







欢迎来到雲闪世界。本文深入探讨了对数据科学从业者有用的高级 SQL 技术。在本文中,我将详细探讨我在分析项目中每天使用的专家级 SQL 查询。SQL 与现代数据仓库一起构成了数据科学的支柱。它是数据处理和用户行为分析不可或缺的工具。我将要讨论的技术旨在从数据科学的角度进行实用和有益的分析。掌握 SQL 是一项宝贵的技能,对各种项目都至关重要,这些技术大大简化了我的日常工作。我希望这对你也有用。
鉴于 SQL 是数据仓库和商业智能专业人员使用的主要语言,它是跨数据平台共享数据的理想选择。其强大的功能有助于实现无缝数据建模和可视化。它仍然是任何数据团队和市场上几乎所有数据平台最受欢迎的沟通方式。
我们将使用 BigQuery 的标准 SQL 方言。运行我编写并在下面提供的查询是免费且简单的。
递归 CTE
类似地,我们将使用 Python 的faker库,我们可以使用 SQL 中的递归 CTE 模拟测试数据。
WITH RECURSIVE
CTE_1 AS (
(SELECT 0 AS iteration)
UNION ALL
SELECT iteration + 1 AS iteration FROM CTE_1 WHERE iteration < 3
)
SELECT iteration FROM CTE_1
ORDER BY 1 ASC输出如下:
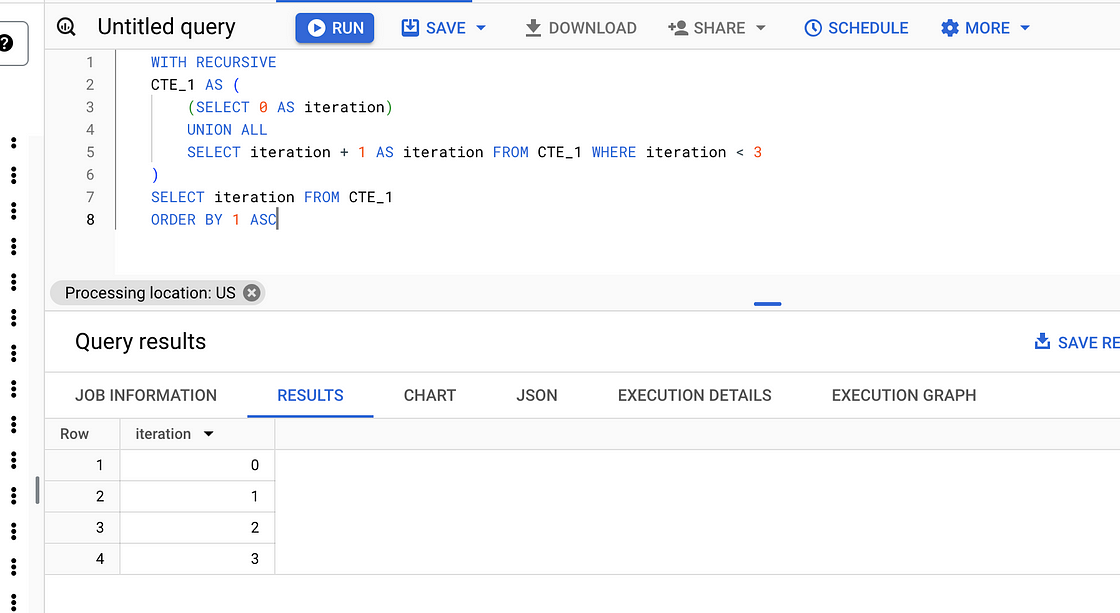
图片来自作者。
在 BigQuery 和许多其他数据仓库解决方案中,CTE 可以是非递归的,也可以是递归的。RECURSIVE关键字允许在 WITH 子句中使用递归(例如,WITH RECURSIVE)。
递归 CTE 持续执行,直到没有产生新结果,这使得它们非常适合查询分层数据和图形数据。在我们的例子中,执行将停止由以下子句定义where:FROM CTE_1 WHERE iteration < 3
相比之下,非递归 CTE 只执行一次。
主要区别在于非递归 CTE 只能引用前面的 CTE 而不能引用自身,而递归 CTE 可以引用自身以及前面或后面的 CTE。
使用图表
使用递归 CTE 处理图形数据非常方便。在数据科学领域,图形是一个非常简洁的概念,几乎无处不在。在数据工程中,我经常使用dependency graphs它来展示数据管道中的数据沿袭。
我们可以使用递归 SQL 技术来评估图中的可达性。在下面的代码片段中,我们将发现nodes可以从node table_5名为SampleGraph
WITH RECURSIVE
SampleGraph AS (
-- table_1 table_5
-- / \ / \
-- table_2 - table_3 table_6 table_7
-- | \ /
-- table_4 table_8
SELECT 'table_1' AS from_node, 'table_2' AS to_node UNION ALL
SELECT 'table_1', 'table_3' UNION ALL
SELECT 'table_2', 'table_3' UNION ALL
