







收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。
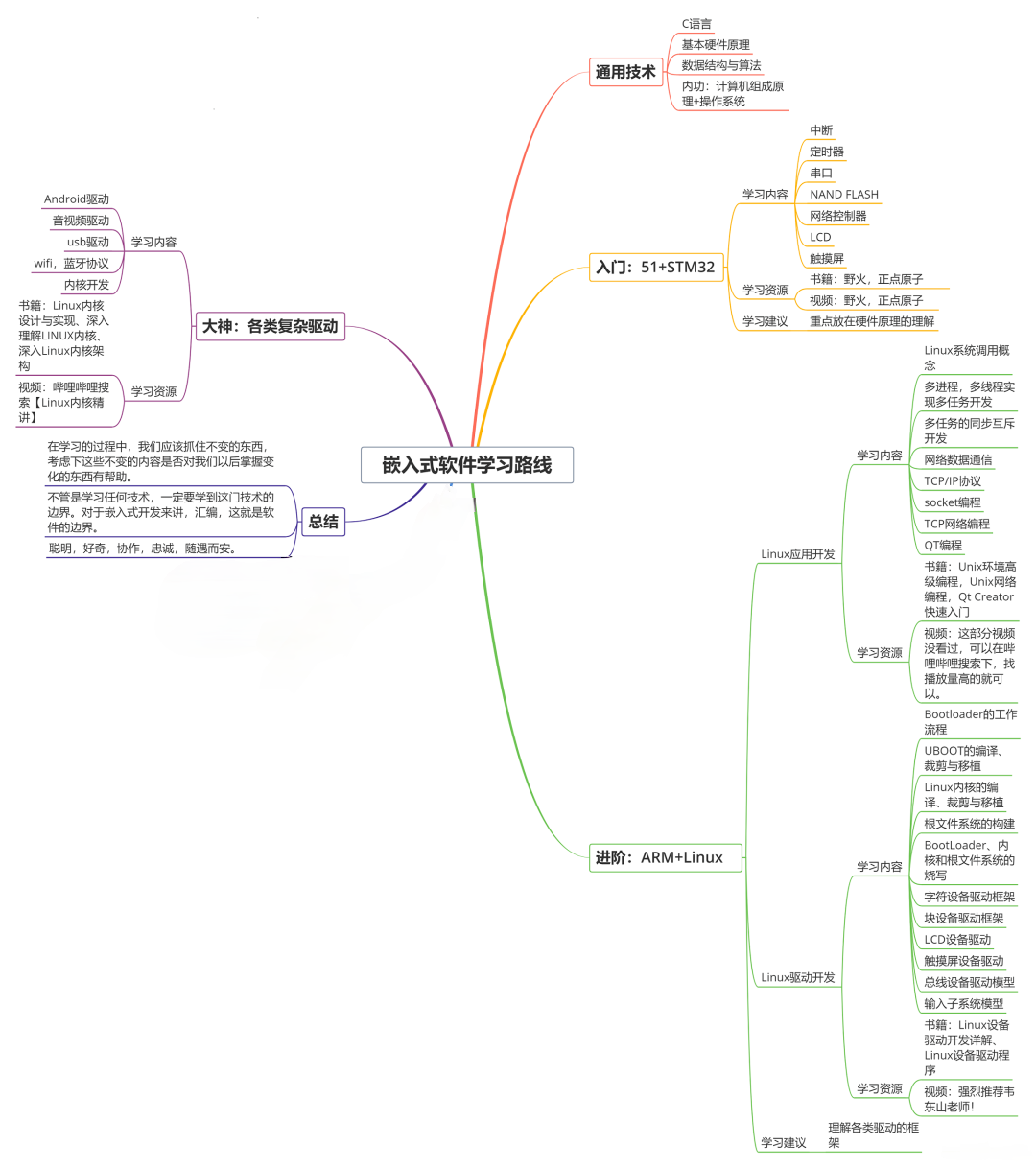
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
O(1)
一、哈希表的概念
1、查找算法
当我们在一个 链表 或者 顺序表 中 查找 一个数据元素 是否存在 的时候,唯一的方法就是遍历整个表,这种方法称为 线性枚举。

如果这时候,顺序表是有序的情况下,我们可以采用折半的方式去查找,这种方法称为 二分枚举。
线性枚举 的时间复杂度为
O
(
n
)
O(n)
O(n)。二分枚举 的时间复杂度为
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n)。是否存在更快速的查找方式呢?这就是本要介绍的一种新的数据结构 —— 哈希表。
2、哈希表
由于它不是顺序结构,所以很多数据结构书上称之为 散列表,下文会统一采用 哈希表 的形式来说明,作为读者,只需要知道这两者是同一种数据结构即可。
我们把需要查找的数据,通过一个 函数映射,找到 存储数据的位置 的过程称为 哈希。这里涉及到几个概念:
a)需要 查找的数据 本身被称为 关键字;
b)通过 函数映射 将 关键字 变成一个 哈希值 的过程中,这里的 函数 被称为 哈希函数;
c)生成 哈希值 的过程过程可能产生冲突,需要进行 冲突解决;
d)解决完冲突以后,实际 存储数据的位置 被称为 哈希地址,通俗的说,它就是一个数组下标;
e)存储所有这些数据的数据结构就是 哈希表,程序实现上一般采用数组实现,所以又叫 哈希数组。整个过程如下图所示:

2、哈希数组
为了方便下标索引,哈希表 的底层实现结构是一个数组,数组类型可以是任意类型,每个位置被称为一个槽。如下图所示,它代表的是一个长度为 8 的 哈希表,又叫 哈希数组。

