







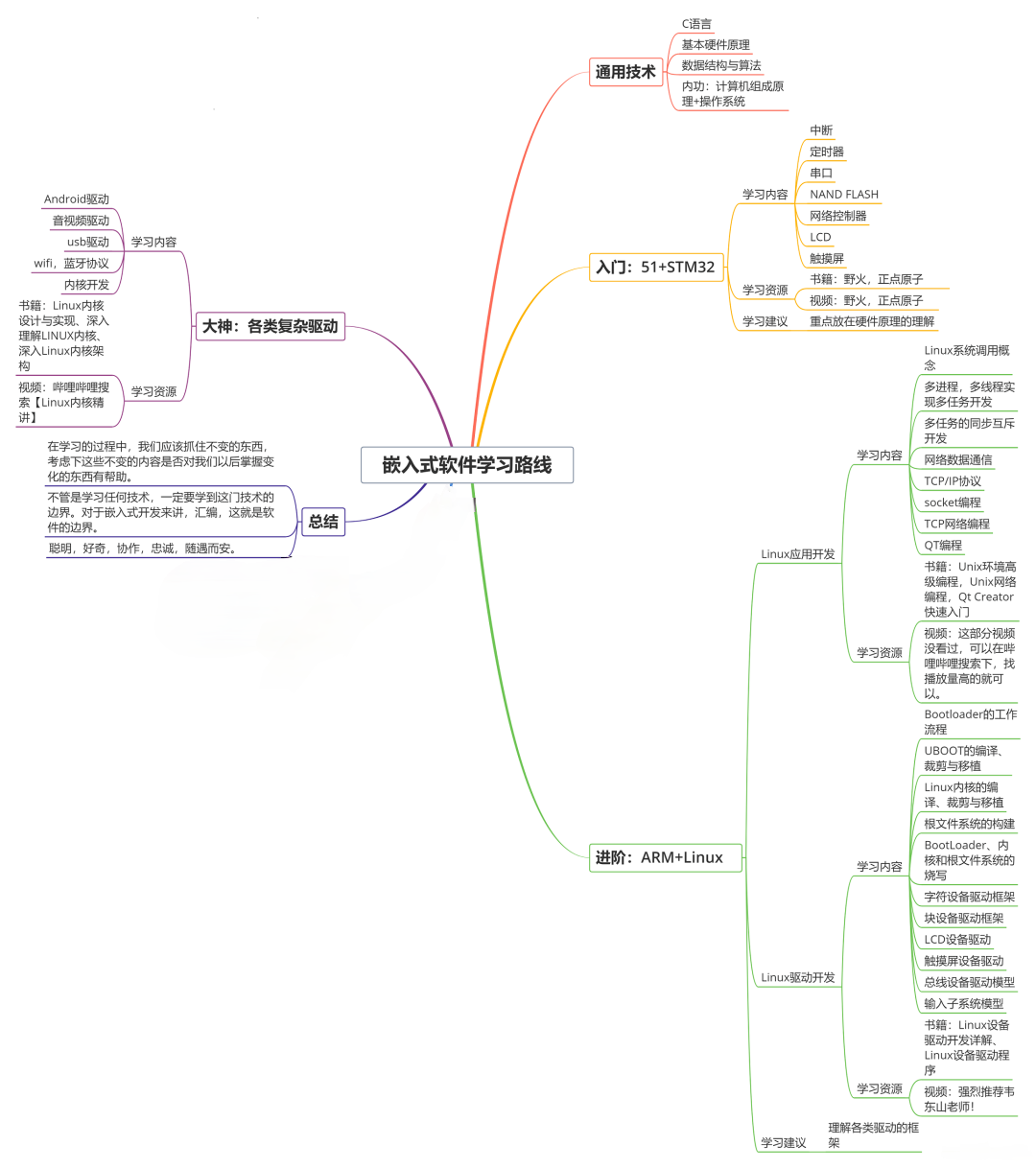
收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
*char2存储于 栈(数组名就是首元素的地址,也就是 char 是地址,*char2 相当于对 cahr2 进行解引用,找到它的内容,那么它的内容是存储在栈上面的)
pChar3存储于 栈(pChar3 是一个指针变量,这个指针变量是在栈上面开的)
*pChar3存储于 代码段(pChar3 是一个指针变量,它存的是一个地址,它指向常量区的字符串 “a b c d”,*pChar 就是对这个指针变量解引用,找到了它的内容,也就是 “abcd” ,所以它是存在代码段的)
ptr1存储于 栈
*ptr1存储于 堆
2、填空题:

答案:
注意:sizeof 是求字节大小,strlen 是求字符串长度的。
sizeof(num1) = 40(算对象占用空间的大小)