SELECT 'table_3', 'table_4' UNION ALL
SELECT 'table_5', 'table_6' UNION ALL
SELECT 'table_5', 'table_7' UNION ALL
SELECT 'table_6', 'table_8' UNION ALL
SELECT 'table_7', 'table_8'
),
R AS (
(SELECT 'table_5' AS node)
UNION ALL
(
SELECT SampleGraph.to_node AS node
FROM R
INNER JOIN SampleGraph
ON (R.node = SampleGraph.from_node)
)
)
SELECT DISTINCT node FROM R ORDER BY node;输出:
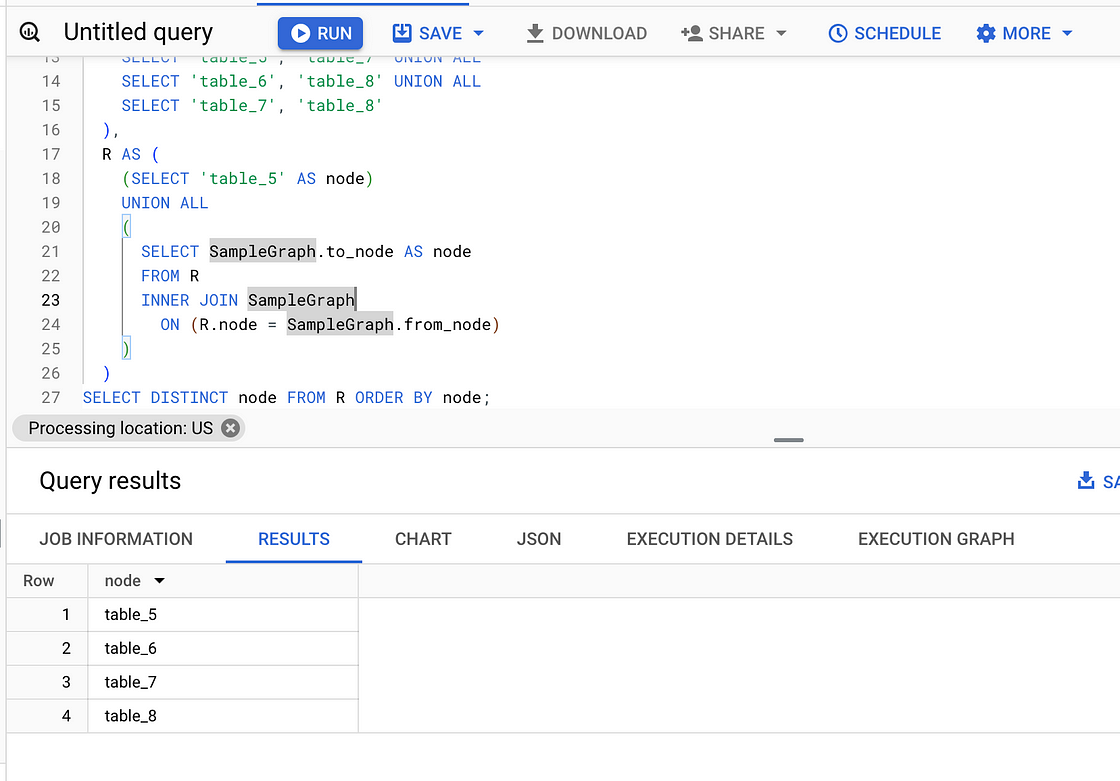
图片来自作者
递归 CTE 非常昂贵,我们希望确保它们用于预期目的。如果您的查询不涉及图表或分层数据,那么探索替代方案可能会更有效,例如结合使用 LOOP 语句和非递归 CTE。
另外,请注意无限递归。我们不希望 SQL 永远运行下去。
模糊匹配和近似连接
在我们需要连接两个数据集(虽然它们值不相同,但非常相似)的情况下,模糊匹配非常有用。这些场景需要更复杂的方法来确保准确的数据匹配。模糊匹配技术是数据分析师在近似 JOIN中经常依赖的高级 SQL 方法的一个很好的例子。
为了说明这一点,请考虑以下 SQL 代码片段:
with people as (
select 'gmail' as domain, 'john.adams@gmail.com' as email
union all
select 'gmail' as domain, 'dave.robinson@gmail.com' as email
)
, linkedin as (
select
'gmail' as domain
,'Dave Robinson' as name
)
, similarity as (
select
linkedin.name as name
, linkedin.domain as domain
, people.email
, fhoffa.x.levenshtein(linkedin.name, people.email) similarity_score
from linkedin
join people
on linkedin.domain = people.domain
)
select
*
, row_number() over (partition by name order by similarity_score) as best_match
from
similarity我们可以应用邻近函数(例如ngramdistance(在 Clickhouse 中可用)和levenshtein(BigQuery))来识别彼此相似的电子邮件。
分数越低表示匹配越好:
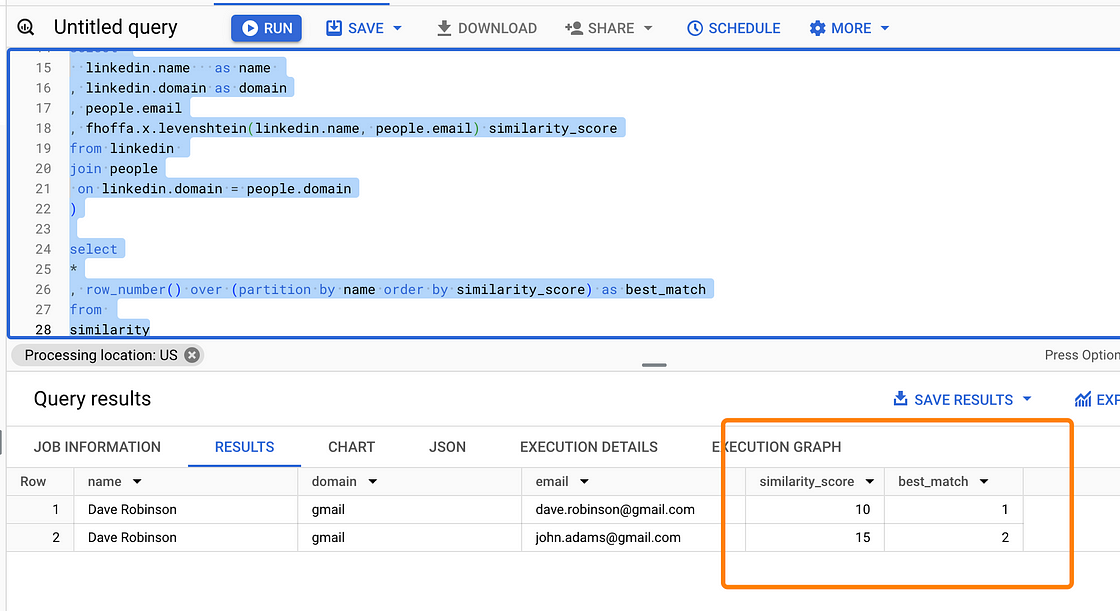
图片来自作者
