






欢迎来到雲闪世界。利用人工智能获得即时洞察和更明智的决策
本文最终产品的特色之一

这篇文章是关于什么的?
本文介绍如何使用 AI 构建一个简单的实时商业智能系统。它将引导您了解一家名为“Aniket AI DataInsight Pro”的虚构公司的设计和实施。其目标是展示企业如何使用 AI 实时收集、处理和分析数据。通过设置一个包含客户入职、数据存储和实时更新等各种组件的模块化系统,本文展示了如何从公司的运营到提供可操作见解的 AI 模型创建无缝的数据流。这种设置可帮助企业根据最新可用数据做出更好的决策,从而提高其效率和竞争力。
为什么要读这篇文章?
在当今快节奏的商业世界中,快速做出明智决策的能力至关重要。人工智能通过处理大量数据并实时提供有价值的见解,在其中发挥了重要作用。这篇文章对于任何想要了解人工智能如何改变业务运营的人来说都是必不可少的。通过一个虚构公司的例子,它提供了实施实时商业智能系统的实用步骤和清晰的架构设计。阅读这篇文章将帮助您了解人工智能在现代商业中的重要性,并为您提供路线图,以便利用它的力量满足您自己的业务需求。
让我们设计
在设计“Aniket AI DataInsight Pro”的架构时,我专注于创建一个模块化且可扩展的系统,使公司能够轻松地实时导入和分析其数据。此设计的核心是 Aniket AI DataInsight Pro 服务器,它负责处理客户端数据并提供实时洞察。该服务器包含多个模块,包括客户端导入模块、主模块、读取时间更新模块和存储模块。
客户入职模块通过设置新客户的数据基础设施,促进新客户的整合。主模块协调整体运营,确保数据流和处理的顺畅。读取时间更新模块确保任何传入数据都得到实时处理并反映在分析中,从而提供最新的见解。存储模块以结构化的方式管理所有客户数据的存储,使其易于访问以进行分析。
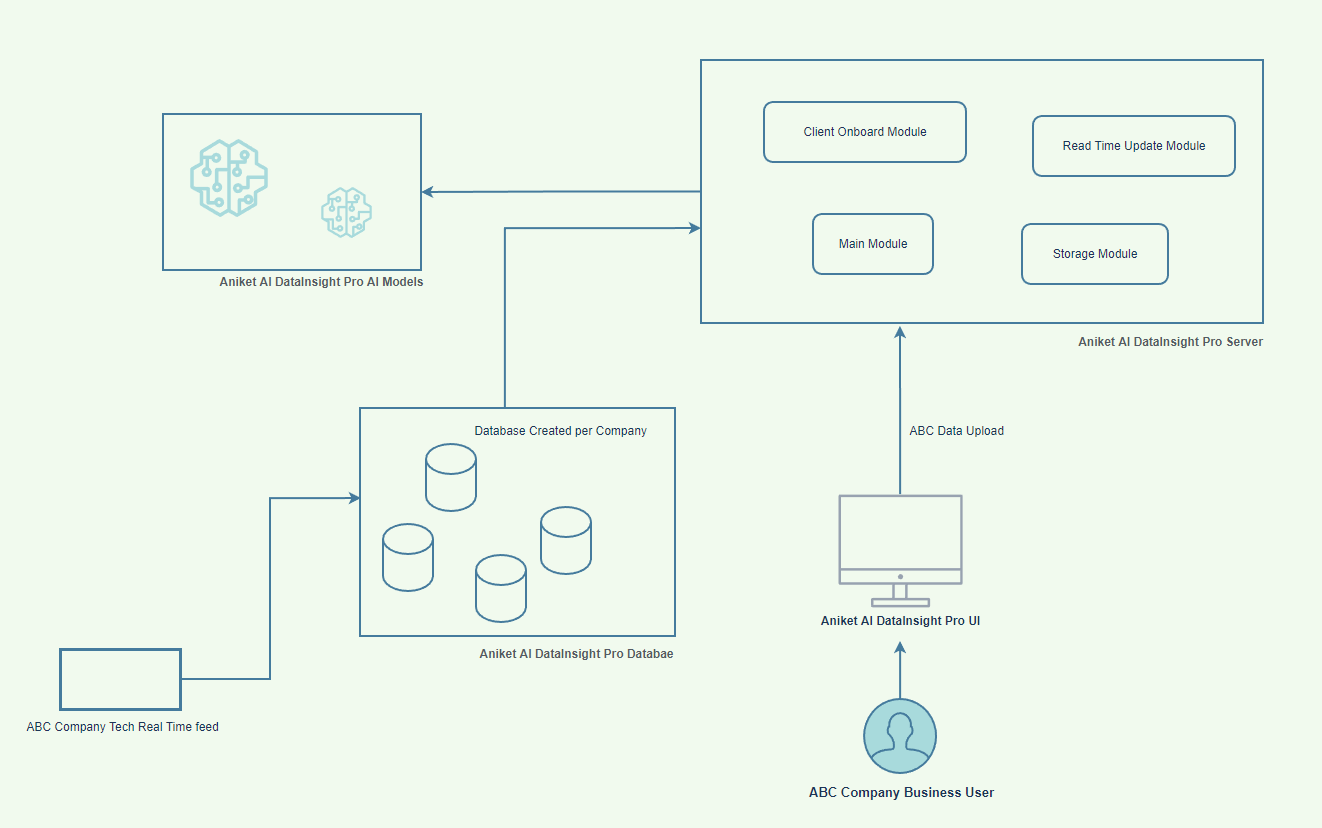
我们 BI 公司的简化设计
Aniket AI DataInsight Pro UI 是 ABC 公司(仅举一例)业务用户的界面,允许他们上传数据并与系统交互。数据上传后,将存储在每个公司创建的专用数据库中,确保数据隔离和安全。
这些数据库输入到 Aniket AI DataInsight Pro AI 模型中,后者可分析数据并提供可操作的见解。ABC Company 技术系统的实时反馈可直接更新数据库,确保始终有最新数据可供分析。这种架构可确保数据从客户系统无缝高效地流向 AI 模型,使企业能够利用高级分析做出更好的决策。
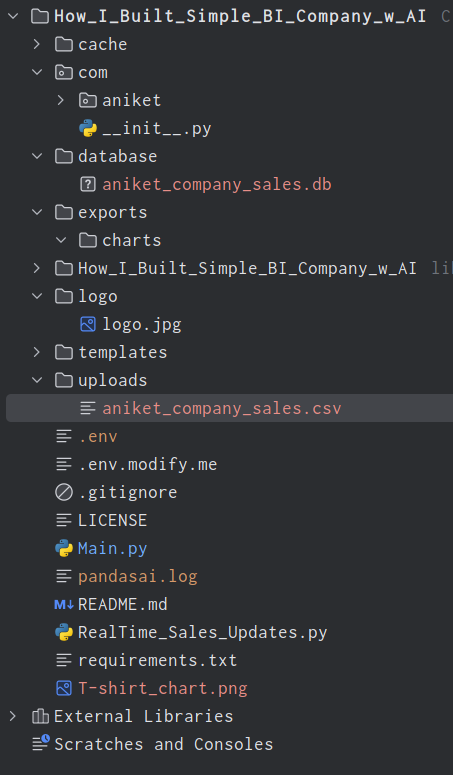
项目结构
主模块
