上的深度学习模型大致分为三类(这里不细述):
- 基于3DCNN的体素模型:先将点云映射到体素空间上,在通过3DCNN进行分类或者分割。但是缺点是计算量受限制,目前最好的设备也大致只能处理
32
×
32
×
32
32\times32\times32
32×32×32的体素;另外由于体素网格的立方体性质,点云表面很多特征都没有办法被表述出来,因此模型效果差。
- 将点云映射到2D空间中利用CNN分类
- 利用传统的人工点云特征分类,例如:
- normal 法向量
- intensity 激光雷达的采样的时候一种特性强度信息的获取是激光扫描仪接受装置采集到的回波强度,此强度信息与目标 的表面材质、粗糙度、入射角方向,以及仪器的发射能量,激光波长有关
- local density 局部稠密度
- local curvature 局部曲率
- linearity, planarity and scattering propesed by Dimensionality based scale selection in 3D lidar point clouds
- verticality feature proposed by Weakly supervised segmentation-aided classification of urban scenes from 3d LiDAR point clouds
2. PointNet
要想设计好的网络,首先要根据点云的特性来实现特定的网络性能,而PointNet就是这么做的。点云具有两个非常重要的特性:

2.1 基于点云的置换不变性
2.1.1 由对称函数到PointNet(vanilla)
点云实际上拥有置换不变性的特点,那么什么是置换不变性呢,简单地说就是点的排序不影响物体的性质,如下图所示:

当一个
N
×
D
N \times D
N×D在
N
N
N的维度上随意的打乱之后,其表述的其实是同一个物体。因此针对点云的置换不变性,其设计的网络必须是一个对称的函数:
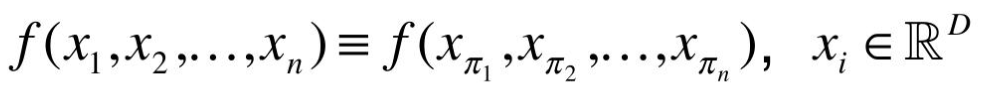
我们经常看到的SUM和MAX等函数其实都是对称函数。
因此我们可以利用max函数设计一个很简单的点云网络,如下:
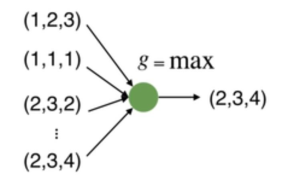
但是这样的网络有一个问题,就是每个点损失的特征太多了,输出的全局特征仅仅继承了三个坐标轴上最大的那个特征,因此我们不妨先将点云上的每一个点映射到一个高维的空间(例如1024维),目的是使得再次做MAX操作,损失的信息不会那么多。
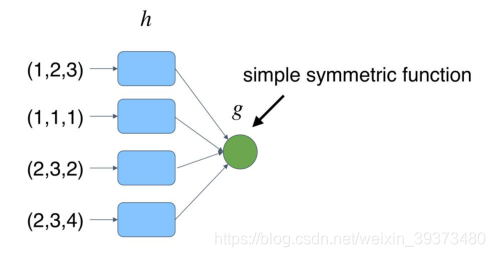
此时我们发现,当我们将点云的每个点先映射到一个冗余的高维空间后,再去进行max的对称函数操作,损失的特征就没那么多了。由此,就可以设计出这PointNet的雏形,称之为PointNet(vanilla):