sizeof(char2) = 5(char2 是一个字符数组,求大小要计算 ‘\0’)
sizeof(pChar3) = 4/8(指针在 32 位平台大小是 4,64 位平台大小是 8)
sizeof(ptr1) = 4/8
strlen(char2) = 4(char2 是一个字符数组,求长度不计算 \0)
strlen(pChar3) = 4
我们再来看一张 C/C++中程序内存区域划分 的图:
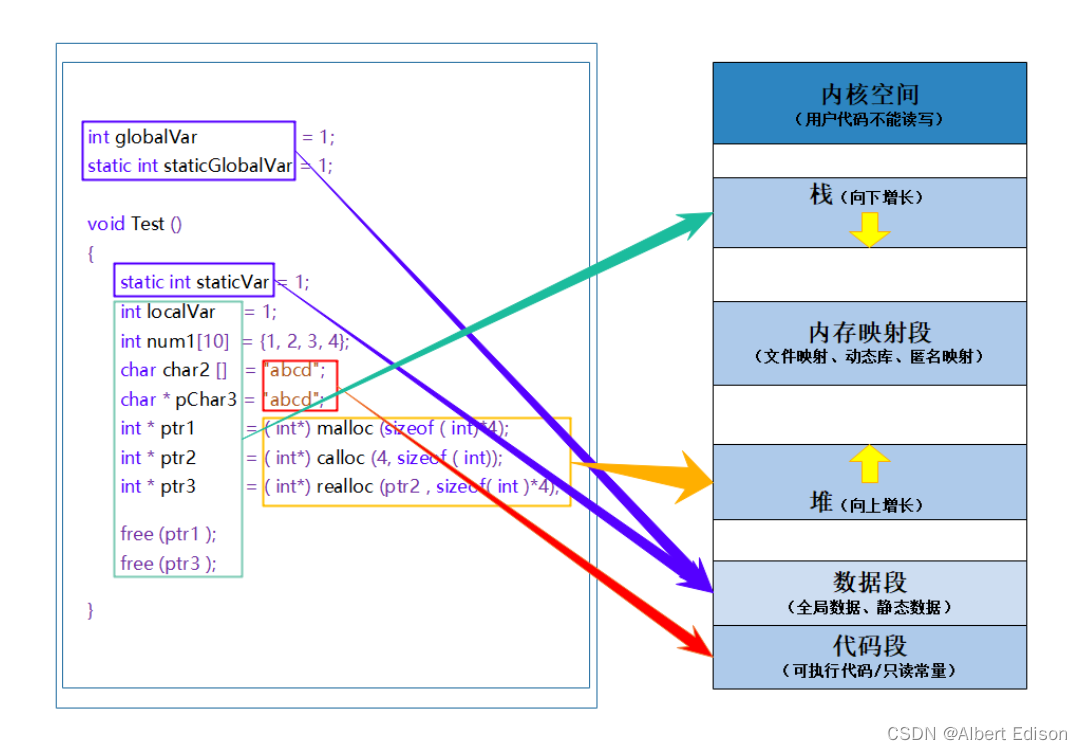
名词解释:
- 栈 又叫堆栈,用于存储 非静态局部变量、函数参数、返回值 等等,栈是向下增长的。
- 内存映射段 是高效的 I/O 映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享内存,做进程间通信。
- 堆 用于存储运行时动态内存分配,堆是向上增长的。
- 数据段 又叫静态区,用于存储全局数据和静态数据。
- 代码段 又叫常量区,用于存放可执行的代码和只读常量。
注意:为什么说栈是向下增长的,而堆是向上增长的?
