






substring() 函数的形式为substring(startIndex,endIndex)。 它返回从startIndex到endIndex - 1的子字符串。
var s = “hello”;
( s.substring(1,4) == “ell” ) // true
#### 10、Object和Map的区别
JavaScript 的对象(Object),本质上是键值对的集合(Hash 结构),但是传统上只能用字符串当作键。这给它的使用带来了很大的限制。

const m = new Map();
const o = {p: ‘Hello World’};
m.set(o, ‘content’)
m.get(o) // “content”
m.has(o) // true
m.delete(o) // true
m.has(o) // false

将对象`o`当作`m`的一个键,然后又使用`get`方法读取这个键,接着使用`delete`方法删除了这个键。

const map = new Map([
[‘name’, ‘张三’],
[‘title’, ‘Author’]
]);
map.size // 2
map.has(‘name’) // true
map.get(‘name’) // “张三”
map.has(‘title’) // true
map.get(‘title’) // “Author”

Map 也可以接受一个数组作为参数。该数组的成员是一个个表示键值对的数组。
const map = new Map();
map.set([‘a’], 555);
map.get([‘a’]) // undefined
上面代码的`set`和`get`方法,表面是针对同一个键,但实际上这是两个不同的数组实例,内存地址是不一样的,因此`get`方法无法读取该键,返回`undefined`。

const map = new Map();
const k1 = [‘a’];
const k2 = [‘a’];
map
.set(k1, 111)
.set(k2, 222);
map.get(k1) // 111
map.get(k2) // 222

Map 的键实际上是跟内存地址绑定的,只要内存地址不一样,就视为两个键。
这就解决了同名属性碰撞(clash)的问题,我们扩展别人的库的时候,如果使用对象作为键名,就不用担心自己的属性与原作者的属性同名。
let map = new Map()
.set(1, ‘a’)
.set(2, ‘b’)
.set(3, ‘c’);
`set`方法返回的是当前的`Map`对象,因此可以采用链式写法。
#### 11、weakMap
`WeakMap`只接受**对象作为键名**(`null`除外),不接受其他类型的值作为键名
用途:

let myWeakmap = new WeakMap();
myWeakmap.set(
document.getElementById(‘logo’),
{timesClicked: 0})
;
document.getElementById(‘logo’).addEventListener(‘click’, function() {
let logoData = myWeakmap.get(document.getElementById(‘logo’));
logoData.timesClicked++;
}, false);
上面代码中,`document.getElementById('logo')`是一个 DOM 节点,每当发生`click`事件,就更新一下状态。
我们将这个状态作为键值放在 WeakMap 里,对应的键名就是这个节点对象。一旦这个 DOM 节点删除,该状态就会自动消失,不存在内存泄漏风险。
#### 12、(a == 1 && a == 2 && a ==3) 有可能是 true 吗?
当两个类型不同时进行==比较时,会将一个类型转为另一个类型,然后再进行比较。
比如`Object`类型与`Number`类型进行比较时,`Object`类型会转换为`Number`类型。
`Object`转换为`Number`时,会尝试调用`Object.valueOf()`和`Object.toString()`来获取对应的数字基本类型。
var a = {
i: 1,
toString: function () {
return a.i++;
}
}
console.log(a == 1 && a == 2 && a == 3) // true
#### 13、函数的length是多少?
可以看出,`function`有多少个形参,`length`就是多少;
但是如果有默认参数,就是`第一个具有默认值之前的参数个数;剩余参数是不算进`length`的计算之中的`
function fn1 (name) {}
function fn2 (name = ‘仙人掌’) {}
function fn3 (name, age = 22) {}
function fn4 (name, age = 22, gender) {}
function fn5(name = ‘仙人掌’, age, gender) { }
console.log(fn1.length) // 1
console.log(fn2.length) // 0
console.log(fn3.length) // 1
console.log(fn4.length) // 1
console.log(fn5.length) // 0
//剩余参数
function fn6(name, …args) {}
console.log(fn6.length) // 1
#### 14、includes 比 indexOf好在哪?
includes可以检测`NaN`,indexOf不能检测`NaN`,includes内部使用了`Number.isNaN`对`NaN`进行了匹配
#### 15、map、object和set的区别
map:对象保存键值对。任何值(对象或者原始值) 都可以作为一个键或一个值。构造函数`Map`可以接受一个数组作为参数。
object:
* 一个`Object` 的键只能是字符串或者 `Symbols`,但一个`Map` 的键可以是任意值。
* `Map`中的键值是有序的(FIFO 原则),而添加到对象中的键则不是。
* `Map`的键值对个数可以从 size 属性获取,而 `Object` 的键值对个数只能手动计算。
* `Object` 都有自己的原型,原型链上的键名有可能和你自己在对象上的设置的键名产生冲突。
set:对象允许你存储任何类型的值,无论是原始值或者是对象引用。它类似于数组,但是成员的值都是唯一的,没有重复的值。
总结:
* 初始化需要的值不一样,Map需要的是一个二维数组,而Set 需要的是一维 Array 数组
* Map 和 Set 都不允许键重复
* Map的键是不能修改,但是键对应的值是可以修改的;Set不能通过迭代器来改变Set的值,因为Set的值就是键。
* Map 是键值对的存在,值也不作为健;而 Set 没有 value 只有 key,value 就是 key;
#### 16、vue和react的diff算法的区别
vue和react的diff算法,都是忽略跨级比较,只做同级比较。vue diff时调动patch函数,参数是vnode和oldVnode,分别代表新旧节点。
1. vue比对节点,当节点元素类型相同,但是className不同,认为是不同类型元素,删除重建,而react会认为是同类型节点,只是修改节点属性
2. vue的列表比对,采用从两端到中间的比对方式,而react则采用从左到右依次比对的方式。当一个集合,只是把最后一个节点移动到了第一个,react会把前面的节点依次移动,而vue只会把最后一个节点移动到第一个。总体上,vue的对比方式更高效。
**虚拟dom**:一个用来标识真实DOM的对象
- 哈哈
- 呵呵
- 嘿嘿
对应的虚拟dom为:
let oldVDOM = { // 旧虚拟DOM
tagName: 'ul', // 标签名
props: { // 标签属性
id: 'list'
},
children: [ // 标签子节点
{
tagName: 'li', props: { class: 'item' }, children: ['哈哈']
},
{
tagName: 'li', props: { class: 'item' }, children: ['呵呵']
},
{
tagName: 'li', props: { class: 'item' }, children: ['嘿嘿']
},
]
}
这时候,我修改一个li标签的文本:
<ul id="list">
<li class="item">哈哈</li>
<li class="item">呵呵</li>
<li class="item">哈哈哈哈</li> // 修改
</ul>
这就是咱们平常说的新旧两个虚拟DOM,这个时候的新虚拟DOM是数据的最新状态,那么我们直接拿新虚拟DOM去渲染成真实DOM的话,效率真的会比直接操作真实DOM高吗?那肯定是不会的,看下图:
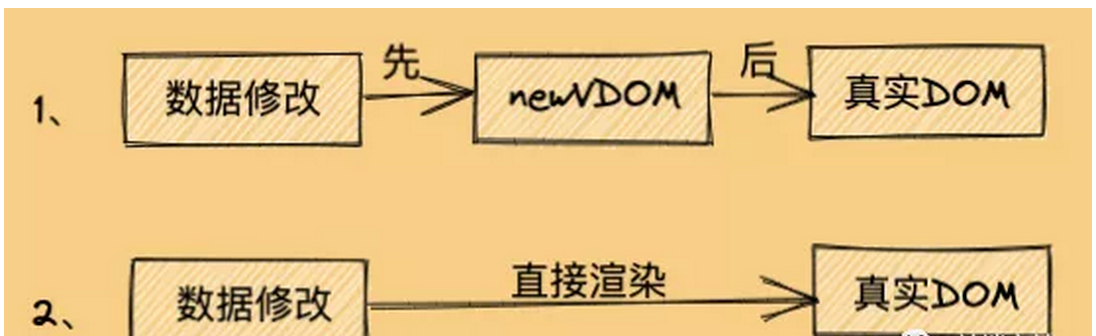
由上图,一看便知,肯定是第2种方式比较快,因为第1种方式中间还夹着一个虚拟DOM的步骤,所以虚拟DOM比真实DOM快这句话其实是错的,或者说是不严谨的。那正确的说法是什么呢?虚拟DOM算法操作真实DOM,性能高于直接操作真实DOM,虚拟DOM和虚拟DOM算法是两种概念。虚拟DOM算法 = 虚拟DOM + Diff算法
什么是Diff算法
上面说了虚拟DOM,也知道了只有虚拟DOM + Diff算法才能真正的提高性能,那讲完虚拟DOM,我们再来讲讲Diff算法吧,还是上面的例子

