







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
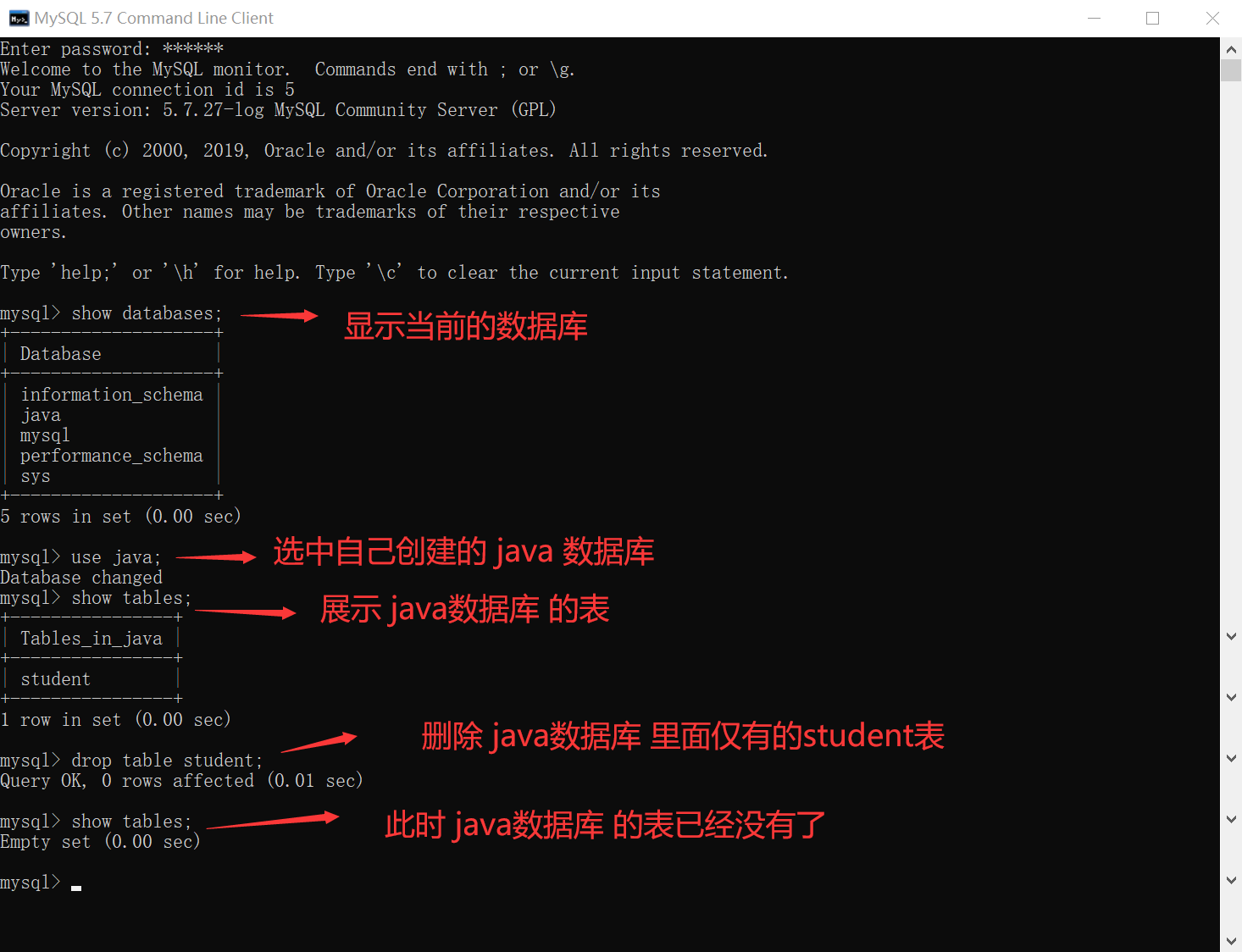
只留下自己创建的java数据库(自带的数据库肯定是不动的了)~~

一、数据库约束
所谓的约束~~
其实就是 数据库可以让程序员定义一些对数据的限制规则,数据库 会在 插入/修改数据的时候,会按照这些规则 对数据进行校验~~
如果校验不通过,就直接报错~~
约束的本质 就是让我们及时发现数据中的错误,更好的保证数据的正确性~~
1.1 约束类型
| not null | 指示某列不能存储 null值(即 该列是必填项) |
| unique | 保证某列的每行必须有唯一的值 |
| default | 规定没有给列赋值时的默认值 |
| primary key | not null 和 unique 的结合。确保某列(或两个列或多个列)有唯一标识,有助于更快速的找到 表中的一个特定的记录 |
| foreign | 保证一个表中的数据 匹配 另一个表中的值的参照完整性 |
| check | 保证列中的值符合指定的条件 |
1.2 null约束
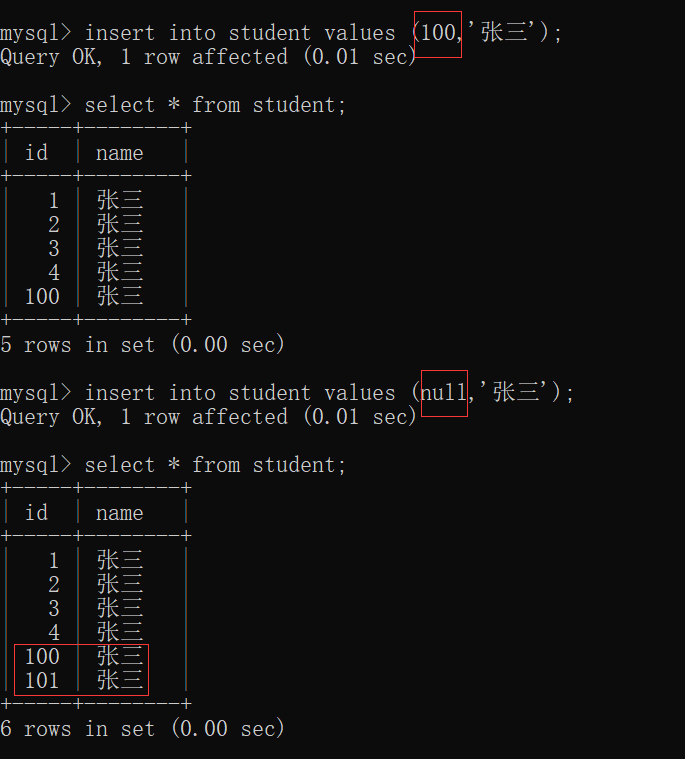
此时,先创建一张 student表:

这张表,初始情况下,没有任何的约束,允许为null:
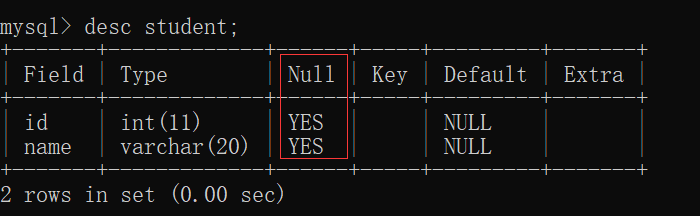
此时,我们完全可以插入空值:

但是,如果我们加上 not null,那么就不会插入成功了~~
删除上面所创建的 student表:
重新创建一个 student表(有约束条件 not null):
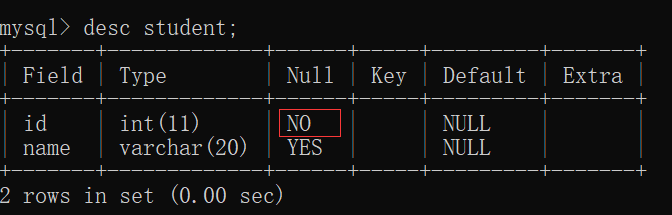
查看 student表 的结构,发现此时 id列不允许为空:
此时,如果再插入空值的时候,会提示报错:id列不允许为空值:
这个是由于创建 student表 的时候,在 id列 设置了 not null~~
使得在下面插入数据的时候,id列 不允许插入空值~~



1.3 unique约束
unique约束,是保证 唯一性约束~~
首先,删除 原来的 student表:
先创建一个普通的表(无任何约束):
插入多条相同的记录,发现插入记录都成功了:
此时,查询 student表 的全列数据:
可以看到的是,创建的是普通的表(无unique约束),
此时,是完全可以插入普通的数据的~~
默认情况下,表里的数据都是可以重复的~~




现在,重新创建一个 带有unique约束的 student表:
首先,删除上次创建的 普通student表:
接着,创建一个带有unique约束的 student表:
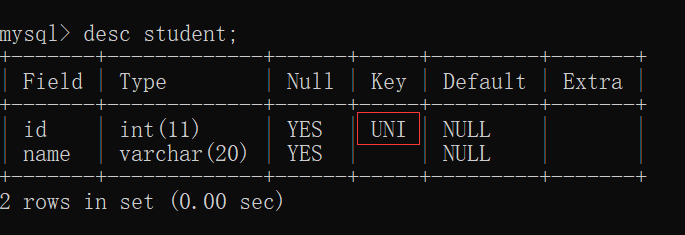
此时,观察 student表 的结构,发现id只能是唯一值:
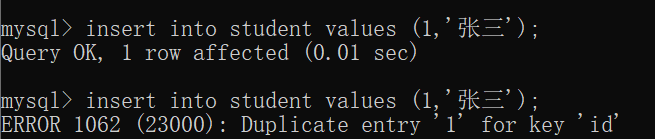
此时,向 student表里面 插入相同数据,会发现出错了(第一条插入没问题,第二条开始就出错了):
duplicate:重复~~
entry:条目~~


1.4 default约束
default约束,就是设定默认值~~
即 当我们插入数据的时候,如果不去指定,那么插入的时候就会自动去填写这个默认值~~
默认情况下的默认值,是null~~
可以通过 default约束 来修改默认的默认值~~
删除旧的 student表:
重新创建一张新的 student表(不加任何限制):
此时我们可以查看 student表 的结构:
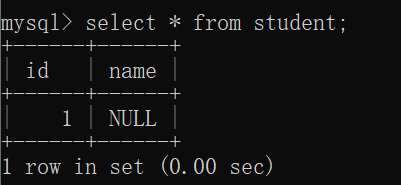
当我们对表进行指定列插入的时候,就会涉及到默认值的情况的:
此时,我们只针对 id列进行插入,那么 剩下的 name列 就按照默认值来走的:




那么,我们可以通过 default约束 来修改默认值~~
重新删除 student表:
创建一张带有 default约束 的 student表:
此时,可以查看表的结构:
那么,此时可以插入数据来观察:
当然,只插入name的话,id就是默认值:




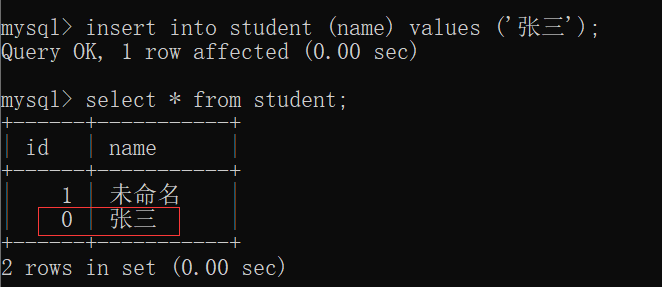
1.5 primary key 约束
primary key 约束,又叫做:主键约束~~
这是在设计表的时候,非常重要的一个列~~
主键表示一条记录的 “身份标识” ,用来区分 这条记录 和 其他的记录~~
主键的要求:
- 主键不能为空,相当于 not null
- 主键不能重复,相当于 unique
- 一个表里只能有一个主键
首先,删除 原来的 student表:
接着,创建一张带有主键的 student表(一般情况下 把 id 当作主键):
此时,可以查看 student表 的结构,会发现也出现了变化:
当插入数据的时候,
主键不允许为空值,同时主键必须唯一(这里的主键指的是 普通主键):





有的人可能会说:主键不能为空,而且必须是唯一的,
也就是说,主键必须填,而且还不能是重复的~~
那么以后填主键的时候,是不是还必须的要好好琢磨琢磨呢?
于是,MySQL为了方便大家填写主键,内置了一个功能 —— “自增主键” ,帮助我们自动生成主键的值,就不用程序员自己来保证了~~
从1开始,依次进行累加~~
自增主键 不是 普通主键,可以手动指定,也可自动生成~~
当我们填入一个具体值的时候,那就是手动指定;
当我们填入null的时候,那就是自动生成(按照自增规则)~~
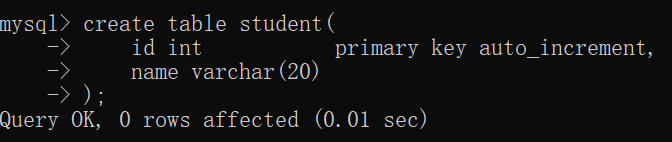
首先,删除原来的 student表:
接着,创建一张新的 student表(内含 自增主键,自增主键 不是普通主键):
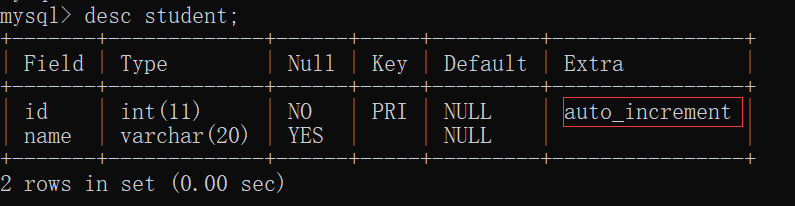
此时,查看 student表 的结构:
现在,插入一些数据:
自增规则:
MySQL要想自增,必须要能够记录下来当前 id已经到哪了~~
还要保证 自增 之后,得是不能重复的~~
MySQL里简单粗暴的做法,直接就是记录当前 自增主键 列里的最大值~~
这就能保证自增速度佷快。并且一定是不重复的~~

