







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
4) 多次删除集中在一起,提高删除效率
记录下已经被删除的数据,每次的删除操作并不是搬移数据,只是记录数据已经被删除,当数组没有更多的存储空间时,再触发一次真正的删除操作。即JVM标记清除垃圾回收算法。
2、链表
- 什么是链表
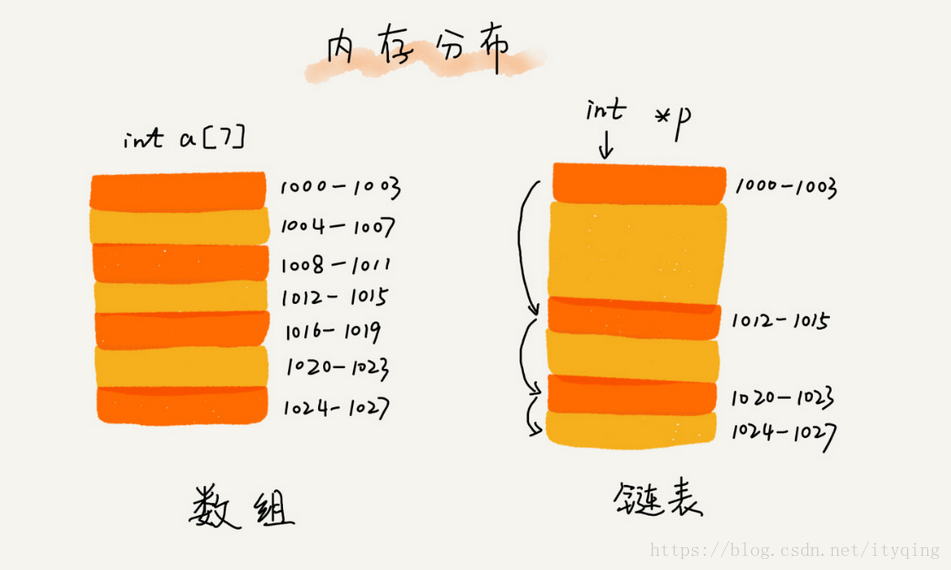
1.和数组一样,链表也是一种线性表。
2.从内存结构来看,链表的内存结构是不连续的内存空间,是将一组零散的内存块串联起来,从而进行数据存储的数据结构。
3.链表中的每一个内存块被称为节点Node。节点除了存储数据外,还需记录链上下一个节点的地址,即后继指针next。
- 链表的特点
1.插入、删除数据效率高O(1)级别(只需更改指针指向即可),随机访问效率低O(n)级别(需要从链头至链尾进行遍历)。
2.和数组相比,内存空间消耗更大,因为每个存储数据的节点都需要额外的空间存储后继指针。
- 常用链表
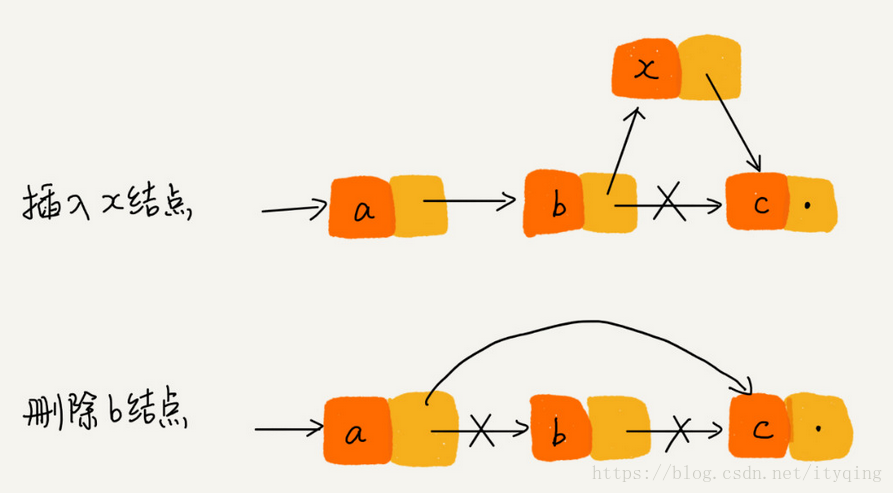
1.单链表
1)每个节点只包含一个指针,即后继指针。
2)单链表有两个特殊的节点,即首节点和尾节点。为什么特殊?用首节点地址表示整条链表,尾节点的后继指针指向空地址null。
3)性能特点:插入和删除节点的时间复杂度为O(1),查找的时间复杂度为O(n)。
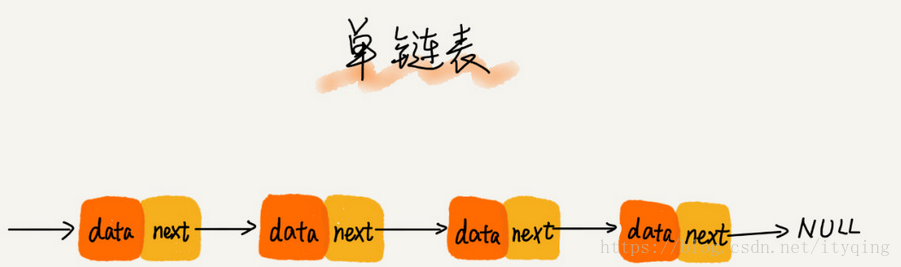
2.循环链表
1)除了尾节点的后继指针指向首节点的地址外均与单链表一致。
2)适用于存储有循环特点的数据,比如约瑟夫问题。
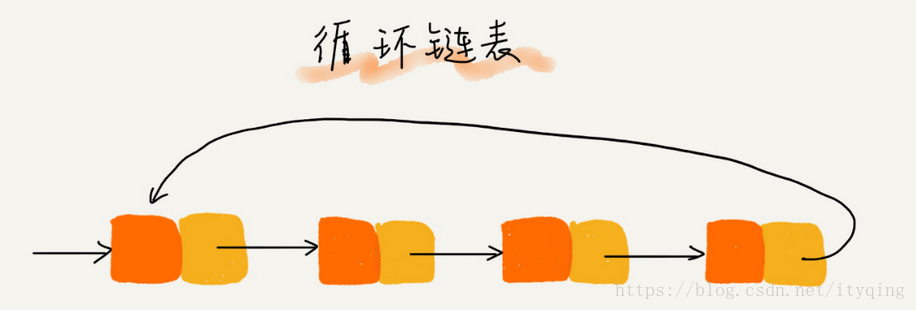
3.双向链表
1)节点除了存储数据外,还有两个指针分别指向前一个节点地址(前驱指针prev)和下一个节点地址(后继指针next)。
2)首节点的前驱指针prev和尾节点的后继指针均指向空地址。
3)性能特点:
和单链表相比,存储相同的数据,需要消耗更多的存储空间。
