






【一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义】
**开源地址:https://docs.qq.com/doc/DSmxTbFJ1cmN1R2dB **
因为这些原因,B+tree 索引要比 Hash 表索引有更广的适用场景。
物理存储角度看索引
MySQL 中的两种常用存储引擎对索引的处理方式差别较大。
InnoDB 的索引
首先看一下 InnoDB 存储引擎中的索引,InnoDB 表的索引按照叶子节点存储的是否为完整表数据分为聚簇索引和二级索引。

全表数据就是存储在聚簇索引中的。
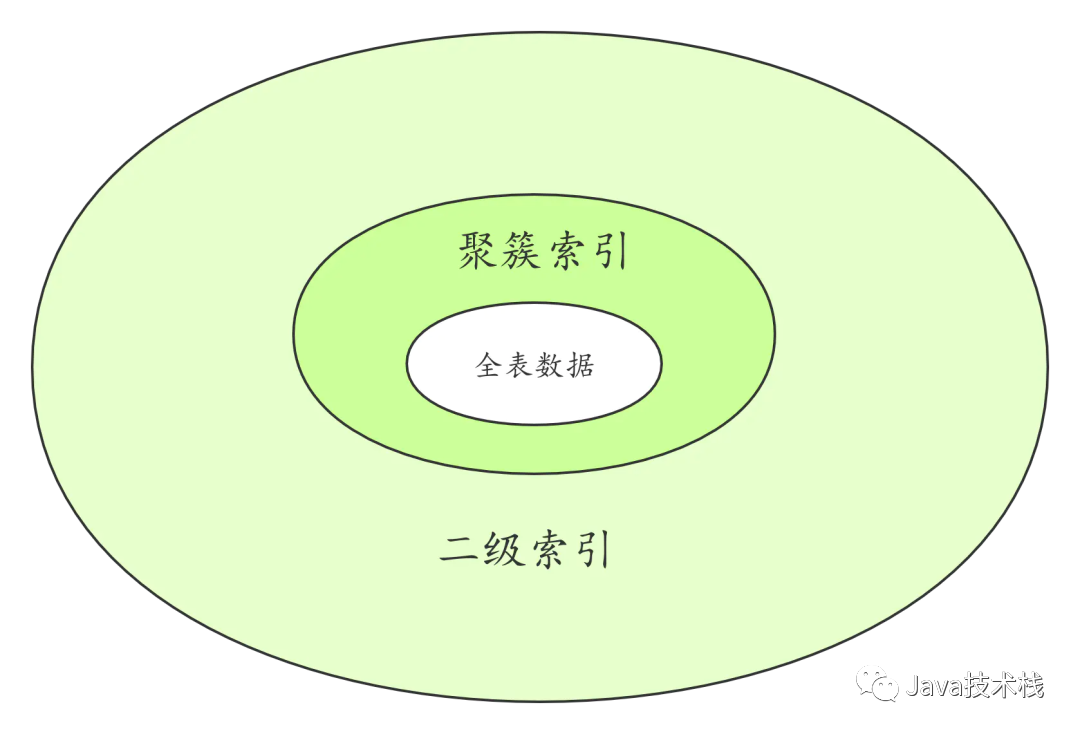 聚簇索引以外的其它索引叫做二级索引。点击关注公众号,Java干货****及时送达
聚簇索引以外的其它索引叫做二级索引。点击关注公众号,Java干货****及时送达
下面结合实际的例子介绍下这两类索引。
create table workers
(
id int(11) not null auto_increment comment ‘员工工号’,
name varchar(16) not null comment ‘员工名字’,
sales int(11) default null comment ‘员工销售业绩’,
primary key (id)
) engine InnoDB
AUTO_INCREMENT = 10
default charset = utf8;
insert into workers(id, name, sales)
values (1, ‘江南’, 12744);
insert into workers(id, name, sales)
values (3, ‘今何在’, 14082);
insert into workers(id, name, sales)
