







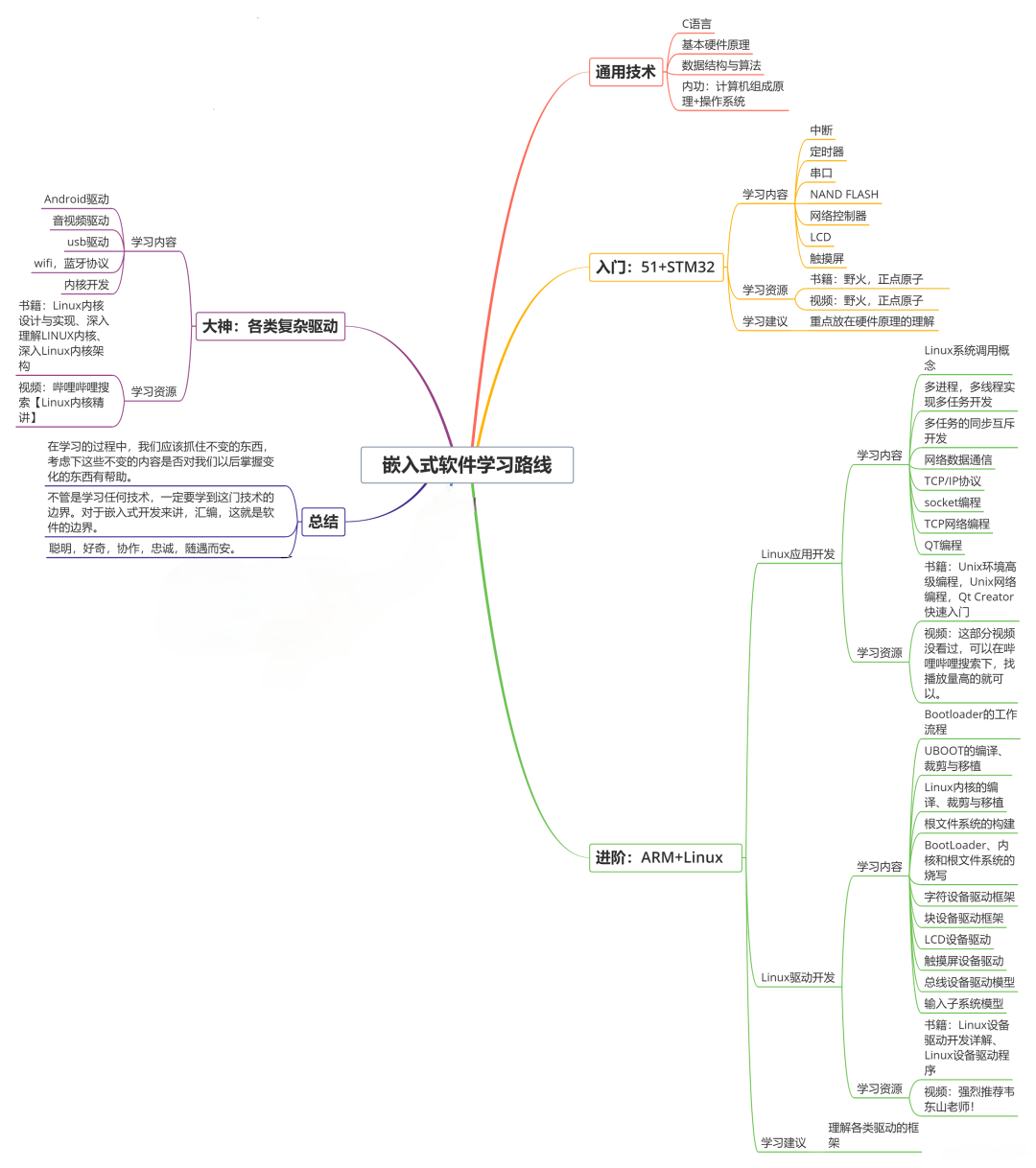
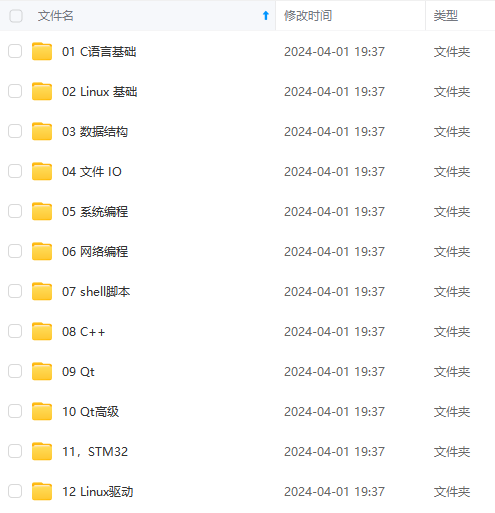
收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
+ - [1. 首页](#1__315)
- [2. 职位列表](#2__322)
- [3. 薪水分析](#3__355)
- [4. 职位描述词云](#4__405)
- [5. app.py文件代码](#5_apppy_414)
猎聘网信息爬取

