






 “如果你手里只有一把锤子,那么所有东西看起来都像钉子。”
“如果你手里只有一把锤子,那么所有东西看起来都像钉子。”
在 AI/ML 时代,机器学习常常被用作解决所有问题的利器。虽然 ML 非常有用且非常重要,但 ML 并不总是解决方案。
最重要的是,机器学习本质上是为了预测推理而生的,这与因果推理本质上是不同的。预测模型是非常强大的工具,它使我们能够检测模式和关联,但它们无法解释事件发生的原因。这就是因果推理发挥作用的地方,它可以让我们做出更明智的决策,有效地影响结果,超越单纯的关联。
预测推理利用了相关性。因此,如果你知道“相关性并不意味着因果关系”,那么你应该明白,不应盲目使用机器学习来衡量因果关系。
我们将一起看到,将预测推理误认为因果推理会导致代价高昂的错误!为了避免犯这样的错误,我们将研究这两种方法之间的主要区别,讨论使用机器学习进行因果估计的局限性,探索如何正确选择适当的方法,它们多久协同解决问题的不同部分,并探索如何在因果机器学习的框架内有效地整合两者。
本文将回答以下问题:
- 什么是因果推理?什么是预测推理?
- 它们之间的主要区别是什么?为什么相关性并不意味着因果关系?
- 为什么使用机器学习推断因果关系会有问题?
- 何时应使用每种类型的推理?
- 因果推理和预测推理如何一起使用?
- 什么是因果机器学习以及它如何适应这一背景?
什么是预测推理?
机器学习是关于预测的。
预测推理涉及根据其他变量的值(如它们本身)估计某事物(结果)的值。如果你看看外面,人们都戴着手套和帽子,那肯定很冷。
例子:
- 垃圾邮件过滤器: ML 算法用于根据电子邮件的内容、发件人和其他各种信息,过滤安全和垃圾邮件之间的传入电子邮件。
- 肿瘤检测:机器学习(深度学习)可用于从 MRI 图像中检测脑肿瘤。
- 欺诈检测:在银行业务中,ML 用于根据信用卡活动检测潜在欺诈行为。
偏差-方差:在预测推理中,您希望模型能够很好地预测结果,大多数情况下是样本外的(使用新的未见数据)。如果导致预测方差较低,您可能会接受一点偏差。
什么是因果推理?
因果推理是对因果关系的研究。它涉及影响评估。