我创建这个模块是为了构建一个用户友好的 Web 应用程序,让用户能够使用高级 AI 模型分析和可视化他们的数据。通过使用 Streamlit,我的目标是让界面直观易用。该应用程序允许用户上传 CSV 数据集,然后将其存储在本地数据库中以便于访问。我添加了选择数据集和询问有关数据的问题的功能,并由强大的 AI 模型生成响应以提供有见地的分析。添加了自定义样式以确保应用程序看起来精致而专业,导航栏可帮助用户轻松访问不同的部分。我希望这个应用程序能够通过使高级分析工具随时可用且易于使用来增强商业智能。
加载环境变量和设置常量
load_dotenv()
DATABASE_FOLDER = 'database''database'
GROQ_API_KEY = os.environ.get("GROQ_API_KEY")此代码从.env文件加载环境变量,以保护 API 密钥等敏感信息的安全。然后,它设置数据库文件的文件夹,并从环境变量中检索 Groq 模型的 API 密钥。
初始化 GroqLLM
model = ChatGroq(model_name="mixtral-8x7b-32768", api_key=GROQ_API_KEY)q(model_name="mixtral-8x7b-32768", api_key=GROQ_API_KEY)在这里,我使用检索到的 API 密钥初始化 Groq 大型语言模型 (LLM)。此模型将用于生成对数据分析提示的响应。
将响应格式化为 HTML 表格
def format_response_to_html_table(response):
lines = response.split('\n')
headers = lines[0].split()
html = "<table><tr>"
for header in headers:
html += f"<th>{header}</th>"
html += "</tr>"
for line in lines[1:]:
html += "<tr>"
for cell in line.split():
html += f"<td>{cell}</td>"
html += "</tr>"
html += "</table>"
return html我编写了这个函数来将文本响应转换为 HTML 表。它将响应按行拆分,假设第一行包含标题,并构造一个带有标题和数据行的 HTML 表,以便于在网页上显示。
获取表名
def get_table_names():get_table_names():
return [os.path.splitext(file)[0] for file in os.listdir(DATABASE_FOLDER) if file.endswith('.db')]此函数检索 中的所有数据库文件的名称DATABASE_FOLDER。它删除.db扩展名以获取每个文件的基本名称,用于在应用程序中进行选择。
设置页面配置