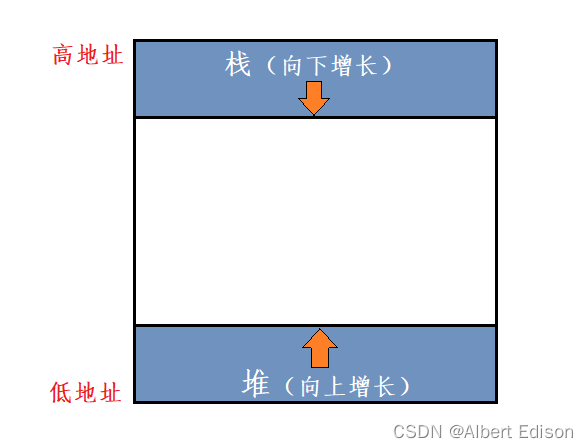
因为,一般情况下,在栈区开辟空间,先开辟的空间地址较高,而在堆区开辟空间,先开辟的空间地址较低。
例如,下面代码中,变量 a 和变量 b 存储在栈区,指针 c 和指针 d 指向堆区的内存空间:
#include <iostream>
using namespace std;
int main()
{
//栈区开辟空间,先开辟的空间地址高
int a = 10;
int b = 20;
cout << &a << endl;
cout << &b << endl;
//堆区开辟空间,先开辟的空间地址低
int\* c = (int\*)malloc(sizeof(int) \* 10);
int\* d = (int\*)malloc(sizeof(int) \* 10);
cout << c << endl;
cout << d << endl;
return 0;
}
我们可以运行上面的代码,可以看出,a 和 b 的地址是大于 c 和 d 的地址
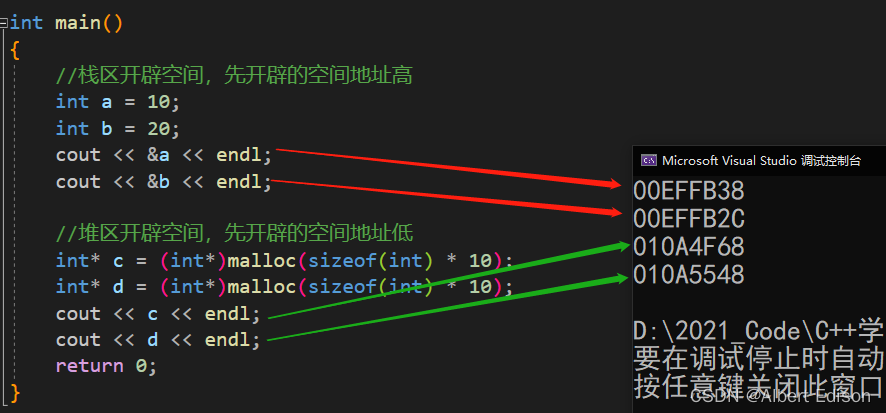
因为在栈区开辟空间,先开辟的空间地址较高,所以打印出来 a 的地址大于 b 的地址;
在堆区开辟空间,先开辟的空间地址较低,所以 c 指向的空间地址小于 d 指向的空间地址。
注意:
在堆区开辟空间,后开辟的空间地址不一定比先开辟的空间地址高。
因为在堆区,后开辟的空间也有可能位于前面某一被释放的空间位置。
2. C语言内存管理方式
(1)malloc
malloc 函数的功能是开辟指定字节大小的内存空间,如果开辟成功就返回该空间的首地址,如果开辟失败就返回一个 NULL(空指针)。
它使用的时候,传参只需传入需要开辟的字节个数。

(2)calloc
calloc 函数的功能也是开辟指定大小的内存空间,如果开辟成功就返回该空间的首地址,如果开辟失败就返回一个 NULL(空指针)。
calloc 函数传参时需要传入开辟的内存用于存放的元素个数和每个元素的大小。
calloc 函数开辟好内存后会将空间内容中的每一个字节都初始化为 0。

(3)realloc
realloc 函数可以调整已经开辟好的动态内存的大小,第一个参数是需要调整大小的动态内存的首地址,第二个参数是动态内存调整后的新大小。
realloc 函数与上面两个函数一样,如果开辟成功便返回开辟好的内存的首地址,开辟失败则返回 NULL(空指针)。
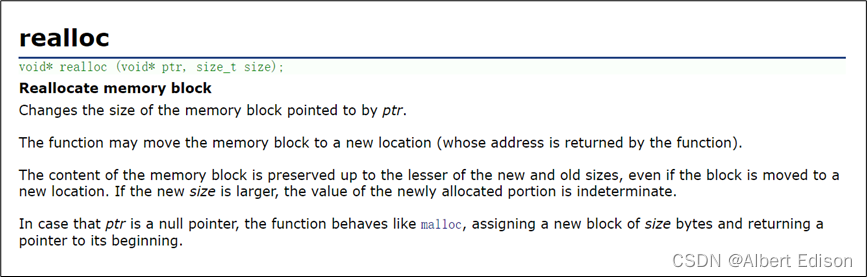
注意:realloc 函数调整动态内存大小的时候会有三种情况:
- 原地扩。需扩展的空间后方有足够的空间可供扩展,此时,realloc 函数直接在原空间后方进行扩展,并返回该内存空间首地址(即原来的首地址)。