插入、删除操作比单链表效率更高O(1)级别。以删除操作为例,删除操作分为2种情况:给定数据值删除对应节点和给定节点地址删除节点。对于前一种情况,单链表和双向链表都需要从头到尾进行遍历从而找到对应节点进行删除,时间复杂度为O(n)。对于第二种情况,要进行删除操作必须找到前驱节点,单链表需要从头到尾进行遍历直到p->next = q,时间复杂度为O(n),而双向链表可以直接找到前驱节点,时间复杂度为O(1)。
对于一个有序链表,双向链表的按值查询效率要比单链表高一些。因为我们可以记录上次查找的位置p,每一次查询时,根据要查找的值与p的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。

4.双向循环链表:
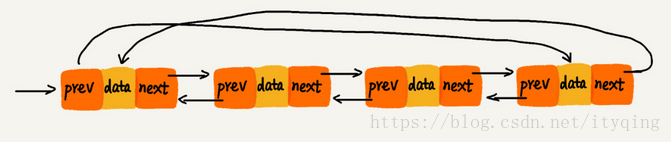
首节点的前驱指针指向尾节点,尾节点的后继指针指向首节点。
- 选择数组还是链表?
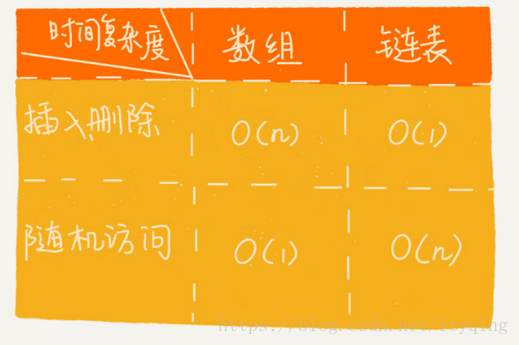
1.插入、删除和随机访问的时间复杂度
数组:插入、删除的时间复杂度是O(n),随机访问的时间复杂度是O(1)。
链表:插入、删除的时间复杂度是O(1),随机访问的时间复杂端是O(n)。
2.数组缺点
1)若申请内存空间很大,比如100M,但若内存空间没有100M的连续空间时,则会申请失败,尽管内存可用空间超过100M。
2)大小固定,若存储空间不足,需进行扩容,一旦扩容就要进行数据复制,而这时非常费时的。
3.链表缺点
1)内存空间消耗更大,因为需要额外的空间存储指针信息。
2)对链表进行频繁的插入和删除操作,会导致频繁的内存申请和释放,容易造成内存碎片,如果是Java语言,还可能会造成频繁的GC(自动垃圾回收器)操作。
4.如何选择?
数组简单易用,在实现上使用连续的内存空间,可以借助CPU的缓冲机制预读数组中的数据,所以访问效率更高,而链表在内存中并不是连续存储,所以对CPU缓存不友好,没办法预读。
如果代码对内存的使用非常苛刻,那数组就更适合。
- 应用
1.如何分别用链表和数组实现LRU缓冲淘汰策略?
1)什么是缓存?
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非广泛的应用,比如常见的CPU缓存、数据库缓存、浏览器缓存等等。
2)为什么使用缓存?即缓存的特点
缓存的大小是有限的,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?就需要用到缓存淘汰策略。
3)什么是缓存淘汰策略?