st.set_page_config(page_title="Aniket AI DataInsight Pro", layout="wide")"Aniket AI DataInsight Pro", layout="wide")此代码设置了 Streamlit 应用的页面配置,指定了页面标题和布局,以确保它在宽屏上看起来不错并且运行良好。
自定义 CSS
st.markdown("""
<style>
.main { background-color: #f8f9fa; }
.stButton>button { background-color: #007bff; color: white; border-radius: 5px; border: none; padding: 10px 24px; text-align: center; text-decoration: none; display: inline-block; font-size: 16px; margin: 4px 2px; cursor: pointer; }
.stSelectbox>div>div { background-color: #ffffff; }
h1, h2, h3 { color: #343a40; }
.card { border-radius: 5px; box-shadow: 0 4px 6px 0 rgba(0, 0, 0, 0.1); padding: 20px; margin: 10px 0; background-color: white; }
.navbar { padding: 10px; background-color: #343a40; color: white; }
.navbar a { color: white; text-decoration: none; padding: 10px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background-color: #f2f2f2; }
tr:nth-child(even) { background-color: #f9f9f9; }
.dataframe { border-collapse: collapse; width: 100%; margin-bottom: 20px; }
.dataframe th, .dataframe td { border: 1px solid #ddd; padding: 8px; text-align: left; }
.dataframe th { background-color: #f2f2f2; font-weight: bold; }
.dataframe tr:nth-child(even) { background-color: #f9f9f9; }
