






本篇内容包含AI绘画扩散模型工作原理浅析和ComfyUI入门知识,并徒手搓出一个“文生图”工作流和“图生图”工作流
需要ComfyUI工作流及教程的小伙伴,下方扫码获取!


这是一个基础工作流(workflow),它包含7个节点(node)和若干连线。一个节点负责完成一项独立的事情,多个节点有序的连接起来就组成了一个完成特定AI绘画任务的工作流。第一次接触 ComfyUI 的选手,特别是不熟悉理工科逻辑思维的文科选手会觉得头大。没关系,这个图先看看就好,我们将从0开始构建这个工作流。
理线头要找最关键的那根,看问题要抓核心。这个基础工作流最核心的节点,是中间那个连线最多、参数最多的“K采样器”节点。我们就从它开始。

要说清楚这个K采样器,需要先解释三个概念:扩散、采样、潜空间(latent)。
「什么是扩散」
我们下载下来的动辄几个G的.ckpt或.safesensor的文件,学名叫做“diffusion model”(扩散模型)。
“扩散”是一种操纵“噪点”的艺术。它有两个分支:往一张图片里添加噪点,和从一张图片中去除噪点。前者就是所谓的“训练模型”的过程(前向扩散),后者则是画图的过程(反向扩散)。
 (前向扩散:添加噪点 -> 用于训练)
(前向扩散:添加噪点 -> 用于训练)
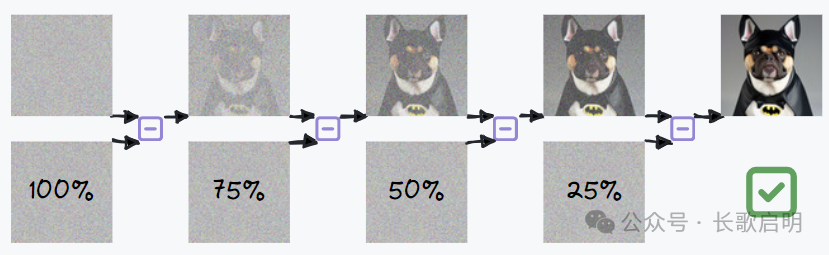 (反向扩散:去除噪点 -> 用于画图)
(反向扩散:去除噪点 -> 用于画图)
模型是怎么训练的呢?给一张狗的照片逐步增加噪声,它会越来越不可辨认,直到最终一片混沌。给这张狗片添加的每一张噪点,组合起来形成了一种“规律”。当把足够多的狗片变成混沌的噪点图片后,这些“噪点图片的集合”就成为了一种更加通用的、把狗噪点化的规律。
模型就是这些“噪点图片”的集合,模型就是“噪点规律”的集大成者。
那么既然我们掌握了如何把狗片完全噪点化的规律,那么把规律反过来用,就能够稳定的从一张噪点图中通过逐步去除噪点,还原出一只狗来。