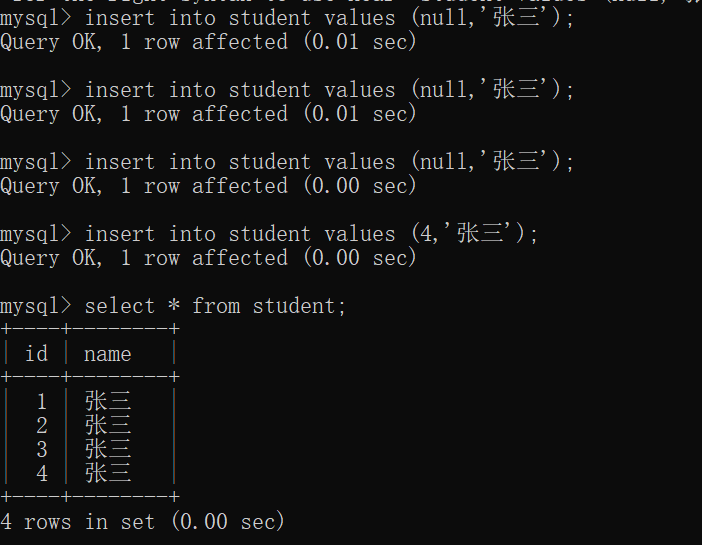
自增主键,主要就是用来生成一个唯一的 id,来保证不重复~~
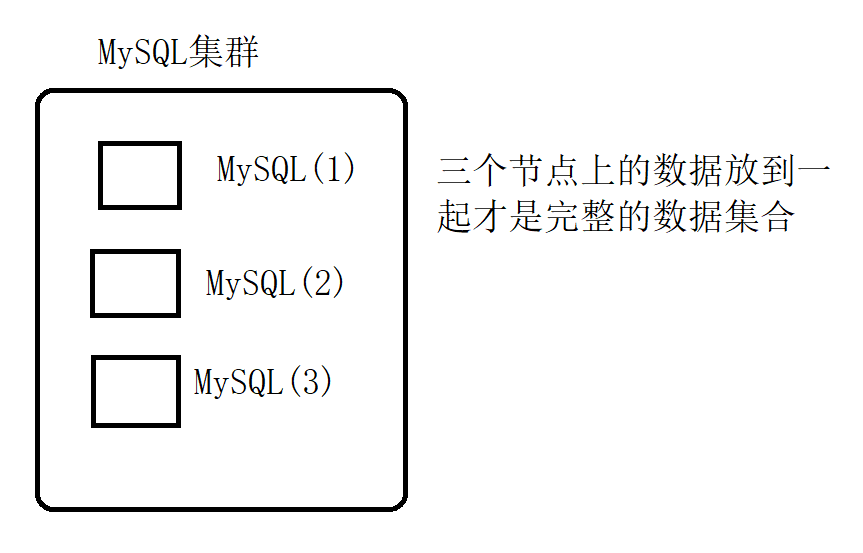
如果数据库是分布式部署的~~
这个时候自增主键就要带来问题的~~
分布式,即 数据量太大,一台机器存不下,就需要使用多台机器来存~~
如果只有一个MySQL数据库服务器,那么 肯定自己是知道 当前 id的最大值,也就容易生成下一个唯一的 id~~
但是,如果是分布式部署,有多台机器,就可能有一个MySQL集群了:
每一个MySQL节点只知道自己节点上的最大值,不知道其他节点上的最大值~~
换句话说,每一个MySQL数据库可以生成一个在自己节点上唯一的 id,但是不能保证 自己生成的 id和其他的几个节点的 id是不是重复的~~
但是,生成唯一 id这样的需求,是客观存在的,但是MySQL自增主键,已经难以满足要求了~~
一个典型的解决方案是:在生成 id的时候,让这些节点相互协商一下,彼此了解对方的情况之后,就能生成唯一的 id了;但是,这个方法的代价有点大(生成一个 id就需要交互一次)~~
聪明的程序员就想出了一些其他的办法~~
一个典型的思路:
唯一 id = 时间戳(ms) + 机房编号/主机编号 + 随机因子(随机数)
往数据库中不停的插入数据~~
每一次插入数据都需要一个唯一的 id~~
数据进入数据库肯定也是有先有后(不同的时间戳)~~
同一个时间戳之内,进入数据库的数据是有限的;使用时间戳 就已经能够区分出大部分的数据了~~
同一个时间戳进入的数据库的数据,又会分摊到不同的主机上~~
同一时间戳 并且 同一主机 的情况下,已经非常少了,再通过生成随机数的情况,就能够得到一个 分布式情况下的唯一 id,并且这种情况下的生成效率也非常高~~
通过上述情况,确实能生成 id,但是也会存在极端情况,导致出现的不唯一,但是出现的概率极低,在工程上忽略不计~~
未来我们见到的分布式唯一 id生成算法,核心思路就是上面这个公式~~
id不一定是数字,id本质就是字符串~~
1.6 foreign key 约束
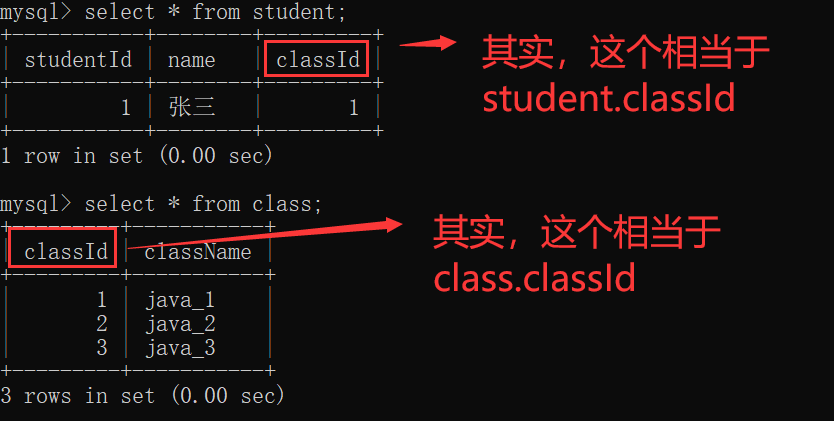
foreign key 约束,又称外键约束,描述了 两张表之间的关联关系~~
学生表 里面存储着 每个同学的信息(其中有一列是 班级编号);
班级表 里面存储着班级的具体信息~~
学生表中的每个同学的班级编号,需要在班级表中存在,如果不存在 就是非法数据!!!
其中,班级表 是负责约束的一方,称为 父表;
学生表 是被约束的一方,称为 子表~~
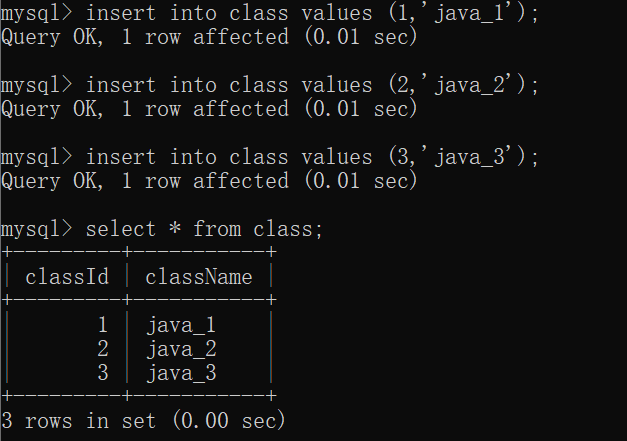
首先,删除原来的 student表:
接着,创建 class表 和 student表(具有外键约束关系):
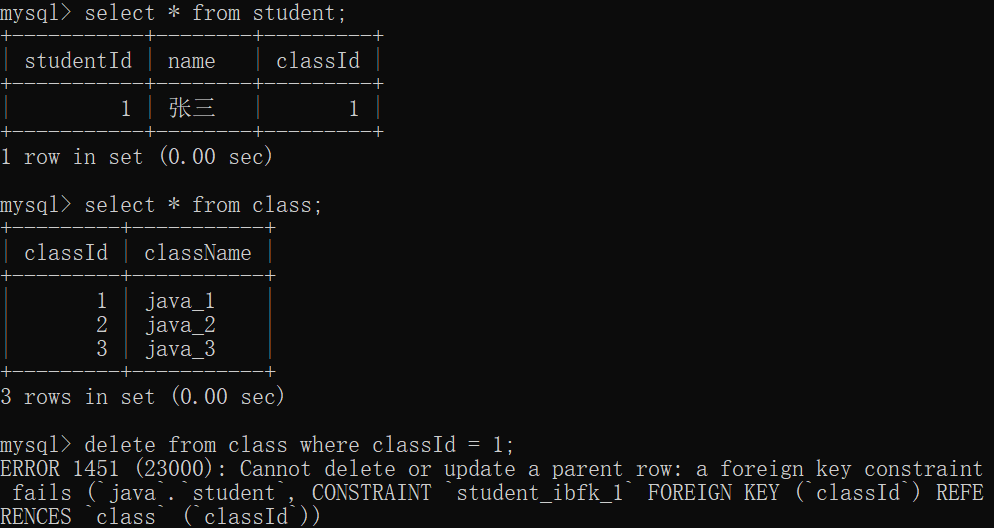
此时,我们可以看看 student表 的结构:
插入数据:
在父表为空的情况下,直接尝试往子表插入,就会报错!!!
如果向父表里面插入几条记录之后,再次尝试向子表里面插入数据:
如果 插入子表的数据(4)没有在父表的 classId(1,2,3)中,同样也会报错:
这就意味着 在外键约束下,每次 插入/修改操作,都会先触发在附表中的查询,父表中存在才能 插入/修改成功; 否则就会失败~~