指的是当缓存被用满时清理数据的优先顺序。
4)有哪些缓存淘汰策略?
常见的3种包括先进先出策略FIFO(First In,First Out)、最少使用策略LFU(Least Frenquently Used)、最近最少使用策略LRU(Least Recently Used)。
5)链表实现LRU缓存淘汰策略
当访问的数据没有存储在缓存的链表中时,直接将数据插入链表表头,时间复杂度为O(1);当访问的数据存在于存储的链表中时,将该数据对应的节点,插入到链表表头,时间复杂度为O(n)。如果缓存被占满,则从链表尾部的数据开始清理,时间复杂度为O(1)。
6)数组实现LRU缓存淘汰策略
方式一:首位置保存最新访问数据,末尾位置优先清理
当访问的数据未存在于缓存的数组中时,直接将数据插入数组第一个元素位置,此时数组所有元素需要向后移动1个位置,时间复杂度为O(n);当访问的数据存在于缓存的数组中时,查找到数据并将其插入数组的第一个位置,此时亦需移动数组元素,时间复杂度为O(n)。缓存用满时,则清理掉末尾的数据,时间复杂度为O(1)。
方式二:首位置优先清理,末尾位置保存最新访问数据
当访问的数据未存在于缓存的数组中时,直接将数据添加进数组作为当前最有一个元素时间复杂度为O(1);当访问的数据存在于缓存的数组中时,查找到数据并将其插入当前数组最后一个元素的位置,此时亦需移动数组元素,时间复杂度为O(n)。缓存用满时,则清理掉数组首位置的元素,且剩余数组元素需整体前移一位,时间复杂度为O(n)。(优化:清理的时候可以考虑一次性清理一定数量,从而降低清理次数,提高性能。)
2.如何通过单链表实现“判断某个字符串是否为水仙花字符串”?(比如 上海自来水来自海上)
1)前提:字符串以单个字符的形式存储在单链表中。
2)遍历链表,判断字符个数是否为奇数,若为偶数,则不是。
3)将链表中的字符倒序存储一份在另一个链表中。
4)同步遍历2个链表,比较对应的字符是否相等,若相等,则是水仙花字串,否则,不是。
六、设计思想
时空替换思想:“用空间换时间” 与 “用时间换空间”
当内存空间充足的时候,如果我们更加追求代码的执行速度,我们就可以选择空间复杂度相对较高,时间复杂度小相对较低的算法和数据结构,缓存就是空间换时间的例子。如果内存比较紧缺,比如代码跑在手机或者单片机上,这时,就要反过来用时间换空间的思路。
3、队列
什么是队列:
队列是一种受限的线性表数据结构,只支持两个操作:入栈push()和出栈pop0,队列跟非常相似,支持的操作也 ,很有限,最基本的操作也是两个:入队enqueue(),放一个数据到队列尾部;出队dequeue0),从队列头部取一个元素。

特点:
1 . 队列跟栈一样,也是一种抽象的数据结构。
- 具有先进先出的特性,支持在队尾插入元素,在队头删除元素。
实现:
队列可以用数组来实现,也可以用链表来实现。
用数组实现的队列叫作顺序队列,用链表实现的队列叫作链式队列。
基于数组的队列:
实现思路:
实现队列需要两个指针:一个是head指针,指向队头;一个是tail指针,指向队尾。你可以结合下面这幅图来理解。当a,b,c,d依次入队之后,队列中的head指针指向下标为0的位置, tail指针指向下标为4的位置。
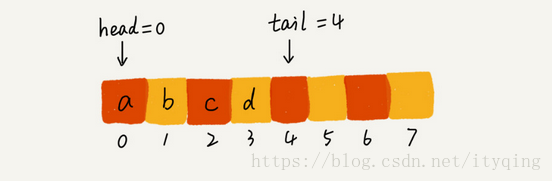
当我们调用两次出队操作之后,队列中head指针指向下标为2的位置, tail指针仍然指向下标为4的位置.
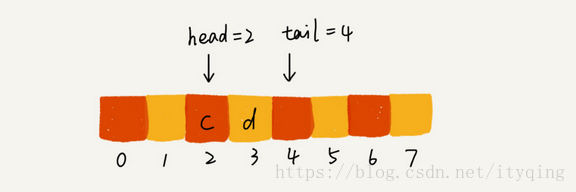
随着不停地进行入队、出队操作, head和tail都会持续往后移动。当tail移 . ,动到最右边,即使数组中还有空闲空间,也无法继续往队列中添加数据了。这个问题该如何解决呢?