这就是扩散模型绘图原理的最简化理解。
「什么是采样」
现在我们就可以解释什么是采样了:从大模型中采集噪点规律,使用这个规律从噪点图片一步一步还原出人类世界的图像。
这就是为什么“采样器”是整个工作流的核心,它负责生成图片。这也是为什么AI绘图模型都那么“大”,客观人类世界的通用规律可不少。
但这里有个问题,即便是一张256x256的图片,要把它完全噪点化也是非常费时费力的,这会导致“训练模型”的过程异常缓慢。潜空间就是为了解决这个问题而引入的。
「什么是潜空间」
人们发现,其实“训练”这个过程并不需要整张图的信息,可以采用某种方式把添加噪点的过程简化。
这个做法的底层思路是,人类使用的图片大都具有规律。比如说哺乳动物的头,基本上都是眼睛下面有鼻子,鼻子下面有嘴。再比如一辆车的最下面一定是轮毂和轮胎,不可能是个西瓜,或是什么别的东西。
人类世界的图片呈现出的“规律性”,称为“流形假说”。
所以,实际上我们需要对模型的训练(对图片的加噪过程)的次数,要远比我们预想的少很多,在非常有限的次数内,就能够完成加噪训练的过程。精简过次数的加噪图会被尽可能的压缩,对人类而言是完全不可识别的。
我们把原来可识别的图片(比如PNG、JPG)所处的维度称为“高维空间”或者“像素空间”,而把被压缩处理过的人类不可识别的数据所处的维度称为“潜空间” latent。后者比前者要小48倍,这大大提升训练和图片生成速度。
所以“潜空间”实际上是个“外挂”,它让“扩散”这件事情更高效了。通过在整个工作中加入“潜空间”完成绘图(扩散加噪)的过程,就称之为 “Latent Diffusion” 即潜空间扩散 。而 Stable Diffusion 则是在 Latent Diffusion 的基础上,进行了数量更多、尺寸更大、质量更好的图片的学习训练。相对来说Stable Diffusion 的训练和出图质量比单纯的 Latent Diffusion 更加稳定可靠,所以它才被叫做 “Stable Diffusion”,也就是“(更加)稳定(的)扩散”。
