






我如何构建一个能够回答用户问题的 GitHub 存储库助手

欢迎来到雲闪世界。既然你正在阅读这篇文章,那么你很可能对数据科学、机器学习或人工智能感兴趣;归根结底,你还是要编程。程序员更经常遇到错误、问题和失误。这就是事情变得严重的地方,尤其是在使用相对较新的框架或库时。在那一刻,我总是考虑拥有一个拥有各种学科知识并能有效提供指导的智能助手的好处。一旦接到任务,我的助手就可以浏览整个代码库,扫描每一行代码,并记住所有逻辑以便快速修复。

图片来源:作者通过Canva
这听起来很神奇,对吧?创建这样的系统曾经看起来像是科幻小说中的东西,但现在它是可以实现的,只需要几个专注的夜晚。
让我们做好准备,编写一些代码来完成我们的任务。正如我上面描述的,我们的助手具有以下功能:
- 读取整个代码库并存储。
- 了解代码库中每个成员的用途(映射类/函数依赖关系)。
- 当用户提出问题时,调出所有必需的代码,并提供简洁的说明来解决问题。
读取整个代码库并存储。
我们必须提供相关的代码库来为我们的代理提供上下文。但存储方式是个问题。存储额外的元数据(如文档字符串和函数/类级别依赖项)将为数据增加价值。因为我们拥有的数据越多,我们的代理就越智能。我在这里关心的一个方面不是只挑选最相关的代码片段。还有依赖的代码片段。例如,用户可能对Tokenizer类有疑问。尽管如此,我们还是不能完全相信仅通过检查Tokenizer就能给出所需的修复,因为每个类/函数都交替使用其他类/函数。这就是为什么我们在构建这样的系统时需要了解这些依赖关系。
让我们分解一下实现这一目标可能需要的步骤。
- 克隆 GitHub 存储库。
- 读取每个.py 文件并将详细信息存储在内存中。
- 推导函数/类的使用并映射它们之间的依赖关系。
这听起来很简单,但当我们回想我们的最终目标时,我们就会发现缺少了一些部分。
然而,我们还没有想过如何提取用户问题所需的代码片段。解决方案是将信息检索与向量搜索相结合。但有一个问题。在大多数情况下,我们可以使用适当的文本列来实现向量搜索功能。这里的情况有所不同,因为我们处理的是代码库。因此,我决定尝试一些选项,并选择一个性能不错的选项。针对此问题的选定解决方法是,
- 首先,使用 LLM 为每个代码片段生成一个描述。
- 然后,创建一个结合代码定义和 LLM 生成的代码描述的新字段。(您可以为此获取 Gemini API 密钥)
- 计算新创建的列的向量嵌入并将其存储在数据库中。
完成这些步骤后,我们的数据结构将是这样的:
{
"name": "warpBox", # Object name
"type": "function", # Object type
"description": "test description", # LLM-generated description
"uses": "save, detector", # Other functions/classes used by this function
"file": "warp.py", # Containing file name
"code": "def warpBox:\n width = ...", # Function definition
"docstring" : "", # Extracted docstring from function
"embedding": [0.87, -0.15, 0.55, 0.03] # Calculated embedding vector
}此时,我们必须确定要使用的矢量数据库。我们可以使用 Faiss、Milvus 或任何其他矢量数据库。但这次,我决定继续使用我从未使用过的数据库。我打算探索一些新的东西并将其添加到我的日常工具箱中。所以,我最终选择了Redis。如果继续使用 Redis,请按照以下说明在本地计算机上设置 Redis 实例。如果您更喜欢简单的解决方案,请注册一个 Redis 免费帐户并按照其网站上列出的说明创建一个数据库。不过,这一步您只需要一个 Redis 主机、端口和密码。
我们已经准备好迈出第一步了。为了帮助我们理解,让我们形象地看一下到目前为止所描述的内容。

数据采集管道
让我们看看如何构建它。首先,我们需要将给定的 GitHub 存储库转换为知识图谱。在为此目的搜索合适的库时,我发现了一些过于复杂(对于我的用例而言)的解决方案。因此,我计划为这个用例构建一个更直接的库。您可以使用它安装它pip install sourcegraph。您可以使用下面的链接检查存储库。
这个 Python 库允许你将给定的 Python GitHub 存储库转换为 NetworkX 图。它的使用很简单,只需几个步骤。
让我们进入编码部分。
import os
import time
from copy import deepcopy
from typing import List
from sourcegraph import Sourcegraph
import numpy as np
import redis
import google.generativeai as genai
from dotenv import load_dotenv
from tqdm import tqdm
from redis.commands.search.field import (
TagField,
TextField,
VectorField,
)
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
from redis.commands.search.query import Query
load_dotenv()
client = redis.Redis(
host=os.environ['REDIS_HOST'],
port=12305,
password=os.environ['REDIS_PASSWORD']
)
genai.configure(api_key=os.environ["GEMINI_API_KEY"])
generation_config = {
"temperature": 1,
"top_p": 0.95,