- 爬取猎聘网信息是为了完成需求分析这门课的作业
- 哎,为了完成作业,五天入门python爬虫,找了个视频就开始了,学习笔记如下爬取豆瓣笔记
- 这篇博客用来记录,爬取猎聘网的整个过程
- 爬取过程整体分为三个过程:
- 爬取职位链接
- 爬取职位详情信息
- 可视化信息统计
爬取职位链接
1. 构建URL:
https://www.liepin.com/zhaopin/?compkind=&dqs=010&pubTime=&pageSize=40&salary=&compTag=&sortFlag=&compIds=&subIndustry=&jobKind=&industries=&compscale=&key=%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98&siTag=LiAE77uh7ygbLjiB5afMYg%7EfA9rXquZc5IkJpXC-Ycixw&d_sfrom=search_fp&d_ckId=cd34a20d8742a36fa58243aee1ca77fe&d_curPage=0&d_pageSize=40&d_headId=cd34a20d8742a36fa58243aee1ca77fe
- https://www.liepin.com:域名
- /zhaopin/:网站前缀
- ?:问号后面接参数
- 这里我们要爬取关键词为“数据挖掘”各个地区的职位信息来分析,所以要分析的关键词为(key),和地区参数(dqs)以&相连
- 参考上述URL:(key=%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98),后面一串乱码是因为汉字在作为关键词时要序列化
- 因为这里用urllib这个包来获取网页,所以要把汉字序列化,如果使用requests包来获取就不用
- 调用(urllib.parse.quote(“数据挖掘”, ‘utf-8’))这个函数来序列化汉字
参考代码如下
def main():
job_list = []
key = "数据挖掘"
dqs = ["010", "020", "050020", "050090", "030", "060080", "040", "060020", "070020", "210040", "280020", "170020"]
new_key = urllib.parse.quote(key, 'utf-8')
for item in dqs:
url = "https://www.liepin.com/zhaopin/?key="+new_key+"&dqs="+item
print(url)
# 获取职位列表链接
job_html = get_job_html(url)
# 解析网页分析网页得到链接
link_list = get_job_link(job_html)
# 把链接储存到数组中
for i in link_list:
job_list.append(i)
# 保存职位链接到表格中
save_link(job_list)
2. 获取网页
- 这里获取网页调用一个包:(from fake_useragent import UserAgent)
- 需要在pip中安装:pip install fake_useragent
- 首先要构造一个请求头:猎聘网的反爬虫不是很强大,不用登录就可以访问,调用UserAgent().random 可以随机生成浏览器标识,这样就不会被阻止
- 如果网站的反扒做的很好就要在网页的请求头上添加相应的参数,参考如下图

参考代码:
def get\_job\_html(url):
print("-------爬取job网页-------")
html = ""
head = {
"User-Agent": UserAgent().random
}
"""
head:模拟浏览器头部信息
"User-Agent":浏览器标识
"""
request = urllib.request.Request(url=url, headers=head)
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except Exception as e:
return None
return html
3. 解析网页
- 分析网页元素获取数据