小知识点1:现在网上很多滑水教学主播,把A1111 WebUI 直接称作 Stable Diffusion 是不对的,Stable Diffusion 是一种公开的技术方案,WebUI 和 ComfyUI 都是这个论文方案的一种实现。一个是理论,一个是根据理论做出来的工具。但凡分不清这二者的博主,你都可以基本推断他的教程是拼凑出来的,他自己也不一定懂。
小知识点2:大名鼎鼎的 Midjourney 和 OpenAI 的 dall-e,都是根据扩散模型理论制作的工具。他们和 webui 以及 comfyui 的区别,前二者是商业工具,后面是开源工具。
OK,解释完了扩散、采样、潜空间,让我们再次回到这个所谓的“K采样器”上。
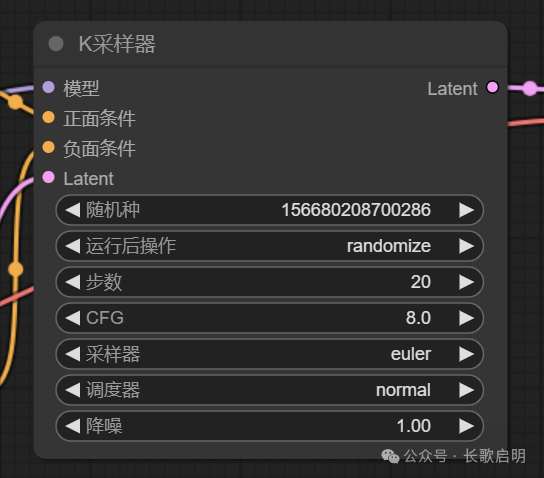
现在上面这个最奇怪的 latent 参数就非常好理解了:K采样器需要一个完全噪点的潜空间,把它从模型中采样出来的“规律噪点”应用在潜空间里面,它需要一个空的潜空间作为输入;K采样器在潜空间完成“降噪”后,生成好的低维潜空间图像,通过这个输出出口将结果交给下一个节点,以便将图片从潜空间“捞”出来并还原成人类能够识别的像素图片。
「从0到1」
所以创建一个工作流的第一步,就是加载一个K采样器。在任意位置单击右键:
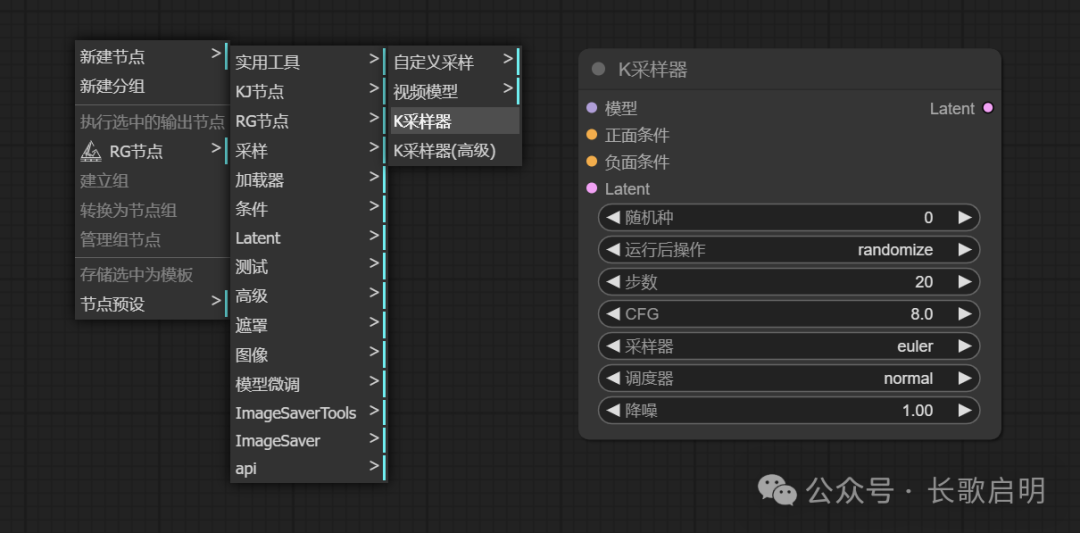 右键 -> 新建节点 -> 采样 -> K采样器
右键 -> 新建节点 -> 采样 -> K采样器
第二步,加载一个空的潜空间,然后把这个空潜空间的输出,用鼠标拖一条线到K采样器的输入上:
 右键 -> 新建节点 -> Latent -> 空Latent
右键 -> 新建节点 -> Latent -> 空Latent
第三步,加载一个 VAEDecoder,从K采样器的输出拖一根线,到它的输入。