注意:每次插入的时候都需要先查询,是否会非常拖慢执行效率?
确实如此!!!
但是也没有特别拖慢~~
如果查询操作 触发了遍历表,那么就是 低效的;
如果查询操作 触发了索引,那么此时就是 相对快不少了~~
建立外键约束的时候,MySQL就要求,引用的父表的列,必须是 主键,或者是 unique~~
而不管是 主键 还是 unique,都是自带索引的~~
注意:
俗话说,当你凝视深渊的时候,深渊也在凝视着你~~
父表虽然对子表产生了限制,但是反过来 子表对父表也有限制:
父表对子表的限制 是不能随意 插入/修改;
子表对父表的限制 是不能随意 修改/删除~~
由于在子表中 引入了 classId = 1 的记录~~
尝试删除父表中 的对应记录,就会发现 这个难以删除~~
场景:
电商~~
商品表(goodsId,name,price)
订单表(orderId,time,goodsId)
由实际情况得知,订单表里面的goodsId 需要在 商品表里面的goodsId存在(详情请参考 淘宝),那么 两张表之间存在 外键约束,且 商品表是父表,订单表是子表~~
如果,此时已经换季了,即 第一次买的时候觉得还挺好,过了一段时间后,想要再次买一次一样的商品,此时却发现该商品已经下架了~~
那么,提问:在外键约束条件下,如何把商品表里面的对应记录进行删除,同时又不影响订单表里面的记录(类似于 淘宝)?
实际上,可以使用 “假的删除” ,即 逻辑上删除,物理上还在(类似于操作系统删除磁盘上的数据——本质上就是把对应的盘块 给标记成无效,并不是真的把盘块上的数据给清空了),可以多搞一个 判断是否下架的字段,
如:
商品表(goodsId,name,price,ok)
约定 ok 为 1 的时候,表示商品在线;约定 ok 为 0 的时候,表示商品下线~~
需要下架商品的时候,并不是真的需要把这个记录给删掉,而只是把 ok 改为 0,并不影响外键约束~~
同时,在展示商品的时候,就可以基于 ok 做筛选,ok 值为 1 的时候 才进行展示~~
虽然,被 ok 设为 0 的商品,始终在磁盘上占着空间(这个和操作系统那个还不一样,操作系统那个 标记成无效磁盘以后,未来磁盘空间也可以重新利用起来),此时是无法被重新利用起来的,但是 并没有太大的影响,硬盘是非常便宜的~~
注意:
用外键关联的两个表,关联字段名完全一样是可以的:
就像 Java中的 类和对象 一样,两个类,是完全可以有两个相同的属性的~~
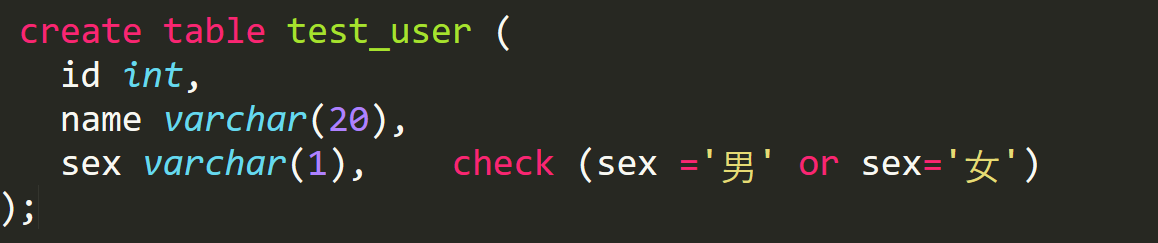
1.7 check约束(了解)
check约束,是一个非常好用的约束~~
它可以对表中的值做一个直接的限制~~
但是,在MySQL 5系列的数据库还不支持~~
注意:
在MySQL数据库中,check约束 和 外键约束 和其他的约束不同,在创建表的时候,约束的前面需要加上 逗号, 的,这个是固定的语法规定~~