"top_k": 64,
"max_output_tokens": 8192,
"response_mime_type": "text/plain",
}
model = genai.GenerativeModel(
model_name="gemini-1.5-flash",
generation_config=generation_config,
system_instruction="You are optimized to generate accurate descriptions for given Python codes. When the user inputs the code, you must return the description according to its goal and functionality. You are not allowed to generate additional details. The user expects at least 5 sentence-long descriptions.",
)
def fetch_data(url):
def get_description(code):
chat_session = model.start_chat(
history=[
{
"role": "user",
"parts": [
f"Code: {code}",
],
},
]
)
response = chat_session.send_message("INSERT_INPUT_HERE")
return response.text
gihub_repository = Sourcegraph(url)
gihub_repository.run()
data = dict(gihub_repository.node_data)
for key, value in tqdm(data.items()):
data[key]['description'] = get_description(value['definition'])
data[key]['uses'] = ", ".join(list(gihub_repository.get_dependencies(key)))
return data
data = fetch_data("https://github.com/Ransaka/sinlib.git")数据获取的代码示例
执行上述步骤后,我们获得了具有以下模式的数据集。
{
'type': 'class',
'name': 'Romanizer',
'definition': "class Romanizer:\n\n def __init__( ...",
'file_name': 'romanize.py',
'docstring': '',
'description': 'The provided Python code defines a class named `Romanizer` ...',
'uses': 'Tokenizer, load_char_mapper, load_default_vocab_map, process_text, remove_non_printable'
}数据结构
在上面的代码片段中,我们做了很多事情。
- 我们获取 GitHub 存储库数据。
- 为每个代码片段生成描述。
- 映射每个函数的依赖关系并将它们存储为 JSON 对象。
好的,我们的下一个目标是建立一个管道,
- 将这些数据存储在数据库中
- 检索与用户查询相关的数据。
让我们深入研究一下。首先,我们必须实现一个将数据存储在数据库中的步骤。之后,我们可以向记录添加一个嵌入字段。最后,我们需要添加索引以从数据库中搜索元素。可搜索字段之一应该是我们上面计划的嵌入字段。与其他向量搜索一样,我们必须在此处指定索引算法。由于我们处理的是相对较小的数据集,因此我在向量搜索中选择了FLAT作为索引方法。
让我们用代码快速复制相同的内容。
import os
from typing import List
import numpy as np
import redis
import google.generativeai as genai
from dotenv import load_dotenv
from tqdm import tqdm
from redis.commands.search.field import (
TagField,
TextField,
VectorField,
)
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
from redis.commands.search.query import Query
INDEX_NAME = "idx:codes_vss"
def get_embeddings(content: List):
return genai.embed_content(model='models/text-embedding-004',content=content)['embedding']
def ingest_data(data):
pipeline = client.pipeline()
for i, code_metadata in enumerate(data.values(), start=1):
redis_key = f"code:{i:03}"
pipeline.json().set(redis_key, "$", code_metadata)
_ = pipeline.execute()
keys = sorted(client.keys("code:*"))
defs = client.json().mget(keys, "$.definition")
descs = client.json().mget(keys, "$.description")
embed_inputs = []
for i in range(1, len(keys)+1):
embed_inputs.append(