.dataframe tr:hover { background-color: #f5f5f5; }
</style>
""", unsafe_allow_html=True)此块将自定义 CSS 样式应用于 Streamlit 应用。这些样式可改善视觉外观,例如设置背景颜色、按钮样式、表格格式等,以确保外观简洁、专业。
服务科
st.markdown('<a name="services"></a>', unsafe_allow_html=True)'<a name="services"></a>', unsafe_allow_html=True)
st.header("Our Services")
col1, col2 = st.columns(2)
with col1:
st.markdown("""
<div class="card">
<h3>Data Analysis</h3>
<p>Unlock the power of your data with our advanced analytics tools.</p>
</div>
""", unsafe_allow_html=True)
with col2:
st.markdown("""
<div class="card">
<h3>Predictive Modeling</h3>
<p>Forecast future trends and make data-driven decisions.</p>
</div>
""", unsafe_allow_html=True)此部分重点介绍应用提供的服务。它使用列整齐地布局服务,并使用卡片使信息具有视觉吸引力且易于阅读。
数据探索器部分
st.markdown('<a name="data-explorer"></a>', unsafe_allow_html=True)'<a name="data-explorer"></a>', unsafe_allow_html=True)
st.header("Data Explorer")
table_names = get_table_names()
selected_table = st.selectbox("Select a dataset", table_names)
def format_df_to_html_table(df):
return df.to_html(index=False, classes=['dataframe'], border=0)在本节中,我将显示数据资源管理器标题并从数据库文件夹中检索表名。该format_df_to_html_table函数将 DataFrame 转换为 HTML 表,这对于在应用程序上显示数据至关重要。
数据分析
if selected_table:
db_path = os.path.join(DATABASE_FOLDER, f'{selected_table}.db')