- 由于每一个页面只有40条数据,所以要实现自动获取获取下一页链接,来实现自动爬取,找到网页种的元素(下一页)获取下一页的链接,实现递归爬取

参考代码如下
def get\_job\_link(html):
job_link = []
# 解析网页得到链接
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('h3'):
if item.has_attr("title"):
# 抽取链接内容
link = item.find_all("a")[0]["href"]
job_link.append(link)
print(link)
try:
find_next_link = soup.select(".pager > div.pagerbar > a")[7]['href']
if find_next_link == "javascript:":
return job_link
# 拼接上域名
find_next_link = "https://www.liepin.com" + str(find_next_link).replace('°', '0')
print(find_next_link)
# 获取到下一个网页的数据
next_html = get_job_html(find_next_link)
# 解析网页
if next_html is not None:
next_link = get_job_link(next_html)
for link in next_link:
job_link.append(link)
except Exception as e:
print(e)
finally:
return job_link
4. 保存数据到表格
- 表格操作很简单,就不赘述
def save\_link(link_list):
work_book = xlwt.Workbook(encoding="utf-8", style_compression=0)
work_sheet = work_book.add_sheet("job\_link", cell_overwrite_ok=True)
col = "Link"
work_sheet.write(0, 0, col)
for i in range(0, len(link_list)):
print("第%d条" % i)
data = link_list[i]
work_sheet.write(i+1, 0, str(data))
work_book.save("job\_link.xls") # 保存数据
爬取职位详情信息
- 获取到职位链接后保存在表格中,下一步就是访问这个些链接,爬取到详细信息,并保存到数据库中
- 爬取开始就发现有链接的规律,有两种链接,第一种是正常的可以直接访问的,还有一种没有添加域名的,所以我们有加上域名

1. 基本步骤
- 获取表格中的链接
- 获取网页
- 解析网页
- 保存数据
基本框架的搭建:
def main():
# 读取表格链接
links = read_excel_get_link()
# 获取链接网页
for i in range(0, len(links)):
if links[i][0] != 'h':
links[i] = "https://www.liepin.com" + links[i]
print(links[i])
# 获取网页
message_html = getLink.get_job_html(links[i])
if message_html is not None:
# 解析数据
message_data = get_message_data(message_html)
else:
continue
# 保存一条数据
try:
save_datas_sql(message_data)
except Exception as e:
continue
2. 获取表格链接
- 表格操作不在赘述
def read\_excel\_get\_link():
links = []
# 读取表格链接数据
# 打开表格
work_book = xlrd.open_workbook("job\_link.xls")
# 获取sheet
sheet = work_book.sheet_by_index(0)
for i in range(1, sheet.nrows):
link = sheet.cell(i, 0).value
links.append(link)
return links
3. 获取职位详情信息网页
message_html = getLink.get_job_html(links[i])
- 调用上面获取职位链接时的函数:get_job_html
4. 解析详情网页得到数据
- 解析网页,获取到页面的元素:
- 职位名称
- 公司
- 薪水
- 职位描述

参看网页的元素:

- 使用标签选择器来定位元素
- 在爬取过程中有时会遇到一些转义字符的问题需要注意
参考代码
def get\_message\_data(html):
data = []
soup = BeautifulSoup(html, "html.parser")
try:
# 岗位名称
title = soup.select(".title-info > h1")[0]['title']
data.append(title)
# 公司
company = soup.select(".title-info > h3 > a")
if len(company) != 0:
company = company[0]['title']
else:
company = " "
data.append(company)
# 薪水
salary = soup.select(".job-title-left > p")
if len(salary) != 0:
salary = salary[0].contents[0]
else:
salary = " "
salary = salary \
.replace('\n', '') \
.replace('\t', '') \
.replace('\r', '') \
.replace(' ', '') \
.replace('"', '')
data.append(salary)
# 描述
description = soup.select(".content.content-word")
if len(description) != 0:
all_des = description[0].contents
description = " "
for item in all_des:
if type(item) == bs4.element.NavigableString:
# print(item)
description = description + item
# print(description)
else:
description = " "
description = description \
.replace('\n', '') \
.replace('\t', '') \
.replace('\r', '') \
.replace(' ', '') \
.replace('"', '')
data.append(description)
except Exception as e:
print(e)
finally:
print(data)
return data
5. 保存数据到数据库
- 使用sqlite3数据库可以很好的储存数据 ,也方便查询数据
创建数据库代码
# 建表语句
def init\_job\_sqlite():
connet = sqlite3.connect("job\_message.db") # 打开或创建文件
# 建表
c = connet.cursor() # 获取游标
sql = '''
create table if not exists job\_message(
id integer not null primary key autoincrement,
title text not null,
company text,
salary text,
description text
)
'''
c.execute(sql) # 执行sql语句
connet.commit() # 提交
connet.close() # 关闭数据库
插入数据到数据库中实现数据的储存
def save\_datas\_sql(data):
init_job_sqlite() # 初始化数控库
# 插入数据
connet = sqlite3.connect("job\_message.db") # 打开或创建文件
c = connet.cursor() # 获取游标
for index in range(0, 4):
data[index] = '"' + data[index] + '"'
sql = '''
insert into job\_message(title,company,salary,description)
values(%s)''' % ",".join(data)
c.execute(sql)
connet.commit()
可视化职位信息
- 这里使用flask框架搭建一个简单网站实现数据的可视化
- 首先在网上随便找一个网页模板下载下来:参考下载网站
1. 首页
- 一些前端展示,这里不在赘述
- 在这里贴上我的文件结构

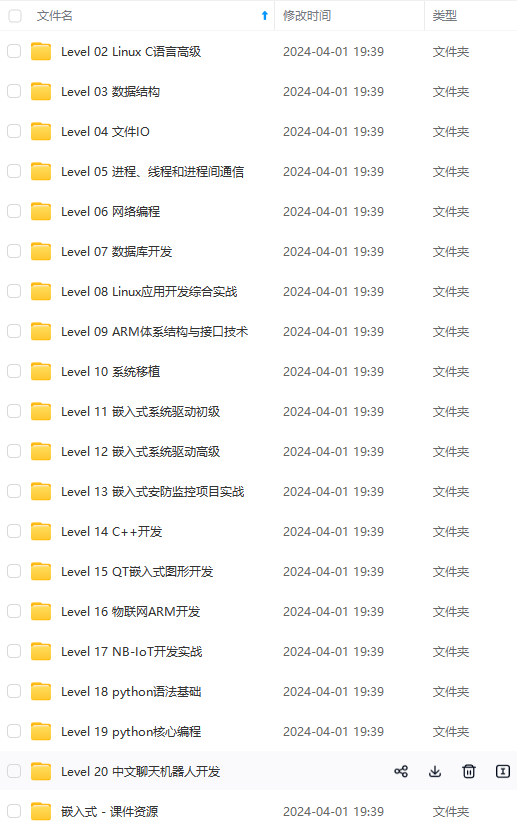
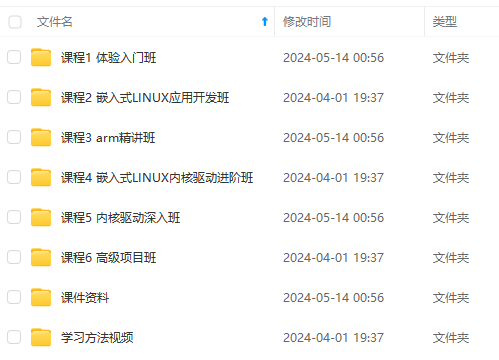
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新
ZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQzMzA5OTA3,size_16,color_FFFFFF,t_70#pic_center)
[外链图片转存中…(img-gT86RBY1-1715625644351)]
[外链图片转存中…(img-NWcWM1NO-1715625644352)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