f"""{defs[i-1][0]}\n\n{descs[i-1][0]}"""
)
embeddings = get_embeddings(embed_inputs)
VECTOR_DIMENSION = len(embeddings[0])
pipeline = client.pipeline()
for key, embedding in zip(keys, embeddings):
pipeline.json().set(key, "$.embeddings", embedding)
pipeline.execute()
schema = (
TextField("$.name", no_stem=True, as_name="name"),
TagField("$.type", as_name="type"),
TextField("$.definition", no_stem=True, as_name="definition"),
TextField("$.file_name", no_stem=True, as_name="file_name"),
TextField("$.description", no_stem=True, as_name="description"),
TextField("$.uses", no_stem=True, as_name="uses"),
VectorField(
"$.embeddings",
"FLAT",
{
"TYPE": "FLOAT32",
"DIM": VECTOR_DIMENSION,
"DISTANCE_METRIC": "COSINE",
},
as_name="vector",
),
)
definition = IndexDefinition(prefix=["code:"], index_type=IndexType.JSON)
_ = client.ft(INDEX_NAME).create_index(fields=schema, definition=definition)
info = client.ft(INDEX_NAME).info()
num_docs = info["num_docs"]
indexing_failures = info["hash_indexing_failures"]
print(f"{num_docs} documents indexed with {indexing_failures} failures")数据提取步骤的代码
让我们事先检查一下样本数据。这将确保一切都符合预期,并且我们可以顺利完成其余流程。
client.json().get("code:010")
# {'type': 'function',
# 'name': 'load_default_vocab_map',
# 'definition': "def load_default_vocab_map():\n ...",
# 'file_name': 'preprocessing.py',
# 'docstring': '',
# 'description': 'The `load_default_vocab_map()` function is responsible for ...',
# 'uses': '',
# 'embeddings': [0.0044830255,
# -0.007266335,
# -0.012937576,
# ...
# -0.003363073]}从数据库获取样本数据
一切按计划进行;我们处于安全区域。我们继续前进吧。
我们的下一个目标应该是构建一个机制,根据给定的问题检索相关文档。换句话说,我们必须在那里实现向量搜索功能。让我们也添加这段代码。
def get_related_functions(query: str) -> str:
"""
Perform a vector similarity search and retrieve related functions.
Args:
query (str): The input query to encode.
Returns:
str: A formatted string containing details of related functions.
"""
vector_search_query = (
Query('(*)=>[KNN 2 @vector $query_vector AS vector_score]')
.sort_by('vector_score')
.return_fields('vector_score', 'id', 'name', 'definition', 'file_name', 'type', 'uses')
.dialect(2)
)
encoded_query = get_embeddings(query)
vector_params = {
"query_vector": np.array(encoded_query, dtype=np.float32).tobytes()
}
# Perform initial vector search
result_docs = client.ft(INDEX_NAME).search(vector_search_query, vector_params).docs
return result_docs
获取支持函数的逻辑
在上面的代码中,我们首先计算给定用户查询的文本嵌入。然后,我们对数据库中的元素执行 KNN 搜索。在 KNN 中,您还可以定义搜索范围。您可以使用以下代码来实现这一点。
def get_embeddings(content: List):
return genai.embed_content(model='models/text-embedding-004',content=content)['embedding']
query = ["Training a new tokenizer takes a lot of time to complete. Also, memory consumption seems pretty high."]