二、表的设计
“设计” 比较高端,已经属于"哲学" 层次的东西了~~
根据一些实际的业务场景,来设计表;主要就是确定 有几个表,每个表有多少个字段~~
怎么来进行表的设计?
- 明确需求场景~~
- 提取出需求的场景,实体可以认为是"关键性的名词"~~
- 理清楚"实体"与"实体"之间的关系:一对一、一对多、多对多~~
不同的关系,在设计表的时候,有不同的套路!!!
2.1 “一对一”关系
以学校的教务系统来举例,
在教务系统里面,有许多的 “学生”,也有许多的 “账户” ,
此时,“学生” 和 “账户” 就是 “一对一” 的关系~~
一个 “学生” 只能有一个 “账户”,一个"账户"只能分配给一个"学生",这种关系就叫做 “一对一” 关系~~
此时的套路有:
第一种套路:把学生和账号,直接放到一个表里~~
如:student(id,name,account,password…)
第二种套路:把学生和账号 各自放到一个表里,然后使用一个额外的 id 来关联就可以了~~
如:
当然,第一种设计套路是下策的,
尤其是一个系统中包含不同身份角色的时候~~

2.2 “一对多”关系
同样, 以学校的教务系统来举例,
在教务系统里面,有许多的 “学生”,也有许多的 “班级” ,
此时,“学生” 和 “班级” 就是 “一对多” 的关系~~
一个 “学生” 只能属于一个 “班级”,但是一个"班级" 却可以包含多个"学生",这种关系就叫做 “一对多” 关系~~
第一种套路:
第二种套路:
都可以表示, 一个 “学生” 只能属于一个 “班级”,但是一个"班级" 却可以包含多个"学生"~~
但是,在MySQL中 没有"数组"这样的类型,所以说,第一种套路 是无法实现的(虽然可以使用 字符创拼接 的方式来凑合着实现,但是实际上是不好的设计,比较低效,也失去了数据库对于数据校验的一些能力)~~

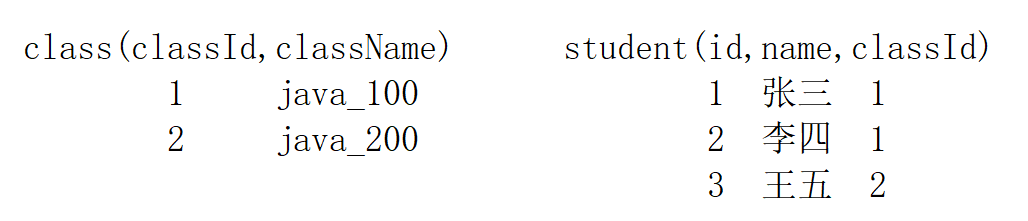
2.3 “多对多”关系
同样, 以学校的教务系统来举例,
在教务系统里面,有许多的 “学生”,也有许多的待选的 “课程” ,
此时,“学生” 和 “课程” 就是 “多对多” 的关系~~
一个 “学生” 可以选择多个 “课程”,同时一个"课程" 也可以 包含 多个"学生",这种关系就叫做 “一对多” 关系~~
一般就是采用一个中间表,来表示"多对多"的关系:

如果需求场景比较简单,很容易就能梳理其中的实体和关系~~
如果需求场景比较复杂,可能涉及到很多很多实体,很多很多组关系,就容易搞乱~~
聪明的程序员就发明了一个工具 —— E-R图(实体-关系图)~~
如果有兴趣的话,可以去搜集相关资料~~

三、新增
此时 会把查询的结果 作为 新增的数据~~
insert into 表名1 select 列名 from 表名2;
--先执行的是 查询操作 select 列名 from 表名2,
--查询出来的结果 插入到另外一个表1里
--当然,查询操作 也可以是上一篇博客里面的 基础查询操作~~
--我们需要保证 查询结果的临时表2的列数和类型 要和要插入的表1得匹配!!!
--不要求列名匹配~~
导入表的数据:
首先,还是需要把 java数据库里面的表都已经删除干净~~
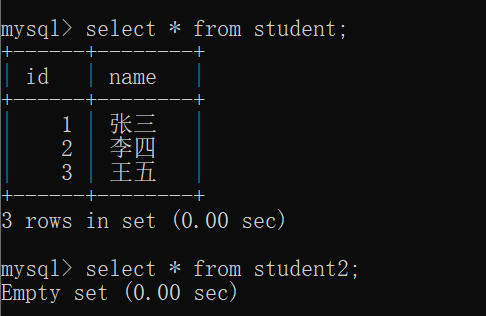
此时,可以创建一个 student表 并且插入一些相关的数据:
接着,再创建一个 student2表:
我们可以来看看 student表 和 student2表 里面的数据:
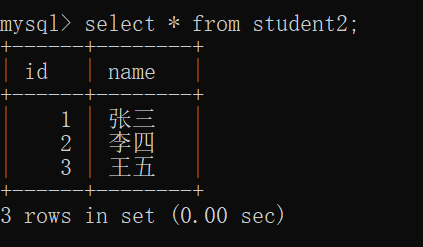
此时,我们可以用 student表 把数据导入到 student2表 里面:
最后,可以观察 student2表 里面的数据:



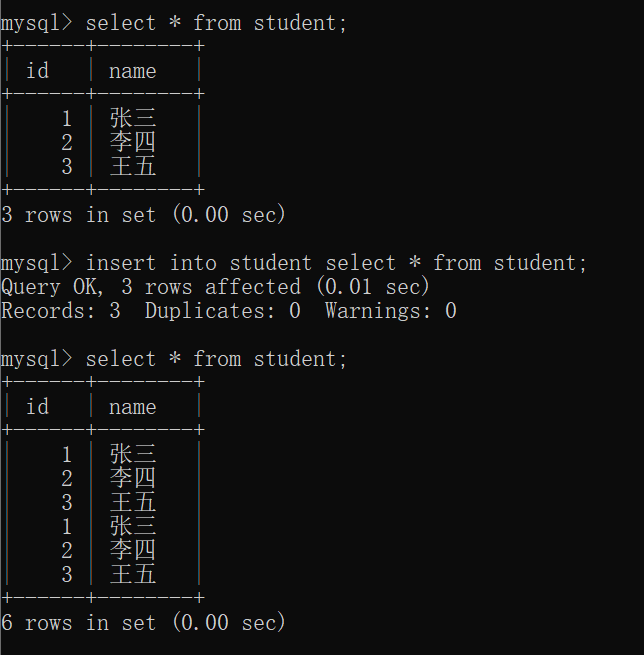
当然,自己也可以插入自己:

四、查询
4.1 聚合查询
4.1.1 聚合函数
如果说,之前介绍的 “表达式查询” 是把列和列之间进行一些运算处理;
那么 现在所要介绍的 “聚合查询” 就是通过行和行之间进行这样的运算~~
聚合查询,需要接着一些相关的聚合函数来进行查询,常见的聚合函数有:
| 聚合函数 | 说明 |
| count( [distinct] 表达式) | 返回查询到的数据的 数量 |
| sum( [distinct] 表达式) | 返回查询到的数据的 总和,不是数字没有意义 |
| avg( [distinct] 表达式) | 返回查询到的数据的 平均值,不是数字没有意义 |
| max( [distinct] 表达式) | 返回查询到的数据的 最大值,不是数字没有意义 |
| min( [distinct] 表达式) | 返回查询到的数据的 最小值,不是数字没有意义 |
distinct 去重~~
[ ] 可选项~~
聚合函数的用法基本上是一样的~~
count
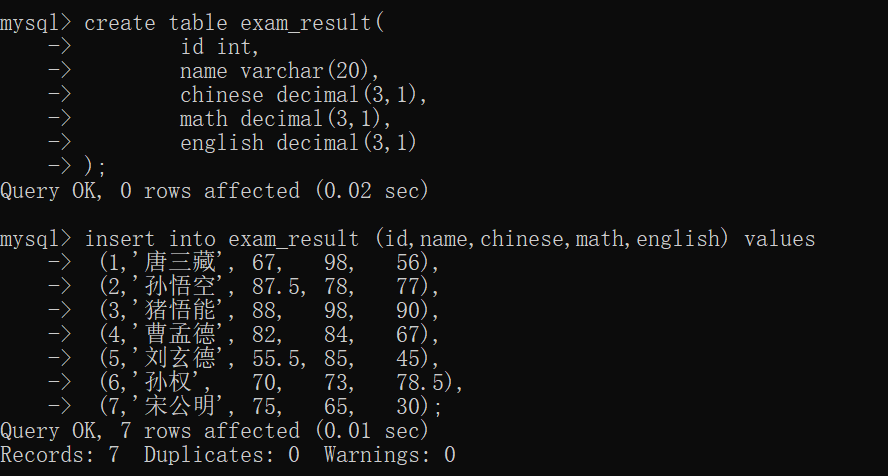
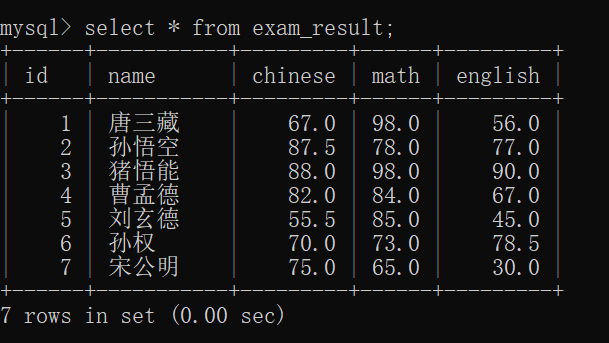
首先,我们需要来创建一张 exam_result表,并且插入一些数据:
接着,我们可以查看 exam_result表:
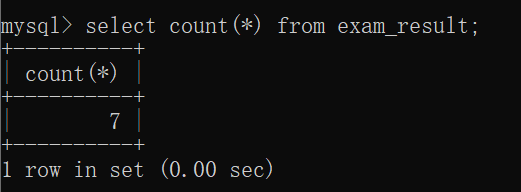
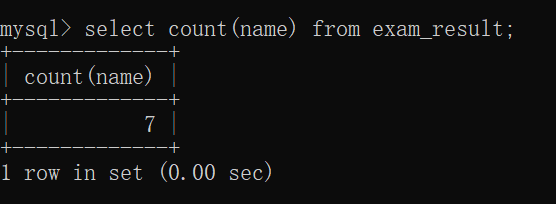
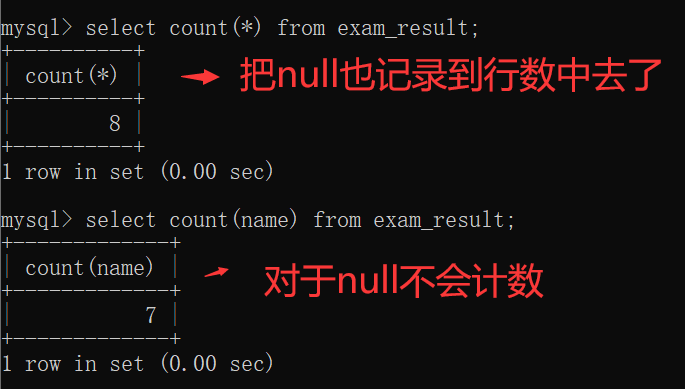
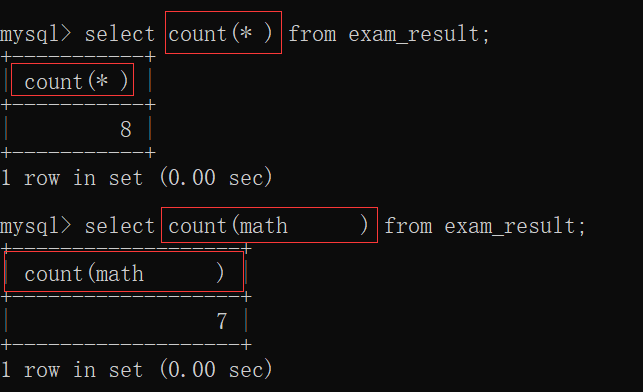
此时,我们可以用聚合函数count了:
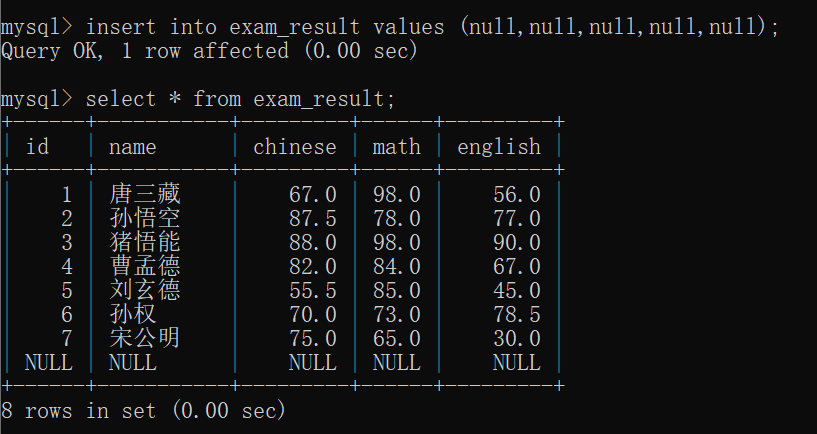
这里有一个小细节,当我们向 exam_result表 里面插入这样一条 全部都是null的记录:
此时,count(*)是把所有的记录都记录起来了,count(name)是把所有的非空记录都记录起来了:
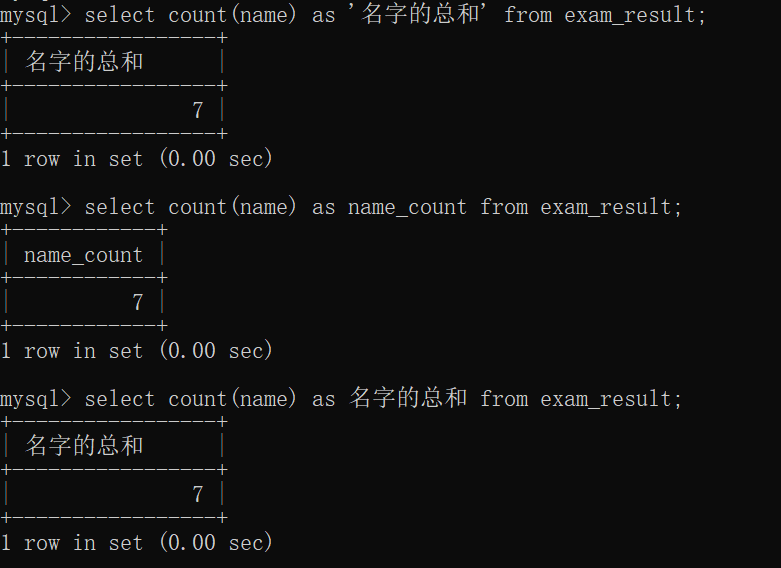
当然,别名啥的也是可以照常用的:
需要注意的是,count后面的括号 与 count 之间不允许有空格,否则就会报错:
但是,count后面的括号 里面 是可以存在空格的:

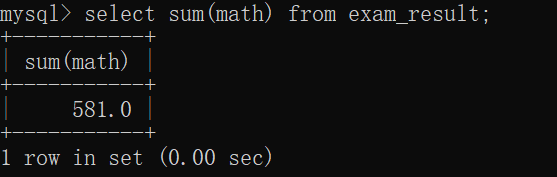
sum
从此可以看出,sum在运算的时候会自动忽略null而进行一系列运算~~
当然,此处的聚合查询,也是完全可以指定筛选条件的:
带有条件的 聚合查询,会先按照条件进行筛选~~
筛选后得到的结果,再进行聚合~~
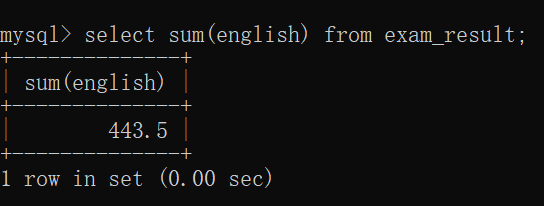
计算英语的总成绩:
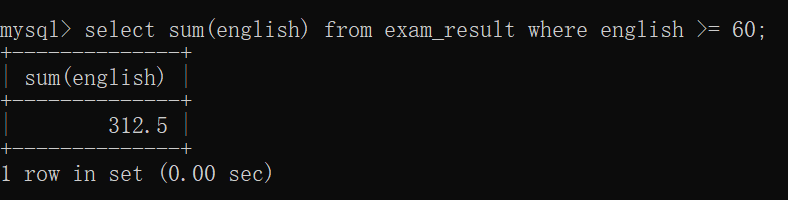
计算英语及格的同学的 英语总成绩:
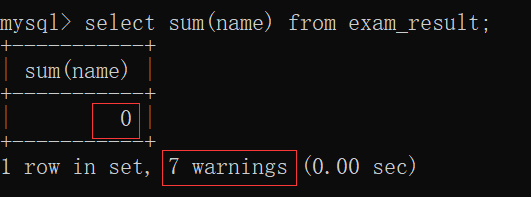
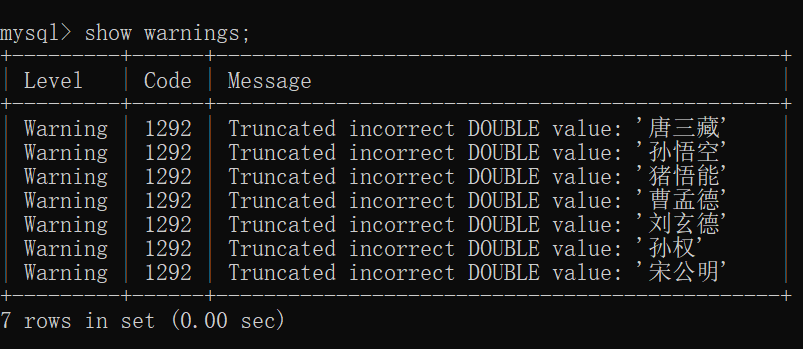
如果不是数字的话,那么计算结果就没有意义:
avg
平均值 = 总分/个数~~
此处的 个数 = 7~~
联想现在高中考试的时候,如果有个同学因为拉肚子而缺考了,那么老师在计算平均分的时候 肯定是不会把他计算过去的~~
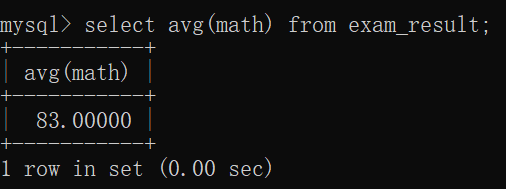