上图中,其实只有一个li标签修改了文本,其他都是不变的,所以没必要所有的节点都要更新,只更新这个li标签就行,Diff算法就是查出这个li标签的算法。
总结:Diff算法是一种对比算法。对比两者是旧虚拟DOM和新虚拟DOM,对比出是哪个虚拟节点更改了,找出这个虚拟节点,并只更新这个虚拟节点所对应的真实节点,而不用更新其他数据没发生改变的节点,实现精准地更新真实DOM,进而提高效率。
使用虚拟DOM算法的损耗计算:总损耗 = 虚拟DOM增删改+(与Diff算法效率有关)真实DOM差异增删改+(较少的节点)排版与重绘
直接操作真实DOM的损耗计算:总损耗 = 真实DOM完全增删改+(可能较多的节点)排版与重绘
Diff算法的原理
Diff同层对比
新旧虚拟DOM对比的时候,Diff算法比较只会在同层级进行, 不会跨层级比较。所以Diff算法是:广度优先算法。 时间复杂度:O(n)
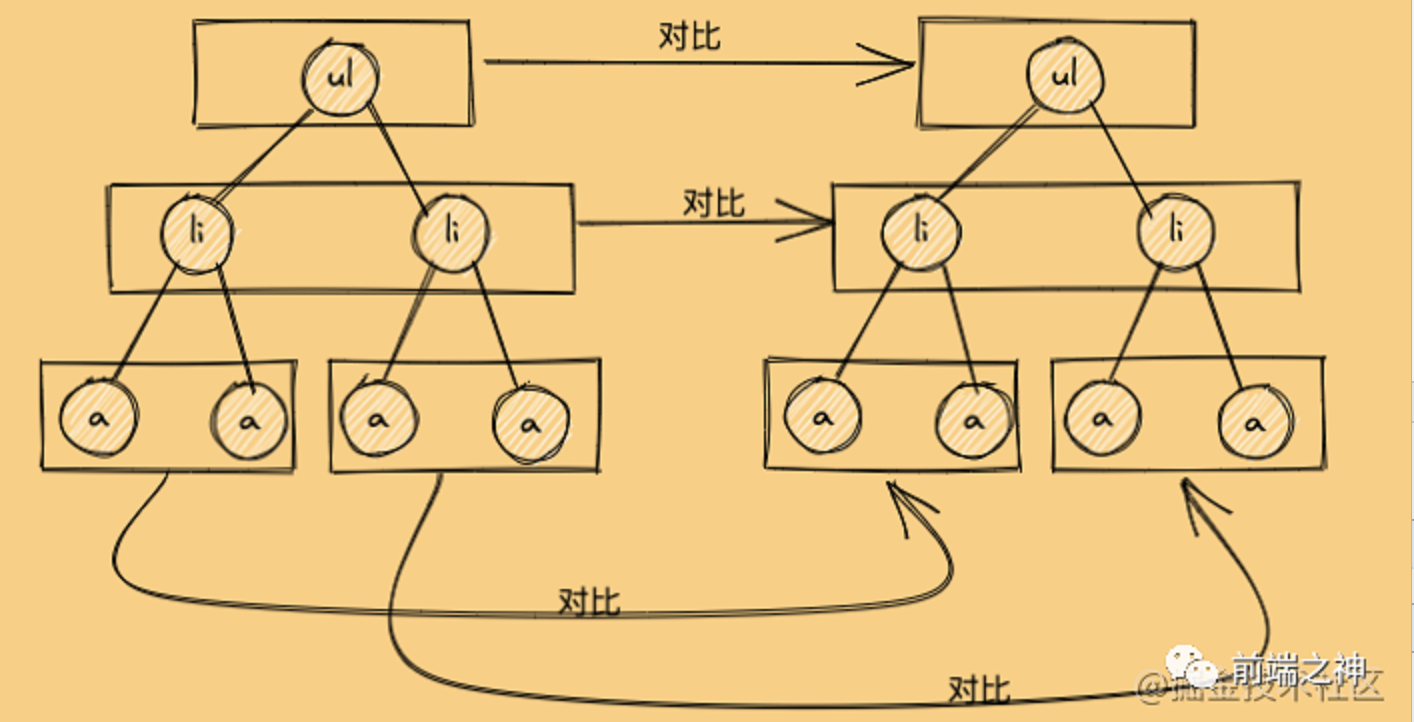
Diff对比流程