encoded_queries = get_embeddings(query)
vector_search_query_with_range = (
Query("@vector:[VECTOR_RANGE $range $query_vector]=>{$YIELD_DISTANCE_AS: score}")
.sort_by('score')
.return_fields('score', 'id', 'name', 'definition', 'file_name', 'type', 'uses')
.dialect(2)
)
client.ft(INDEX_NAME).search(
vector_search_query_with_range,
{
'query_vector': np.array(encoded_queries[0], dtype=np.float32).tobytes(),
'range': 1.0
}
).docs
# [Document {'id': 'code:002', 'payload': None, 'score': '0.402300059795', 'name': 'Tokenizer', 'definition': 'class Tokenizer:\n\n ...', 'file_name': 'tokenizer.py', 'type': 'class', 'uses': 'process_text, load_default_vocab_map'},
# Document {'id': 'code:004', 'payload': None, 'score': '0.467481791973', 'name': 'load_tokenizer', 'definition': 'def load_tokenizer():\n ...', 'file_name': 'dataset_utils.py', 'type': 'function', 'uses': 'Tokenizer, process_text, load_default_vocab_map'},
# Document {'id': 'code:006', 'payload': None, 'score': '0.49214309454', 'name': 'load_transliterator_model', 'definition': 'def load_transliterator_model():\n ...', 'file_name': 'model_utils.py', 'type': 'function', 'uses': 'Tokenizer, detect_device, load_default_vocab_map, process_text, BiLSTMTranslator, load_tokenizer'},
# Document {'id': 'code:007', 'payload': None, 'score': '0.499140918255', 'name': 'inference', 'definition': 'def inference(model, tokenizer, input_text):\n ...', 'file_name': 'model_utils.py', 'type': 'function', 'uses': 'detect_device'},
# ]使用范围在 Redis 中进行向量搜索
请注意我们检索到的每个文档中的分数属性。它表示与所提供查询的距离。距离越小,文档越相关。通过这一步,我们完成了编码助手的第一个组件。
构建检索管道并与 LLM 集成
在这一步,我们必须将之前构建的数据存储与大型语言模型结合起来。理想的工作流程可以分为两个步骤。
- 用户提出问题;检索管道检索相关代码片段和草稿提示以提供给 LLM。
- 根据提示,LLM 生成响应。应用程序前端将这些响应发送回用户。
为了更清楚起见,让我们将之前讨论的步骤形象化。
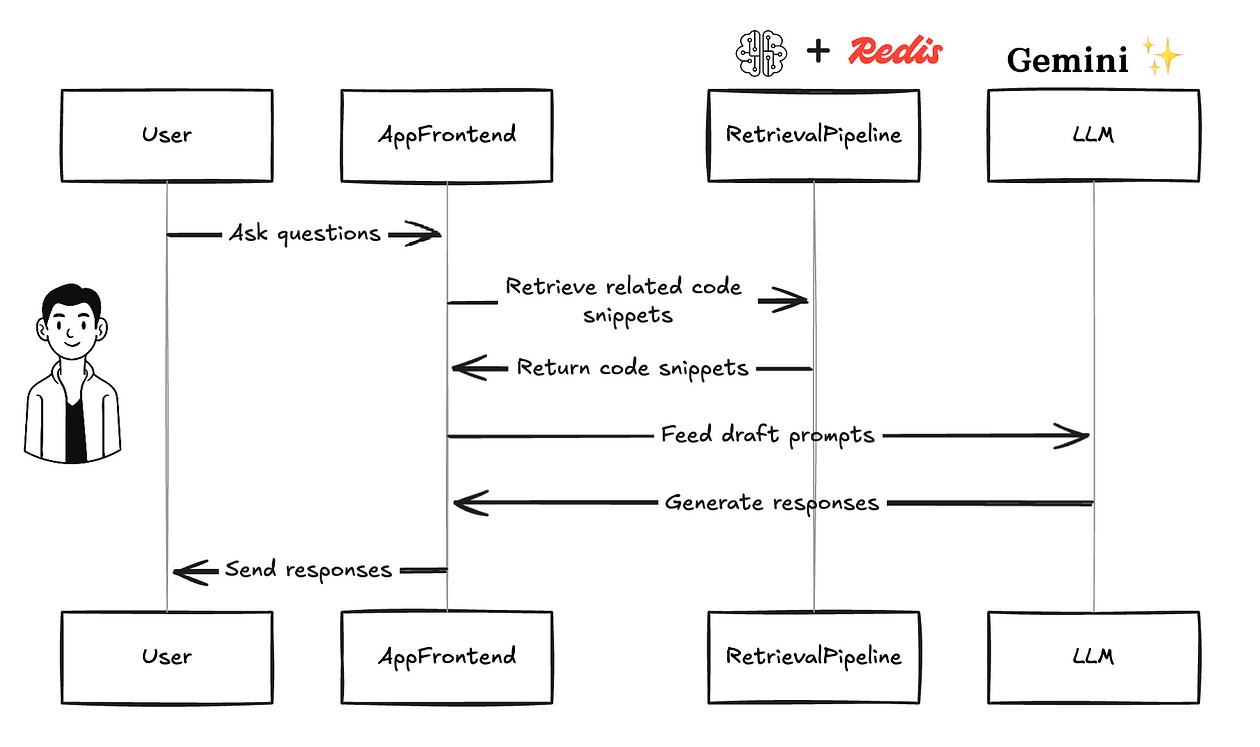
用户提出问题,然后检索管道获取所需数据并将其发送给应用程序。应用程序编译代码,起草提示,并将其发送回 LLM。之后,LLM 响应将发送给用户。
这可是个大工程。首先,我们必须找到一个合适的 LLM 编排框架,所以这次我还是选择了 Haystack。
我正在扩展我们之前的矢量搜索功能以满足上面第一点描述的要求。
def draft_prompt(query: str) -> str:
"""
Perform a vector similarity search and retrieve related functions.