- 异地扩。需扩展的空间后方没有足够的空间可供扩展,此时,realloc 函数会在堆区中重新找一块满足要求的内存空间,把原空间内的数据拷贝到新空间中,并主动将原空间内存释放(即还给操作系统),返回新内存空间的首地址。
- 扩容失败。需扩展的空间后方没有足够的空间可供扩展,并且堆区中也没有符合需要开辟的内存大小的空间。结果就是开辟内存失败,返回一个 NULL(空指针)。
(4)free
free 函数的作用就是将 malloc、calloc 以及 realloc 函数申请的动态内存空间释放,其释放空间的大小取决于之前申请的内存空间的大小。

关于 malloc、calloc、realloc 和 free 的具体用法,请参考:
3. C++内存管理方式
C 语言内存管理方式在 C++ 中可以继续使用,但有些地方就无能为力而且使用起来比较麻烦,因此 C++ 又提出了自己的内存管理方式:通过 new 和 delete 操作符进行动态内存管理。
🍑 new和delete操作内置类型
(1)new 一个 int 类型的对象
int main()
{
// 动态申请一个int类型的空间
int\* p1 = new int;
// 销毁p1
delete p1;
return 0;
}
等价于用 malloc 来定义:
int main()
{
// 用malloc动态申请一个int类型的空间
int\* p1 = (int\*)malloc(sizeof(int));
// 销毁p1
free(p1);
return 0;
}
(2)new 10 个 int 类型的对象
int main()
{
// 动态申请10个int类型的空间
int\* p2 = new int[10];
// 销毁p1
delete[] p2;
return 0;
}
等价于用 malloc 来定义:
int main()
{
// 动态申请10个int类型的空间
int\* p2 = (int\*)malloc(sizeof(int) \* 10);
// 销毁p2
free(p2);
return 0;
}
(3)new 一个 int 类型对象,然后初始化为 10
int main()
{
// 动态申请一个int类型的空间并初始化为10
int\* p3 = new int(10);
// 销毁p3
delete p3;
return 0;
}
等价于用 malloc 来定义:
int main()
{
int\* p3 = (int\*)malloc(sizeof(int));
\*p3 = 10; //赋值
//销毁p3
free(p3);
return 0;
}
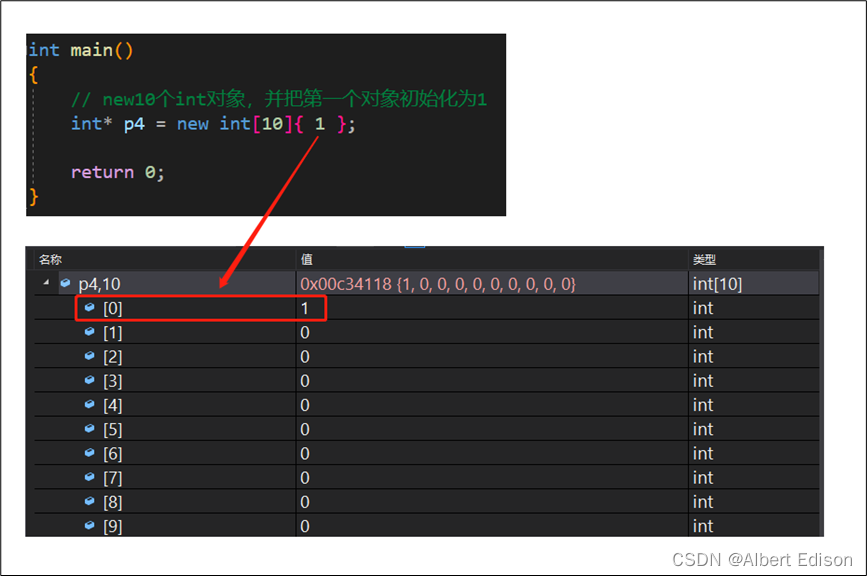