max
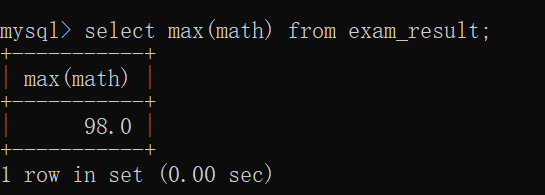
min
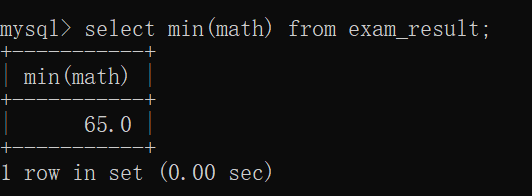
4.1.2 分组查询(group by 子句)
聚合查询 里面还有一个重要的操作:分组查询~~
把表中的若干行,分成好几组~~
指定某一列作为分组的依据~~
分组依据的列的值相同,则被归为一组~~
分成多个组之后,还可以针对每个组,分别使用聚合函数~~
使用 group by 进行分组查询时, select 指定的字段必须是 分组依据字段,其他字段若想出现在 select 中则必须包含在聚合函数中。
比如说,select指定的字段 不是 分组依据字段,查出来的结果不报错,但是查出来的结果 是无意义的结果~~
那些其它字段里面的值,如果不用聚合函数来操作的话,就是单纯查一列,得到的就是每一个分组里面的第一条记录~~
首先,把 java数据库里面的表删除:
接着,重新创建一个 student表,并且插入一些数据:
然后,我们就可以来看一看 student表 中的数据:
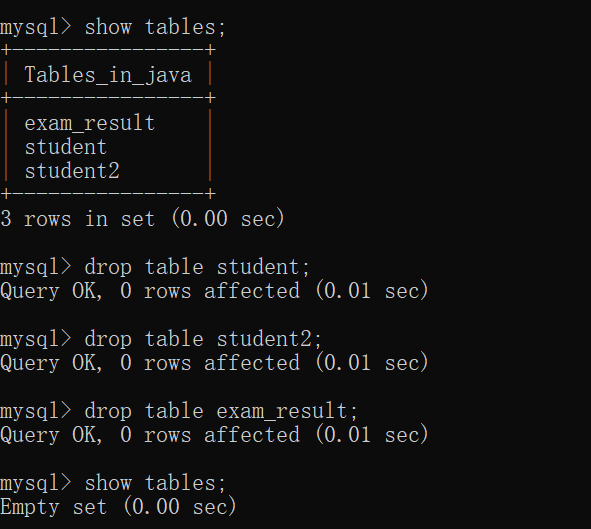

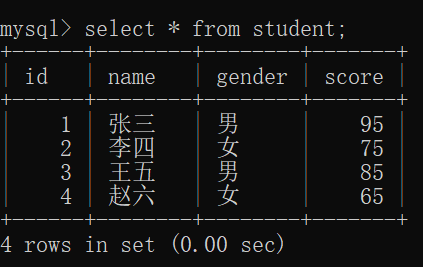
现在,我们就可以来试一试 分组查询了:
需要统计:男生 和 女生 各自的最高分、最低分、平均分~~
此时,根据性别,男生是一组,女神是一组;
然后再这两组里面,分别查出各自的最高分、最低分、平均分~~

4.1.3 having 子句
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 where 语句,而需要用having~~
在进行聚合查询的时候,也能指定条件筛选:
- 在聚合之前,进行筛选,针对筛选之后的结果,再聚合筛选(使用 where 子句 限制条件)
- 在聚合之后,进行筛选 (使用 having 子句 限制条件)
- 同时在前面和后面都筛选(where 子句 + having 子句)
聚合之前筛选:
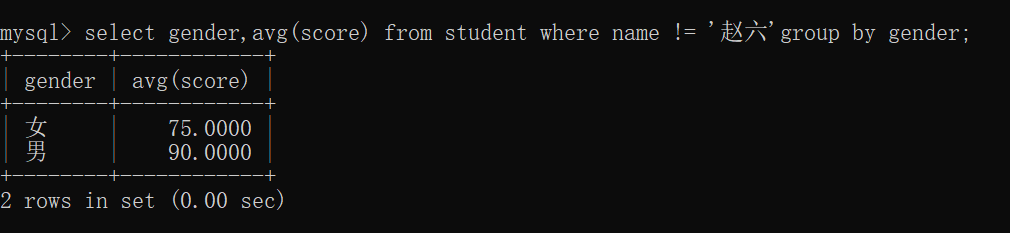
查询每个性别平均分,但是除去赵六同学(先把 赵六 排除掉,再聚合筛选)~~
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
若想出现在 select 中则必须包含在聚合函数中。**
比如说,select指定的字段 不是 分组依据字段,查出来的结果不报错,但是查出来的结果 是无意义的结果~~
那些其它字段里面的值,如果不用聚合函数来操作的话,就是单纯查一列,得到的就是每一个分组里面的第一条记录~~
首先,把 java数据库里面的表删除:
接着,重新创建一个 student表,并且插入一些数据:
然后,我们就可以来看一看 student表 中的数据:
现在,我们就可以来试一试 分组查询了:
需要统计:男生 和 女生 各自的最高分、最低分、平均分~~
此时,根据性别,男生是一组,女神是一组;
然后再这两组里面,分别查出各自的最高分、最低分、平均分~~
4.1.3 having 子句
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 where 语句,而需要用having~~
在进行聚合查询的时候,也能指定条件筛选:
- 在聚合之前,进行筛选,针对筛选之后的结果,再聚合筛选(使用 where 子句 限制条件)
- 在聚合之后,进行筛选 (使用 having 子句 限制条件)
- 同时在前面和后面都筛选(where 子句 + having 子句)
聚合之前筛选:
查询每个性别平均分,但是除去赵六同学(先把 赵六 排除掉,再聚合筛选)~~
[外链图片转存中…(img-eEYO08Ut-1715725396009)]
[外链图片转存中…(img-F9tDhzvm-1715725396010)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 2643
2643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