sqlite_connector = SqliteConnector(config={"database": db_path, "table": selected_table})
df_connector = SmartDataframe(sqlite_connector, config={"llm": model})
prompt = st.text_input("Ask a question about your data:")
if st.button("Analyze"):
if prompt:
with st.spinner("Analyzing data..."):
try:
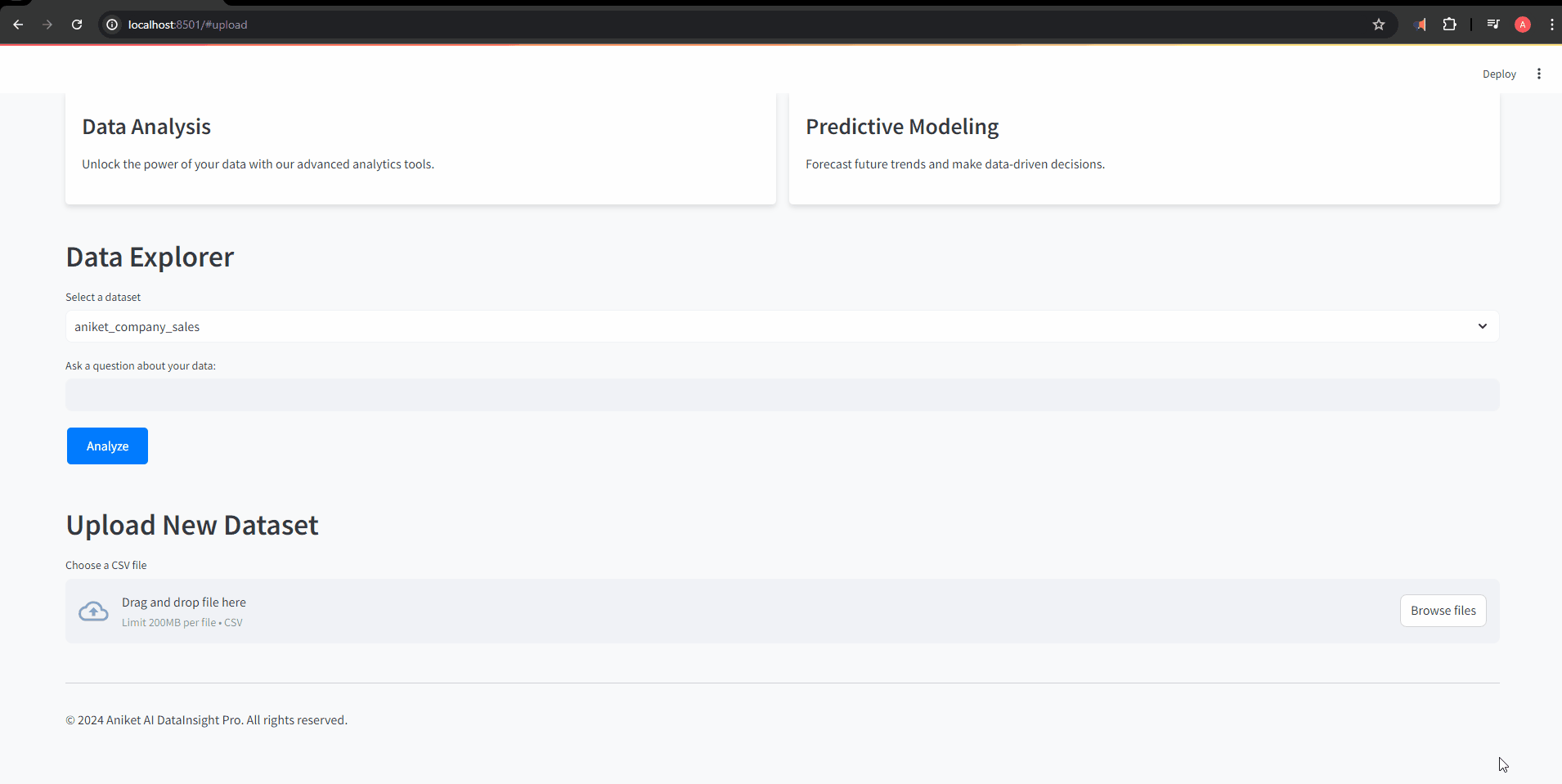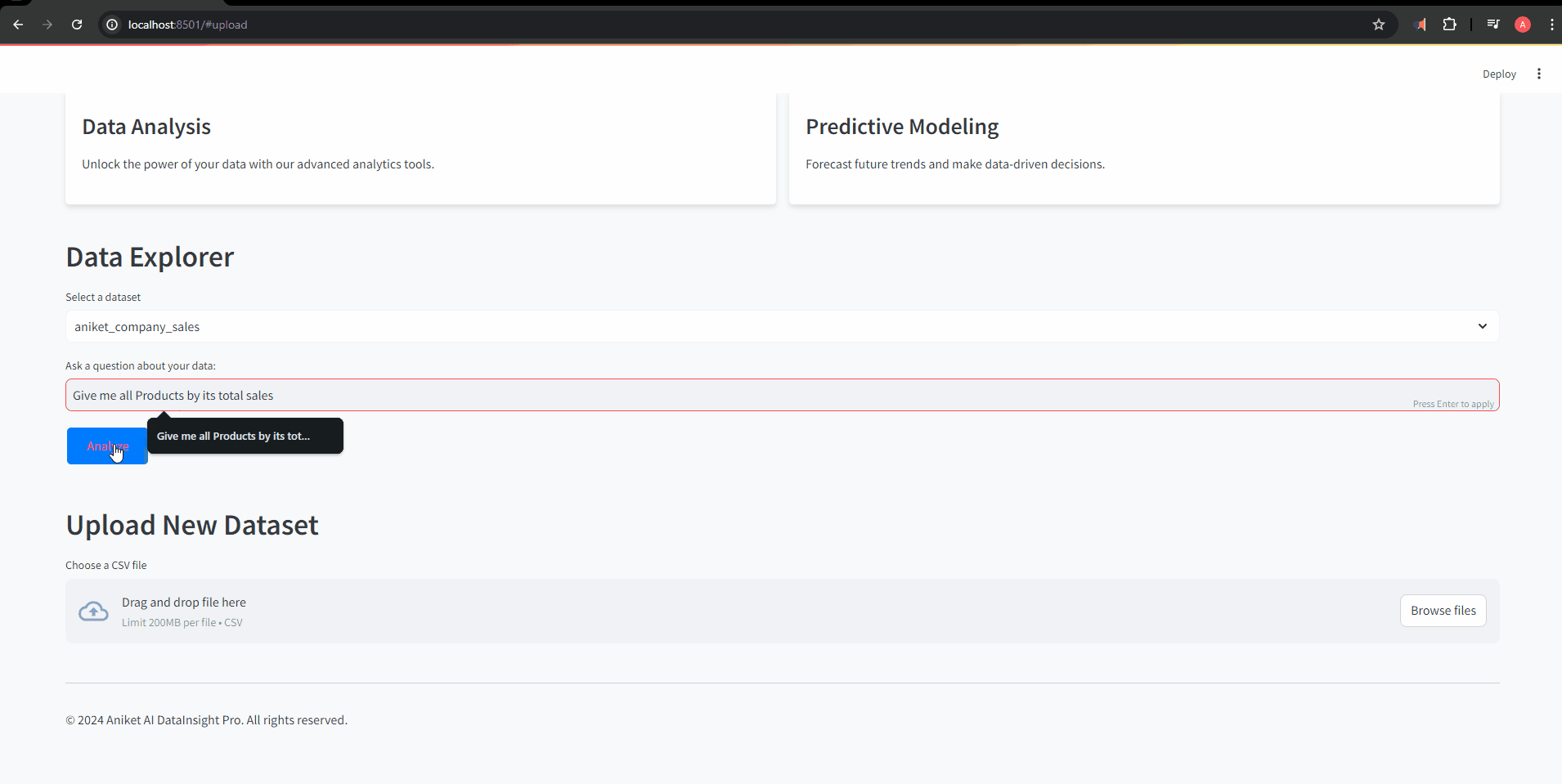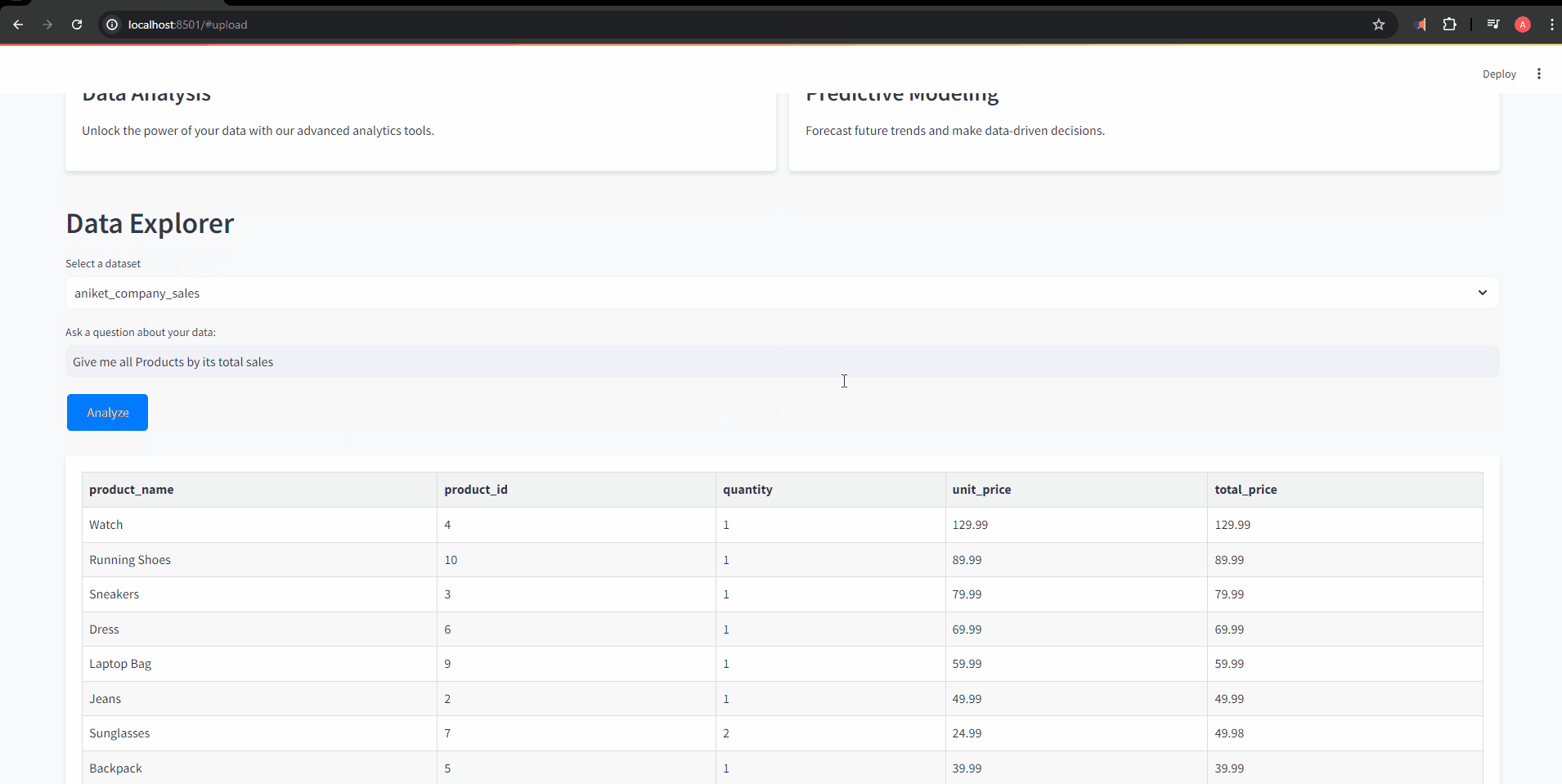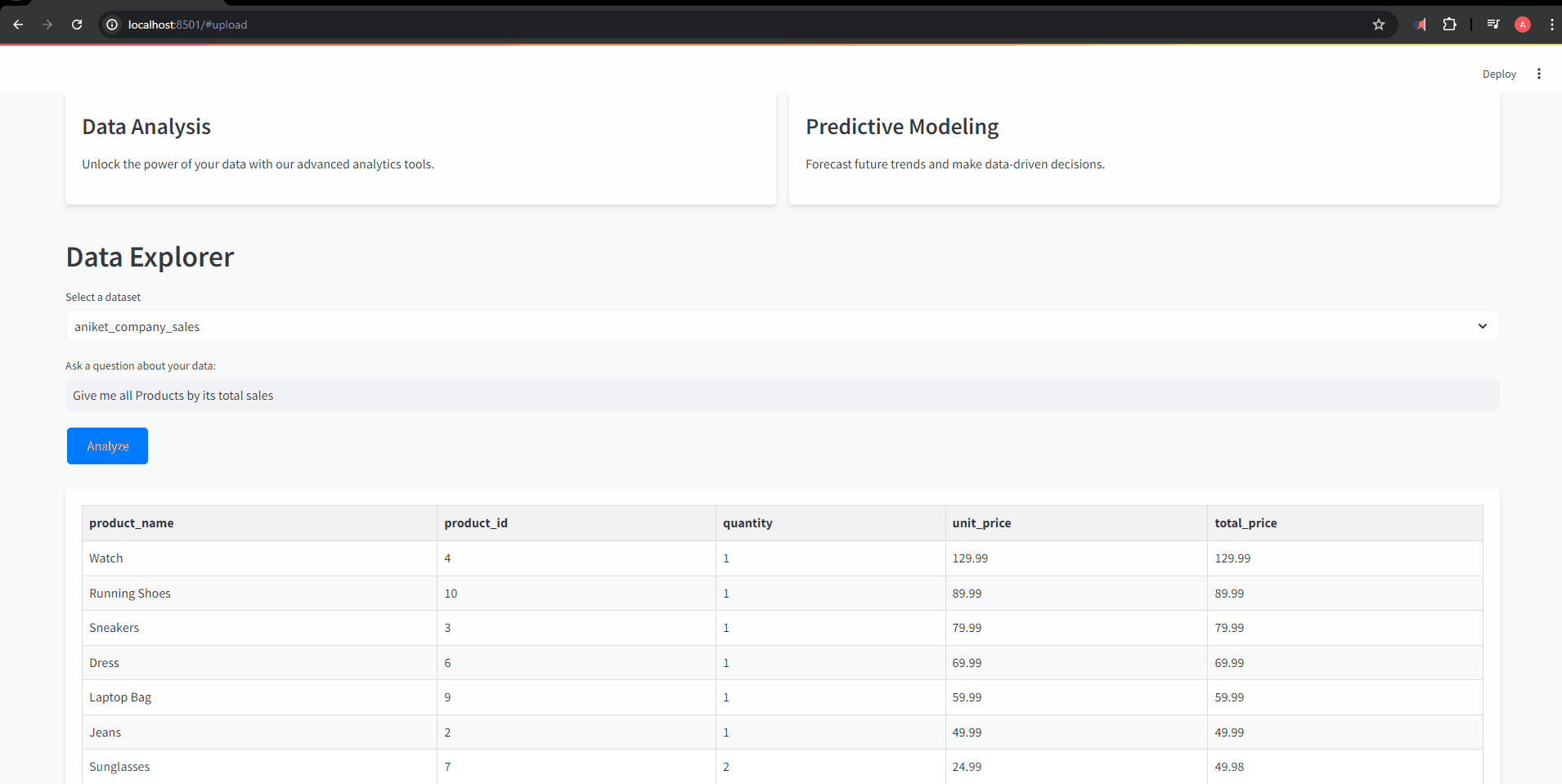
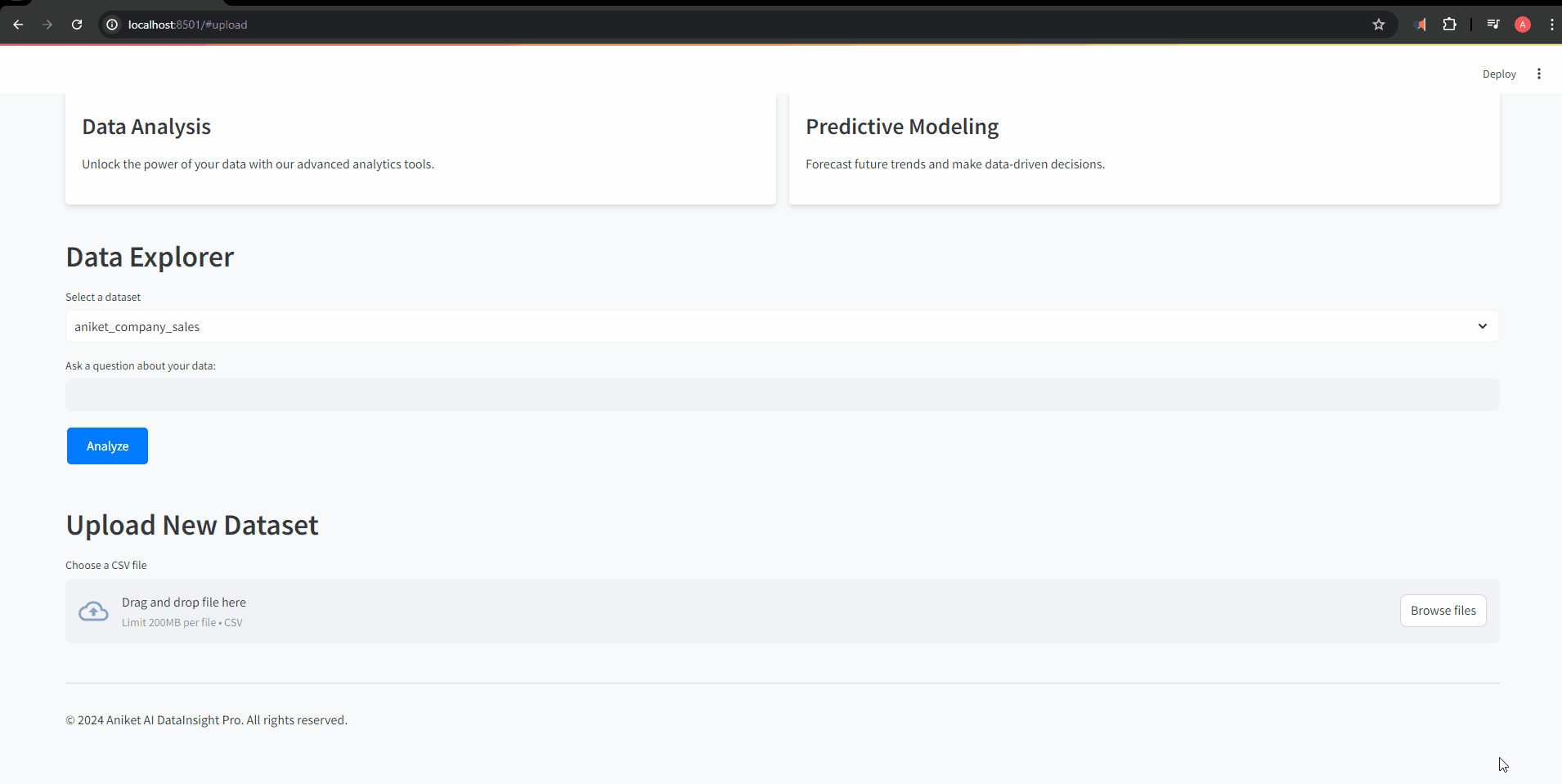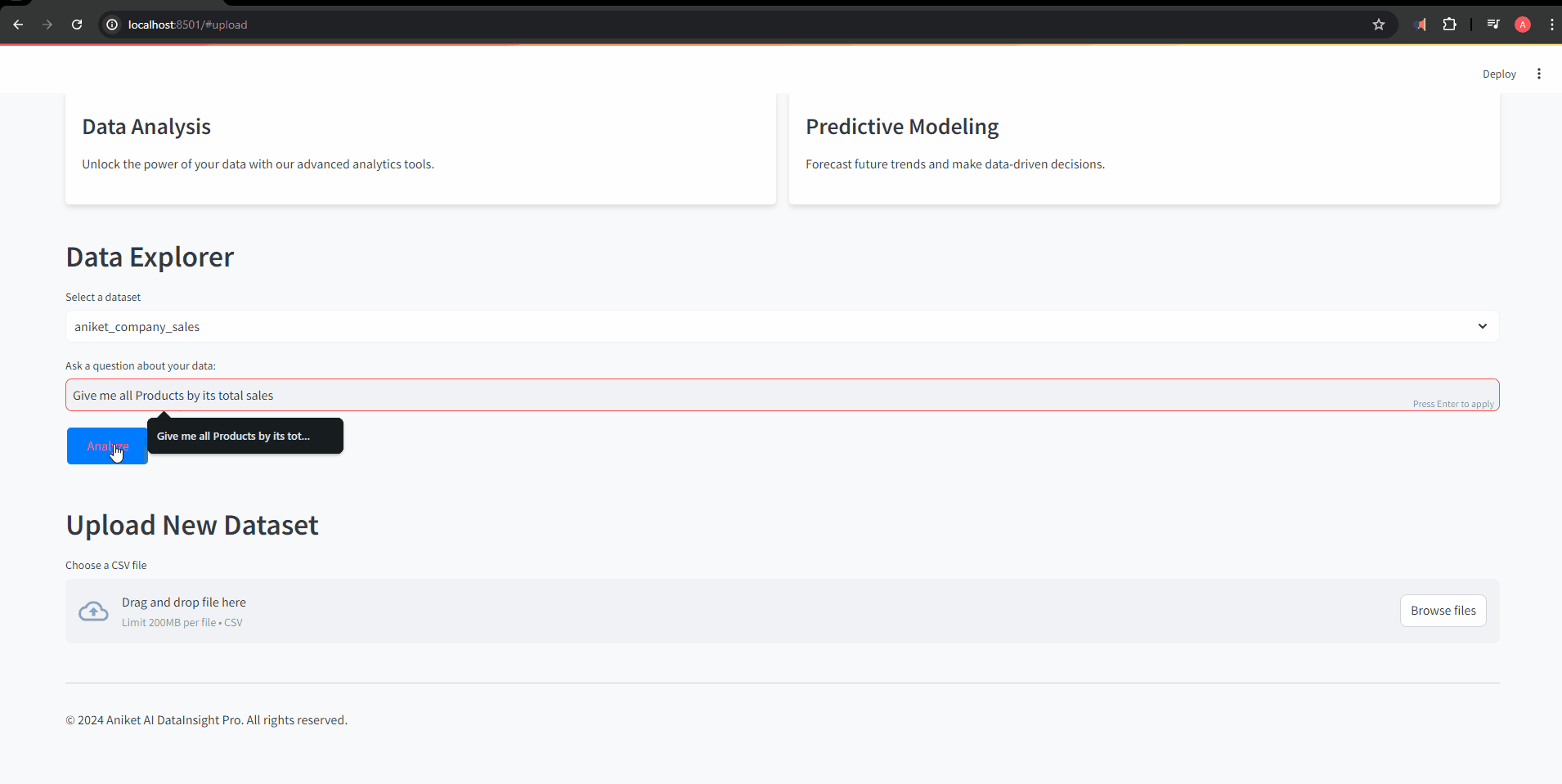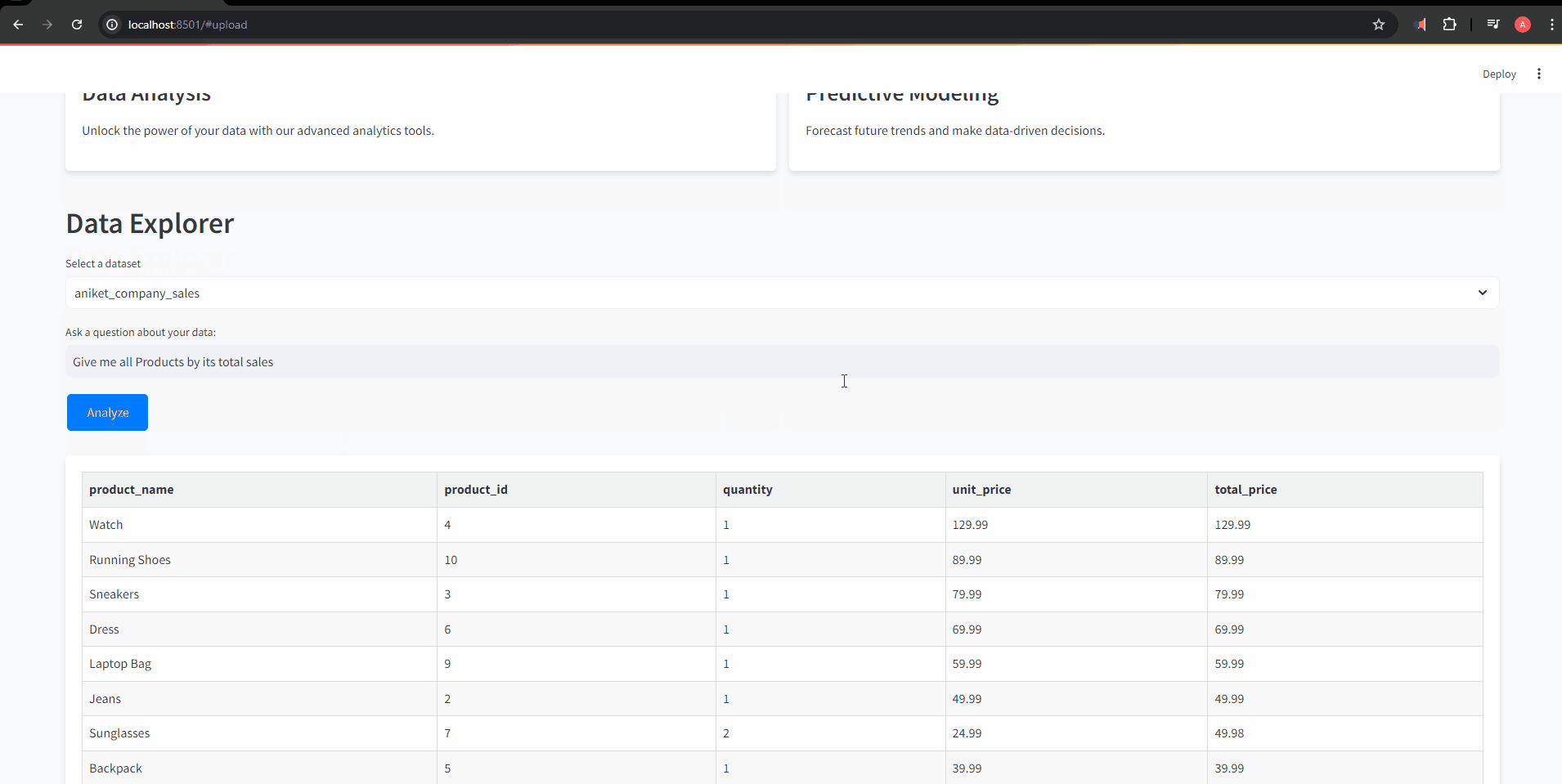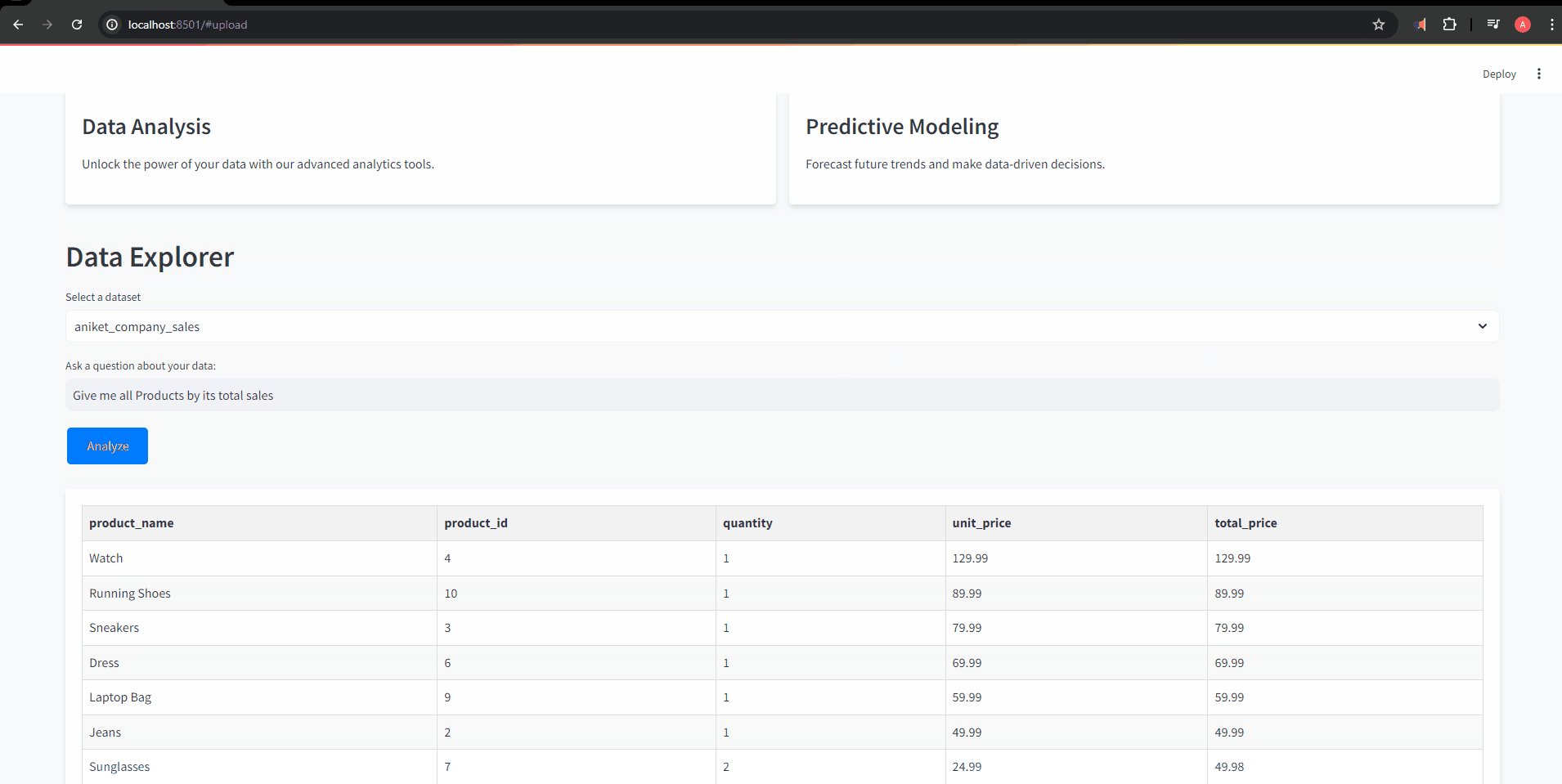
response = df_connector.chat(prompt)
if isinstance(response, pd.DataFrame):
formatted_response = format_df_to_html_table(response)
else:
formatted_response = f"<pre>{str(response)}</pre>"
st.markdown(f'<div class="card">{formatted_response}</div>', unsafe_allow_html=True)
chart_path = "exports/charts/temp_chart.png"
if os.path.exists(chart_path):
image = Image.open(chart_path)
st.image(image, caption="Generated Chart", use_column_width=True)
os.remove(chart_path)
except Exception as e:
st.error(f"An error occurred: {str(e)}")
else:
st.warning("Please enter a question about your data.")