3、关键字
关键字 是哈希数组中的元素,可以是任意类型的,它可以是整型、浮点型、字符型、字符串,甚至是结构体或者类。如下的 A、C、M 都可以是关键字;
int A = 5;
char C[100] = "Hello World!";
struct Obj { };
Obj M;
哈希表的实现过程中,我们需要通过一些手段,将一个非整型的 关键字 转换成 数组下标,也就是 哈希值,从而通过
O
(
1
)
O(1)
O(1) 的时间快速索引到它所对应的位置。
而将一个非整型的 关键字 转换成 整型 的手段就是 哈希函数。
4、哈希函数
哈希函数可以简单的理解为就是小学课本上那个函数,即
y
=
f
(
x
)
y = f(x)
y=f(x),这里的
f
(
x
)
f(x)
f(x) 就是哈希函数,
x
x
x 是关键字,
y
y
y 是哈希值。好的哈希函数应该具备以下两个特质:
a)单射;
b)雪崩效应:输入值
x
x
x 的
1
1
1 比特的变化,能够造成输出值
y
y
y 至少一半比特的变化;
单射很容易理解,图
(
a
)
(a)
(a) 中已知哈希值
y
y
y 时,键
x
x
x 可能有两种情况,不是一个单射;而图
(
b
)
(b)
(b) 中已知哈希值
y
y
y 时,键
x
x
x 一定是唯一确定的,所以它是单射。由于
x
x
x 和
y
y
y 一一对应,这样就从本原上减少了冲突。
 雪崩效应是为了让哈希值更加符合随机分布的原则,哈希表中的键分布的越随机,利用率越高,效率也越高。
雪崩效应是为了让哈希值更加符合随机分布的原则,哈希表中的键分布的越随机,利用率越高,效率也越高。
常用的哈希函数有:直接定址法、除留余数法、数字分析法、平方取中法、折叠法、随机数法 等等。有关哈希函数的内容,下文会进行详细讲解。
5、哈希冲突
哈希函数在生成 哈希值 的过程中,如果产生 不同的关键字得到相同的哈希值 的情况,就被称为 哈希冲突。
即对于哈希函数
y
=
f
(
x
)
y = f(x)
y=f(x),当关键字
x
1
≠
x
2
x_1 \neq x_2
x1=x2,但是却有
f
(
x
1
)
=
f
(
x
2
)
f(x_1) = f(x_2)
f(x1)=f(x2),这时候,我们需要进行冲突解决。
冲突解决方法有很多,主要有:开放定址法、再散列函数法、链地址法、公共溢出区法 等等。有关解决冲突的内容,下文会进行详细讲解。
6、哈希地址
哈希地址 就是一个 数组下标 ,即哈希数组的下标。通过下标获得数据,被称为 索引。通过数据获得下标,被称为 哈希。平时工作的时候,和同事交流时用到的一个词 反查 就是说的 哈希。
二、常用哈希函数
1、直接定址法
直接定址法 就是 关键字 本身就是 哈希值,表示成函数值就是
f
(
x
)
=
x
f(x) = x
f(x)=x 例如,我们需要统计一个字符串中每个字符的出现次数,就可以通过这种方法。任何一个字符的范围都是
[
0
,
255
]
[0, 255]
[0,255],所以只要用一个长度为 256 的哈希数组就可以存储每个字符对应的出现次数,利用一次遍历枚举就可以解决这个问题。C代码实现如下:
int i, hash[256];
for(i = 0; str[i]; ++i) {
++hash[ str[i] ];
}
这个就是最基础的直接定址法的实现。hash[c]代表字符c在这个字符串str中的出现次数。
2、平方取中法
平方取中法 就是对 关键字 进行平方,再取中间的某几位作为 哈希值。
例如,对于关键字
1314
1314
1314,得到平方为
1726596
1726596
1726596,取中间三位作为哈希值,即
265
265
265。
平方取中法 比较适用于 不清楚关键字的分布,且位数也不是很大 的情况。
3、折叠法
折叠法 是将关键字分割成位数相等的几部分(注意最后一部分位数不够可以短一些),然后再进行求和,得到一个 哈希值。
例如,对于关键字
5201314
5201314
5201314,将它分为四组,并且相加得到:
52
01
31
4
=
88
52+01+31+4 = 88
52+01+31+4=88,这就是哈希值。
折叠法 比较适用于 不清楚关键字的分布,但是关键字位数较多 的情况。
4、除留余数法
除留余数法 就是 关键字 模上 哈希表 长度,表示成函数值就是
f
(
x
)
=
x
m
o
d
m
f(x) = x \ mod \ m
f(x)=x mod m 其中
m
m
m 代表了哈希表的长度,这种方法,不仅可以对关键字直接取模,也可以在 平方取中法、折叠法 之后再取模。
例如,对于一个长度为 4 的哈希数组,我们可以将关键字 模 4 得到哈希值,如图所示:

5、位与法
哈希数组的长度一般选择 2 的幂,因为我们知道取模运算是比较耗时的,而位运算相对较为高效。
选择 2 的幂作为数组长度,可以将 取模运算 转换成 二进制位与。
令
m
=
2
k
m = 2^k
m=2k,那么它的二进制表示就是:
m
=
(
1
000…000
⏟
k
)
2
m = (1\underbrace{000…000}_{\rm k})_2
m=(1k
000…000)2,任何一个数模上
m
m
m,就相当于取了
m
m
m 的二进制低
k
k
k 位,而
m
−
1
=
(
111…111
⏟
k
)
2
m-1 = (\underbrace{111…111}_{\rm k})_2
m−1=(k
111…111)2 ,所以和 位与
m
−
1
m-1
m−1 的效果是一样的。即:
x
%
S
=
=
x
&
(
S
−
1
)
x \ % \ S == x \ & \ (S - 1)
x % S==x & (S−1) 除了直接定址法,其它三种方法都有可能导致哈希冲突,接下来,我们就来讨论下常用的一些哈希冲突的解决方案。
三、常见哈希冲突解决方案
1、开放定址法
1)原理讲解
开放定址法 就是一旦发生冲突,就去寻找下一个空的地址,只要哈希表足够大,总能找到一个空的位置,并且记录下来作为它的 哈希地址。公式如下:
f
i
(
x
)
=
(
f
(
x
)
d
i
)
m
o
d
m
f_i(x) = (f(x)+d_i) \ mod \ m
fi(x)=(f(x)+di) mod m
这里的
d
i
d_i
di 是一个数列,可以是常数列
(
1
,
1
,
1
,
.
.
.
,
1
)
(1, 1, 1, …,1)
(1,1,1,…,1),也可以是等差数列
(
1
,
2
,
3
,
.
.
.
,
m
−
1
)
(1,2,3,…,m-1)
(1,2,3,…,m−1)。
2)动画演示

上图中,采用的是哈希函数算法是 除留余数法,采用的哈希冲突解决方案是 开放定址法,哈希表的每个数据就是一个关键字,插入之前需要先进行查找,如果找到的位置未被插入,则执行插入;否则,找到下一个未被插入的位置进行插入;总共插入了 6 个数据,分别为:11、12、13、20、19、28。
这种方法需要注意的是,当插入数据超过哈希表长度时,不能再执行插入。
本文在第四章讲解 哈希表的现实 时采用的就是常数列的开放定址法。
2、再散列函数法
1)原理讲解
再散列函数法 就是一旦发生冲突,就采用另一个哈希函数,可以是 平方取中法、折叠法、除留余数法 等等的组合,一般用两个哈希函数,产生冲突的概率已经微乎其微了。
再散列函数法 能够使关键字不产生聚集,当然,也会增加不少哈希函数的计算时间。
3、链地址法
1)原理讲解
当然,产生冲突后,我们也可以选择不换位置,还是在原来的位置,只是把 哈希值 相同的用链表串联起来。这种方法被称为 链地址法。
2)动画演示

上图中,采用的是哈希函数算法是 除留余数法,采用的哈希冲突解决方案是 链地址法,哈希表的每个数据保留了一个 链表头结点 和 尾结点,插入之前需要先进行查找,如果找到的位置,链表非空,则插入尾结点并且更新尾结点;否则,生成一个新的链表头结点和尾结点;总共插入了 6 个数据,分别为:11、12、13、20、19、28。
4、公共溢出区法
1)原理讲解
一旦产生冲突的数据,统一放到另外一个顺序表中,每次查找数据,在哈希数组中到的关键字和给定关键字相等,则认为查找成功;否则,就去公共溢出区顺序查找,这种方法被称为 公共溢出区法。
这种方法适合冲突较少的情况。
哈希表相关的内容,可以参考我的这篇文章:夜深人静写算法(九)- 哈希表
4、队列
内存结构:看用数组实现,还是链表实现
实现难度:一般
下标访问:不支持
分类:FIFO、单调队列、双端队列
插入时间复杂度:O
(
1
)
O(1)
O(1)
查找时间复杂度:理论上不支持
删除时间复杂度:O
(
1
)
O(1)
O(1)
一、概念
1、队列的定义
队列 是仅限在 一端 进行 插入,另一端 进行 删除 的 线性表。
队列 又被称为 先进先出 (First In First Out) 的线性表,简称 FIFO 。

2、队首
允许进行元素删除的一端称为 队首。如下图所示:

3、队尾
允许进行元素插入的一端称为 队尾。如下图所示:

二、接口
1、数据入队
队列的插入操作,叫做 入队。它是将 数据元素 从 队尾 进行插入的过程,如图所示,表示的是 插入 两个数据(绿色 和 蓝色)的过程:

2、数据出队
队列的删除操作,叫做 出队。它是将 队首 元素进行删除的过程,如图所示,表示的是 依次 删除 两个数据(红色 和 橙色)的过程:

3、清空队列
队列的清空操作,就是一直 出队,直到队列为空的过程,当 队首 和 队尾 重合时,就代表队尾为空了,如图所示:

4、获取队首数据
对于一个队列来说只能获取 队首 数据,一般不支持获取 其它数据。
5、获取队列元素个数
队列元素个数一般用一个额外变量存储,入队 时加一,出队 时减一。这样获取队列元素的时候就不需要遍历整个队列。通过
O
(
1
)
O(1)
O(1) 的时间复杂度获取队列元素个数。
6、队列的判空
当队列元素个数为零时,就是一个 空队,空队 不允许 出队 操作。
有关队列的更多内容,可以参考我的这篇文章:《画解数据结构》(1 - 6)- 队列
5、栈
内存结构:看用数组实现,还是链表实现
实现难度:一般
下标访问:不支持
分类:FILO、单调栈
插入时间复杂度:O
(
1
)
O(1)
O(1)
查找时间复杂度:理论上不支持
删除时间复杂度:O
(
1
)
O(1)
O(1)
一、概念
1、栈的定义
栈 是仅限在 表尾 进行 插入 和 删除 的 线性表。
栈 又被称为 后进先出 (Last In First Out) 的线性表,简称 LIFO 。
2、栈顶
栈 是一个线性表,我们把允许 插入 和 删除 的一端称为 栈顶。

