






| now-1h/d | 2001-01-01 00:00:00 |
| 2001.02.01\|\|+1M/d | 2001-03-01 00:00:00(2001.02.01加上1个月,再向下舍入到最近一天) |
Response Filtering
这是对响应进行过滤,用户可以通过过滤查看自己关注的信息,例如如下请求:
curl -X GET “localhost:9200/_search?filter_path=took,hits.hits._id,hits.hits._score&pretty”
请求结果如下:
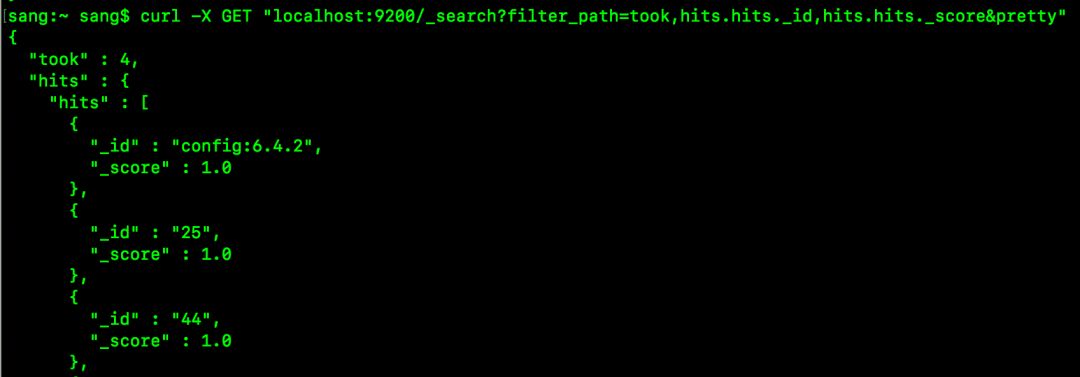
这里还支持使用 *通配符去匹配filed名称或者field名称中的部分字符,如下:
curl -X GET “localhost:9200/_cluster/state?pretty&filter_path=metadata.indices..stat”
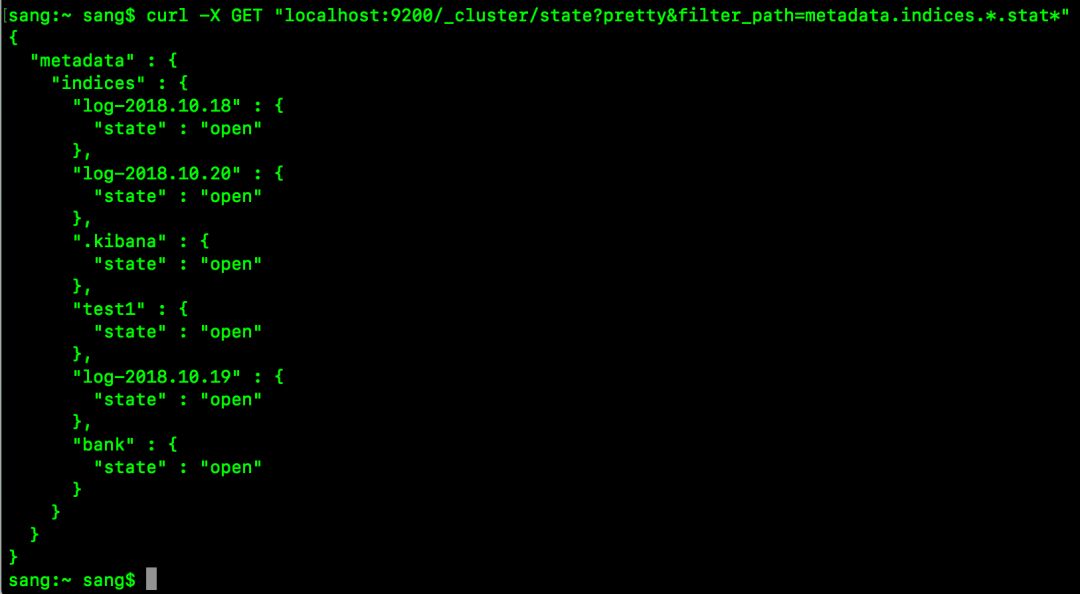
还可以使用 **指定包括字段,但是不知道字段确切路径的请求,如下:
curl -X GET “localhost:9200/_cluster/state?pretty&filter_path=routing_table.indices.**.state”
执行结果如下:
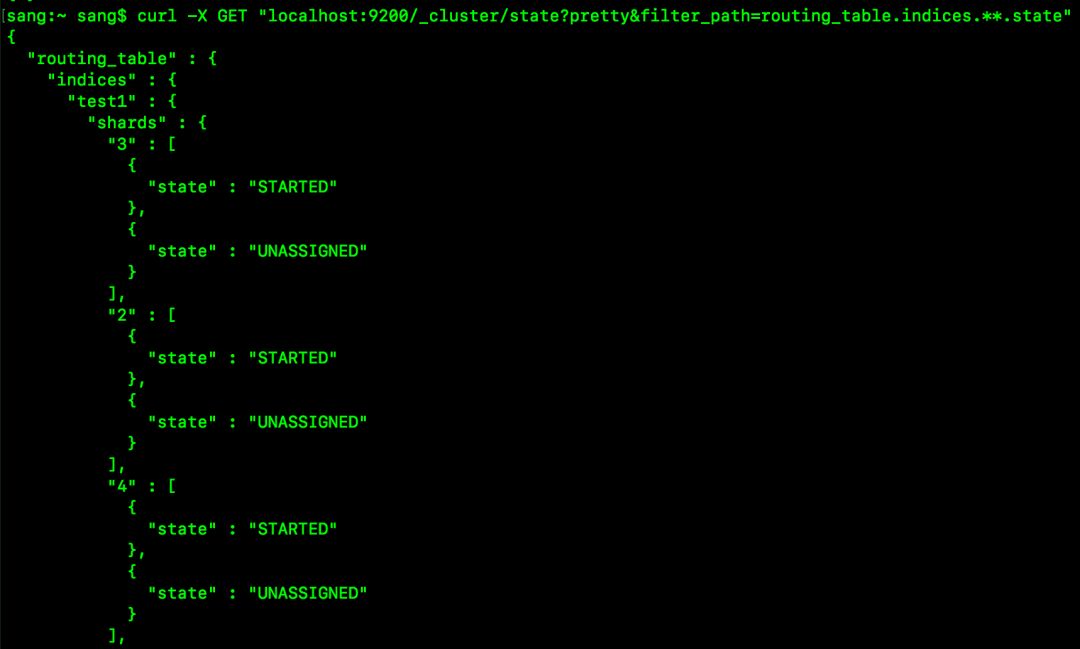
也可以在字段前加上 -前缀来排除一个或者多个字段,例如如下请求:
curl -X GET “localhost:9200/_count?pretty&filter_path=-_shards”