因果推理旨在衡量当你改变其他事物的值时结果的价值。在因果推理中,你想知道如果你改变一个变量(特征)的值,其他所有变量都相同,会发生什么。这与预测推理完全不同,在预测推理中,你试图预测特征的不同观察值的结果值。
例子:
- 营销活动投资回报率:因果推理有助于衡量营销活动(原因)的影响(后果)。
- 政治经济学:因果推理通常用于衡量一项政策(原因)的效果(后果)。
- 医学研究:因果推断是衡量药物或行为(原因)对健康结果(后果)的影响的关键。
偏差-方差:在因果推理中,您不会关注使用 R 平方等指标的预测质量。因果推理旨在测量无偏系数。有可能存在一个具有相对较低预测能力的有效因果推理模型,因为因果效应可能仅解释结果方差的一小部分。
关键概念差异:因果推理的复杂性在于我们想要测量一些我们永远不会真正观察到的东西。要测量因果效应,你需要一个参考点:反事实。反事实是没有你的治疗或干预的世界。因果效应是通过将观察到的情况与这个参考(反事实)进行比较来衡量的。
想象一下你头疼。你吃了一片药,过了一会儿,头疼就消失了。但这是因为药片的作用吗?是因为你喝了茶或喝了很多水?还是只是因为时间流逝?由于所有这些影响都是混杂的,因此不可能知道是哪个因素或哪些因素的组合起了作用。完美回答这个问题的唯一方法是有两个平行世界。在其中一个世界中,你吃药,而在另一个世界中,你不吃药。由于药片是这两种情况之间的唯一区别,因此你可以声称药片就是原因。但显然,我们没有平行世界可以玩。在因果推理中,我们称之为:因果推理的基本问题。

因此,因果推理的整个想法是通过找到一个好的反事实来接近这个不可能的理想平行世界情况。这就是为什么黄金标准是随机实验。如果你在一个代表性群体中随机分配治疗(药丸与安慰剂),唯一的系统性差异(假设一切都做得正确)就是治疗,因此结果的统计显著差异可以归因于治疗。
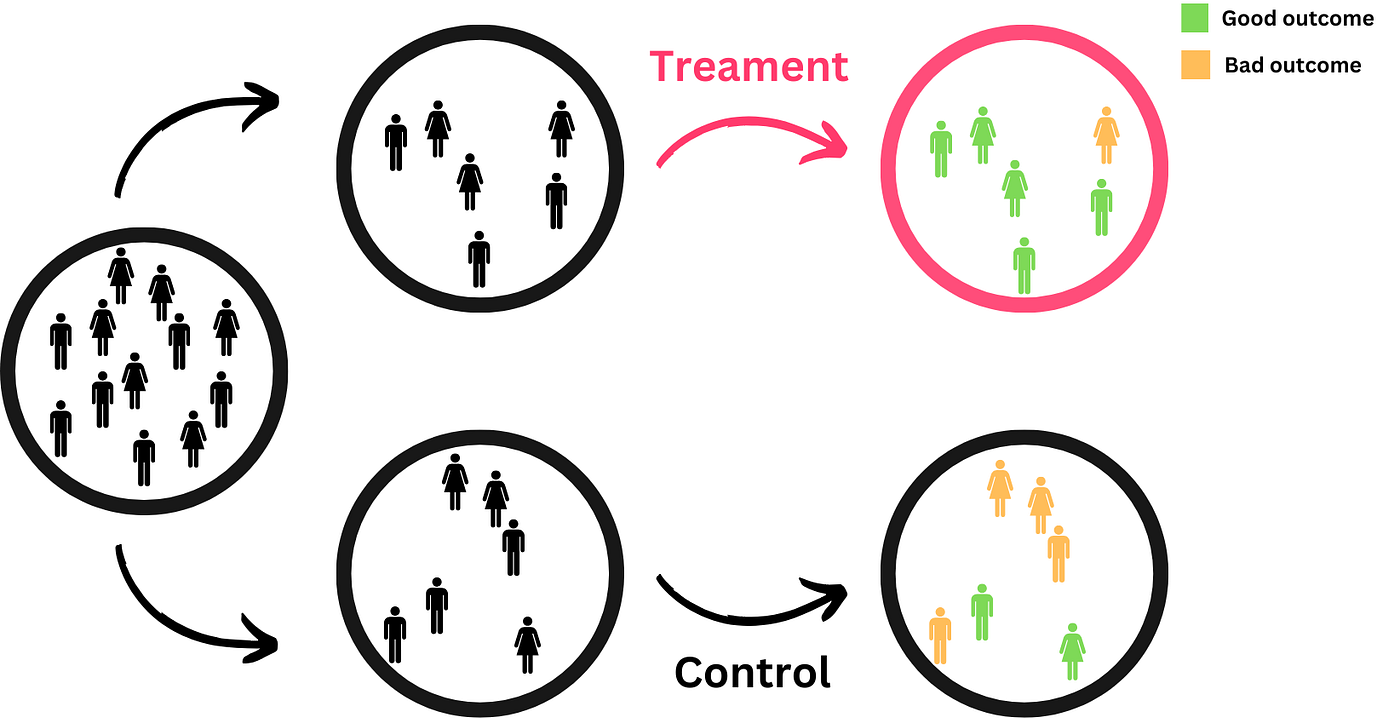
请注意,随机实验有弱点,也可以用观察数据来衡量因果关系。如果你想了解更多,我在这里更深入地解释了这些概念和因果推断:
为什么相关性并不意味着因果关系?
我们都知道“相关性并不意味着因果关系”。但为什么呢?