3、栈底
和 栈顶 相对,另一端称为 栈底,实际上,栈底的元素我们不需要关心。

二、接口
1、数据入栈
栈的插入操作,叫做 入栈,也可称为 进栈、压栈。如下图所示,代表了三次入栈操作:

2、数据出栈
栈的删除操作,叫做 出栈,也可称为 弹栈。如下图所示,代表了两次出栈操作:

3、清空栈
一直 出栈,直到栈为空,如下图所示:

1、获取栈顶数据
对于一个栈来说只能获取 栈顶 数据,一般不支持获取 其它数据。
2、获取栈元素个数
栈元素个数一般用一个额外变量存储,入栈 时加一,出栈 时减一。这样获取栈元素的时候就不需要遍历整个栈。通过
O
(
1
)
O(1)
O(1) 的时间复杂度获取栈元素个数。
3、栈的判空
当栈元素个数为零时,就是一个空栈,空栈不允许 出栈 操作。
栈相关的内容,可以参考我的这篇文章:《画解数据结构》(1 - 5)- 栈
🌵7、二叉树
优先队列 是 堆实现的,所以也属于 二叉树 范畴。它和队列不同,不属于线性表。
内存结构:内存结构一般不连续,但是有时候实现的时候,为了方便,一般是物理连续,逻辑不连续
实现难度:较难
下标访问:不支持
分类:二叉树 和 多叉树
插入时间复杂度:看情况而定
查找时间复杂度:理论上O
(
l
o
g
2
n
)
O(log_2n)
O(log2n)
删除时间复杂度:看情况而定
🌳8、多叉树
内存结构:内存结构一般不连续,但是有时候实现的时候,为了方便,一般是物理连续,逻辑不连续
实现难度:较难
下标访问:不支持
分类:二叉树 和 多叉树
插入时间复杂度:看情况而定
查找时间复杂度:理论上O
(
l
o
g
2
n
)
O(log_2n)
O(log2n)
删除时间复杂度:看情况而定
- 一种经典的多叉树是字典树,可以参考我的这篇文章:
- 夜深人静写算法(七)- 字典树
🌲9、森林
- 比较经典的森林是:并查集,可以参考我的这篇文章:
- 夜深人静写算法(五)- 并查集
🍀10、树状数组
- 树状数组是用来做 单点更新,成端求和 的问题的,有关于它的内容,可以参考:
- 夜深人静写算法(十三)- 树状数组
🌍11、图
内存结构:不一定
实现难度:难
下标访问:不支持
分类:有向图、无向图
插入时间复杂度:根据算法而定
查找时间复杂度:根据算法而定
删除时间复杂度:根据算法而定
1、图的概念
- 在讲解最短路问题之前,首先需要介绍一下计算机中图(图论)的概念,如下:
- 图
G
G
G 是一个有序二元组
(
V
,
E
)
(V,E)
(V,E),其中
V
V
V 称为顶点集合,
E
E
E 称为边集合,
E
E
E 与
V
V
V 不相交。顶点集合的元素被称为顶点,边集合的元素被称为边。
- 对于无权图,边由二元组
(
u
,
v
)
(u,v)
(u,v) 表示,其中
u
,
v
∈
V
u, v \in V
u,v∈V。对于带权图,边由三元组
(
u
,
v
,
w
)
(u,v, w)
(u,v,w) 表示,其中
u
,
v
∈
V
u, v \in V
u,v∈V,
w
w
w 为权值,可以是任意类型。
- 图分为有向图和无向图,对于有向图,
(
u
,
v
)
(u, v)
(u,v) 表示的是 从顶点
u
u
u 到 顶点
v
v
v 的边,即
u
→
v
u \to v
u→v;对于无向图,
(
u
,
v
)
(u, v)
(u,v) 可以理解成两条边,一条是 从顶点
u
u
u 到 顶点
v
v
v 的边,即
u
→
v
u \to v
u→v,另一条是从顶点
v
v
v 到 顶点
u
u
u 的边,即
v
→
u
v \to u
v→u;
2、图的存储
- 对于图的存储,程序实现上也有多种方案,根据不同情况采用不同的方案。接下来以图二-3-1所表示的图为例,讲解四种存储图的方案。

1)邻接矩阵
- 邻接矩阵是直接利用一个二维数组对边的关系进行存储,矩阵的第
i
i
i 行第
j
j
j 列的值 表示
i
→
j
i \to j
i→j 这条边的权值;特殊的,如果不存在这条边,用一个特殊标记
∞
\infty
∞ 来表示;如果
i
=
j
i = j
i=j,则权值为
0
0
0。
- 它的优点是:实现非常简单,而且很容易理解;缺点也很明显,如果这个图是一个非常稀疏的图,图中边很少,但是点很多,就会造成非常大的内存浪费,点数过大的时候根本就无法存储。
- [
0
∞
3
∞
1
0
2
∞
∞
∞
0
3
9
8
∞
0
]
\left[ \begin{matrix} 0 & \infty & 3 & \infty \ 1 & 0 & 2 & \infty \ \infty & \infty & 0 & 3 \ 9 & 8 & \infty & 0 \end{matrix} \right]
⎣⎢⎢⎡01∞9∞0∞8320∞∞∞30⎦⎥⎥⎤
2)邻接表
- 邻接表是图中常用的存储结构之一,采用链表来存储,每个顶点都有一个链表,链表的数据表示和当前顶点直接相邻的顶点的数据
(
v
,
w
)
(v, w)
(v,w),即 顶点 和 边权。
- 它的优点是:对于稀疏图不会有数据浪费;缺点就是实现相对邻接矩阵来说较麻烦,需要自己实现链表,动态分配内存。
- 如图所示,
d
a
t
a
data
data 即
(
v
,
w
)
(v, w)
(v,w) 二元组,代表和对应顶点
u
u
u 直接相连的顶点数据,
w
w
w 代表
u
→
v
u \to v
u→v 的边权,
n
e
x
t
next
next 是一个指针,指向下一个
(
v
,
w
)
(v, w)
(v,w) 二元组。