values (7, ‘路明非’, 14738);
insert into workers(id, name, sales)
values (8, ‘吕归尘’, 7087);
insert into workers(id, name, sales)
values (11, ‘姬野’, 8565);
insert into workers(id, name, sales)
values (15, ‘凯撒’, 8501);
insert into workers(id, name, sales)
values (20, ‘绘梨衣’, 7890);
我们现在自己的测试数据库中创建一个包含销售员信息的测试表 workers
包含 id(主键),name,sales 三个字段,指定表的存储引擎为 InnoDB。
然后插入 8 条数据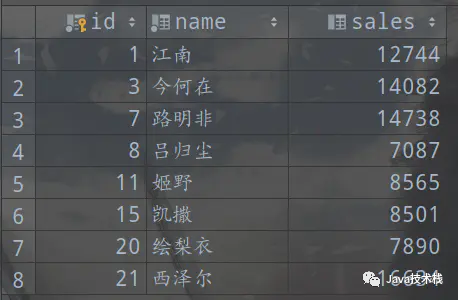
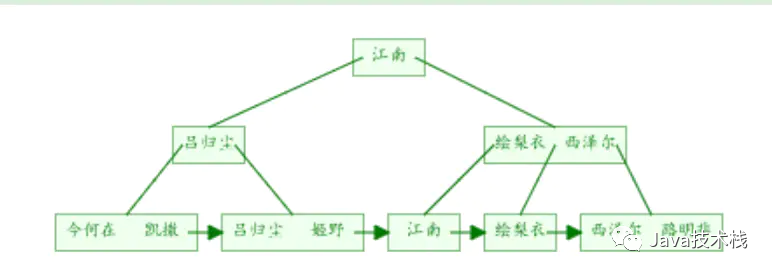
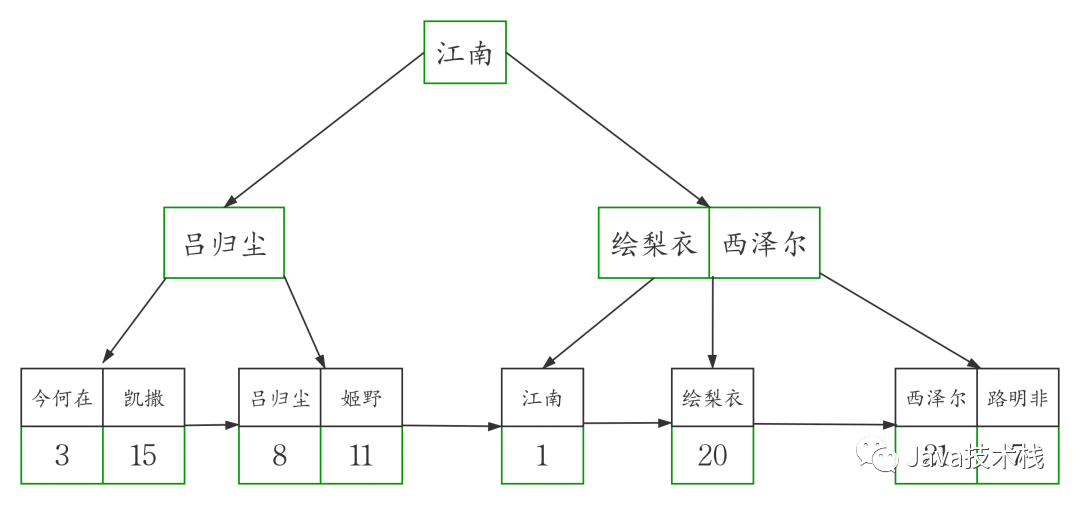
这个例子当中,workers 表的聚簇索引建立在字段 id 上
为了准确模拟,我们先把主键 id 插入 b+tree 得到下图
然后在此图基础上,我画出了高清版。
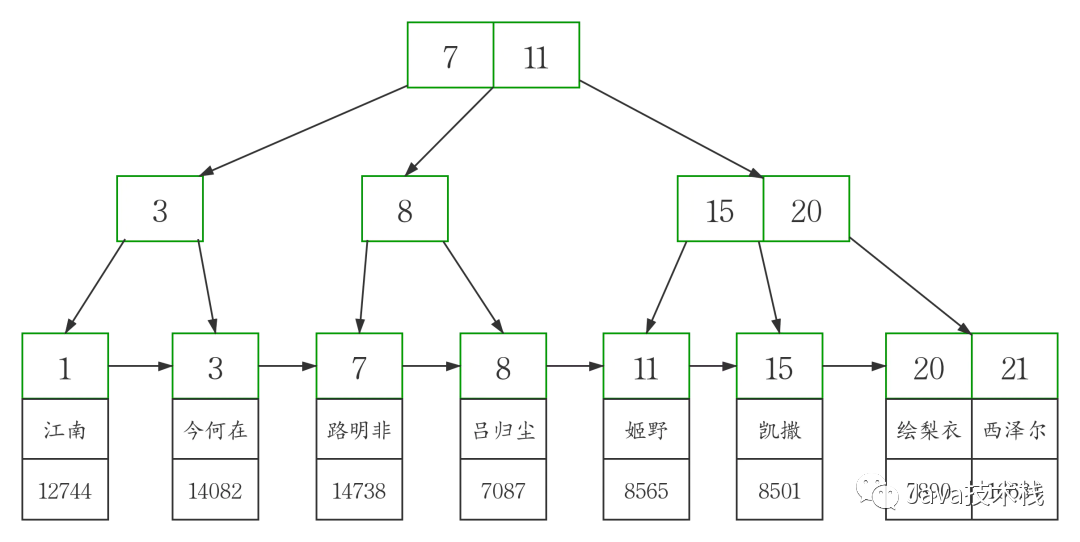
从图中可以看到,聚簇索引的每个叶子节点存储了一行完整的表数据,叶子节点间采用单向链表按 id 列递增连接,可以方便的进行顺序检索。
InnoDB 表要求必须有聚簇索引,默认在主键字段上建立聚簇索引,在没有主键字段的情况下,表的第一个 NOT NULL 的唯一索引将被建立为聚簇索引,在前两者都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列并在此列上创建聚簇索引。