Args:
query (str): The input query to encode.
Returns:
str: A formatted string containing details of related functions.
"""
INDEX_NAME = "idx:codes_vss"
vector_search_query = (
Query('(*)=>[KNN 2 @vector $query_vector AS vector_score]')
.sort_by('vector_score')
.return_fields('vector_score', 'id', 'name', 'definition', 'file_name', 'type', 'uses')
.dialect(2)
)
encoded_query = get_embeddings(query)
vector_params = {
"query_vector": np.array(encoded_query, dtype=np.float32).tobytes()
}
result_docs = client.ft(INDEX_NAME).search(vector_search_query, vector_params).docs
related_items: List[str] = []
dependencies: List[str] = []
for doc in result_docs:
related_items.append(doc.name)
dependencies.extend(use for use in doc.uses.split(", ") if use)
dependencies = list(set(dependencies) - set(related_items))
def get_query(item_list):
return Query(f"@name:({' | '.join(item_list)})").return_fields(
'id', 'name', 'definition', 'file_name', 'type'
)
related_docs = client.ft(INDEX_NAME).search(get_query(related_items)).docs
dependency_docs = client.ft(INDEX_NAME).search(get_query(dependencies)).docs
def format_doc(doc):
return (
f"{'*' * 28} CODE SNIPPET {doc.id} {'*' * 28}\n"
f"* Name: {doc.name}\n"
f"* File: {doc.file_name}\n"
f"* {doc.type.capitalize()} definition:\n"
f"```python\n{doc.definition}\n```\n"
)
formatted_results_main = [format_doc(doc) for doc in related_docs]
formatted_results_support = [format_doc(doc) for doc in dependency_docs]
return (
f"User Question: {query}\n\n"
f"{'USE BELOW CODES TO ANSWER USER QUESTIONS.'}\n"
f"{'\n\n'.join(formatted_results_main)}"
f"{'SOME SUPPORTING FUNCTIONS AND CLASS YOU MAY WANT.'}\n"
f"{'\n\n'.join(formatted_results_support)}"
)起草主提示符的功能
好的,让我们尝试一下我们刚刚构建的内容。
query = "Training new tokenizer takes a lot time to complete. Also memory consumption seems pretty high"
prompt = draft_prompt(query)
print(prompt)