- 在 C++ 中,还可以使用 vector 这个容器来代替链表的功能;
vector<Edge> edges[maxn];
3)前向星
- 前向星是以存储边的方式来存储图,先将边读入并存储在连续的数组中,然后按照边的起点进行排序,这样数组中起点相等的边就能够在数组中进行连续访问了。
- 它的优点是实现简单,容易理解;缺点是需要在所有边都读入完毕的情况下对所有边进行一次排序,带来了时间开销,实用性也较差,只适合离线算法。
- 如图所示,表示的是三元组
(
u
,
v
,
w
)
(u, v, w)
(u,v,w) 的数组,
i
d
x
idx
idx 代表数组下标。
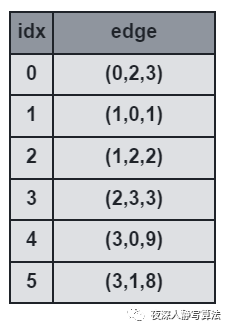
- 那么用哪种数据结构才能满足所有图的需求呢?
- 接下来介绍一种新的数据结构 —— 链式前向星。
4)链式前向星
- 链式前向星和邻接表类似,也是链式结构和数组结构的结合,每个结点
i
i
i 都有一个链表,链表的所有数据是从
i
i
i 出发的所有边的集合(对比邻接表存的是顶点集合),边的表示为一个四元组
(
u
,
v
,
w
,
n
e
x
t
)
(u, v, w, next)
(u,v,w,next),其中
(
u
,
v
)
(u, v)
(u,v) 代表该条边的有向顶点对
u
→
v
u \to v
u→v,
w
w
w 代表边上的权值,
n
e
x
t
next
next 指向下一条边。
- 具体的,我们需要一个边的结构体数组
edge[maxm],maxm表示边的总数,所有边都存储在这个结构体数组中,并且用head[i]来指向
i
i
i 结点的第一条边。
- 边的结构体声明如下:
struct Edge {
int u, v, w, next;
Edge() {}
Edge(int _u, int _v, int _w, int _next) :
u(_u), v(_v), w(_w), next(_next)
{
}
}edge[maxm];
- 初始化所有的
head[i] = -1,当前边总数edgeCount = 0; - 每读入一条
u
→
v
u \to v
u→v 的边,调用 addEdge(u, v, w),具体函数的实现如下:
void addEdge(int u, int v, int w) {
edge[edgeCount] = Edge(u, v, w, head[u]);
head[u] = edgeCount++;
}
- 这个函数的含义是每加入一条边
(
u
,
v
,
w
)
(u, v, w)
(u,v,w),就在原有的链表结构的首部插入这条边,使得每次插入的时间复杂度为
O
(
1
)
O(1)
O(1),所以链表的边的顺序和读入顺序正好是逆序的。这种结构在无论是稠密的还是稀疏的图上都有非常好的表现,空间上没有浪费,时间上也是最小开销。
- 调用的时候只要通过
head[i]就能访问到由
i
i
i 出发的第一条边的编号,通过编号到edge数组进行索引可以得到边的具体信息,然后根据这条边的next域可以得到第二条边的编号,以此类推,直到 next域为 -1 为止。
for (int e = head[u]; ~e; e = edges[e].next) {
int v = edges[e].v;
ValueType w = edges[e].w;
...
}
- 文中的
~e等价于e != -1,是对e进行二进制取反的操作(-1 的的补码二进制全是 1,取反后变成全 0,这样就使得条件不满足跳出循环)。
三、四个入门算法
1、排序
- 一般网上的文章在讲各种 「 排序 」 算法的时候,都会甩出一张 「 思维导图 」,如下:

- 当然,我也不例外……
- 这些概念也不用多说,只要你能够把**「 快速排序 」的思想理解了。基本上其它算法的思想也都能学会。这个思路就是经典的:「 要学就学最难的,其它肯定能学会 」。因为当你连「 最难的 」都已经 「 KO 」 了,其它的还不是「 小菜一碟 」**?信心自然就来了。
- 我们要战胜的其实不是**「 算法 」本身,而是我们对 「 算法 」 的恐惧。一旦建立起「 自信心 」,后面的事情,就「 水到渠成 」**了。
- 然而,实际情况比这可要简单得多。实际在上机刷题的过程中,不可能让你手写一个排序,你只需要知道 C++ 中 STL 的 sort 函数就够了,它的底层就是由【快速排序】实现的。
- 所有的排序题都可以做。我挑一个来说。至于上面说到的那十个排序算法,如果有缘,我会在八月份的这个专栏 ❤️**《画解数据结构》导航** ❤️ 中更新,尽情期待~~
I、例题描述
给你两个有序整数数组
n
u
m
s
1
nums1
nums1 和
n
u
m
s
2
nums2
nums2,请你将
n
u
m
s
2
nums2
nums2 合并到
n
u
m
s
1
nums1
nums1 中,使
n
u
m
s
1
nums1
nums1 成为一个有序数组。初始化
n
u
m
s
1
nums1
nums1 和
n
u
m
s
2
nums2
nums2 的元素数量分别为
m
m
m 和
n
n
n 。你可以假设
n
u
m
s
1
nums1
nums1 的空间大小等于
m
n
m + n
m+n,这样它就有足够的空间保存来自
n
u
m
s
2
nums2
nums2 的元素。
样例输入:n
u
m
s
1
=
[
1
,
2
,
3
,
0
,
0
,
0
]
,
m
=
3
,
n
u
m
s
2
=
[
2
,
5
,
6
]
,
n
=
3
nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
nums1=[1,2,3,0,0,0],m=3,nums2=[2,5,6],n=3
样例输出:[
1
,
2
,
2
,
3
,
5
,
6
]
[1,2,2,3,5,6]
[1,2,2,3,5,6]
原题出处: LeetCode 88. 合并两个有序数组
II、基础框架
- c++ 版本给出的基础框架代码如下:
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
}
};
III、思路分析
- 这个题别想太多,直接把第二个数组的元素加到第一个数组元素的后面,然后直接排序就成。