(4)new 10 个 int 类型对象,并进行初始化
int main()
{
//动态申请10个int类型的空间并初始化为1到10
int\* p4 = new int[10]{ 1,2,3,4,5,6,7,8,9,10 };
//销毁p4
delete[] p4;
return 0;
}
如果我们只初始化第一个对象的话,后面 9 个对象默认为初始化为 0
等价于用 malloc 来定义:
int main()
{
//动态申请10个int类型的空间并初始化为1到10
int\* p8 = (int\*)malloc(sizeof(int) \* 10); //申请
for (int i = 0; i < 10; i++) //赋值
{
p8[i] = i;
}
free(p8); //销毁
return 0;
}
我们再来看一张详细图:
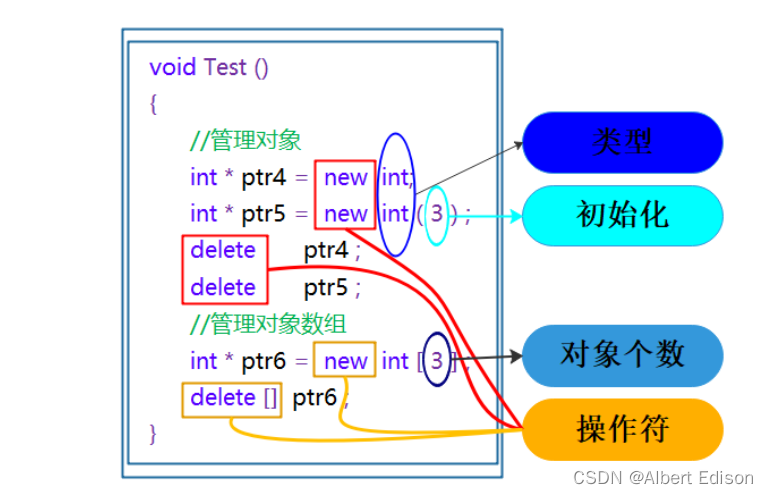
注意:
- 申请和释放 单个 元素的空间,使用 new 和 delete 操作符
- 申请和释放 连续 的空间,使用 new[ ] 和 delete[ ]
🍑 new和delete操作自定义类型
对于内置类型而言,用 malloc 和 new 除了用法不同,其他没什么区别,但是,它们的区别在于 自定义类型!
对于下面这段代码相信大家很熟悉吧,是我们前面学过的链表定义节点的方法:
//链表
struct ListNode
{
ListNode\* next;
int val;
};
//申请节点
struct ListNode\* BuyListNode(int x) {
struct ListNode\* node = (struct ListNode\*)malloc(sizeof(struct ListNode));
assert(node);
node->next = NULL;
node->val = x;
return node;
}
int main()
{
// 定义n1节点
struct ListNode\* n1 = BuyListNode(1);
return 0;
}
有没有发现,如果用 C 语言的这套方式来定义的话,是不是很繁琐?
那么我们可以用 new 来改进一下:
//链表
struct ListNode
{
ListNode\* _next;
int _val;
//构造函数
ListNode(int val = 0)
:\_next(nullptr) // 初始化列表
, \_val(val)
{}
};
int main()
{
// 定义n1节点
ListNode\* n2 = new ListNode(2); // new会去调用ListNode的构造函数
return 0;
}
这样是不是很方便?