执行结果如下:

为了实现更多控制,inclusive和exclusive可以出现在同一个表达式中,此时首先使用exclusive filters,然后再对过滤的结果使用inclusive filters,例如如下案例:
curl -X GET “localhost:9200/_cluster/state?pretty&filter_path=metadata.indices..state,-metadata.indices.log-”
执行结果如下:
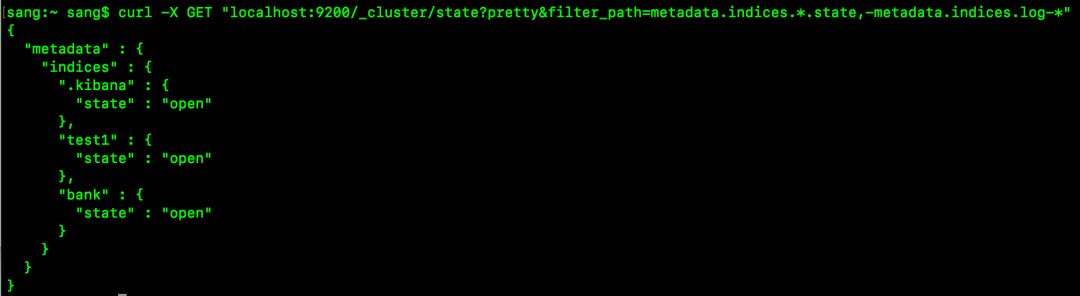
对于 _source字段也可以直接过滤,可以结合 _source字段的参数,再加上filter_path即可实现,例如如下请求:
curl -X POST “localhost:9200/library/book?refresh” -H ‘Content-Type: application/json’ -d’
{“title”: “Book #1”, “rating”: 200.1}
’
curl -X POST “localhost:9200/library/book?refresh” -H ‘Content-Type: application/json’ -d’
{“title”: “Book #2”, “rating”: 1.7}
’
curl -X POST “localhost:9200/library/book?refresh” -H ‘Content-Type: application/json’ -d’
{“title”: “Book #3”, “rating”: 0.1}