当数据改变时,会触发setter,并且通过Dep.notify去通知所有订阅者Watcher,订阅者们就会调用patch方法,给真实DOM打补丁,更新相应的视图
17、如何遍历输出页面上的所有元素
使用createNodeIterator
const body = document.getElementByTagName("body")[0]
const it = document.createNodeIterator(body)
let root = it.nextNode()
while(root){
console.log(root)
root = it.nextNode()
}
18、判断元素是否在可视区域内
使用getBoundingClientRect
Element.getBoundingClientRect() 方法返回元素的大小及其相对于视口的位置。返回的是一个对象,
对象里有这8个属性:left,right,top,bottom,width,height,x,y
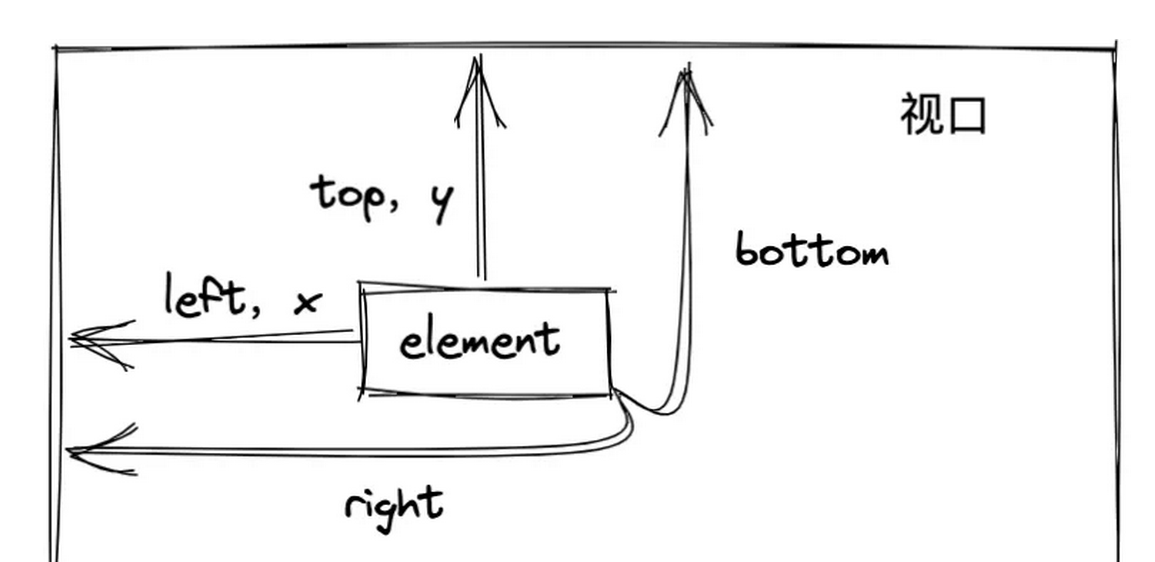
根据这个用处,咱们可以实现:懒加载和无限滚动