所以 C++ 的 new,相当于我们之前写的 BuyListNode 函数,也就是说,针对自定义类型,malloc 只能开空间,但是 new 是 开空间 + 调用构造函数进行初始化
🍑 总结
(1)C++ 中如果是申请内置类型的对象或是数组,用 new/delete 和 malloc/free 没有什么区别。
(2)如果是自定义类型的话,new 和 delete 分别是 开空间+构造函数、析构函数+释放空间,而 malloc 和 free 仅仅是 开空间和释放空间,可以看到区别还是很大的。
(3)建议在 C++ 中无论是内置类型还是自定义类型的申请和释放,尽量都使用 new 和 delete。
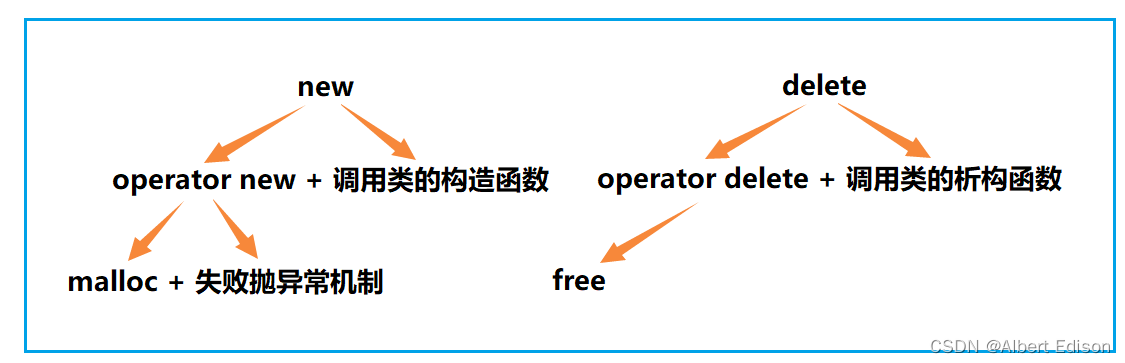
4. operator new 与 operator delete
new 和 delete 是用户进行动态内存申请和释放的操作符。
operator new 和 operator delete 是系统提供的全局函数,new 在底层调用 operator new 全局函数来申请空间,delete 在底层通过operator delete 全局函数来释放空间。
operator new 和 operator delete 的用法与 malloc 和 free 的用法完全一样,其功能都是在堆上申请和释放空间。
下面是 operator new 和 operator delete 的源代码
/\*
operator new:该函数实际通过malloc来申请空间,当malloc申请空间成功时直接返回;申请空间失败,
尝试执行空间不足应对措施,如果改应对措施用户设置了,则继续申请,否则抛异常。
\*/
void\* __CRTDECL operator new(size_t size) \_THROW1(_STD bad_alloc)
{
// try to allocate size bytes
void\* p;
while ((p = malloc(size)) == 0)
if (\_callnewh(size) == 0)
{
// report no memory
// 如果申请内存失败了,这里会抛出bad\_alloc 类型异常
static const std::bad_alloc nomem;
\_RAISE(nomem);
}
return (p);
}
/\*
operator delete: 该函数最终是通过free来释放空间的
\*/
void operator delete(void\* pUserData)
{
_CrtMemBlockHeader\* pHead;
RTCCALLBACK(_RTC_Free_hook, (pUserData, 0));
if (pUserData == NULL)
return;
\_mlock(_HEAP_LOCK); /\* block other threads \*/
__TRY
/\* get a pointer to memory block header \*/
pHead = pHdr(pUserData);
/\* verify block type \*/
\_ASSERTE(\_BLOCK\_TYPE\_IS\_VALID(pHead->nBlockUse));
\_free\_dbg(pUserData, pHead->nBlockUse);
__FINALLY
\_munlock(_HEAP_LOCK); /\* release other threads \*/
__END_TRY_FINALLY
return;
}
new 先去调用 operator new,然后,operator new 的底层是通过调用 malloc 函数来申请空间的,当 malloc 申请空间成功时直接返回;若申请空间失败,则尝试执行空间不足的应对措施,如果该应对措施用户设置了,则继续申请,否则抛异常。
而 operator delete 的底层是通过调用 free 函数来释放空间的。
🍑 类专属重载
那么 operator new 和 operator delete 什么时候用呢?