’
curl -X GET “localhost:9200/_search?pretty&filter_path=hits.hits._source&_source=title&sort=rating:desc”
执行结果如下:
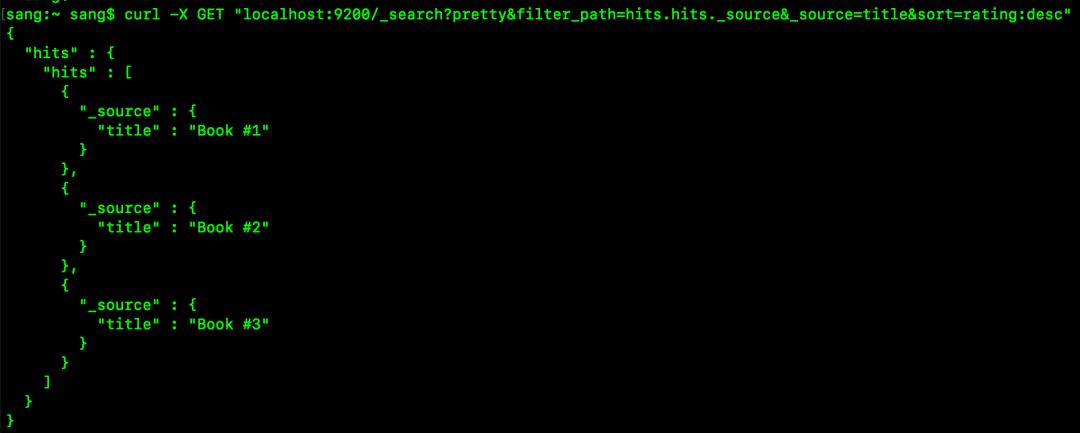
Flat Settings
这个还是用来设置响应格式,默认值为false,响应格式如下:
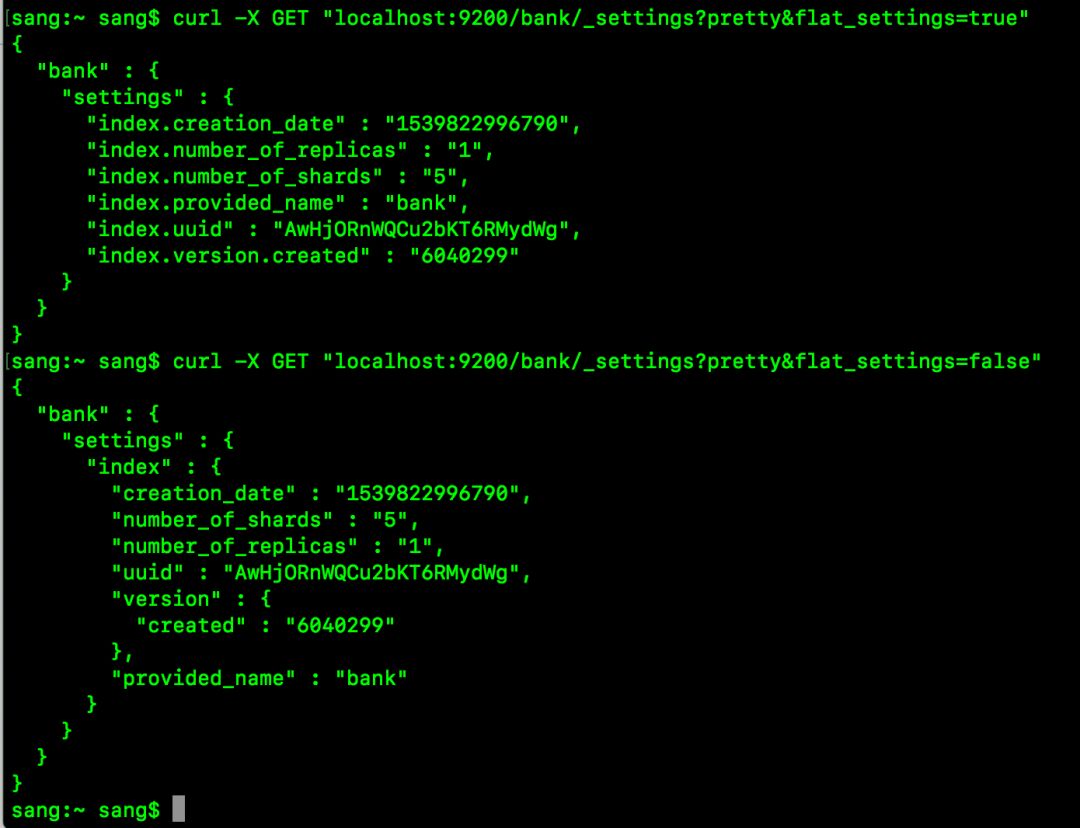
上图展示了flat_settings为true和false时的两种不同情况。
Parameters
REST参数(使用HTTP时,映射到HTTP URL参数)遵循使用下划线的约定。
Boolean Values
在请求参数或者请求体JSON中,都支持使用false来描述boolean值false,使用true来描述boolean值true。
Number Values
所有的REST API都支持在原生的JSON number基础之上,将numbered parameters作为字符串来提供。
Time units
每当需要指定durations时间时,时间必须指定单位,单位有如下几种:
| 符号 | 含义 |
| — | — |
| d | days |
| h | hours |
| m | minutes |
| s | seconds |
| ms | milliseconds |
| micros | microseconds |
| nanos | nanoseconds |
Byte size units
当需要指定数据的字节单位时,也需要指定单位,可用单位如下:
| 符号 | 含义 |
| — | — |
| b | Bytes |
| kb | Kilobytes |
| mb | Megabytes |
| gb | Gigabytes |
| tb | Terabytes |
| pb | Petabytes |
Unit-less quantities
无单位数量,意味者这些数量没有单位,但是如果这些数字比较大,直接打印出来可能不利于阅读,此时可以用10M代替10,000,000,用7k代替7000,用87代替87,支持的乘数有:
| 符号 | 含义 |
| — | — |
|
| Single |
| k | Kilo |
| m | Mega |
| g | Giga |
| t | Tera |
| p | Peta |
Distance Units
在需要指定距离单位的时候,如果没有指定,默认的距离单位是meter(米),也可以手动指定距离单位,支持的距离单位如下:
| 符号 | 含义 |
| — | — |
| mi/ miles | Mile |
| yd/ yards | Yard |
| ft/ feet | Feet |
| in/ inch | Inch |
| km/ kilometers | Kilometer |
| m/ meters | Meter |
| cm/ centimeters | Centimeter |
| mm/ millimeters | Millimeter |
| NM/ nmi/ nauticalmiles | Nauticalmile |
Fuzziness
fuzziness用来实现模糊查询,这里的模糊查询被定义为Levenshtein Edit Distance,指将一个字符串变为另外一个字符串所需要操作的步数,默认值为AUTO,AUTO策略如下:
-
字符长度在0~2之间,必须全部匹配
-
字符长度在3~5之间,允许编辑一次
-
字符长度大于5,允许编辑两次
例如,我的test1索引中,有一个文档的name属性值为sang,我可以使用如下方式查询:
curl -X GET “localhost:9200/test1/_doc/_search?pretty” -H ‘Content-Type: application/json’ -d’
{
“query”: {
“fuzzy”: {
“name”: “song”
}
}
}
’
song和sang有一个字符之差,但是由于字符长度为4,因此默认允许编辑一次,所以这个查询是可以查到相关结果的,如下:
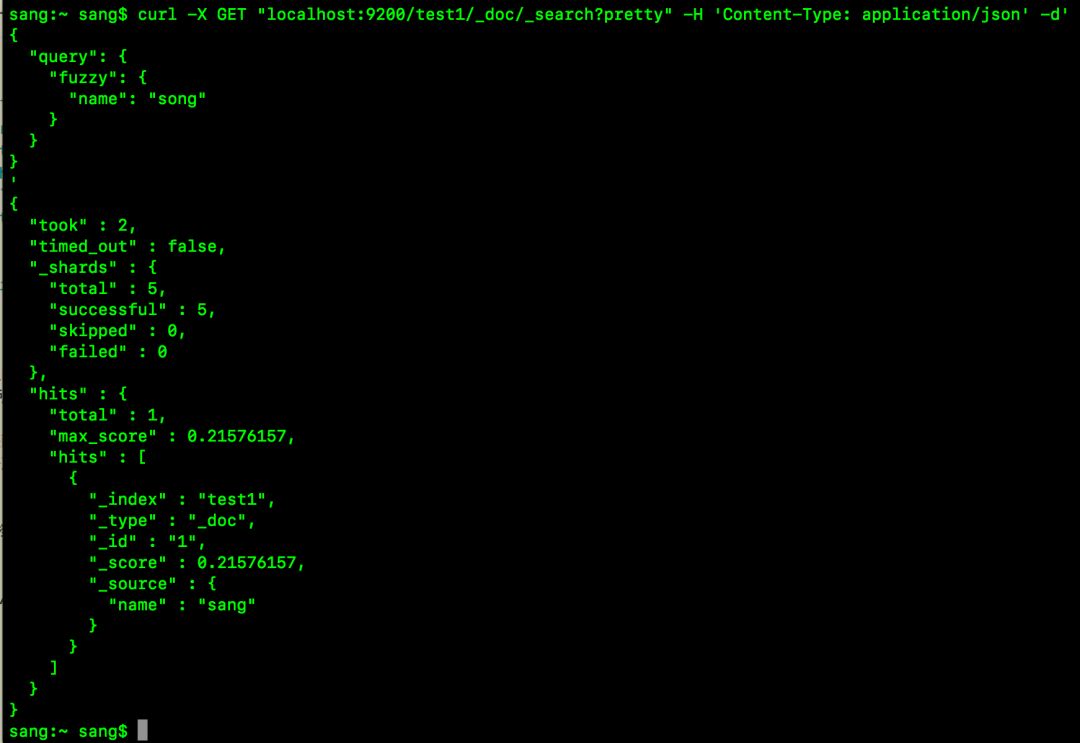
如果将song改为soog就会查询失败,此时,可以手动指定fuzziness的值,如下:
curl -X GET “localhost:9200/test1/_doc/_search?pretty” -H ‘Content-Type: application/json’ -d’
{
“query”: {
“fuzzy”: {
“name”: {
“value”: “soog”,
“fuzziness”: 2
}
}
}
}
’
上面的请求表示允许对字符编辑两次,如果编辑两次,则soog就可以匹配上sang了,如下:
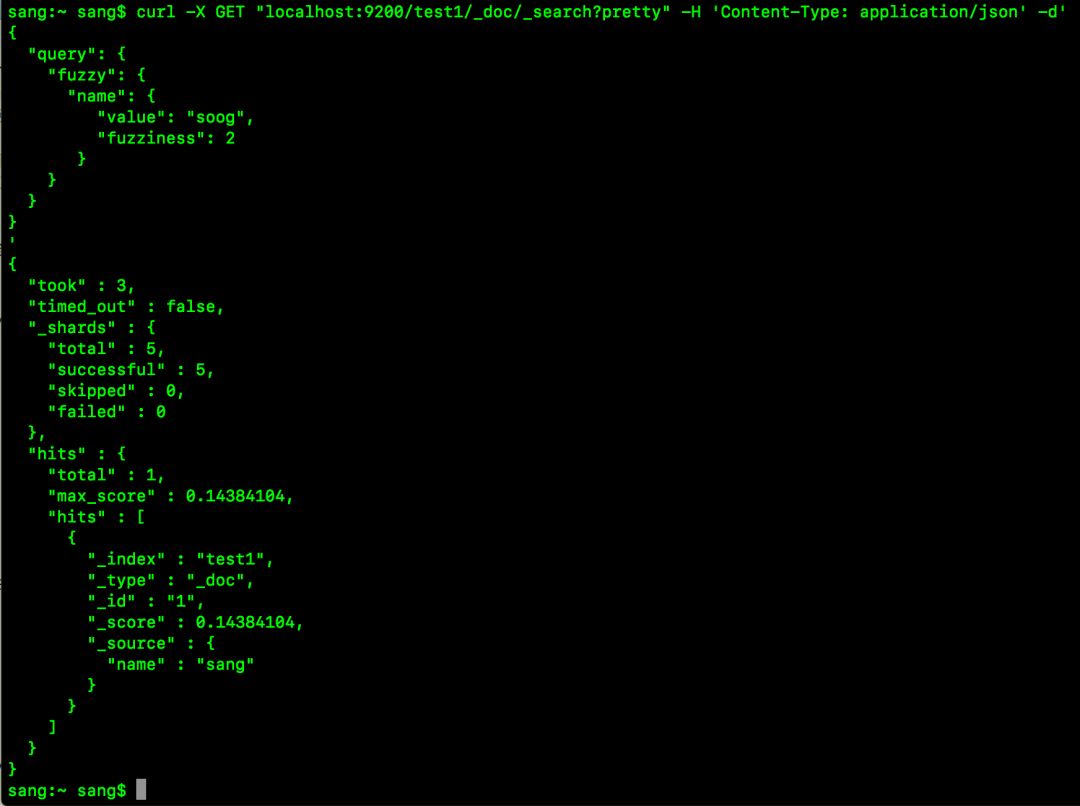
Enabling stack traces
默认情况下,当执行的请求出错时,不包括堆栈追踪信息,例如如下请求:
curl -X POST “localhost:9200/twitter/_search?size=surprise_me&pretty”
总结
上述知识点,囊括了目前互联网企业的主流应用技术以及能让你成为“香饽饽”的高级架构知识,每个笔记里面几乎都带有实战内容。
很多人担心学了容易忘,这里教你一个方法,那就是重复学习。
打个比方,假如你正在学习 spring 注解,突然发现了一个注解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。

人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。
ch?size=surprise_me&pretty"
总结
上述知识点,囊括了目前互联网企业的主流应用技术以及能让你成为“香饽饽”的高级架构知识,每个笔记里面几乎都带有实战内容。
很多人担心学了容易忘,这里教你一个方法,那就是重复学习。
打个比方,假如你正在学习 spring 注解,突然发现了一个注解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。
[外链图片转存中…(img-jM1RowsP-1719155625742)]
人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。















 1887
1887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