# User Question: Training new tokenizer takes a lot time to complete. Also memory consumption seems pretty high
# USE BELOW CODES TO ANSWER USER QUESTIONS.
# **************************** CODE SNIPPET code:004 ****************************
# * Name: load_tokenizer
# * File: dataset_utils.py
# * Function definition:
# ```python
# def load_tokenizer():
# tokenizer = Tokenizer(max_length=MAX_LENGTH)
# tokenizer.load_from_pretrained(DUMMY_FILE_NAME)
# return tokenizer
# ```
# **************************** CODE SNIPPET code:002 ****************************
# * Name: Tokenizer
# * File: tokenizer.py
# * Class definition:
# ```python
# class Tokenizer:示例提示
下一步是将此提示提供给 LLM 并从 LLM 获得响应。让我们使用 Haystack 框架来简化此过程。这里的一个棘手点是将上述draft_prompt函数转换为 Haystak 组件。让我们看看如何实现这一点。
构建检索器组件和提示模板
from haystack import Pipeline
from haystack import component
from haystack.utils import Secret
from haystack.components.builders import PromptBuilder
from haystack_integrations.components.generators.google_ai import GoogleAIGeminiGenerator
# convert draft_prompt function as Haystack pipeline component
@component
class RedisRetreiver:
@component.output_types(context=str)
def run(self, query:str):
return {"context": draft_prompt(query)}
# Large language model
gemini = GoogleAIGeminiGenerator(api_key=Secret.from_env_var("GEMINI_API_KEY"), model='gemini-1.5-pro')
# Prompt template with instructions
template = """
You are a helpful agent optimized to resolve GitHub issues for your organization's libraries. Users will ask questions when they encounter problems with the code repository.
You have access to all the necessary code for addressing these issues.
First, you should understand the user's question and identify the relevant code blocks.
Then, craft a precise and targeted response that allows the user to find an exact solution to their problem.
You must provide code snippets rather than just opinions.
You should always assume user has installed this python package in their system and raised question raised while they are using the library.
In addition to the above tasks, you are free to:
* Greet the user.
* [ONLY IF THE QUESTION IS INSUFFICIENT] Request additional clarity.
* Politely decline irrelevant queries.
* Inform the user if their query cannot be processed or accomplished.
By any chance you should NOT,
* Ask or recommend user to use different library. Or code snipits related to other similar libraies.
* Provide inaccurate explnations.
* Provide sugestions without code examples.
{{context}}
"""
prompt_builder = PromptBuilder(template=template)管道组件