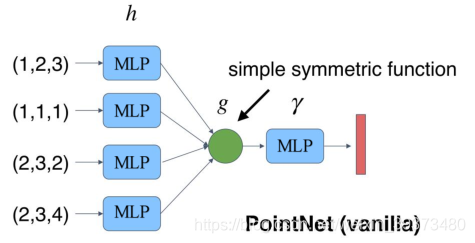
2.1.2 理论证明
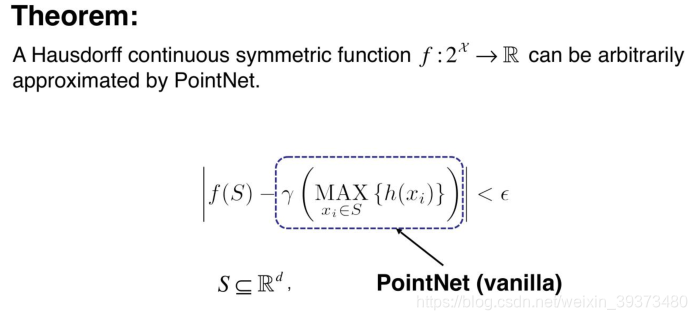
论文中其实有给出理论的证明,大致的意思是:任意一个在Hausdorff空间上连续的函数,都可以被这样的PointNet(vanilla)无限的逼近。
2.2 基于点云的旋转不变性
点云的旋转不变性指的是,给予一个点云一个旋转,所有的
x
,
y
,
z
x,y,z
x,y,z坐标都变了,但是代表的还是同一个物体。

因此对于普通的PointNet(vanilla),如果先后输入同一个但是经过不同旋转角度的物体,它可能不能很好地将其识别出来。在论文中的方法是新引入了一个T-Net网络去学习点云的旋转,将物体校准,剩下来的PointNet(vanilla)只需要对校准后的物体进行分类或者分割即可。
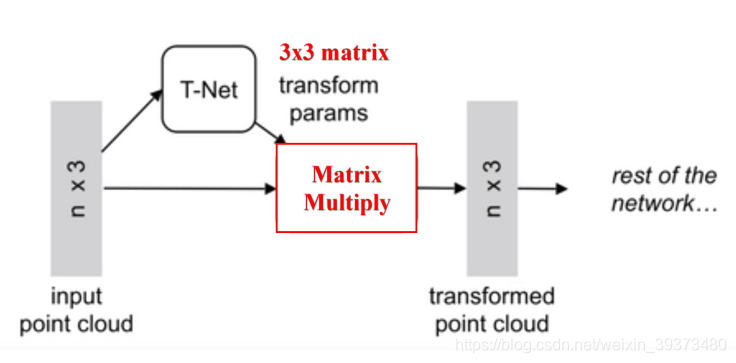
由图可以看出,由于点云的旋转非常的简单,只需要对一个
N
×
D
N\times D
N×D的点云矩阵乘以一个
D
×
D
D \times D
D×D的旋转矩阵即可,因此对输入点云学习一个
3
×
3
3 \times 3
3×3的矩阵,即可将其矫正;同样的将点云映射到K维的冗余空间后,再对K维的点云特征做一次校对,只不过这次校对需要引入一个正则化惩罚项,希望其尽可能接近于一个正交矩阵。
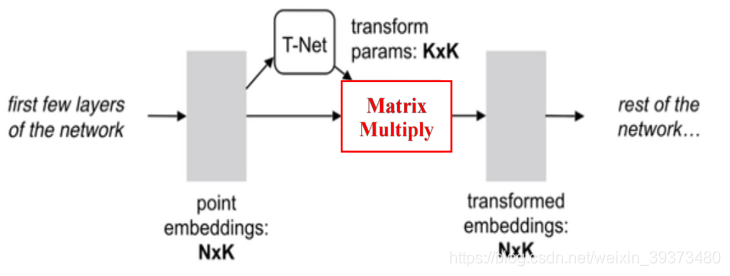
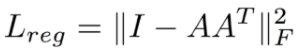
2.3 网络总体结构
满足了以上两个点云的特性之后,就可以顺理成章的设计出PointNet的网络结构了。
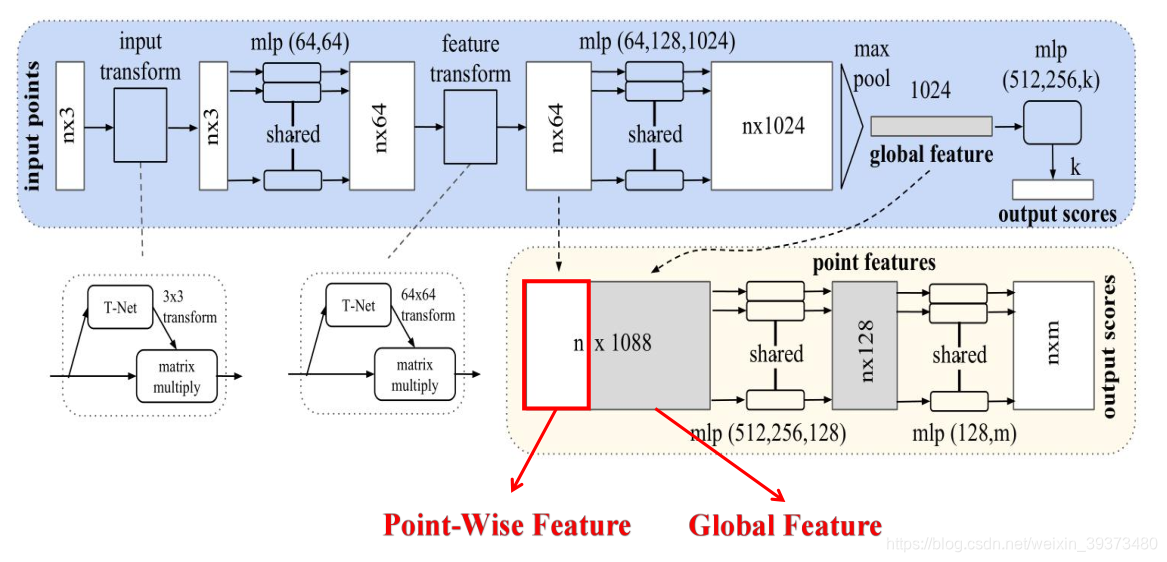
具体来说,对于每一个
N
×
3
N\times 3
N×3的点云输入,网络先通过一个T-Net将其在空间上对齐(旋转到正面),再通过MLP将其映射到64维的空间上,再进行对齐,最后映射到1024维的空间上。这时对于每一个点,都有一个1024维的向量表征,而这样的向量表征对于一个3维的点云明显是冗余的,因此这个时候引入最大池化操作,将1024维所有通道上都只保留最大的那一个,这样得到的
1
×
1024
1\times 1024
1×1024的向量就是
N
N
N个点云的全局特征。
如果做的是分类的问题,直接将这个全局特征再进过MLP去输出每一类的概率即可;但如果是分割问题,由于需要输出的是逐点的类别,因此其将全局特征拼接在了点云64维的逐点特征上,最后通过MLP,输出逐点的分类概率。
2.4 实验结果和网络的鲁棒性
pointnet当时不论是分割还是分类的结果都超过了当时的体素系列网络,同时由于参数少等特点,训练快,属于轻量级网络。
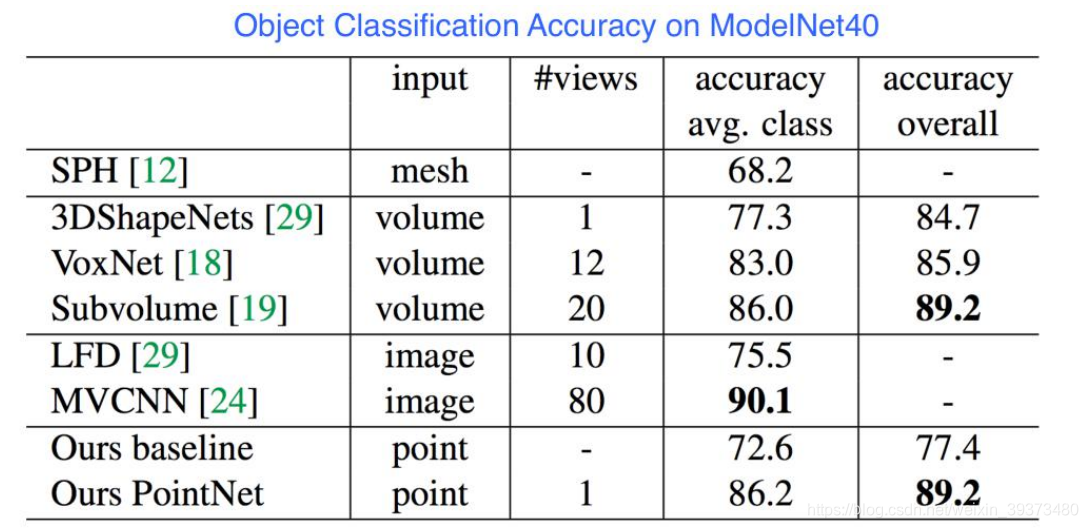