在出队时可以不用搬移数据。如果没有空闲空间了,我们只需要在入队时,再集中触 ,发一次数据的搬移操作。
当队列的tail指针移动到数组的最右边后,如果有新的数据入队,我们可以将 head到tail之间的数据,整体搬移到数组中0到tail-head的位置。
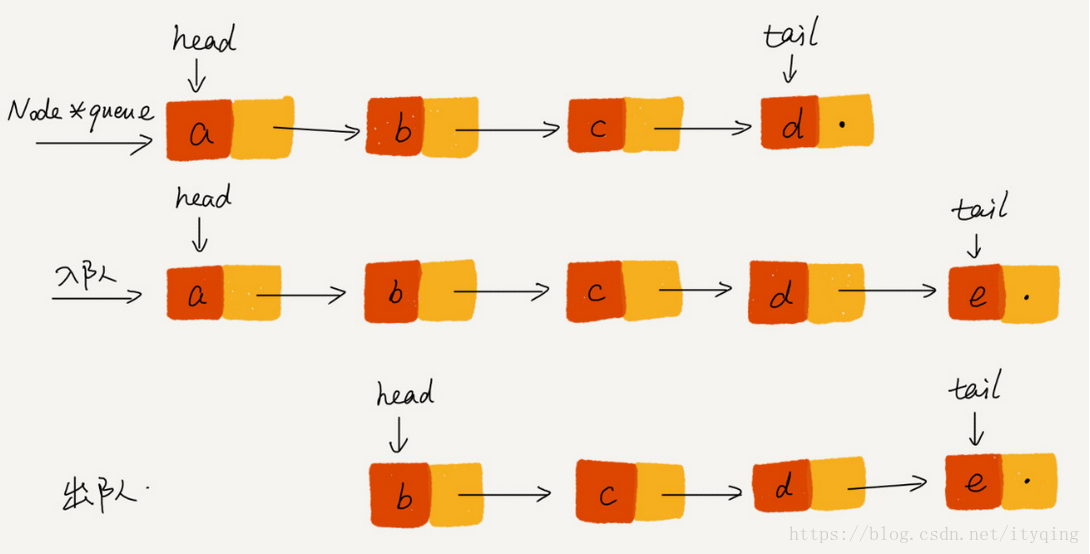
基于链表的实现:
需要两个指针: head指针和tail指针,它们分别指向链表的第一个结,点和最后一个结点。
如图所示,入队时, tail->next= new node, tail = tail->next:出队时, head = head->next.
循环队列:
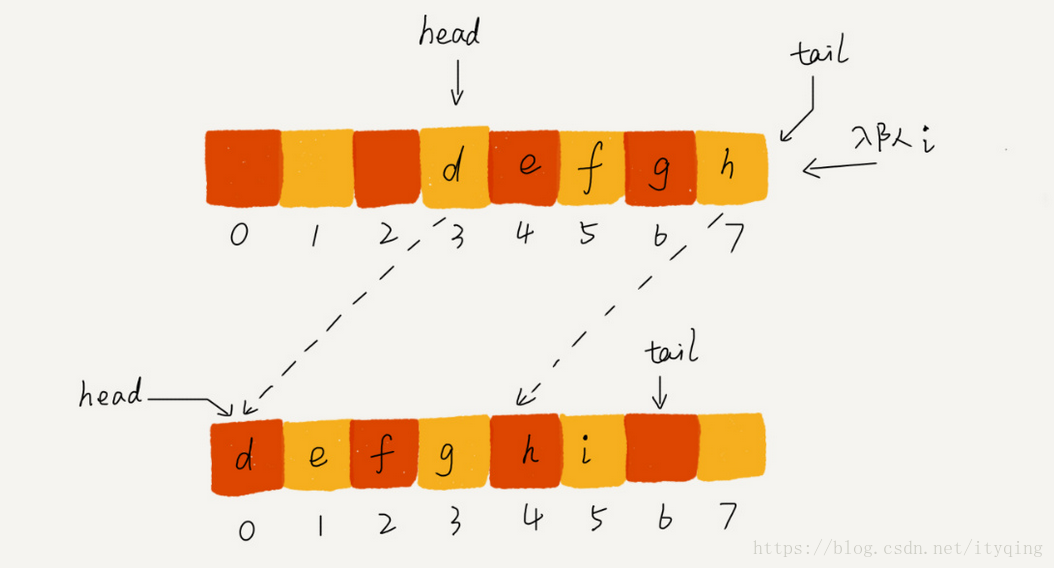
我们刚才用数组来实现队列的时候,在tail==n时,会有数据搬移操作,这样入队操作性能就会受到影响。那有没有办法能够避免数据搬移呢?我们来看看循环队列的解决思路。循环队列,顾名思义,它长得像一个环。原本数组是有头有尾的,是一条直线。现在我们把首尾相,连,板成了一个环。我画了一张图,你可以直观地感受一下。
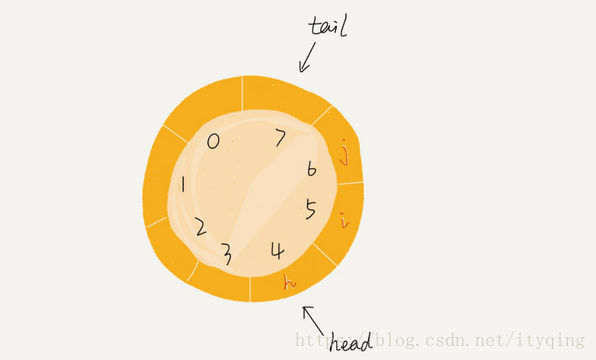
我们可以看到,图中这个队列的大小为8,当前head-4, tail-7,当有一个新的元素a入队时, .我们放入下标为7的位置。但这个时候,我们并不把tail更新为8,而是将其在环中后移一位,到下标为0的位置。当再有一个元素b入队时,我们将b放入下标为0的位置,然后tail加1更新为1,所以,在a, b依次入队之后,循环队列中的元素就变成了下面的样子:
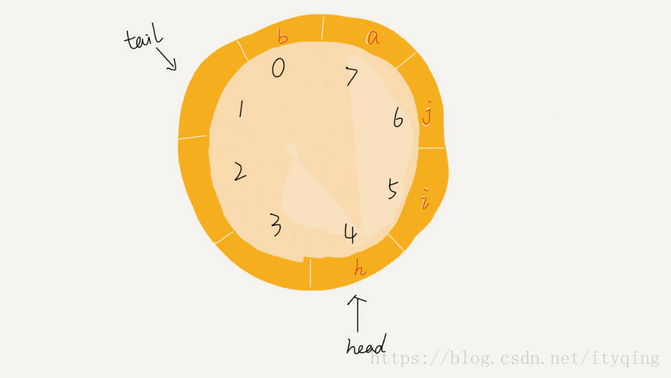
队列为空的判断条件是head == tail,但队列满的判断条件就稍微有点复杂了。我画了一张队列满的图,你可以看一下,试着总结一下规律,
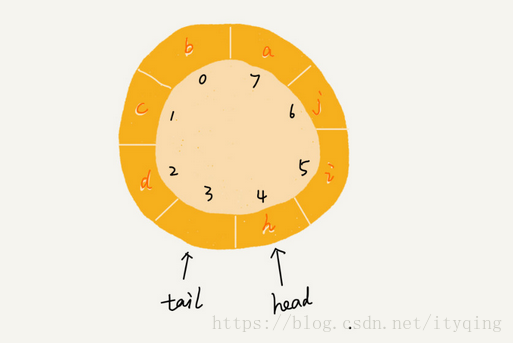
就像我图中画的队满的情况, tail=3, head-4, n=8,所以总结一下规律就是: (3+1)%8-4,多画几张队满的图,你就会发现,当队满时, (tail+1)%n=head…你有没有发现,当队列满时,图中的tail指向的位置实际上是没有存储数据的。所以,循环队列会浪费一个数组的存储空间。