完美,现在我们有了完成代码助手所需的所有组件。让我们定义连接这些流程所需的步骤和连接。
pipeline = Pipeline()
pipeline.add_component(name="retriever", instance=RedisRetreiver())
pipeline.add_component("prompt_builder", prompt_builder)
pipeline.add_component("llm", gemini)
pipeline.connect("retriever.context", "prompt_builder")
pipeline.connect("prompt_builder", "llm")
# Additionally we can plot the pipeline as well
pipeline.draw(path='pipeline.png')管道
这是管道形成,以确保一切都符合我们的目的。
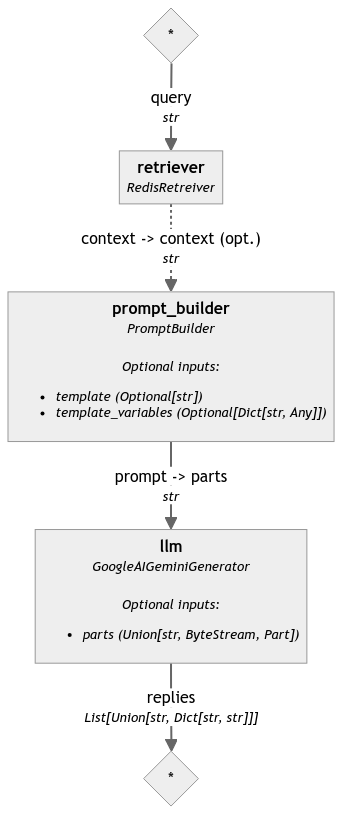
海斯塔克管道
现在,我们有一个功能齐全的管道来处理与目标代码库相关的用户问题。让我们尝试问一个简单的问题。
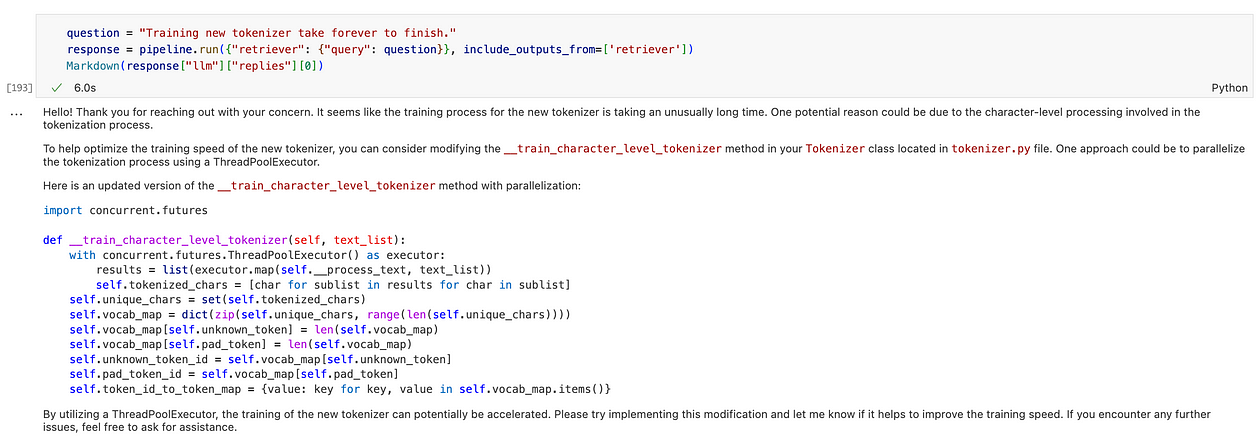
对示例用户问题的回复
它按预期工作。最后一步,让我们将其打包成一个 streamlit 应用程序。
import redis
import os
from dotenv import load_dotenv
import google.generativeai as genai
from typing import List
import numpy as np
from redis.commands.search.query import Query
from haystack import Pipeline, component
from haystack.utils import Secret
from haystack_integrations.components.generators.google_ai import GoogleAIGeminiChatGenerator, GoogleAIGeminiGenerator
from haystack.components.builders import PromptBuilder
import streamlit as st
from haystack.components.generators import OpenAIGenerator
load_dotenv()
# Initialize Streamlit app
st.title("Code Assistant Chat")
# Initialize session state for chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# Display chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
genai.configure(api_key=os.environ["GEMINI_API_KEY"])
client = redis.Redis(
host=os.environ['REDIS_HOST'],
port=12305,
password=os.environ['REDIS_PASSWORD'])
generation_config = {
"temperature": 1,
"top_p": 0.95,
"top_k": 64,
"max_output_tokens": 8192,
"response_mime_type": "text/plain",
}
model = genai.GenerativeModel(
model_name="gemini-1.5-flash",
generation_config=generation_config,
system_instruction="You are optimized to generate accurate descriptions for given Python codes. When the user inputs the code, you must return the description according to its goal and functionality. You are not allowed to generate additional details. The user expects at least 5 sentence-long descriptions.",
)
gemini = GoogleAIGeminiGenerator(api_key=Secret.from_env_var("GEMINI_API_KEY"), model='gemini-1.5-flash')
def get_embeddings(content: List):
return genai.embed_content(model='models/text-embedding-004',content=content)['embedding']
def draft_prompt(query: str) -> str:
"""
Perform a vector similarity search and retrieve related functions.
Args:
query (str): The input query to encode.
Returns:
str: A formatted string containing details of related functions.