else:
st.info("No datasets available. Please upload a CSV file to begin analysis.")在数据探索器部分,此块允许用户选择数据集并提出相关问题。该应用使用所选表连接到数据库,处理用户的问题,并以 HTML 表或纯文本形式显示分析结果,以及生成的任何图表。
上传新数据集部分
st.markdown('<a name="upload"></a>', unsafe_allow_html=True)'<a name="upload"></a>', unsafe_allow_html=True)
st.header("Upload New Dataset")
uploaded_file = st.file_uploader("Choose a CSV file", type="csv")
if uploaded_file is not None:
if st.button("Process Dataset"):
df = pd.read_csv(uploaded_file)
db_name = os.path.splitext(uploaded_file.name)[0]
db_path = os.path.join(DATABASE_FOLDER, f'{db_name}.db')
conn = sqlite3.connect(db_path)
df.to_sql(db_name, conn, if_exists='replace', index=False)
conn.close()
st.success(f"Dataset '{uploaded_file.name}' has been processed and is ready for analysis.")
st.experimental_rerun()此部分允许用户上传新的 CSV 数据集。
客户端入职模块
我开发了此代码来创建一个 Web 服务,该服务允许用户使用 Flask 将 CSV 数据上传到数据库并进行同步。通过设置路由来处理文件上传和 JSON 数据,我确保用户可以轻松处理和管理他们的数据。我添加了从 CSV 文件创建表格和同步记录以保持数据最新的功能。这些功能的目的是为用户提供一种简单、高效的方式,通过 Web 界面管理和分析他们的数据。
设置Flask应用程序
app = Flask(__name__)我初始化了一个 Flask 应用程序来处理 Web 请求和响应。这是处理和同步数据的 Web 服务的基础。
创建数据库文件夹
DATABASE_FOLDER = 'database''database'
if not os.path.exists(DATABASE_FOLDER):
os.makedirs(DATABASE_FOLDER)我检查了该database文件夹是否存在,如果不存在则创建它。这确保该文件夹可用于存储应用程序使用的数据库文件。
从 CSV 创建表
def create_table_from_csv(csv_file, table_name):
conn = sqlite3.connect(os.path.join(DATABASE_FOLDER, f'{table_name}.db'))
cursor = conn.cursor()
with open(csv_file, 'r') as file:
csv_reader = csv.reader(file)
headers = next(csv_reader)
create_table_query = f"CREATE TABLE IF NOT EXISTS {table_name} ({', '.join([f'{header} TEXT' for header in headers])})"
cursor.execute(create_table_query)
insert_query = f"INSERT INTO {table_name} VALUES ({', '.join(['?' for _ in headers])})"
cursor.executemany(insert_query, csv_reader)
conn.commit()
conn.close()此函数读取 CSV 文件并在 SQLite 数据库中创建相应的表。它首先连接到数据库,读取 CSV 标题以创建表列,然后将 CSV 数据插入表中。此设置允许轻松创建数据库并从 CSV 文件插入数据。
处理客户入职请求
@app.route('/process_client_onboard', methods=['POST'])
def process_client_onboard():
if 'file' not in request.files:
return jsonify({"error": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"error": "No selected file"}), 400
if file and file.filename.endswith('.csv'):
filename = file.filename
table_name = os.path.splitext(filename)[0]
file_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(file_path)
create_table_from_csv(file_path, table_name)
return jsonify({"message": f"Table '{table_name}' created successfully"}), 200
else:
return jsonify({"error": "Invalid file format. Please upload a CSV file."}), 400此路由负责处理 CSV 文件的上传和处理。它会检查请求中是否存在文件,验证文件类型,并将文件保存到上传文件夹。然后,它会调用create_table_from_csv从上传的 CSV 创建表。该路由会根据操作的成功或失败返回适当的响应。
同步数据
@app.route('/synch_up_data', methods=['POST'])
def synch_up_data():
data = request.json
if not data or 'table_name' not in data or 'records' not in data:
return jsonify({"error": "Invalid data format"}), 400
table_name = data['table_name']
records = data['records']
conn = sqlite3.connect(os.path.join(DATABASE_FOLDER, f'{table_name}.db'))
cursor = conn.cursor()
try:
cursor.execute(f"PRAGMA table_info({table_name})")
columns = [col[1] for col in cursor.fetchall()]
placeholders = ', '.join(['?' for _ in columns])
query = f"INSERT OR REPLACE INTO {table_name} ({', '.join(columns)}) VALUES ({placeholders})"
for record in records:
values = [record.get(col, None) for col in columns]
cursor.execute(query, values)
conn.commit()
return jsonify({"message": f"Data synchronized successfully for table '{table_name}'"}), 200
except sqlite3.Error as e:
return jsonify({"error": f"Database error: {str(e)}"}), 500
finally:
conn.close()此路由通过接受 JSON 输入来同步数据。它会检查数据是否包含必需的字段(table_name和records),连接到适当的 SQLite 数据库,并准备 SQL 查询以插入或替换指定表中的记录。该函数会处理任何潜在的数据库错误,并在完成后返回成功消息。
运行Flask应用程序
if __name__ == '__main__':
app.config['UPLOAD_FOLDER'] = 'uploads'
if not os.path.exists(app.config['UPLOAD_FOLDER']):
os.makedirs(app.config['UPLOAD_FOLDER'])
app.run(debug=True)最后,此块设置应用程序的上传文件夹配置,确保文件夹存在,并以调试模式启动 Flask 服务器。这允许应用程序处理文件上传和数据同步请求。
通过以这种方式构建代码,我的目标是创建一个强大且用户友好的应用程序,以高效处理和管理客户端数据。
实时销售更新模块
我创建了此代码来模拟公司产品的实时销售更新。该脚本会为各种产品生成随机销售数据,并将这些数据存储在 SQLite 数据库中。通过设置连续运行的循环,它会每分钟添加一条新的销售记录。这有助于测试和演示如何实时收集和管理销售数据,为评估数据处理和处理系统提供了一个现实的场景。
设置数据库和 CSV 文件名
db_name = "database/aniket_company_sales.db"
csv_file = "aniket_company_sales.csv"我指定了用于存储和检索销售数据的数据库和 CSV 文件的名称。这为数据存储和管理的位置提供了一致的参考。
定义产品信息
products = [
("001", "T-shirt", "Clothing", 19.99),
("002", "Jeans", "Clothing", 49.99),
("003", "Sneakers", "Footwear", 79.99),
("004", "Watch", "Accessories", 129.99),
("005", "Backpack", "Accessories", 39.99),
("006", "Dress", "Clothing", 69.99),
("007", "Sunglasses", "Accessories", 24.99),
("008", "Socks", "Clothing", 9.99),
("009", "Laptop Bag", "Accessories", 59.99),
("010", "Running Shoes", "Footwear", 89.99),我列出了各种产品及其详细信息,例如 ID、名称、类别和价格。这可以模拟不同产品的销售情况。
创建数据库连接
def create_connection():
return sqlite3.connect(db_name)此函数建立并返回与 SQLite 数据库的连接。它简化了在需要时连接数据库的过程。
将随机销售添加到数据库
def add_random_sale(conn):
cursor = conn.cursor()
date = (datetime.now() + timedelta(days=random.randint(0, 30))).strftime("%Y-%m-%d")
product = random.choice(products)
quantity = random.randint(1, 5)
total_price = round(product[3] * quantity, 2)
cursor.execute("""
INSERT INTO aniket_company_sales (date, product_id, product_name, category, quantity, unit_price, total_price)
VALUES (?, ?, ?, ?, ?, ?, ?)