主要有两种情况。首先,如下面案例 1 所示,溺水事故和冰淇淋销售之间的正相关关系可以说只是由于一个共同的原因:天气。天气晴朗时,溺水事故和冰淇淋销售之间都会发生,但溺水事故和冰淇淋销售之间没有直接的因果关系。这就是我们所说的虚假相关性。第二种情况在案例 2 中描述。教育对绩效有直接影响,但认知能力对两者都有影响。因此,在这种情况下,教育和工作绩效之间的正相关与认知能力的影响混淆了。
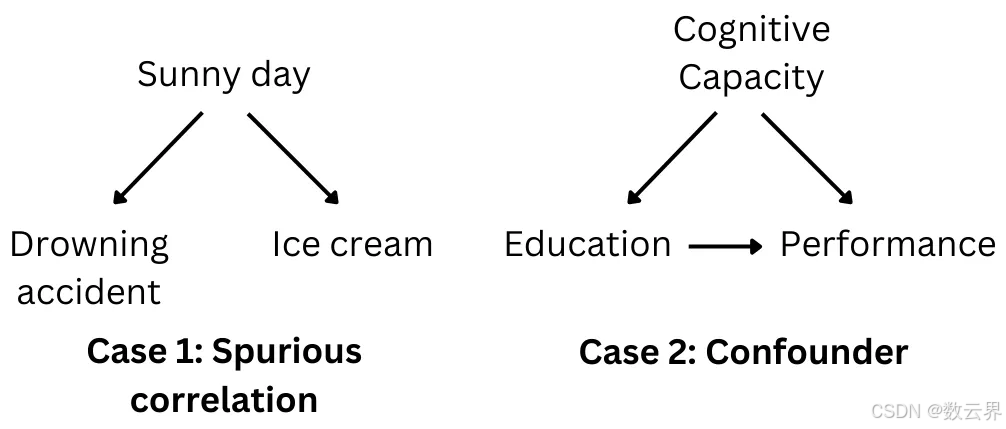
正如我在介绍中提到的,预测推理利用了相关性。因此,任何知道“相关性并不意味着因果关系”的人都应该明白,机器学习本身并不适合因果推理。即使没有因果关系,冰淇淋销量也可能是当天溺水事故风险的一个很好的预测指标。这种关系只是相关性,并由一个共同的原因驱动:天气。
但是,如果你想研究冰淇淋销售对溺水事故的潜在因果关系,你必须考虑第三个变量(天气)。否则,由于著名的遗漏变量偏差,你对因果关系的估计会存在偏差。一旦你将这个第三个变量纳入分析,你肯定会发现冰淇淋销售不再影响溺水事故。通常,解决这个问题的一个简单方法是将此变量纳入模型中,这样它就不会再被“遗漏”了。然而,混杂因素往往是不可观察的,因此不可能简单地将它们纳入模型中。因果推理有许多方法来解决这个未观察到的混杂因素问题,但讨论这些超出了本文的范围。如果你想了解更多关于因果推理的信息,你可以按照我的指南进行操作:
因此,因果推理和预测推理之间的主要区别在于选择“特征”的方式。
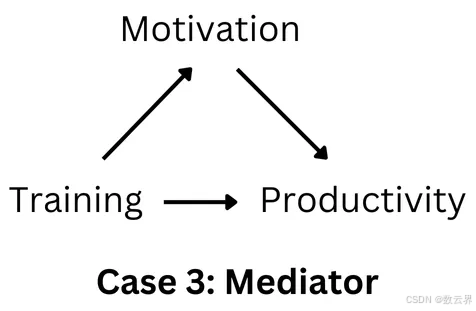