正如上一节提到的,K采样器在潜空间完成图片的“绘制”(一遍遍降噪)后,要把潜空间交给下一个节点,将图片从潜空间还原出来。负责还原图片的节点就是这个 VAEDecoder(变分自动解码器),它是整个工作流的最后一步,负责把图片还原为人类可以识别的样子。
 右键 -> 新建节点 -> Latent -> VAE解码
右键 -> 新建节点 -> Latent -> VAE解码
我们还剩下最后一个问题:文字究竟是如何操纵/指导采样器,生成出所描述的图像的?
大模型本身是无法理解人类自然语言的,所以为了把人话翻译成模型能听懂的话,自然语言经历了一个转换过程(标记化-向量化-嵌入),转换的结果会交给模型中一个叫做噪声预测器(UNET)的东西,用来“预测”从大模型中采样哪些噪点规律。整个文字的转换过程由一个叫 CLIP 的模型实现,这就是我们在 WebUI 或者 ComfyUI 上看到的正向提示词输入框和反向提示词输入框,它可不仅仅是个普通的文本框那么简单。
这种使用CLIP模型,将人类的自然语言,转化成大模型能理解的机器语言的过程,我们就称其为“CLIP编码”,对应的节点就叫做“CLIP文本编码器”。当然直观上,它就是一个输入框。
我们加载两个输入框,一个用于正向提示词,一个用于负向提示词。并把CLIP的输出,各拖一条线到K采样器的对应输入上。
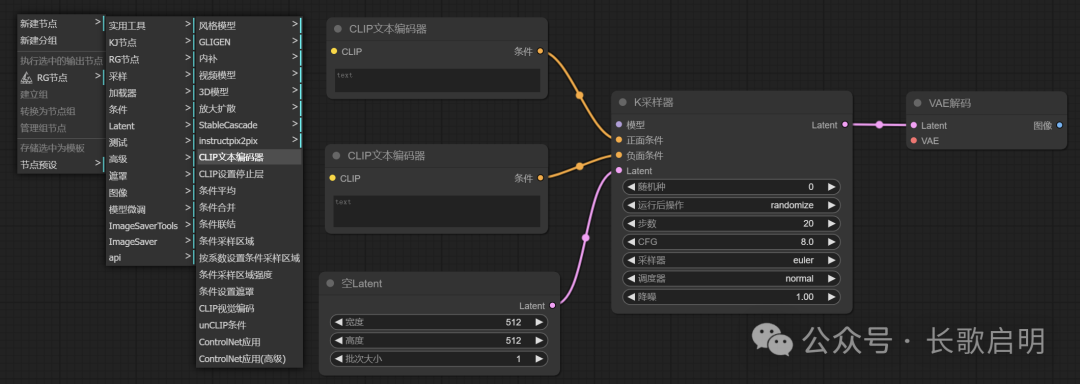 右键 -> 新建节点 -> 条件 -> CLIP文本编辑器
右键 -> 新建节点 -> 条件 -> CLIP文本编辑器
最后一步,也是最简单的一步,加载模型和图像输出节点。把模型的CLIP输出给到两个输入框。
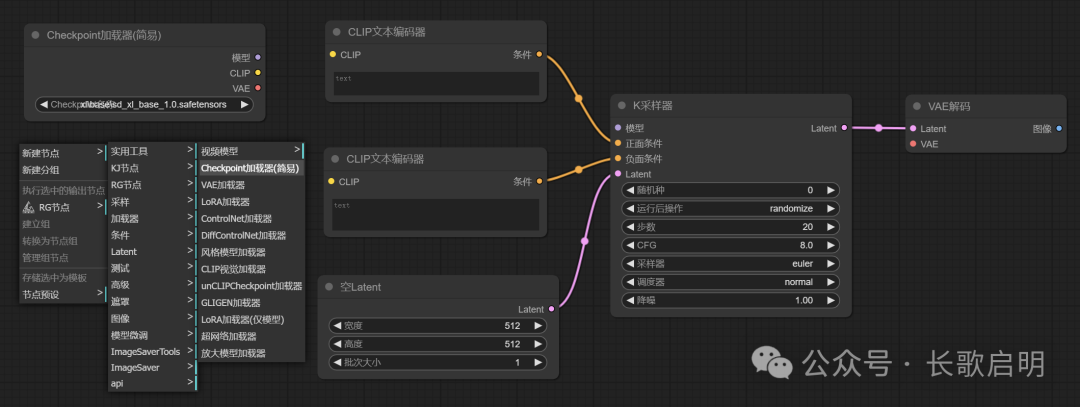 右键 -> 新建节点 -> 加载器 -> checkpoint加载器
右键 -> 新建节点 -> 加载器 -> checkpoint加载器