""", (date, product[0], product[1], product[2], quantity, product[3], total_price))
conn.commit()
print(f"Added new sale: {date}, {product[1]}, Quantity: {quantity}, Total: ${total_price}")在这个函数中,我生成随机销售数据。我选择未来 30 天内的一个随机日期,从列表中选择一个随机产品,并计算出一个随机数量和总价。然后,我将这些数据插入数据库并提交更改。这模拟了添加新销售记录的过程。
运行脚本的主要函数
def main():
conn = create_connection()
while True:
add_random_sale(conn)
time.sleep(60) # Wait for 1 minute在主函数中,我创建了与数据库的连接,并每分钟不断添加随机销售记录。此循环确保定期生成和存储新的销售数据,模拟实时销售更新。
脚本的入口点
if __name__ == "__main__":__name__ == "__main__":
main()最后,我添加了这个块,以便main在直接执行脚本时运行该函数。这确保脚本在运行时开始生成销售数据。
通过以这种方式构建代码,我的目的是创建一个简单而有效的实时销售数据生成和存储模拟,使其可用于测试和演示目的。
让我们设置
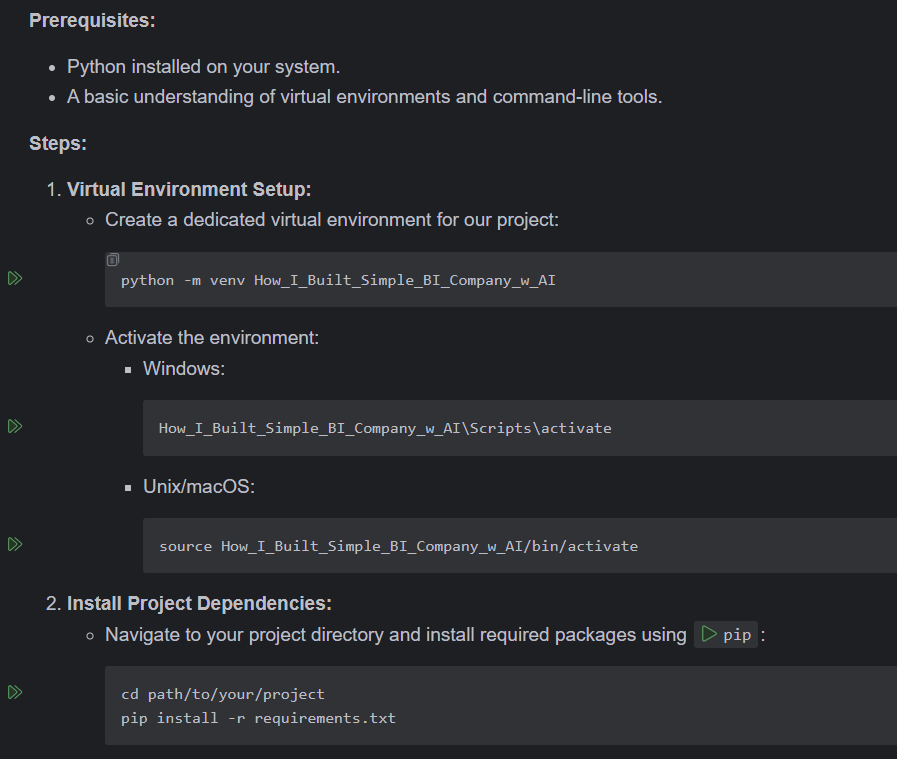
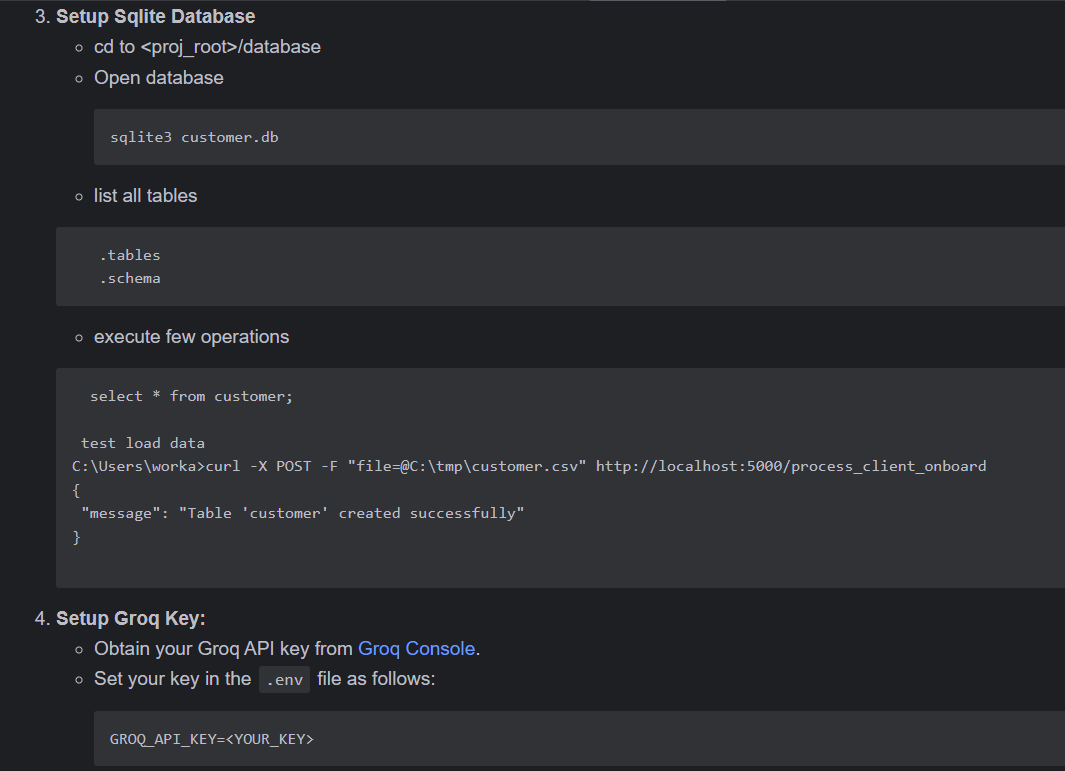
跑起来吧
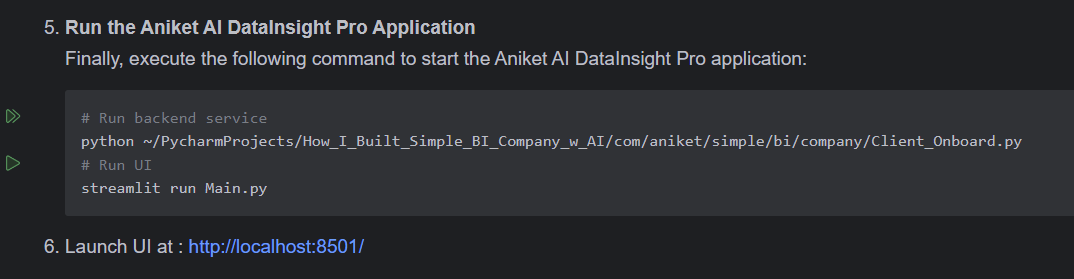
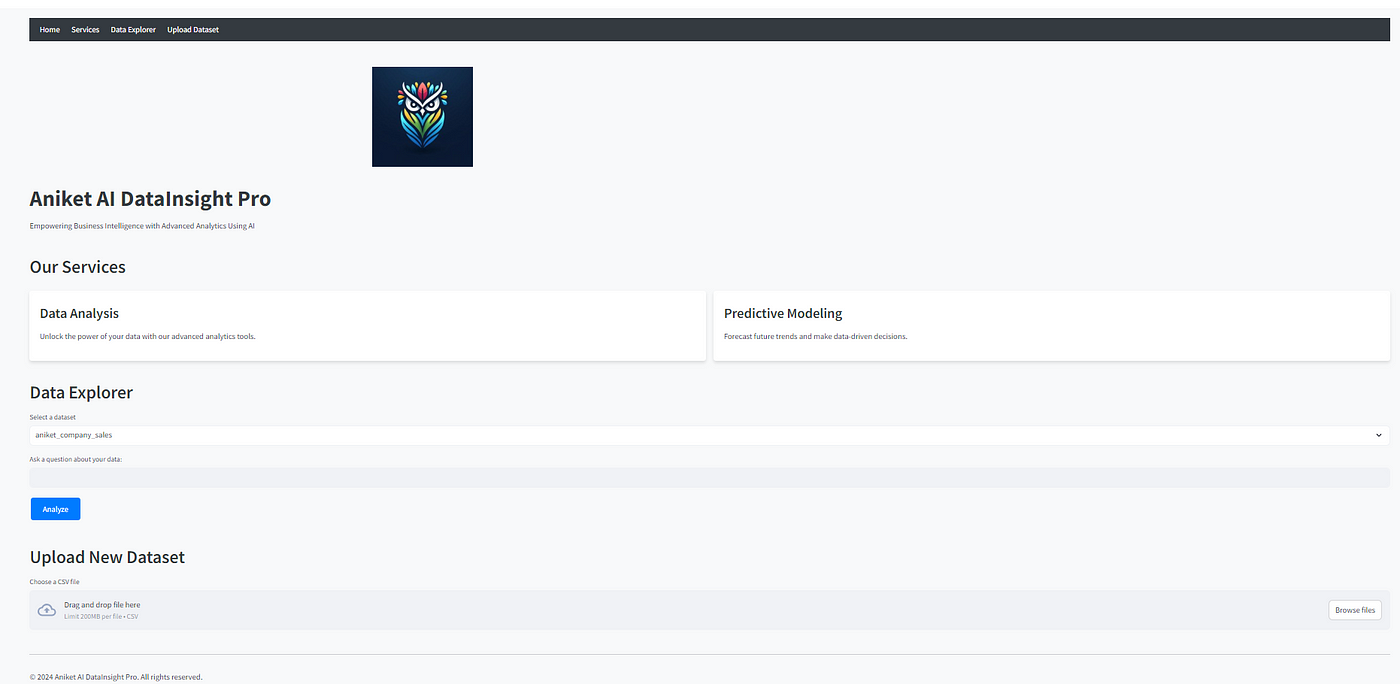
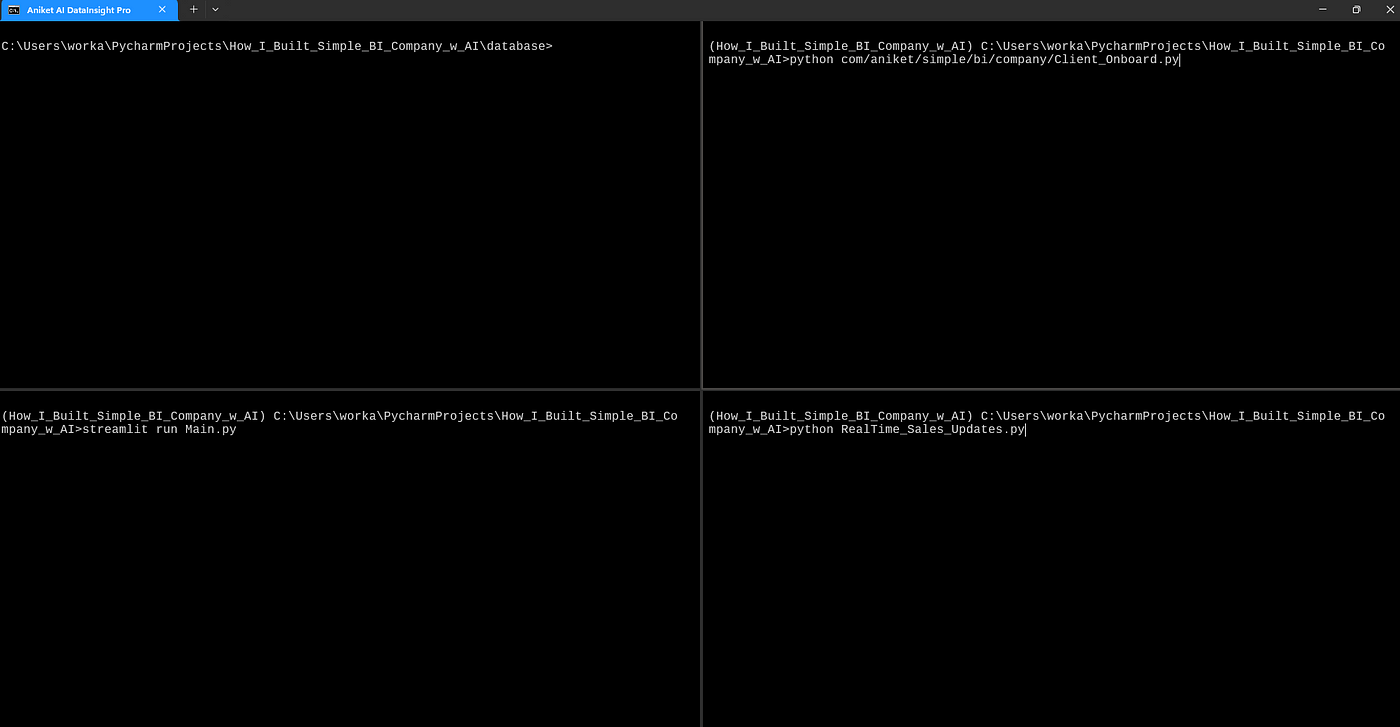
展示我们如何提供所有服务
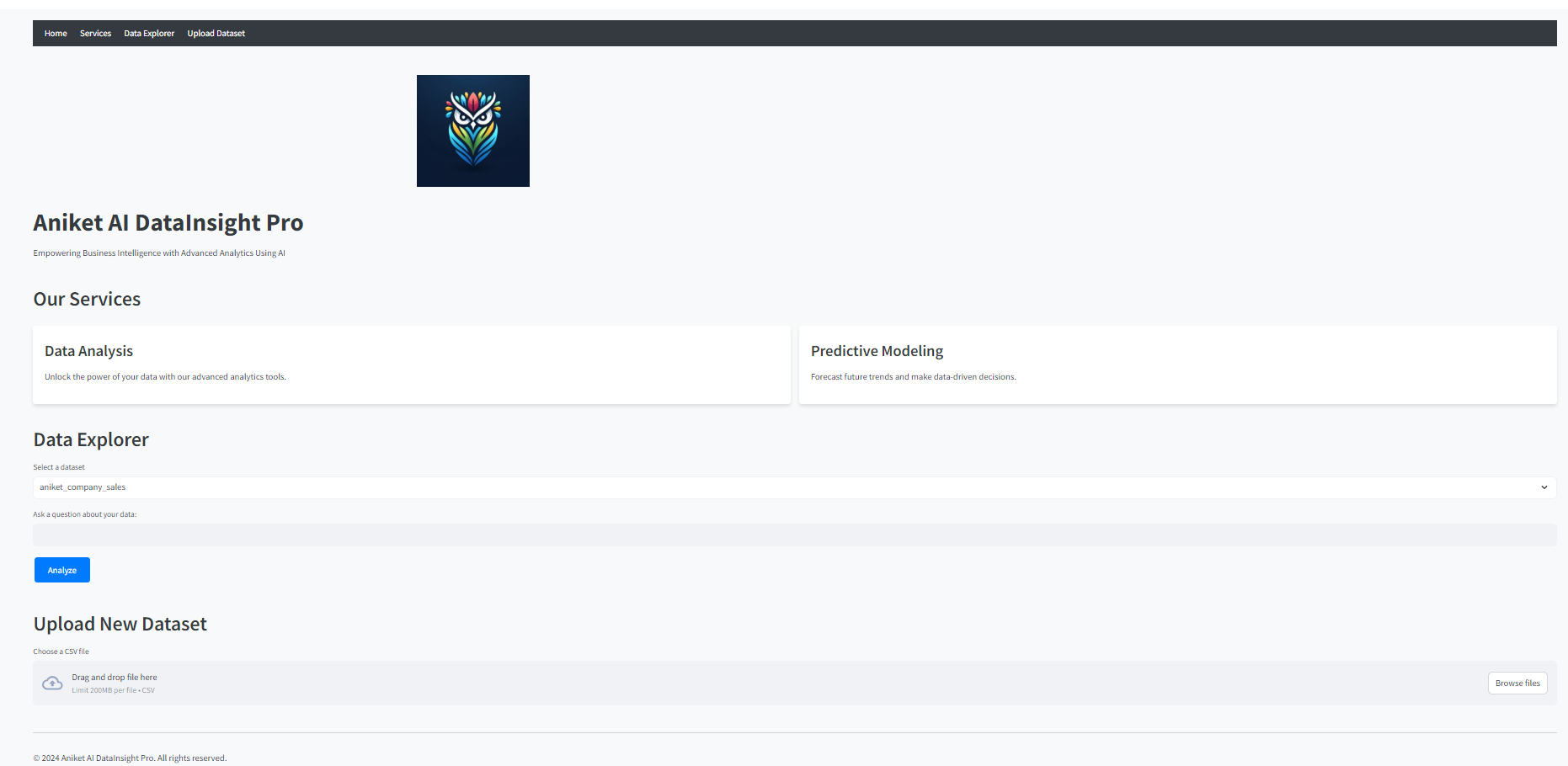
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