解决浪费一个存储空间的思路:定义一个记录队列大小的值size,当这个值与数组大小相等时,表示队列已满,当tail达到最底时,size不等于数组大小时,tail就指向数组第一个位置。当出队时,size—,入队时size++
阻塞队列和并发队列(应用比较广泛)
阻塞队列其实就是在队列基础上增加了阻塞操作。
简单来说,就是在队列为空的时候,从队头取数 , 据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才能返回;如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。
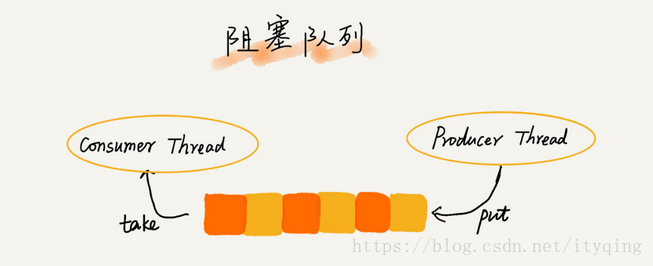
你应该已经发现了,上述的定义就是一个"生产者-消费者模型" !是的,我们可以使用阻塞队列,轻松实现一个"生产者-消费者模型" !这种基干阴寒队列实现的"生产者-消费者模型" ,可以有效地协调生产和消费的速度。当"生产 , 者"生产数据的速度过快, “消费者"来不及消费时,存储数据的队列很快就会满了。这个时候,生产者就阻塞等待,直到"消费者"消费了数据, “生产者"才会被唤醒继续"生产而且不仅如此,基于阻塞队列,我们还可以通过协调"生产者"和"消费者"的个数,来提高数据,的处理效率。比如前面的例子,我们可以多配置几个"消费者” ,来应对一个"生产者”
小结:
队列最大的特点就是先进先出,主要的两个操作是入队和出队。
它既可以用数组来实现,也可以用链表来实现。用数组实现的叫顺序队列,用链表实现的叫链式队列。
长在数组实现队列的时候,会有数据搬移操作,要想解决数据搬移的问题,我们就,需要像环一样的循环队列。要想写出没有bug的循环队列实现代码,关键要确定好队空和队满的,判定条件。
阻塞队列、并发队列,底层都还是队列这种数据结构,只不过在之上附加了很多其他功能。阻塞队列就是入队、出队操作可以阴寒,并发队列就是队列的操作多线程安全。
4、递归算法
一、什么是递归?