假设有下面这样一个链表,我们现在对链表进行插入数据
struct ListNode
{
ListNode\* _next;
ListNode\* _prev;
int _data;
// 构造函数
ListNode(int data = 0)
:\_next(nullptr)
,\_prev(nullptr)
,\_data(data)
{
cout << "ListNode()" << endl;
}
};
class List
{
public:
List()
{
_head = new ListNode; // 调用 operator new + 构造函数
_head->_next = _head;
_head->_prev = _head;
}
//尾插
void PushBack(int val)
{
ListNode\* newnode = new ListNode;
ListNode\* tail = _head->_prev;
// \_head(头) \_tail(尾) newnode(新节点)
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
}
//析构函数
~List()
{
ListNode\* cur = _head->_next;
while (cur != _head)
{
ListNode\* next = cur->_next;
delete cur;
cur = next;
}
delete _head;
_head = nullptr;
}
private:
ListNode\* _head;
};
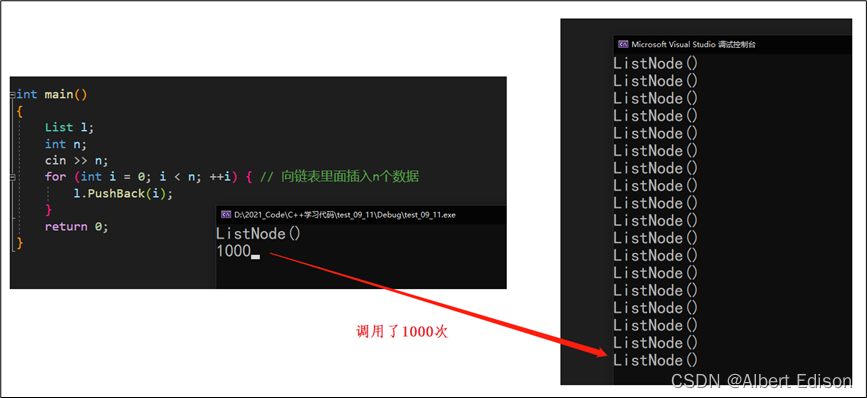
int main()
{
List l;
int n;
cin >> n;
for (int i = 0; i < n; ++i) { // 向链表里面插入n个数据
l.PushBack(i);
}
return 0;
}
如果我们输入 1000,那么就会向堆申请 1000 次空间。
也就是说会去:调用 new,然后又调用 operator new,最后再调用 malloc。
也就是说,现在这 1000 个数据是存在链表里面的,那么我把这堆数据用完,就会去把它清理掉,但是过了一会儿,我又要开辟空间去存放另外一对数据…
可以发现,在这个过程中,堆 会反复的给我们 申请空间,然后又 释放空间。
(其实有点像购物车的机制,把某个商品添加到购物车,然后又把某个商品从购物车删除)
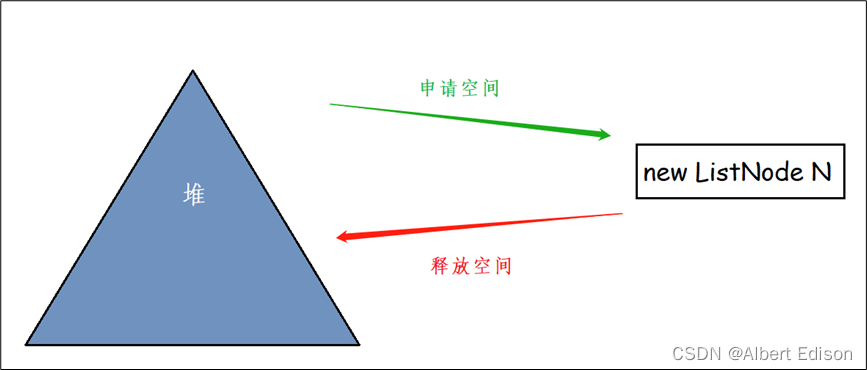
那么有没有什么好的方法可以不向堆去申请空间呢?当然有!
这个时候就会引出一个新的概念:池化技术。
我可以自己建一个 内存池,我要 申请 和 释放 空间就去找我创建的内存池,那么它和堆的区别在哪里呢?内存池离你更近,它更快,可以提高效率
收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
**,然后又 释放空间。
(其实有点像购物车的机制,把某个商品添加到购物车,然后又把某个商品从购物车删除)
那么有没有什么好的方法可以不向堆去申请空间呢?当然有!
这个时候就会引出一个新的概念:池化技术。
我可以自己建一个 内存池,我要 申请 和 释放 空间就去找我创建的内存池,那么它和堆的区别在哪里呢?内存池离你更近,它更快,可以提高效率
收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。
[外链图片转存中…(img-X3tLG1ic-1715847915743)]
[外链图片转存中…(img-qUlrOAZQ-1715847915743)]
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1637
1637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