推荐一个 Spring Boot 基础教程及实战示例:https://www.javastack.cn/categories/Spring-Boot/
接着来看二级索引。
还以刚才的 workers 表为例
我们在 name 字段上添加二级索引 index_name
alter table workers add index index_name(name);
同样我们画出了二级索引 index_name 的 B+tree 示意图
图中可以看出二级索引的叶子节点并不存储一行完整的表数据,而是存储了聚簇索引所在列的值,也就是workers 表中的 id 列的值。
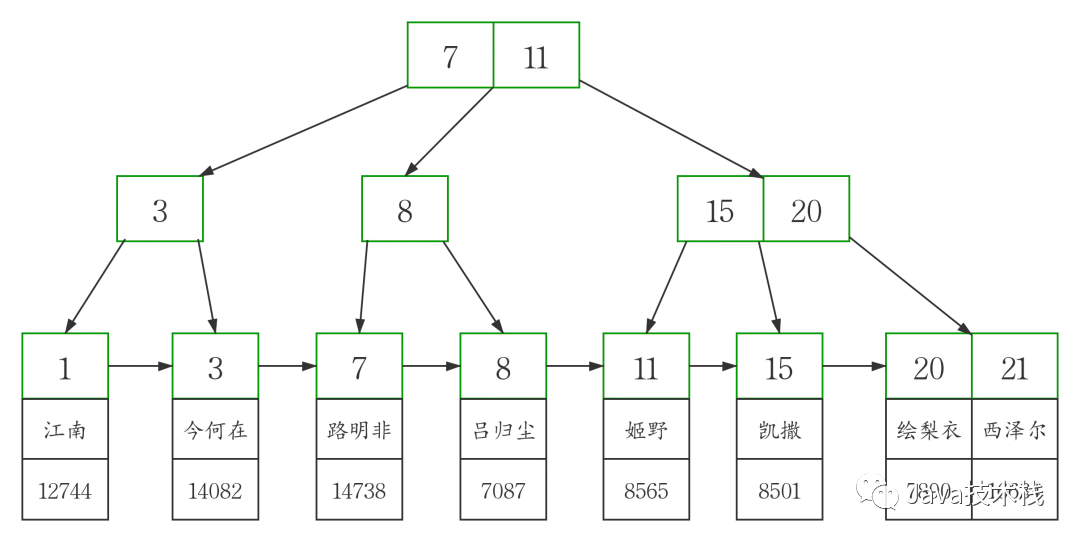
这两张示意图中 B+tree 的度设置为了 3 ,这也主要是为了方便演示。
实际的 B+tree 索引中,树的度通常会大于 100。
说了聚簇索引和二级索引 肯定要提到「回表查询」。
由于二级索引的叶子节点不存储完整的表数据,所以当通过二级索引查询到聚簇索引的列值后,还需要回到局促索引也就是表数据本身进一步获取数据。
比如说我们要在 workers 表中查询 名叫吕归尘的人
select * from workers where name=‘吕归尘’;
这条 SQL 通过 name='吕归尘’的条件
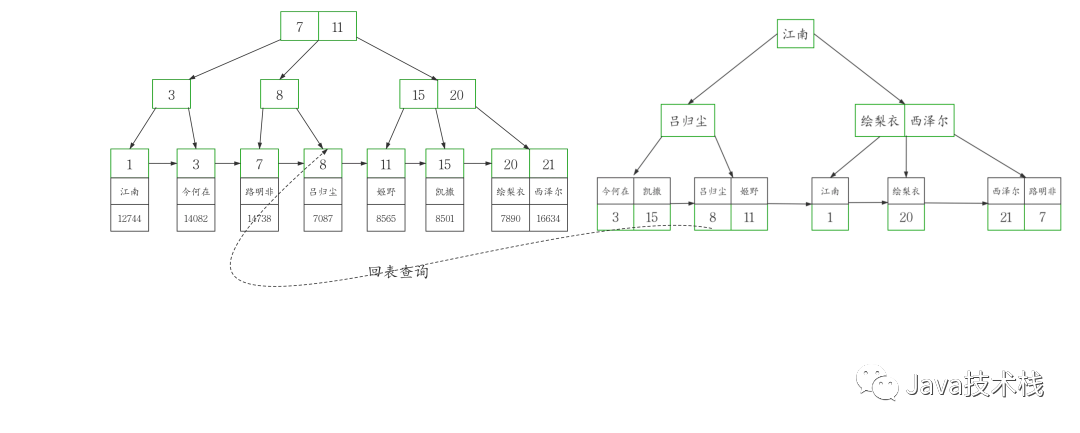
在二级索引 index_name 中查询到主键 id=8 ,接着带着 id=8 这个条件
进一步回到聚簇索引查询以后才能获取到完整的数据,很显然回表需要额外的 B+tree 搜索过程,必然增大查询耗时。点击关注公众号,Java干货****及时送达
需要注意的是通过二级索引查询时,回表不是必须的过程,当 Query 的所有字段在二级索引中就能找到时,就不需要回表,MySQL 称此时的二级索引为覆盖索引或称触发了 「索引覆盖」。