不仅如此,论文对PointNet对点云的点的缺失鲁棒性做了实验,实验证明,当PointNet缺失了60%左右的点的时候,其网络的效果都不怎么减少:
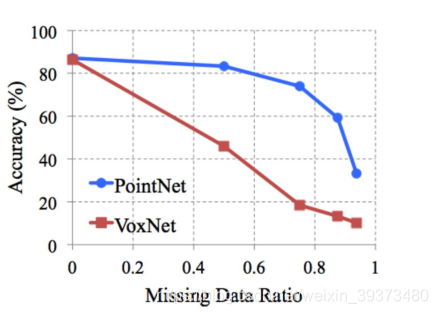
通过研究是哪些点最大程度激活了神经元的值,论文发现,能够最大程度激活网络的点都是物体的主干点(下图第二行),将其上采样,很容易能得到原始的结构。因此这就是PointNet网络的缺失鲁棒性的来源。

2.5 代码解析
PointNet的代码实际上仅由两部分组成,就是T-Net和一个Encoder-Decoder结构:
先看T-Net的代码:
class T\_Net(nn.Module):
def \_\_init\_\_(self):
super(T_Net, self).__init__()
# 这里需要注意的是上文提到的MLP均由卷积结构完成
# 比如说将3维映射到64维,其利用64个1x3的卷积核
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.array([1,0,0,0,1,0,0,0,1]).astype(np.float32))).view(1,9).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, 3, 3) # 输出为Batch\*3\*3的张量
return x
再看PointNet的主体:
class PointNetEncoder(nn.Module):
def \_\_init\_\_(self, global_feat = True):
super(PointNetEncoder, self).__init__()
self.stn = T_Net()
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.global_feat = global_feat
def forward(self, x):
'''生成全局特征'''
n_pts = x.size()[2]
trans = self.stn(x)
x = x.transpose(2,1)
x = torch.bmm(x, trans) # batch matrix multiply 即乘以T-Net的结果
x = x.transpose(2,1)
x = self.conv1(x)
x = F.relu(self.bn1(x))
pointfeat = x
x_skip = self.conv2(x)
x = F.relu(self.bn2(x_skip))
x = self.bn3(self.conv3(x))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
if self.global_feat:
return x, trans
else:
x = x.view(-1, 1024, 1).repeat(1, 1, n_pts)
return torch.cat([x, pointfeat], 1), trans
class PointNetCls(nn.Module):
def \_\_init\_\_(self, k = 2):
super(PointNetCls, self).__init__()
self.k = k
self.feat = PointNetEncoder(global_feat=False)
self.conv1 = torch.nn.Conv1d(1088, 512, 1)
self.conv2 = torch.nn.Conv1d(512, 256, 1)
self.conv3 = torch.nn.Conv1d(256, 128, 1)
self.conv4 = torch.nn.Conv1d(128, self.k, 1)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.bn3 = nn.BatchNorm1d(128)
def forward(self, x):
'''分类网络'''
batchsize = x.size()[0]
n_pts = x.size()[2]
x, trans = self.feat(x)
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = self.conv4(x)
x = x.transpose(2,1).contiguous()
x = F.log_softmax(x.view(-1,self.k), dim=-1)
x = x.view(batchsize, n_pts, self.k)
return x
class PointNetPartSeg(nn.Module):
def \_\_init\_\_(self,num_class):
super(PointNetPartSeg, self).__init__()
self.k = num_class
self.feat = PointNetEncoder(global_feat=False)
self.conv1 = torch.nn.Conv1d(1088, 512, 1)
self.conv2 = torch.nn.Conv1d(512, 256, 1)
self.conv3 = torch.nn.Conv1d(256, 128, 1)
self.conv4 = torch.nn.Conv1d(128, self.k, 1)
self.bn1 = nn.BatchNorm1d(512)
self.bn1_1 = nn.BatchNorm1d(1024)
self.bn2 = nn.BatchNorm1d(256)
self.bn3 = nn.BatchNorm1d(128)