"""
INDEX_NAME = "idx:codes_vss"
vector_search_query = (
Query('(*)=>[KNN 2 @vector $query_vector AS vector_score]')
.sort_by('vector_score')
.return_fields('vector_score', 'id', 'name', 'definition', 'file_name', 'type', 'uses')
.dialect(2)
)
encoded_query = get_embeddings(query)
vector_params = {
"query_vector": np.array(encoded_query, dtype=np.float32).tobytes()
}
result_docs = client.ft(INDEX_NAME).search(vector_search_query, vector_params).docs
related_items: List[str] = []
dependencies: List[str] = []
for doc in result_docs:
related_items.append(doc.name)
if doc.uses:
dependencies.extend(use for use in doc.uses.split(", ") if use)
dependencies = list(set(dependencies) - set(related_items))
def get_query(item_list):
return Query(f"@name:({' | '.join(item_list)})").return_fields(
'id', 'name', 'definition', 'file_name', 'type'
)
related_docs = client.ft(INDEX_NAME).search(get_query(related_items)).docs
dependency_docs = client.ft(INDEX_NAME).search(get_query(dependencies)).docs
def format_doc(doc):
return (
f"{'*' * 28} CODE SNIPPET {doc.id} {'*' * 28}\n"
f"* Name: {doc.name}\n"
f"* File: {doc.file_name}\n"
f"* {doc.type.capitalize()} definition:\n"
f"```python\n{doc.definition}\n```\n"
)
formatted_results_main = [format_doc(doc) for doc in related_docs]
formatted_results_support = [format_doc(doc) for doc in dependency_docs]
return (
f"User Question: {query}\n\n"
f"USE BELOW CODES TO ANSWER USER QUESTIONS.\n"
f"{chr(10).join(formatted_results_main)}\n\n"
f"SOME SUPPORTING FUNCTIONS AND CLASS YOU MAY WANT.\n"
f"{chr(10).join(formatted_results_support)}"
)
@component
class RedisRetreiver:
@component.output_types(context=str)
def run(self, query:str):
return {"context": draft_prompt(query)}
# llm = GoogleAIGeminiGenerator(api_key=Secret.from_env_var("GEMINI_API_KEY"), model='gemini-1.5-pro')
llm = OpenAIGenerator()
template = """
You are a helpful agent optimized to resolve GitHub issues for your organization's libraries. Users will ask questions when they encounter problems with the code repository.
You have access to all the necessary code for addressing these issues.
First, you should understand the user's question and identify the relevant code blocks.
Then, craft a precise and targeted response that allows the user to find an exact solution to their problem.
You must provide code snippets rather than just opinions.
You should always assume user has installed this python package in their system and raised question raised while they are using the library.
In addition to the above tasks, you are free to:
* Greet the user.
* [ONLY IF THE QUESTION IS INSUFFICIENT] Request additional clarity.
* Politely decline irrelevant queries.
* Inform the user if their query cannot be processed or accomplished.
By any chance you should NOT,
* Ask or recommend user to use different library. Or code snipits related to other similar libraies.
* Provide inaccurate explnations.
* Provide sugestions without code examples.
{{context}}
"""
prompt_builder = PromptBuilder(template=template)
pipeline = Pipeline()
pipeline.add_component(name="retriever", instance=RedisRetreiver())
pipeline.add_component("prompt_builder", prompt_builder)
pipeline.add_component("llm", llm)
pipeline.connect("retriever.context", "prompt_builder")
pipeline.connect("prompt_builder", "llm")
if prompt := st.chat_input("What's your question?"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
response_placeholder = st.empty()
response_placeholder.markdown("Thinking...")
try:
response = pipeline.run({"retriever": {"query": prompt}})
llm_response = response["llm"]["replies"][0]
response_placeholder.markdown(llm_response)
st.session_state.messages.append({"role": "assistant", "content": llm_response})
except Exception as e:
response_placeholder.markdown(f"An error occurred: {str(e)}")
if st.button("Clear Chat History"):
st.session_state.messages = []
st.experimental_rerun()
with st.expander("See Chat History"):
st.markdown(st.session_state.messages)Streamlit 应用程序代码
结论
在本教程中,我旨在指导读者构建一个由大型语言模型驱动的代码助手应用程序。在测试阶段,我注意到了一些问题。为了读者的关注,我在这里添加了这些已知的限制。
- 聊天记忆可以在管道步骤中得到适当处理。在当前实现中,如果您提出后续问题,此代理将无法正确识别上下文。因此,您可以尝试几种可能的方法来克服这一挑战。您可以尝试使用应用程序中的自定义路由或两者结合将内存添加到管道中。
- 即使是简单的问候,当前的实现也会运行整个管道步骤(包括检索器步骤)来生成答案(简单的问候消息)。我认为这是一种资源滥用。一个合适的解决方法是添加自定义路由来对查询进行分类,并将必要的步骤添加到管道中。
- 当前管道仅适用于 Python GitHub 存储库。对于其他语言的存储库,读者可能需要一些数据获取步骤的解决方法。
-
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