<div id="box"></div>
body {
height: 3000px;
width: 3000px;
}
#box {
width: 300px;
height: 300px;
background-color: red;
margin-top: 300px;
margin-left: 300px;
}
// js
const box = document.getElementById('box')
window.onscroll = function () {
// box完整出现在视口里才会输出true,否则为false
console.log(checkInView(box))
}
function checkInView(dom) {
const { top, left, bottom, right } = dom.getBoundingClientRect()
console.log(top, left, bottom, right)
console.log(window.innerHeight, window.innerWidth)
return top >= 0 &&
left >= 0 &&
bottom <= (window.innerHeight || document.documentElement.clientHeight) &&
right <= (window.innerWidth || document.documentElement.clientWidth)
}

19、getComputedStyle
Window.getComputedStyle()方法返回一个对象,该对象在应用活动样式表并解析这些值可能包含的任何基本计算后报告元素的所有CSS属性的值。私有的CSS属性值可以通过对象提供的API或通过简单地使用CSS属性名称进行索引来访问。
window.getComputedStyle(element, pseudoElement)
element: 必需,要获取样式的元素。pseudoElement: 可选,伪类元素,当不查询伪类元素的时候可以忽略或者传入 null。
搭配getPropertyValue可以获取到具体样式

// html
#box {
width: 300px;
height: 300px;
background-color: yellow;
}
<div id="box"></div>
const box = document.getElementById('box')
const styles = window.getComputedStyle(box)
// 搭配getPropertyValue可以获取到具体样式
const height = styles.getPropertyValue("height")
const width = styles.getPropertyValue("width")
console.log(height, width) // ’300px‘ '300px'

20、DOMContentLoaded
是什么:
当初始的 HTML 文档被完全加载和解析完成之后,DOMContentLoaded 事件被触发,而无需等待样式表、图像和子框架的完全加载。
这时问题又来了,“HTML 文档被加载和解析完成”是什么意思呢?或者说,HTML 文档被加载和解析完成之前,浏览器做了哪些事情呢?那我们需要从浏览器渲染原理来谈谈。
浏览器向服务器请求到了 HTML 文档后便开始解析,产物是 DOM(文档对象模型),到这里 HTML 文档就被加载和解析完成了。如果有 CSS 的会根据 CSS 生成 CSSOM(CSS 对象模型),然后再由 DOM 和 CSSOM 合并产生渲染树。有了渲染树,知道了所有节点的样式,下面便根据这些节点以及样式计算它们在浏览器中确切的大小和位置,这就是布局阶段。有了以上这些信息,下面就把节点绘制到浏览器上。所有的过程如下图所示:

现在你可能了解 HTML 文档被加载和解析完成前浏览器大概做了哪些工作,但还没完,因为我们还没有考虑现在前端的主角之一 JavaScript。
JavaScript 可以阻塞 DOM 的生成,也就是说当浏览器在解析 HTML 文档时,如果遇到
当 HTML 文档被解析时如果遇见(同步)脚本,则停止解析,先去加载脚本,然后执行,执行结束后继续解析 HTML 文档。过程如下图

defer 脚本:
当 HTML 文档被解析时如果遇见 defer 脚本,则在后台加载脚本,文档解析过程不中断,而等文档解析结束之后,defer 脚本执行。另外,defer 脚本的执行顺序与定义时的位置有关。过程如下图:

async 脚本:
当 HTML 文档被解析时如果遇见 async 脚本,则在后台加载脚本,文档解析过程不中断。脚本加载完成后,文档停止解析,脚本执行,执行结束后文档继续解析。过程如下图:

async 和 defer 对 DOMContentLoaded 事件触发的影响:
defer 与 DOMContentLoaded
如果 script 标签中包含 defer,那么这一块脚本将不会影响 HTML 文档的解析,而是等到 HTML 解析完成后才会执行。而 DOMContentLoaded 只有在 defer 脚本执行结束后才会被触发。所以这意味着什么呢?HTML 文档解析不受影响,等 DOM 构建完成之后 defer 脚本执行,但脚本执行之前需要等待 CSSOM 构建完成。在 DOM、CSSOM 构建完毕,defer 脚本执行完成之后,DOMContentLoaded 事件触发。
async 与 DOMContentLoaded
如果 script 标签中包含 async,则 HTML 文档构建不受影响,解析完毕后,DOMContentLoaded 触发,而不需要等待 async 脚本执行、样式表加载等等。
DOMContentLoaded和load
当 HTML 文档解析完成就会触发 DOMContentLoaded,而所有资源加载完成之后,load 事件才会被触发。
另外需要提一下的是,我们在 jQuery 中经常使用的
(document).ready(function()//…代码…);其实监听的就是DOMContentLoaded事件
而 ((document).load(function() { // …代码… }); 监听的是 load 事件。
使用:
document.addEventListener("DOMContentLoaded", function(event) {
console.log("DOM fully loaded and parsed");
});
21、 webpack配置中的3种hash值
事先准备3个文件(main.js、main.css、console.js)
在main.js中引入main.css
import './main.css'
console.log('我是main.js')
webpack.config.js

// 多入口打包
entry: {
main: './src/main.js',
console: './src/console.js'
},
// 输出配置
output: {
path: path.resolve(__dirname, './dist'),
// 这里预设为hash
filename: 'js/[name].[hash].js',
clean: true
},
plugins: [
// 打包css文件的配置
new MiniCssExtractPlugin({
// 这里预设为hash
filename: 'styles/[name].[hash].css'
})
]

1、全局hash
打包后,所有文件的文件名hash值都是一致的,修改一下main.css这个文件,重新打包,所有文件的hash值跟着变
结论:整个项目文件是一致的,修改其中一个会导致所有跟着一起改。
2、chunkhash
consfig中把输出文件名规则修改为chunkhash
hash值会根据入口文件的不同而分出两个阵营:
main.js、main.css一个阵营,都属于main.js入口文件console.js一个阵营,属于console.js入口文件