1.递归是一种非常高效、简洁的编码技巧,一种应用非常广泛的算法,比如DFS深度优先搜索、前中后序二叉树遍历等都是使用递归。
2.方法或函数调用自身的方式称为递归调用,调用称为递,返回称为归。
3.基本上,所有的递归问题都可以用递推公式来表示,比如
f(n) = f(n-1) + 1;
f(n) = f(n-1) + f(n-2);
f(n)=n*f(n-1);
二、为什么使用递归?递归的优缺点?
1.优点:代码的表达力很强,写起来简洁。
2.缺点:空间复杂度高、有堆栈溢出风险、存在重复计算、过多的函数调用会耗时较多等问题。
三、什么样的问题可以用递归解决呢?
一个问题只要同时满足以下3个条件,就可以用递归来解决:
1.问题的解可以分解为几个子问题的解。何为子问题?就是数据规模更小的问题。
2.问题与子问题,除了数据规模不同,求解思路完全一样
3.存在递归终止条件
四、如何实现递归?
1.递归代码编写
写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
2.递归代码理解
对于递归代码,若试图想清楚整个递和归的过程,实际上是进入了一个思维误区。
那该如何理解递归代码呢?如果一个问题A可以分解为若干个子问题B、C、D,你可以假设子问题B、C、D已经解决。而且,你只需要思考问题A与子问题B、C、D两层之间的关系即可,不需要一层层往下思考子问题与子子问题,子子问题与子子子问题之间的关系。屏蔽掉递归细节,这样子理解起来就简单多了。
因此,理解递归代码,就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤。
递归的关键是终止条件
五、递归常见问题及解决方案
1.警惕堆栈溢出:可以声明一个全局变量来控制递归的深度,从而避免堆栈溢出。
2.警惕重复计算:通过某种数据结构来保存已经求解过的值,从而避免重复计算。
六、如何将递归改写为非递归代码?
笼统的讲,所有的递归代码都可以改写为迭代循环的非递归写法。如何做?抽象出递推公式、初始值和边界条件,然后用迭代循环实现。
5、排序
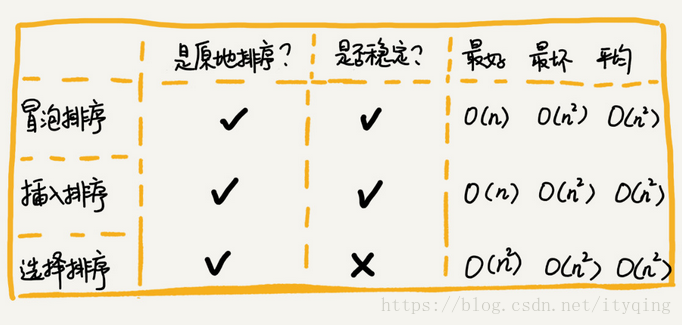
一、排序方法与复杂度归类
(1)几种最经典、最常用的排序方法:冒泡排序、插入排序、选择排序、快速排序、归并排序、计数排序、基数排序、桶排序。
(2)复杂度归类
冒泡排序、插入排序、选择排序 O(n^2)
快速排序、归并排序 O(nlogn)
计数排序、基数排序、桶排序 O(n)
二、如何分析一个“排序算法”?
<1>算法的执行效率
- 最好、最坏、平均情况时间复杂度。
- 时间复杂度的系数、常数和低阶。
- 比较次数,交换(或移动)次数。
<2>排序算法的稳定性 - 稳定性概念:如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
- 稳定性重要性:可针对对象的多种属性进行有优先级的排序。
- 举例:给电商交易系统中的“订单”排序,按照金额大小对订单数据排序,对于相同金额的订单以下单时间早晚排序。用稳定排序算法可简洁地解决。先按照下单时间给订单排序,排序完成后用稳定排序算法按照订单金额重新排序。
<3>排序算法的内存损耗
原地排序算法:特指空间复杂度是O(1)的排序算法。
常见的排序算法:
冒泡排序
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求,如果不满足就让它俩互换。

代码:
public int[] bubbleSort(int[] a) {
int n = a.length;
if (n<=1) {
return a;
}
for (int i = 0; i < n; i++) {
//提前退出冒泡循环的标志
boolean flag = false;
for (int j = 0; j < n-i-1; j++) {
if (a[j]>a[j+1]) {//
int temp = a[j];
a[j] = a[j+1];
a[j+1] = temp;
flag = true;//表示有数据交换
}
if (!flag) {
break; //没有数据交换(说明已排好序无需再进行冒泡),提前退出
}
}
}
return a;
}
四、插入排序
插入排序将数组数据分成已排序区间和未排序区间。初始已排序区间只有一个元素,即数组第一个元素。在未排序区间取出一个元素插入到已排序区间的合适位置,直到未排序区间为空。
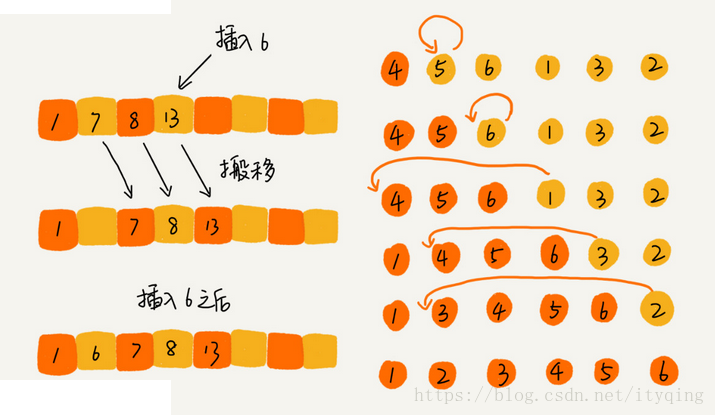
代码:
public int[] insertionSort(int[] a) {
int n = a.length;
if (n<=1) return a;
for (int i = 1; i < n; i++) {
int value = a[i];
int j = i-1;
for (; j >=0; j--) {
if (a[j] > value) {
a[j+1] = a[j];//移动数据
}else {
break;
}
}
a[j+1] = value;//插入数据
}
return a;
}
五、选择排序
选择排序将数组分成已排序区间和未排序区间。初始已排序区间为空。每次从未排序区间中选出最小的元素插入已排序区间的末尾,直到未排序区间为空。
代码:
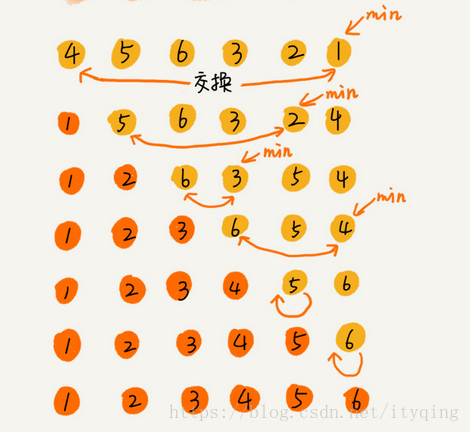
public int[] selectionSort(int[] a) {
int n = a.length;
for (int i = 0; i < a.length - 1; i++) {
for (int j = i+1; j < a.length; j++) {
//交换
if (a[i] > a[j]) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
}
return a;
}
六、归并排序
如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
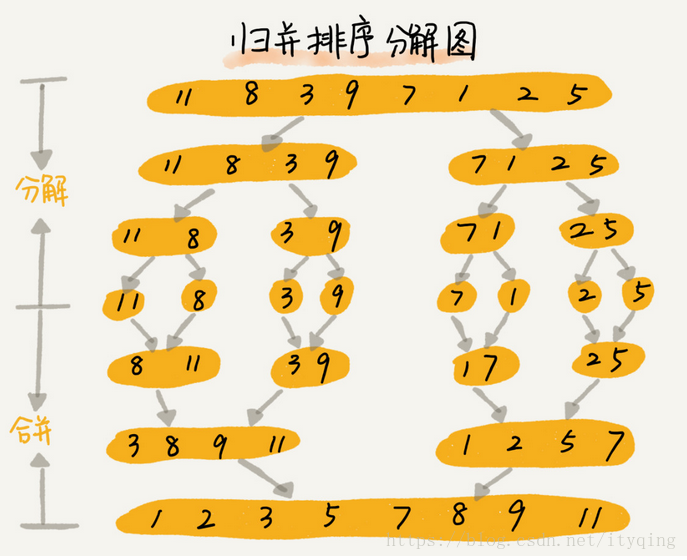
实现思路:
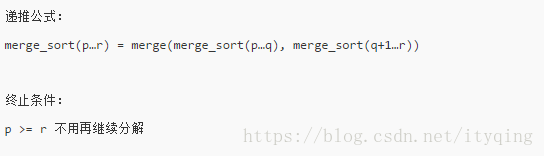
merge-sort(p…r)表示,给下标从p到r之间的数组排序。我们将这个排序问题转化为了两个子问 ,题, merge_sort(p…q)和merge-sort(q+1…r),其中下标q等于p和r的中间位置,也就是, (p+r)/2,当下标从p到q和从q+1到r这两个子数组都排好序之后,我们再将两个有序的子数组合并在一起,这样下标从p到r之间的数据就也排好序了。
代码:
// 归并排序算法, a是数组,n表示数组大小
public static void mergeSort(int[] a, int n) {
mergeSortInternally(a, 0, n-1);
}
// 递归调用函数