在机器学习中,你通常会包含可能提高预测质量的特征,而你的算法可以帮助根据预测能力选择最佳特征。然而,在因果推理中,即使预测能力很低且影响在统计上并不显著,也应该不惜一切代价包含某些特征(混杂因素/常见原因)。我们主要关注的不是混杂因素的预测能力,而是它如何影响我们正在研究的原因系数。此外,有些特征不应包含在因果推理模型中,例如中介变量。中介变量代表间接的因果途径,控制此类变量将无法衡量感兴趣的总体因果效应(见下图)。因此,主要区别在于,因果推理中是否包含特征取决于变量之间假定的因果关系。
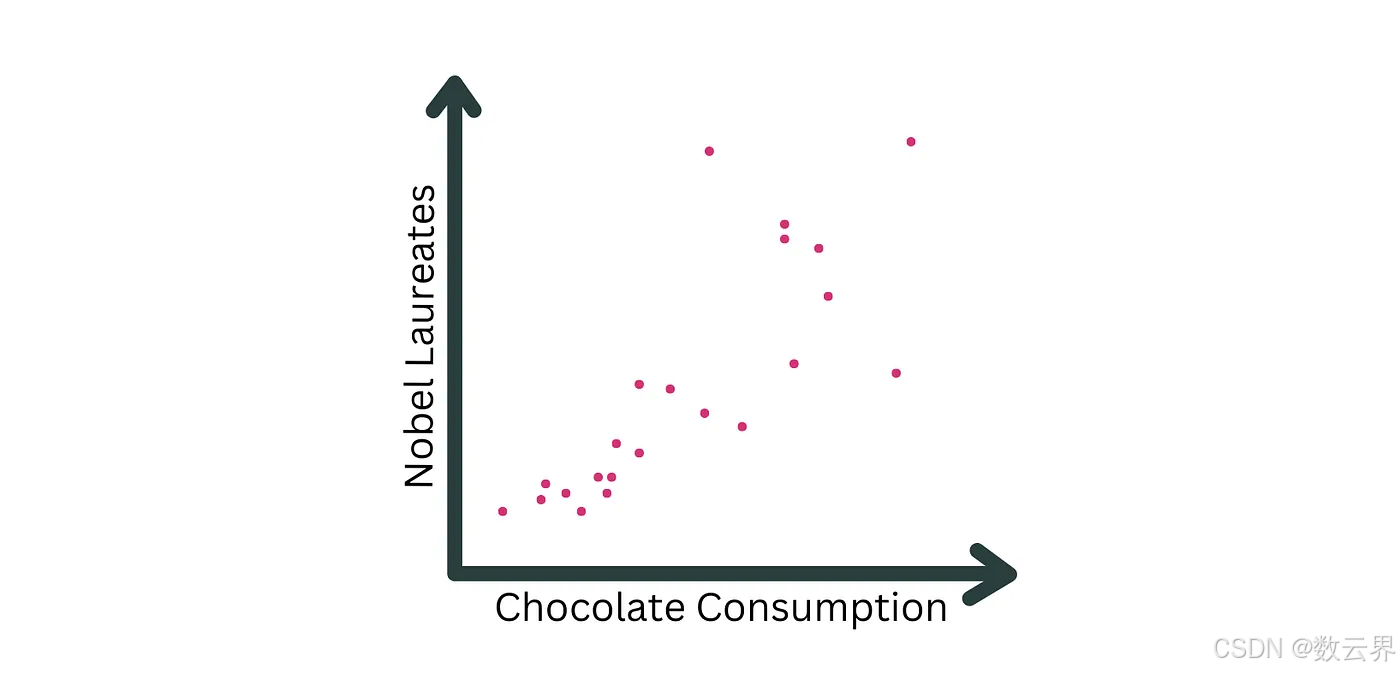
一个著名的相关性是巧克力消费量和诺贝尔奖获得者之间的相关性。作者发现,在国家层面,这两个变量之间的线性相关系数为 0.8。虽然这听起来像是多吃巧克力的一个很好的理由,但不应将其解释为因果关系。
现在让我分享一个更严肃的例子。想象一下尝试优化内容创建者的帖子。为此,您构建了一个包含众多特征的 ML 模型。分析显示,下午晚些时候或晚上发布的帖子效果最佳。因此,您建议制定一个精确的时间表,只在下午 5 点到晚上 9 点之间发布帖子。实施后,每篇帖子的展示次数就崩溃了。发生了什么?ML 算法根据当前模式进行预测,解释数据:当天晚些时候发布的帖子与更高的展示次数相关。最终,晚上发布的帖子更加自发,计划性更少,作者的目的不是取悦特定的观众,而只是分享一些有价值的东西。所以时间不是原因;这是帖子的性质。这种自发性可能更难用 ML 模型捕捉(即使你编码了一些特征,如长度、语气等,捕捉到这一点可能并不是一件容易的事)。
在营销中,预测模型通常用于衡量营销活动的投资回报率。
通常,诸如简单的营销组合模型 (MMM)之类的模型会受到遗漏变量偏差的影响,并且投资回报率的衡量会产生误导。