IV、时间复杂度
- STL 排序函数的时间复杂度为
O
(
n
l
o
g
2
n
)
O(nlog_2n)
O(nlog2n),遍历的时间复杂度为
O
(
n
)
O(n)
O(n),所以总的时间复杂度为
O
(
n
l
o
g
2
n
)
O(nlog_2n)
O(nlog2n)。
IV、源码详解
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
for(int i = m; i < n + m; ++i) {
nums1[i] = nums2[i-m]; // (1)
}
sort(nums1.begin(), nums1.end()); // (2)
}
};
- (
1
)
(1)
(1) 简单合并两个数组;
- (
2
)
(2)
(2) 对数组1进行排序;
VI、本题小知识
只要能够达到最终的结果,
O
(
n
)
O(n)
O(n) 和
O
(
n
l
o
g
2
n
)
O(nlog_2n)
O(nlog2n) 的差距其实并没有那么大。只要是和有序相关的,就可以调用这个函数,直接就出来了。
2、线性迭代
- 迭代就是一件事情重复的做,干的事情一样,只是参数的不同。一般配合的 数据结构 是 【数组】 或者 【链表】,实现方式也是一个循环。比 枚举 稍微复杂一点。
I、例题描述
给定单链表的头节点
h
e
a
d
head
head ,要求反转链表,并返回反转后的链表头。
样例输入:[
1
,
2
,
3
,
4
]
[1,2,3,4]
[1,2,3,4]
样例输出:[
4
,
3
,
2
,
1
]
[4, 3, 2, 1]
[4,3,2,1]
原题出处: LeetCode 206. 反转链表

II、基础框架
- c++ 版本给出的基础框架代码如下:
/\*\*
\* Definition for singly-linked list.
\* struct ListNode {
\* int val;
\* ListNode \*next;
\* ListNode() : val(0), next(nullptr) {}
\* ListNode(int x) : val(x), next(nullptr) {}
\* ListNode(int x, ListNode \*next) : val(x), next(next) {}
\* };
\*/
class Solution {
public:
ListNode\* reverseList(ListNode\* head) {
}
};
- 这里引入了一种数据结构 链表
ListNode; - 成员有两个:数据域
val和指针域next。 - 返回的是链表头结点;
III、思路分析
- 这个问题,我们可以采用头插法,即每次拿出第 2 个节点插到头部,拿出第 3 个节点插到头部,拿出第 4 个节点插到头部,… 拿出最后一个节点插到头部。
- 于是整个过程可以分为两个步骤:删除第
i
i
i 个节点,将它放到头部,反复迭代
i
i
i 即可。
- 如图所示:

- 我们发现,图中的蓝色指针永远固定在最开始的链表头结点上,那么可以以它为契机,每次删除它的
next,并且插到最新的头结点前面,不断改变头结点head的指向,迭代
n
−
1
n-1
n−1 次就能得到答案了。
IV、时间复杂度
- 每个结点只会被访问一次,执行一次头插操作,总共
n
n
n 个节点的情况下,时间复杂度
O
(
n
)
O(n)
O(n)。
V、源码详解
class Solution {
ListNode \*removeNextAndReturn(ListNode\* now) { // (1)
if(now == nullptr || now->next == nullptr) {
return nullptr; // (2)
}
ListNode \*retNode = now->next; // (3)
now->next = now->next->next; // (4)
return retNode;
}
public:
ListNode\* reverseList(ListNode\* head) {
ListNode \*doRemoveNode = head; // (5)
while(doRemoveNode) { // (6)
ListNode \*newHead = removeNextAndReturn(doRemoveNode); // (7)
if(newHead) { // (8)
newHead->next = head;
head = newHead;
}else {
break; // (9)
}
}
return head;
}
};
- (
1
)
(1)
(1) ListNode *removeNextAndReturn(ListNode* now)函数的作用是删除now的next节点,并且返回;
- (
2
)
(2)
(2) 本身为空或者下一个节点为空,返回空;
- (
3
)
(3)
(3) 将需要删除的节点缓存起来,供后续返回;
- (
4
)
(4)
(4) 执行删除 now->next 的操作;
- (
5
)
(5)
(5) doRemoveNode指向的下一个节点是将要被删除的节点,所以doRemoveNode需要被缓存起来,不然都不知道怎么进行删除;
- (
6
)
(6)
(6) 没有需要删除的节点了就结束迭代;
- (
7
)
(7)
(7) 删除 doRemoveNode 的下一个节点并返回被删除的节点;
- (
8
)
(8)
(8) 如果有被删除的节点,则插入头部;
- (
9
)
(9)
(9) 如果没有,则跳出迭代。
VI、本题小知识
复杂问题简单化的最好办法就是将问题拆细,比如这个问题中,将一个节点取出来插到头部这件事情可以分为两步:
1)删除给定节点;
2)将删除的节点插入头部;
3、线性枚举
- 线性枚举,一般配合的 数据结构 是 【数组】 或者 【链表】,实现方式就是一个循环。正因为只有一个循环,所以线性枚举解决的问题一般比较简单,而且很容易从题目中看出来。
I、例题描述
编写一个函数,将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。
必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
样例输入:[
“
a
”
,
“
b
”
,
“
c
”
,
“
d
”
]
[“a”, “b”, “c”, “d”]
[“a”,“b”,“c”,“d”]
样例输出:[
“
d
”
,
“
c
”
,
“
b
”
,
“
a
”
]
[ “d”, “c”, “b”, “a”]
[“d”,“c”,“b”,“a”]
原题出处: LeetCode 344. 反转字符串
II、基础框架
- c++ 版本给出的基础框架代码如下,要求不采用任何的辅助数组;
- 也就是空间复杂度要求
O
(
1
)
O(1)
O(1)。
class Solution {
public:
void reverseString(vector<char>& s) {
}
};
III、思路分析
翻转的含义,相当于就是 第一个字符 和 最后一个交换,第二个字符 和 最后第二个交换,… 以此类推,所以我们首先实现一个交换变量的函数
swap,然后再枚举 第一个字符、第二个字符、第三个字符 …… 即可。
对于第i
i
i 个字符,它的交换对象是 第
l
e
n
−
i
−
1
len-i-1
len−i−1 个字符 (其中
l
e
n
len
len 为字符串长度)。
swap函数的实现,可以参考:《C语言入门100例》 - 例2 | 交换变量。
IV、时间复杂度
- 线性枚举的过程为
O
(
n
)
O(n)
O(n),交换变量为
O
(
1
)
O(1)
O(1),两个过程是相乘的关系,所以整个算法的时间复杂度为
O
(
n
)
O(n)
O(n)。
IV、源码详解
class Solution {
public:
void swap(char& a, char& b) { // (1)
char tmp = a;
a = b;
b = tmp;
}
void reverseString(vector<char>& s) {
int len = s.size();
for(int i = 0; i < len / 2; ++i) { // (2)
swap(s[i], s[len-i-1]);
}
}
};
- (
1
)
(1)
(1) 实现一个变量交换的函数,其中&是C++中的引用,在函数传参是经常用到,被称为:引用传递(pass-by-reference),即被调函数的形式参数虽然也作为局部变量在堆栈中开辟了内存空间
,但是这时存放的是由主调函数放进来的实参变量的地址。被调函数对形参的任何操作都被处理成间接寻址,即通过堆栈中存放的地址访问主调函数中的实参变量。
简而言之,函数调用的参数,可以传引用,从而使得函数返回时,传参值的改变依旧生效。
- (
2
)
(2)
(2) 这一步是做的线性枚举,注意枚举范围是
[
0
,
l
e
n
/
2
−
1
]
[0, len/2-1]
[0,len/2−1]。
VI、本题小知识
函数调用的参数,可以传引用,从而使得函数返回时,传参值的改变依旧生效。
4、二分枚举
- 能用二分枚举的问题,一定可以用线性枚举来实现,只是时间上的差别,二分枚举的时间复杂度一般为对数级,效率上会高不少。同时,实现难度也会略微有所上升。我们通过平时开发时遇到的常见问题来举个例子。
I、例题描述
软件开发的时候,会有版本的概念。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。假设你有
n
n
n 个版本
[
1
,
2
,
.
.
.
,
n
]
[1, 2, …, n]
[1,2,…,n],你想找出导致之后所有版本出错的第一个错误的版本。可以通过调用
bool isBadVersion(version)接口来判断版本号version是否在单元测试中出错。实现一个函数来查找第一个错误的版本。应该尽量减少对调用 API 的次数。
样例输入:5
5
5 和
b
a
d
=
4
bad = 4
bad=4
样例输出:4
4
4
原题出处: LeetCode 278. 第一个错误的版本
II、基础框架
- c++ 版本给出的基础框架代码如下,其中
bool isBadVersion(int version)是供你调用的 API,也就是当你调用这个 API 时,如果version是错误的,则返回true;否则,返回false;
// The API isBadVersion is defined for you.
// bool isBadVersion(int version);
class Solution {
public:
int firstBadVersion(int n) {
}
};
III、思路分析
- 由题意可得,我们调用它提供的 API 时,返回值分布如下:
- 000…000111…111
000…000111…111