3、contenthash
每个文件hash值都不一样,每个文件的hash值都是根据自身的内容去生成的
当某个文件内容修改时,打包只会修改其本身的hash值,不会影响其他文件的hash值
22、package.lock.json的作用
锁定安装模块的版本
比如在package.json中,vue的版本是^2.6.14
^的意思是,加入过几天vue在大版本2下更新了小版本2.6.15,那么当npm install的时候vue会自动升级为2.16.5
引起的问题:
比如有A\B两个开发者
- 程序员A:接手项目时vue版本时2.16.4,并一直使用这个版本
- 程序员B:一个月后加入项目,这时vue已经升级到了2.9.14,npm install的时候会自动升级
这时候会导致两个开发时vue版本不一致,从而导致合作中产生一些问题和错误
package.lock.json解决该问题
比如现在有A、B两个开发者
A:接手项目时vue的版本时2.6.14,此版本被所在了package-lock.json中
B:一个月后加入该项目,这时vue已经升级到了2.9.14,npm install的时候,按理说会自动升级,但是由于package-lock.json中锁着2.6.14这个版本,所以阻止了自动升级,保证版本还是2.6.14
23、MutationObserver
作用:监控DOM元素的变化
例子:添加水印,使用MutationObserver阻止用户恶意破坏水印,因为在控制台修改水印的background-image或者将水印的div删掉,都会引起MutationObserver的监控触发
- observer:开启监控DOM的变化
- disconnect:停止检测DOM的变化
代码:
1、定义画水印的函数
import type { Directive, App } from 'vue'
interface Value {
font?: string
textColor?: string
text?: string
}
const waterMarkId = 'waterMark'
const canvasId = 'can'
const drawWatermark = (el, value: Value) => {
const {
font = '16px Microsoft JhengHei',
textColor = 'rgba(180, 180, 180, 0.3)',
text = 'nlf大菜鸟',
} = value
// 创建一个canvas标签
const canvas = document.getElementById(canvasId) as HTMLCanvasElement
// 如果已有则不再创建
const can = canvas || document.createElement('canvas')
can.id = canvasId
el.appendChild(can)
// 设置宽高
can.width = 400
can.height = 200
// 不可见
can.style.display = 'none'
const ctx = can.getContext('2d')!
// 设置画布的样式
ctx.rotate((-20 * Math.PI) / 180)
ctx.font = font
ctx.fillStyle = textColor
ctx.textAlign = 'left'
ctx.textBaseline = 'middle'
ctx.fillText(text, can.width / 3, can.height / 2)
// 水印容器
const waterMaskDiv = document.createElement('div')
waterMaskDiv.id = waterMarkId
// 设置容器的属性样式
// 将刚刚生成的canvas内容转成图片,并赋值给容器的 background-image 样式
const styleStr = `
width: 100%;
height: 100%;
position: fixed;
z-index: -1;
top: 0;
left: 0;
pointer-events: none;
background-image: url(${can.toDataURL('image/png')})
`
waterMaskDiv.setAttribute('style', styleStr)
// 将水印容器放到目标元素下
el.appendChild(waterMaskDiv)
return styleStr
}
//不使用监测
const watermarkDirective: Directive = {
mounted(el, { value }) {
// 接收styleStr,后面可以用来对比
el.waterMarkStylestr = drawWatermark(el, value)
}
}
使用的时候直接以v-watermark来使用:

<div
v-watermark="
{
text: '水印名称',
textColor: 'rgba(180, 180, 180, 0.3)'
}
"
>
</div>

2、使用监控

const watermarkDirective: Directive = {
mounted(el, { value }) {
// 接收styleStr,后面可以用来对比
el.waterMarkStylestr = drawWatermark(el, value)
// 先定义一个MutationObserver
el.observer = new MutationObserver(() => {
const instance = document.getElementById(waterMarkId)
const style = instance?.getAttribute('style')
const { waterMarkStylestr } = el
// 修改样式 || 删除div
if ((instance && style !== waterMarkStylestr) || !instance) {
if (instance) {
// div还在,说明只是修改style
instance.setAttribute('style', waterMarkStylestr)
} else {
// div不在,说明删除了div
drawWatermark(el, value)
}
}
})
// 启动监控
el.observer.observe(document.body, {
childList: true,
attributes: true,
subtree: true,
})
},
unmounted(el) {
// 指定元素销毁时,记得停止监控
el.observer.disconnect()
el.observer = null
},
}