private static void mergeSortInternally(int[] a, int p, int r) {
// 递归终止条件
if (p >= r) return;
// 取p到r之间的中间位置q
int q = (p+r)/2;
// 分治递归
mergeSortInternally(a, p, q);
mergeSortInternally(a, q+1, r);
// 将A[p...q]和A[q+1...r]合并为A[p...r]
merge(a, p, q, r);
}
private static void merge(int[] a, int p, int q, int r) {
int i = p;
int j = q+1;
int k = 0; // 初始化变量i, j, k
int[] tmp = new int[r-p+1]; // 申请一个大小跟a[p...r]一样的临时数组
// 1 排序
while (i<=q && j<=r) {
if (a[i] <= a[j]) {
tmp[k++] = a[i++]; // i++等于i:=i+1
} else {
tmp[k++] = a[j++];
}
}
// 2 判断哪个子数组中有剩余的数据
int start = i;
int end = q;
if (j <= r) {
start = j;
end = r;
}
// 3 将剩余的数据拷贝到临时数组tmp
while (start <= end) {
tmp[k++] = a[start++];
}
// 4 将tmp中的数组拷贝回a[p...r]
for (i = 0; i <= r-p; ++i) {
a[p+i] = tmp[i];
}
}
merge是这样执行的:
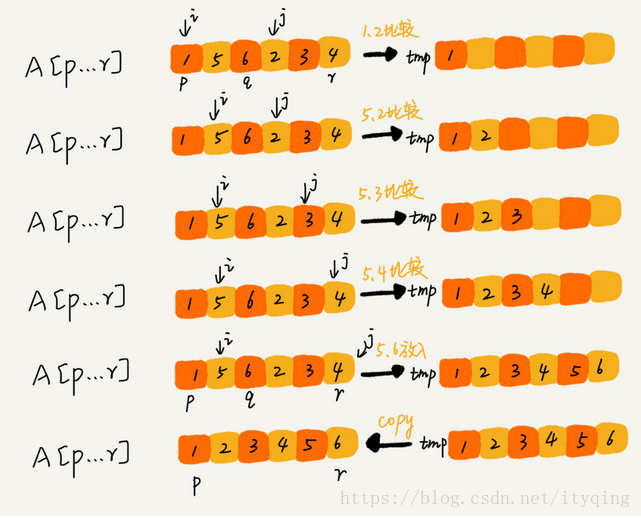
代码分析:


七、快速排序
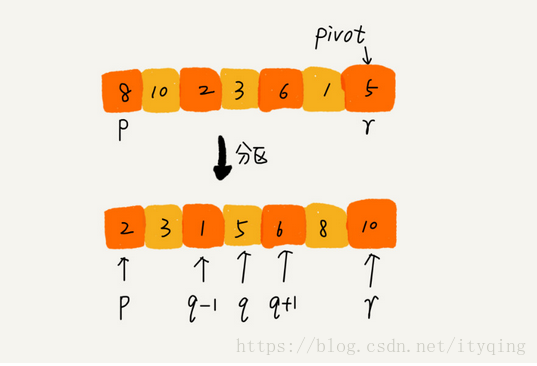
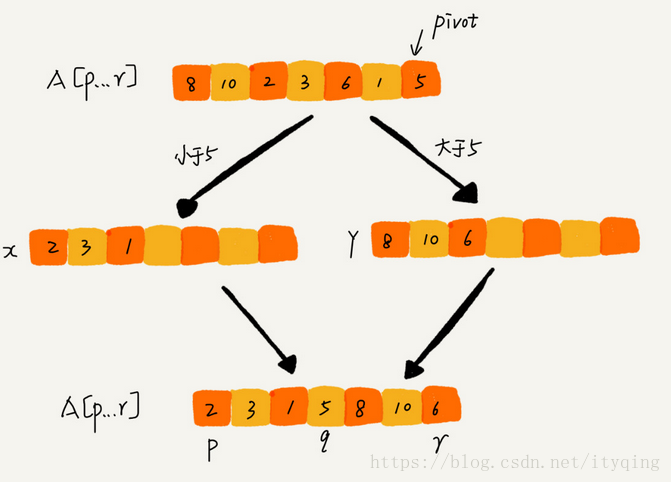
快排的思想: 如果要排序数组中下标从p到r之间的一组数据,我们选择p到r之间的任意一个数据作为pivot (分区点) 。我们遍历p到r之间的数据,将小于pivot的放到左边,将大于pivot的放到右边,将pivot放到中间。经过这一步骤之后,数组p到r之间的数据就被分成了三个部分,前面p到q-1之间都是小于pivot的,中间是pivot,后面的q+1到r之间是大于pivot的。
快排利用的分而治之的思想
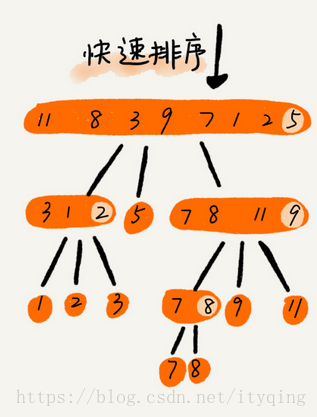
八、线性排序:
时间复杂度O(n)
我们把时间复杂度是线性的排序算法叫作线性排序(Linear sort)常见的线性算法有: 桶排序、计数排序、基数排序
特点:
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
八、线性排序:
时间复杂度O(n)
我们把时间复杂度是线性的排序算法叫作线性排序(Linear sort)常见的线性算法有: 桶排序、计数排序、基数排序
特点:
[外链图片转存中…(img-SFTUFLyE-1715563919499)]
[外链图片转存中…(img-E36GeLKk-1715563919499)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