000…000111…111
- 其中 0 代表
false,1 代表true;也就是一旦出现 1,就再也不会出现 0 了。 - 所以基于这思路,我们可以二分位置;
归纳总结为 2 种情况,如下:
1)当前二分到的位置m
i
d
mid
mid,给出的版本是错误,那么从当前位置以后的版本不需要再检测了(因为一定也是错误的),并且我们可以肯定,出错的位置一定在
[
l
,
m
i
d
]
[l, mid]
[l,mid];并且
m
i
d
mid
mid 是一个可行解,记录下来;
2)当前二分到的位置m
i
d
mid
mid,给出的版本是正确,则出错位置可能在
[
m
i
d
1
,
r
]
[mid+1, r]
[mid+1,r];
IV、时间复杂度
- 由于每次都是将区间折半,所以时间复杂度为
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n)。
V、源码详解
// The API isBadVersion is defined for you.
// bool isBadVersion(int version);
class Solution {
public:
int firstBadVersion(int n) {
long long l = 1, r = n; // (1)
long long ans = (long long)n + 1;
while(l <= r) {
long long mid = (l + r) / 2;
if( isBadVersion(mid) ) {
ans = mid; // (2)
r = mid - 1;
}else {
l = mid + 1; // (3)
}
}
return ans;
}
};
- (
1
)
(1)
(1) 需要这里,这里两个区间相加可能超过 int,所以需要采用 64 位整型long long;
- (
2
)
(2)
(2) 找到错误版本的嫌疑区间
[
l
,
m
i
d
]
[l, mid]
[l,mid],并且
m
i
d
mid
mid 是确定的候选嫌疑位置;
- (
3
)
(3)
(3) 错误版本不可能落在
[
l
,
m
i
d
]
[l, mid]
[l,mid],所以可能在
[
m
i
d
1
,
r
]
[mid+1, r]
[mid+1,r],需要继续二分迭代;
VI、本题小知识
二分时,如果区间范围过大,int难以招架时,需要动用long long;
收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
-by-reference)**,即被调函数的形式参数虽然也作为局部变量在堆栈中开辟了内存空间
,但是这时存放的是由主调函数放进来的实参变量的地址。被调函数对形参的任何操作都被处理成间接寻址,即通过堆栈中存放的地址访问主调函数中的实参变量。
简而言之,函数调用的参数,可以传引用,从而使得函数返回时,传参值的改变依旧生效。
- (
2
)
(2)
(2) 这一步是做的线性枚举,注意枚举范围是
[
0
,
l
e
n
/
2
−
1
]
[0, len/2-1]
[0,len/2−1]。
VI、本题小知识
函数调用的参数,可以传引用,从而使得函数返回时,传参值的改变依旧生效。
4、二分枚举
- 能用二分枚举的问题,一定可以用线性枚举来实现,只是时间上的差别,二分枚举的时间复杂度一般为对数级,效率上会高不少。同时,实现难度也会略微有所上升。我们通过平时开发时遇到的常见问题来举个例子。
I、例题描述
软件开发的时候,会有版本的概念。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。假设你有
n
n
n 个版本
[
1
,
2
,
.
.
.
,
n
]
[1, 2, …, n]
[1,2,…,n],你想找出导致之后所有版本出错的第一个错误的版本。可以通过调用
bool isBadVersion(version)接口来判断版本号version是否在单元测试中出错。实现一个函数来查找第一个错误的版本。应该尽量减少对调用 API 的次数。
样例输入:5
5
5 和
b
a
d
=
4
bad = 4
bad=4
样例输出:4
4
4
原题出处: LeetCode 278. 第一个错误的版本
II、基础框架
- c++ 版本给出的基础框架代码如下,其中
bool isBadVersion(int version)是供你调用的 API,也就是当你调用这个 API 时,如果version是错误的,则返回true;否则,返回false;
// The API isBadVersion is defined for you.
// bool isBadVersion(int version);
class Solution {
public:
int firstBadVersion(int n) {
}
};
III、思路分析
- 由题意可得,我们调用它提供的 API 时,返回值分布如下:
- 000…000111…111
000…000111…111
000…000111…111
- 其中 0 代表
false,1 代表true;也就是一旦出现 1,就再也不会出现 0 了。 - 所以基于这思路,我们可以二分位置;
归纳总结为 2 种情况,如下:
1)当前二分到的位置m
i
d
mid
mid,给出的版本是错误,那么从当前位置以后的版本不需要再检测了(因为一定也是错误的),并且我们可以肯定,出错的位置一定在
[
l
,
m
i
d
]
[l, mid]
[l,mid];并且
m
i
d
mid
mid 是一个可行解,记录下来;
2)当前二分到的位置m
i
d
mid
mid,给出的版本是正确,则出错位置可能在
[
m
i
d
1
,
r
]
[mid+1, r]
[mid+1,r];
IV、时间复杂度
- 由于每次都是将区间折半,所以时间复杂度为
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n)。
V、源码详解
// The API isBadVersion is defined for you.
// bool isBadVersion(int version);
class Solution {
public:
int firstBadVersion(int n) {
long long l = 1, r = n; // (1)
long long ans = (long long)n + 1;
while(l <= r) {
long long mid = (l + r) / 2;
if( isBadVersion(mid) ) {
ans = mid; // (2)
r = mid - 1;
}else {
l = mid + 1; // (3)
}
}
return ans;
}
};
- (
1
)
(1)
(1) 需要这里,这里两个区间相加可能超过 int,所以需要采用 64 位整型long long;
- (
2
)
(2)
(2) 找到错误版本的嫌疑区间
[
l
,
m
i
d
]
[l, mid]
[l,mid],并且
m
i
d
mid
mid 是确定的候选嫌疑位置;
- (
3
)
(3)
(3) 错误版本不可能落在
[
l
,
m
i
d
]
[l, mid]
[l,mid],所以可能在
[
m
i
d
1
,
r
]
[mid+1, r]
[mid+1,r],需要继续二分迭代;
VI、本题小知识
二分时,如果区间范围过大,int难以招架时,需要动用long long;
收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。
[外链图片转存中…(img-pk9rmcbP-1715802598479)]
[外链图片转存中…(img-NPtymVNC-1715802598479)]
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