def forward(self, x):
'''分割网络'''
batchsize = x.size()[0]
n_pts = x.size()[2]
x, trans = self.feat(x)
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = self.conv4(x)
x = x.transpose(2,1).contiguous()
x = F.log_softmax(x.view(-1,self.k), dim=-1)
x = x.view(batchsize, n_pts, self.k)
return x, trans
3. PointNet++
3.1 PointNet的缺点
PointNet++的提出源于PointNet的缺点——缺失局部特征。

从很多实验结果都可以看出,PointNet对于场景的分割效果十分一般,由于其网络直接暴力地将所有的点最大池化为了一个全局特征,因此局部点与点之间的联系并没有被网络学习到。在分类和物体的Part Segmentation中,这样的问题还可以通过中心化物体的坐标轴部分地解决,但在场景分割中,这就导致效果十分一般了。
3.2 Multi-Scale PointNet
作者在第二代PointNet中主要借鉴了CNN的多层感受野的思想。CNN通过分层不断地使用卷积核扫描图像上的像素并做内积,使得越到后面的特征图感受野越大,同时每个像素包含的信息也越多。而PointNet++就是仿照了这样的结构,具体如下:
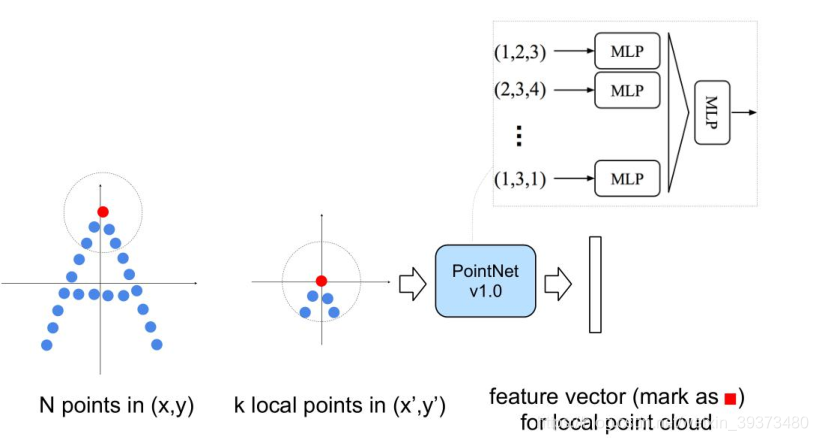
其先通过在整个点云的局部采样并划一个范围,将里面的点作为局部的特征,用PointNet进行一次特征的提取。因此,通过了多次这样的操作以后,原本的点的个数变得越来越少,而每个点都是有上一层更多的点通过PointNet提取出来的局部特征,也就是每个点包含的信息变多了。文章将这样的一个层成为Set Abstraction。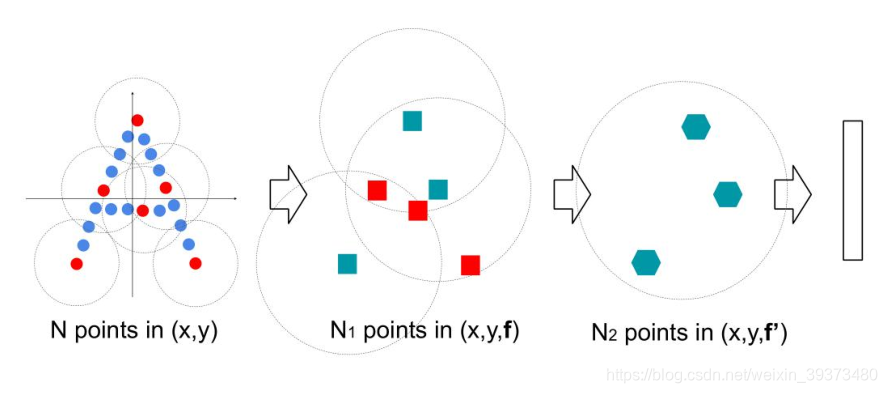
3.3 Set Abstraction的实现细节
一个Set Abstraction主要由三部分组成:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl8zOTM3MzQ4MA==,size_16,color_FFFFFF,t_70)
3.3 Set Abstraction的实现细节
一个Set Abstraction主要由三部分组成:
[外链图片转存中…(img-vw3HDzAG-1715722459735)]
[外链图片转存中…(img-vcjrDxbg-1715722459736)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