通常,竞争对手的行为可能与我们的广告活动相关,也会影响我们的销售。如果没有适当考虑这一点,投资回报率可能会被低估或高估,从而导致业务决策和广告支出不理想。
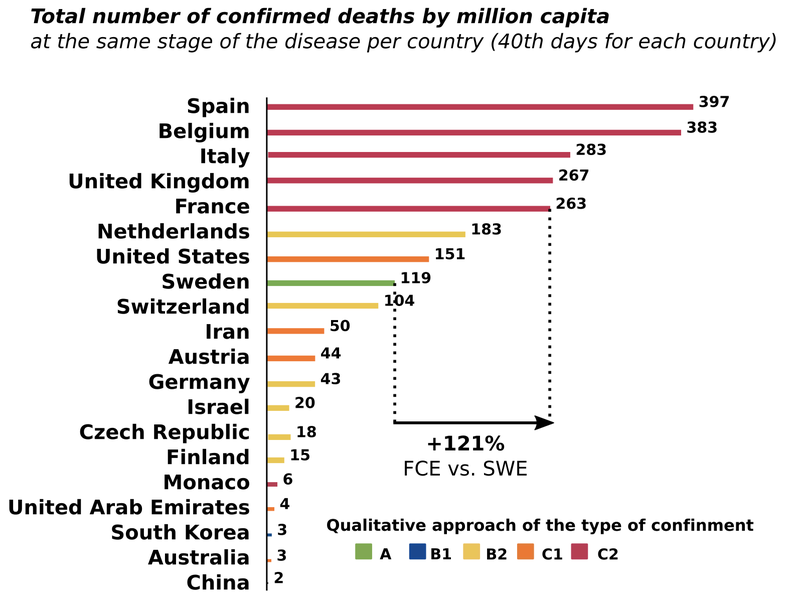
这一概念对于政策和决策也很重要。在新冠疫情开始时,一位法国“专家”用一张图表来论证封锁适得其反(见下图)。该图显示,封锁的严格程度与新冠相关死亡人数呈正相关(封锁越严厉,死亡人数就越多)。然而,这种关系很可能是由相反的因果关系驱动的:当情况糟糕(大量死亡)时,各国会采取严格措施。这被称为反向因果关系。事实上,当你在控制潜在混杂因素的情况下,正确研究一个国家在封锁前后的病例和死亡人数走势时,你会发现强烈的负面影响。
何时应使用每种类型的推理?
机器学习和因果推理都非常有用;它们只是服务于不同的目的。
和数字和统计数据一样,大多数时候问题不在于指标,而在于对指标的解释。因此,相关性是有用的,只有当你盲目地将其解释为因果关系时,它才会成为问题。
何时使用因果推理:当您想要了解因果关系并进行影响评估时。
- 政策评估:确定新政策的影响,例如新的教育计划对学生表现的影响。
- 医学研究:评估新药或新疗法对健康结果的有效性。
- 经济学:了解利率变化对通货膨胀或就业等经济指标的影响。
- 营销:评估营销活动对销售的影响。
因果推理中的关键问题:
- X 对 Y 有何影响?
- 改变 X 会导致 Y 改变吗?
- 如果我们干预 X,Y 会发生什么情况?
何时使用预测推理:当您想要进行准确预测(特征和结果之间的关联)并从数据中学习模式时。
- 风险评估:预测信用违约或保险索赔的可能性。
- 推荐系统:根据用户过去的行为向用户推荐产品或内容。
- 诊断:对医学图像进行分类以检测疾病。
预测推理的关键问题:
- 给定 X,Y 的期望值是多少?