select id,name from workers where name=‘吕归尘’;
这句 SQL 只查询了 id,和 name,二级索引就已经包含了 Query 所以需要的所有字段,就无需回表查询。
explain select id,name from workers where name=‘吕归尘’;
使用 explain 查看此条 SQL 的执行计划 执行计划的 Extra 字段中出现了 Using where;Using index 表明查询触发了索引 index_name 的索引覆盖,且对索引做了 where 筛选,这里不需要回表。
执行计划的 Extra 字段中出现了 Using where;Using index 表明查询触发了索引 index_name 的索引覆盖,且对索引做了 where 筛选,这里不需要回表。
最新面试题整理好了,点击Java面试库小程序在线刷题。
下面做对比,查询一下没有索引的
explain select id,name,sales from workers where name=‘吕归尘’;

Extra 为 Using Index Condition 表示会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行。Index Condition Pushdown (ICP)是 MySQL 5.6 以上版本中的新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式。ICP 开启时的执行计划含有 Using index condition 标示 ,表示优化器使用了 ICP 对数据访问进行优化。
如果你对此感兴趣去查阅对应的官方文档和技术博客。
这次我们简化来理解,不考虑 ICP 对数据访问的优化,当关闭 ICP 时,Index 仅仅是 data access 的一种访问方式,存储引擎通过索引回表获取的数据会传递到 MySQL Server 层进行 WHERE 条件过滤。
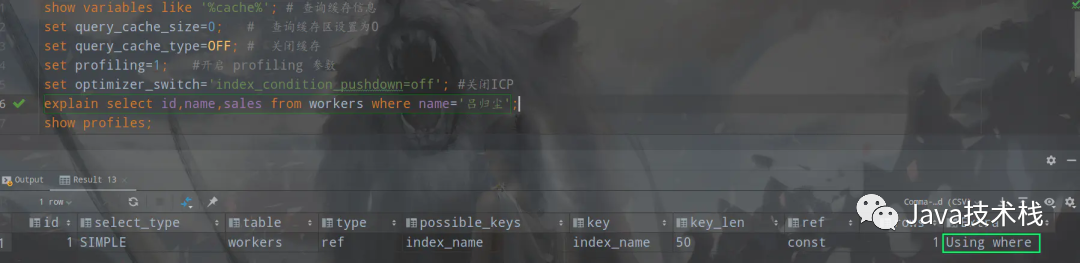
Extra 为 Using where 只是提醒我们 MySQL 将用 where 子句来过滤结果集。这个一般发生在 MySQL 服务器,而不是存储引擎层。一般发生在不能走索引扫描的情况下或者走索引扫描,但是有些查询条件不在索引当中的情况下。
这里表明没有触发索引覆盖,进行回表查询。
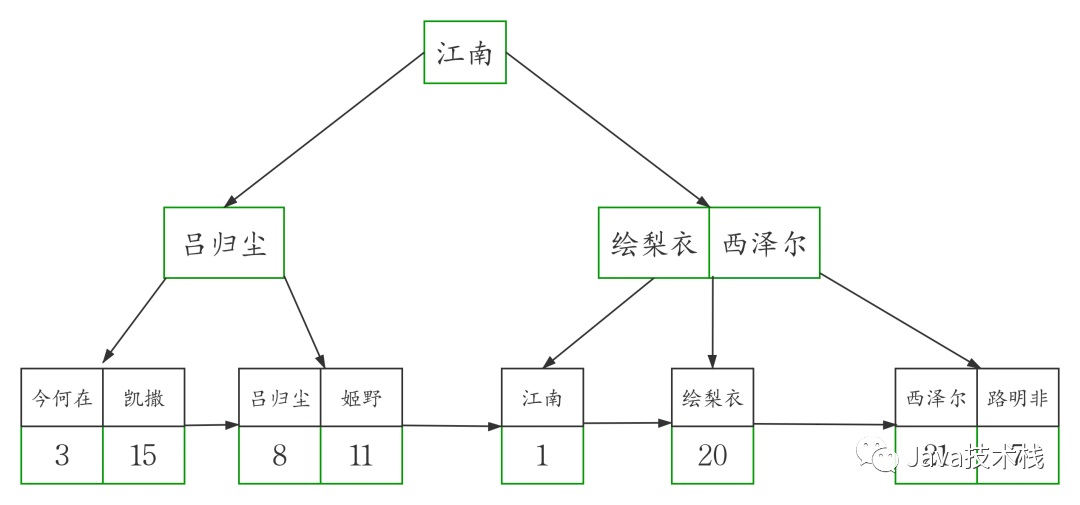
MyISAM 的索引
说完了 InnoDB 的索引,接下来我们来看 MyISAM 的索引
以 MyISAM 存储引擎存储的表不存在聚簇索引。
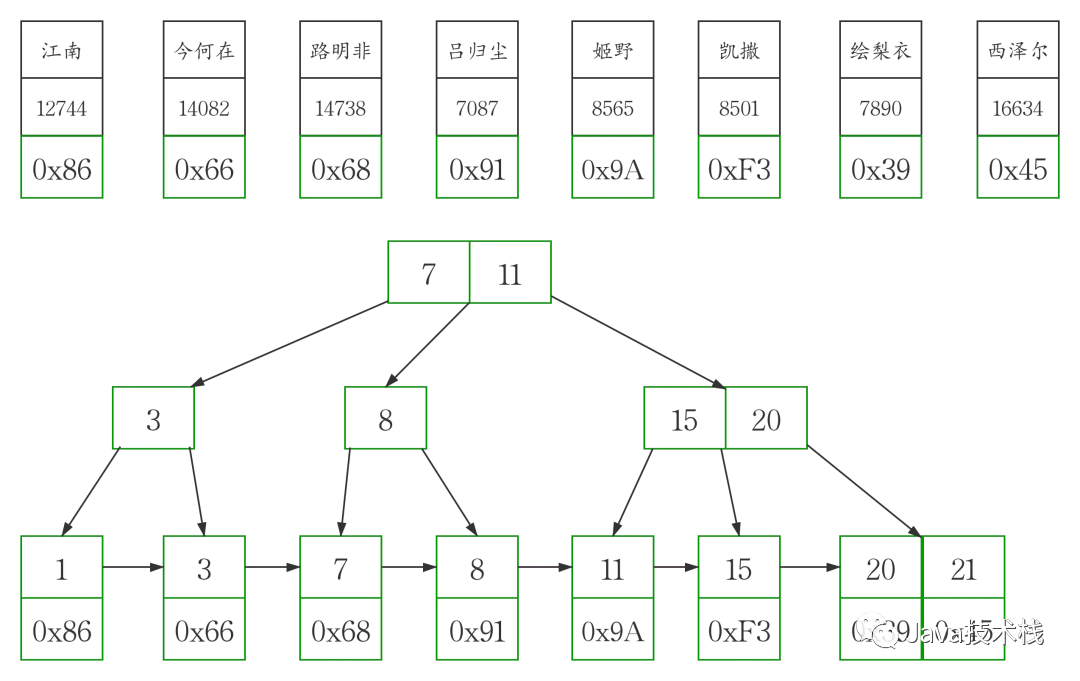
MyISAM 表中的主键索引和非主键索引的结构是一样的,从上图中我们可以看到
他们的叶子节点是不存储表数据的,节点中存放的是表数据的地址,所以 MyISAM 表可以没有主键。
MyISAM 表的数据和索引是分开的,是单独存放的。
MyISAM 表中的主键索引和非主键索引的区别仅在于主键索引 B+tree 上的 key 必须符合主键的限制,
非主键索引 B+tree 上的 key 只要符合相应字段的特性就可以了。
索引字段特性角度看索引
create table persons
(
id int(11) not null auto_increment comment ‘主键id’,
eno int(11) comment ‘工号’,
eid int(11) comment ‘身份证号’,
veid int(11) comment ‘虚拟身份证号’,
name varchar(16) comment ‘名字’,