右键 -> 新建节点 -> 图像 -> 预览图像/保存图像
到此为止,一个基础工作流的所有节点我们就都创建出来了。但我们还不能直接运行,还缺几根线。此时直接 CTRL+ENTER,ComfyUI 会给出错误提示。(注意它画红圈的部分)
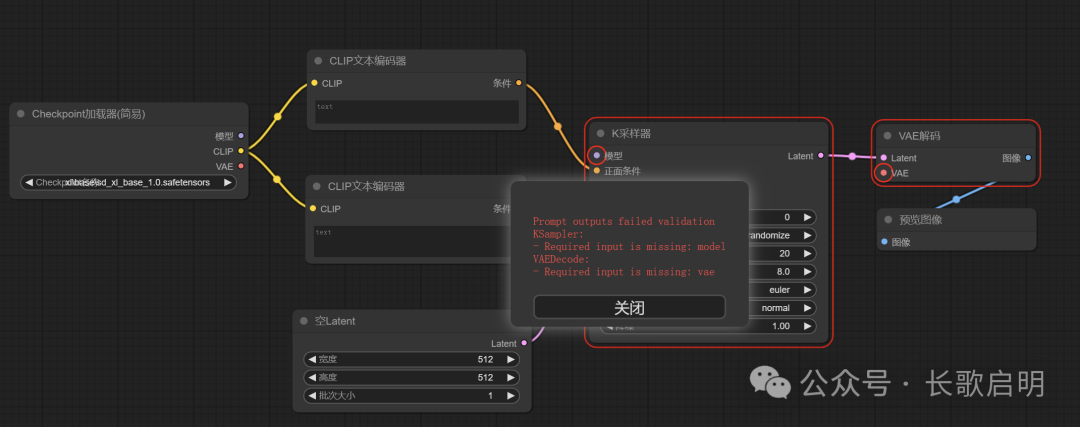
问题1:K采样器还缺少一个模型的输入,这是当然的,不给K采样器模型输入,要从哪里采样噪点呢?我们把模型加载器的输出拉条线到K采样器的模型输入上。
问题2:我们的VAE解码器缺一个VAE输入,这个输入从哪里来呢?注意模型加载器那里刚好有一个VAE输出,我们直接拉条线过去。
这也就是为什么,我们从C站等模型仓库下载模型时,模型的作者都会附上一句:“我的模型已经包含/不包含VAE”。这句话非常重要!如果模型本身不包含VAE,那么就算从模型加载器这里拉线过去,生成的图像也是不符合预期的。当模型不自带VAE时,我们需要另外加载一个叫做“VAE加载器”的节点,单独加载VAE并把输出拉根线到解码器上。
补充了这两条线后,这个最基础的工作流就可以工作了,随便写一点提示词,CTRL+ENTER:元神,启动!(我在说什么。。。)
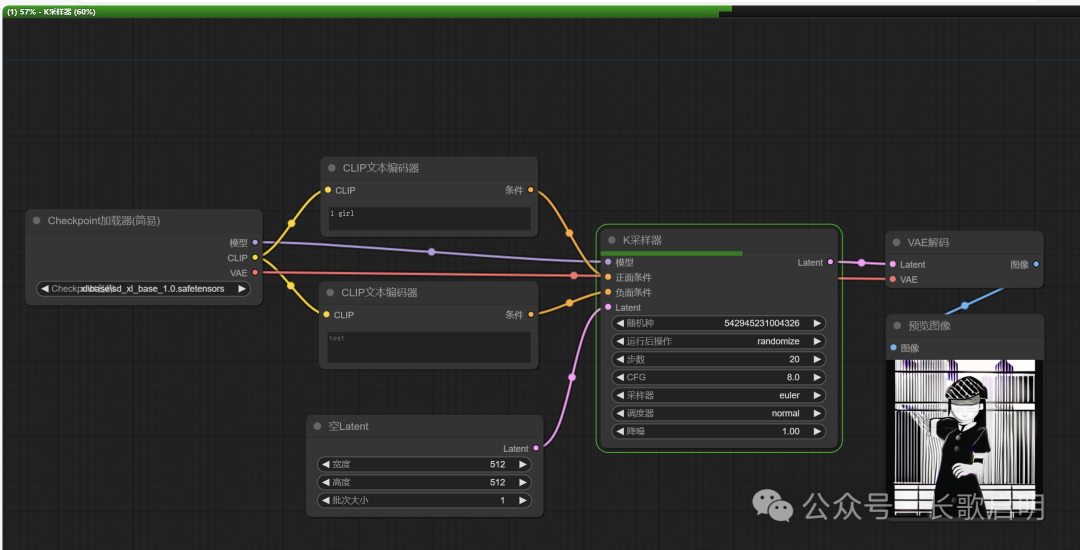
上方有一上一下两个进度条,上面的进度条表示整个工作流的运行进度,下面的进度条表示当前节点的运行进度。绿色的框标识出当前已执行到哪一个节点。最后图像节点会将解码好的图片展示出来。(不要在意图片质量,毕竟提示词只有一个词而已)
至此,我们徒手搓了一个“文生图”的ComfyUI工作流。
「K采样器的其他参数解释」
随机种:控制采样器从模型中抽取噪点的一致性。如果随机种是固定的,那么在其他所有节点和参数不变的情况下,从潜空间还原出来的图像会是一模一样的一张图。