- 我们能根据有关 X 的新数据预测 Y 吗?
- 我们利用 X 的当前和历史数据能多准确地预测 Y?
因果推理和预测推理如何一起使用?
虽然因果推理和预测推理的用途不同,但它们有时可以协同工作。Booking.com 高级机器学习经理 Dima Goldenberg 在与 Aleksander Molak(《Python 中的因果推理和发现》的作者)的播客中完美地说明了这一点。
Booking.com 显然正在努力开发推荐系统。“推荐”是一个预测问题:“客户 X 更喜欢看到什么类型的产品?”因此,第一步通常用机器学习来解决。然而,还有另一个相关问题:“这个新的推荐系统对销售/转化等有什么影响?”在这里,关键字“影响...”应该直接让你意识到你必须在第二步中使用因果推理。这一步将需要因果推理和更精确的随机实验(A/B 测试)。
这是一个典型的工作流程,包括机器学习和因果推理的互补角色。您使用机器学习开发预测模型,并使用因果推理评估其影响。
那么,因果机器学习是什么以及它如何适应这一背景?
最近,出现了一个新的领域:因果机器学习。虽然这是一个重要的突破,但我认为它增加了混乱。
许多人看到“因果机器学习”这个术语,只是认为他们可以随意地使用机器学习进行因果推理。
因果 ML 是两全其美的结合。然而,因果 ML 并不是盲目用于因果推理的机器学习。它更像是因果推理,并在其上添加 ML 以改善结果。因果推理的关键区别概念对于因果 ML 仍然有效。特征选择依赖于假设的因果关系。
让我介绍一下 Causal ML 中的两种主要方法来说明这种有趣的组合。
A.处理高维数据和复杂的函数形式
在某些情况下,因果推理模型中有许多控制变量。为了降低遗漏变量偏差的风险,您纳入了许多潜在的混杂因素。您应该如何处理如此多的控制变量?也许您的控制组之间存在多重共线性,或者您应该控制非线性效应或相互作用。使用传统的因果推理方法解决这些问题很快就会变得非常复杂,而且非常随意。
由于机器学习在处理高维数据方面特别有效,因此它可用于解决这些挑战。机器学习将用于找到最佳控制集和正确的函数形式,以使您的模型不会受到多重共线性的影响,同时仍满足测量因果关系的条件(参见:双重机器学习方法)。
B. 异质性治疗效果
因果推断历来侧重于衡量平均治疗效果 (ATE),即衡量治疗的平均效果。但是,您肯定知道,平均值很有用,但也可能产生误导。治疗效果可能因对象而异。想象一下,一种新药平均而言显著降低了患癌症的风险,但实际上,整个效果是由对男性的结果驱动的,而对女性的影响为零。或者想象一下,一项营销活动平均而言导致更高的转化率,但实际上它在特定地区产生了负面影响。
因果机器学习让我们能够超越平均治疗效果,通过识别条件平均治疗效果 (CATE) 来发现这种异质性。换句话说,它有助于根据受试者的不同特征有条件地识别治疗效果。
揭示条件平均治疗效果的主要方法称为因果森林。然而,需要注意的是,虽然这种方法可以让我们找到对治疗有不同反应的子群体,但机器学习发现的此类群体的特征不一定是因果关系。想象一下,该模型显示广告对智能手机用户和平板电脑用户的影响完全不同。“设备”不应被解释为造成这种差异的原因。真正的原因可能是无法衡量的,但与这个特征相关,例如年龄。
结论
如今,区分预测推理和因果推理至关重要,这样才能避免在营销、政策制定和医学研究等各个领域犯下代价高昂的错误。我们研究了为什么机器学习尽管具有出色的预测能力,但由于其依赖相关性/关联而不是因果关系,本质上并不适合因果推理。希望您能够理解这种区别,并为正确类型的问题选择正确的模型。

如果您想了解有关因果机器学习的更多信息,这里有一些有价值且可靠的资源可以关注
雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