primary key (id) comment ‘主键索引’,
UNIQUE key (eno) comment ‘eno唯一索引’,
UNIQUE key (eid) comment ‘eid唯一索引’
) engine = InnoDB
auto_increment = 1000
default charset = utf8;
alter table persons
add unique index index_veid (veid) comment ‘veid唯一索引’;
通过 show index from persons;命令我们看到已经成功创建了三个唯一索引。
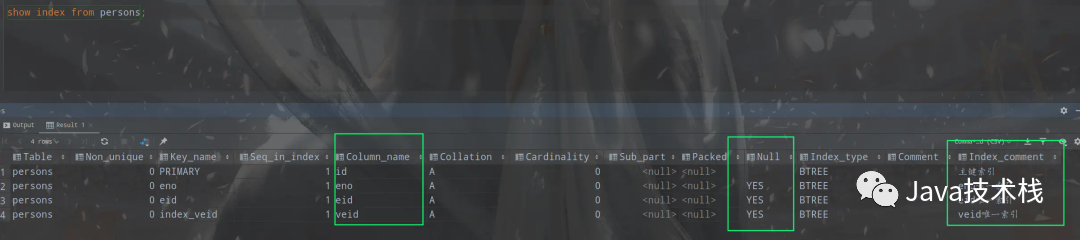
普通索引
主键索引和唯一索引对字段的要求是要求字段为主键或 unique 字段,
而那些建立在普通字段上的索引叫做普通索引,既不要求字段为主键也不要求字段为 unique。
另外,关注公众号Java技术栈,在后台回复:面试,可以获取我整理的 MySQL 系列面试题和答案,非常齐全。
前缀索引
前缀索引是指对字符类型字段的前几个字符或对二进制类型字段的前几个 bytes 建立的索引,而不是在整个字段上建索引。
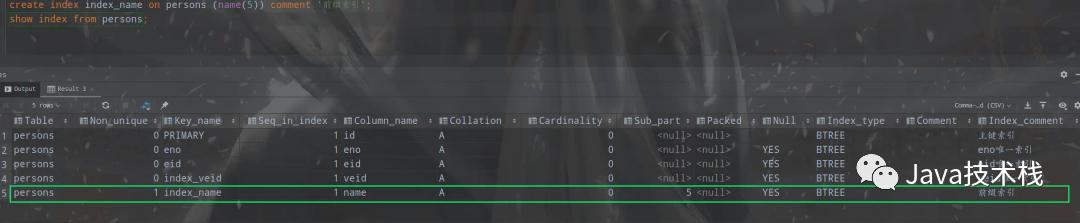
例如,可以对 persons 表中的 name(varchar(16))字段 中 name 的前 5 个字符建立索引。
create index index_name on persons (name(5)) comment ‘前缀索引’;
show index from persons;















 225
225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