运行后参数:当选择 randomize随机 时,每次绘图后采样器会随机重置“随机种”,选择 固定 则种子会保持“不变”。“增加”和“减少”则会在每次绘图完成后给种子略微加减,通常用于批量跑图开盲盒。
步数:即K采样器要从模型中抽取多少次噪音,并应用到潜空间中。步数和采样器有直接关系,有的采样器采样精细,意味着每次只能从潜空间去掉一点点噪声,也就意味着需要高步数才能完成绘图步骤,比如 DPM 采样方式;而有的采样器则步子迈得比较大,采样粗犷但是能够快速成图,比如常用的 EULER 采样方式。
降噪:即采样器从模型中抽取的噪点,要在多大程度/多大比率上应用到潜空间中。对于文生图来说,我们肯定是希望尽可能快速且全面的进行降噪,所以这里是1.00。而对于图生图或ControlNet等场景而言,就不一定是1了。
关于采样器和调度器,是另外一个很大得话题,一两句话说不完,需要单开一篇讲。
「附加题」
我们刚刚给到采样器的潜空间,是一个空的潜空间。采样器会在这个空的潜空间初始化一个全噪点图片。那么如果我们给采样器的不是一个空潜空间,而是一个有内容的潜空间呢?这其实就是“图生图”的底层逻辑。
当然图像是不能直接给采样器的,图像处在“高维像素空间”,所以我们在”加载图像“节点后面,还要加一个“VAE编码器”来把它打到潜空间去,并将VAE编码的输出给到采样器。
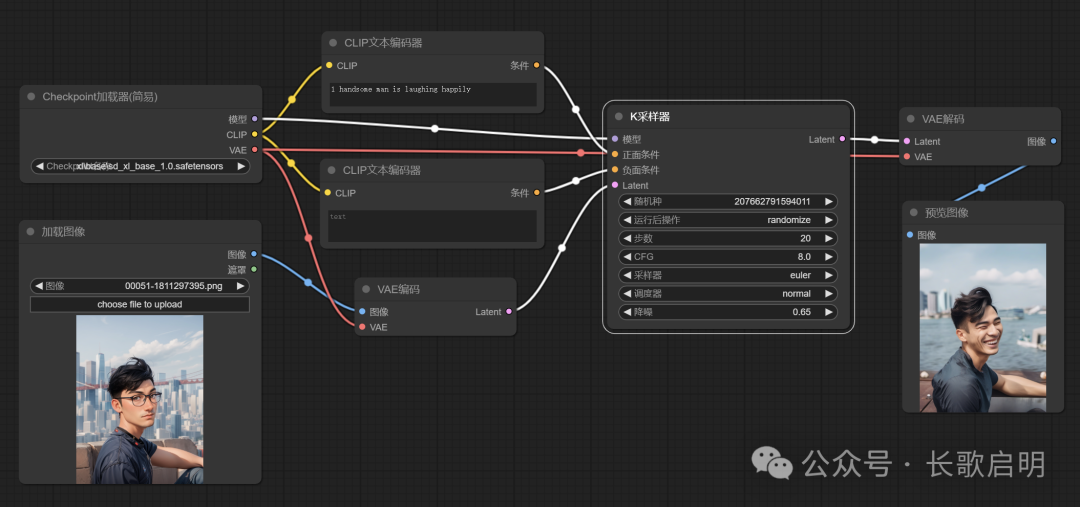
这时候我们需要调整K采样器的“降噪”这个参数,如果保持1(100%)不变,那么生成的图片会完全不像参考图片。值越小表示越参考图片。这里调整为0.65(65%),也就是保留原图35%的特征。
这就是一个基础版的“图生图”工作流。
「作业」
本篇教程完整手搓了“文生图”和“图生图”绘画工作流,大家可以对照 A1111 WebUI 的文生图和图生图操作步骤,对比一下两种绘画工具的使用体验。

写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