现在,控制台修改style或者删除容器div,都会重新生成水印,这样恶意用户就无法得逞
24、HTTPS加密的过程
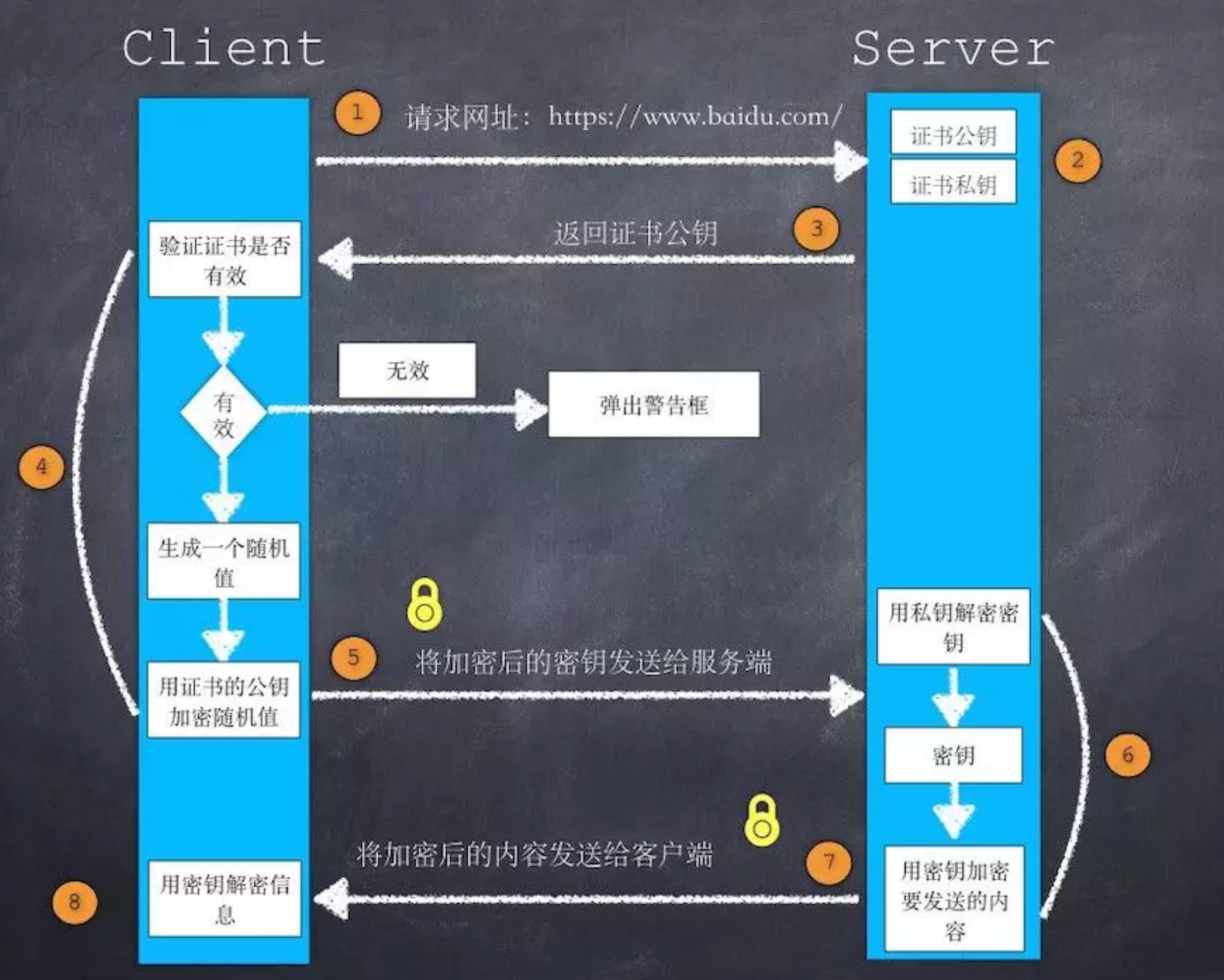
1、首先,客户端发起握手请求,以明文传输请求信息
2、服务器必须要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面。这套证书其实就是一对公钥和私钥。如果对公钥不太理解,可以想象成一把钥匙和一个锁头,只是世界上只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。
3、服务端返回证书、加密算法等信息给客服端
最后
小编的一位同事在校期间连续三年参加ACM-ICPC竞赛。从参赛开始,原计划每天刷一道算法题,实际上每天有时候不止一题,一年最终完成了 600+:
凭借三年刷题经验,他在校招中很快拿到了各大公司的offer。
入职前,他把他的刷题经验总结成1121页PDF书籍,作为礼物赠送给他的学弟学妹,希望同学们都能在最短时间内掌握校招常见的算法及解题思路。

整本书,我仔细看了一遍,作者非常细心地将常见核心算法题和汇总题拆分为4个章节。

而对于有时间的同学,作者还给出了他结合众多数据结构算法书籍,挑选出的一千多道题的解题思路和方法,以供有需要的同学慢慢研究。
















 56万+
56万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