事实证明,这种方法在使用属性(即电子邮件地址)匹配来自两个独立数据集的实体(即个人等)的任务中非常有用。当处理来自 LinkedIn、Crunchbase 等平台的数据时,这是一个简单的场景,我们需要对齐用户信息。
使用 LEAD 和 LAG 运算符计算用户活动和会话
窗口函数在数据科学中被证明非常有用。
我们经常需要计算会话来汇总用户活动。下面的示例演示了如何在 SQL 中执行此操作。
-- models/sessions.sql
-- mock some data
with raw_event_data as (
select 'A' as user_id, timestamp_add(current_timestamp(), interval -1 minute) as timestamp union all
select 'A' as user_id, timestamp_add(current_timestamp(), interval -3 minute) as timestamp union all
select 'A' as user_id, timestamp_add(current_timestamp(), interval -5 minute) as timestamp union all
select 'A' as user_id, timestamp_add(current_timestamp(), interval -36 minute) as timestamp union all
select 'A' as user_id, timestamp_add(current_timestamp(), interval -75 minute) as timestamp
)
-- calculate sessions:
SELECT
event.user_id || '-' || row_number() over(partition by event.user_id order by event.timestamp) as session_id
, event.user_id
, event.timestamp as session_start_at
, lead(timestamp) over(partition by event.user_id order by event.timestamp) as next_session_start_at
FROM (
SELECT
e.user_id
, e.timestamp
, DATE_DIFF(
e.timestamp
,LAG(e.timestamp) OVER(
PARTITION BY e.user_id ORDER BY e.timestamp
)
, minute
) AS inactivity_time
FROM raw_event_data AS e
) as event
WHERE (event.inactivity_time > 30 OR event.inactivity_time is null)输出如下:
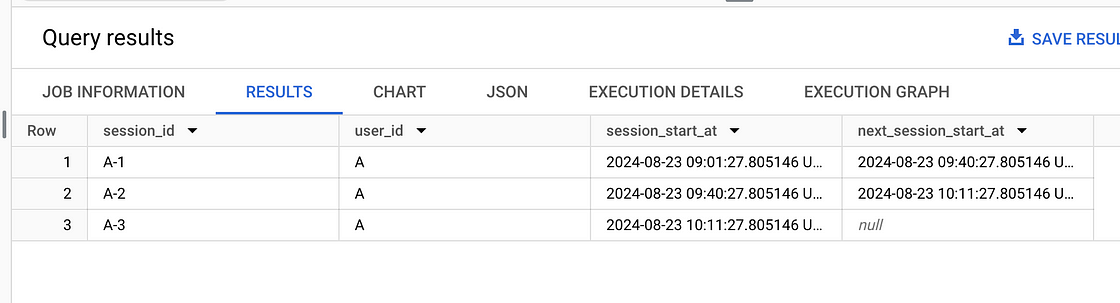
使用 SQL 计算用户会话。图片由作者提供。
当数据科学团队必须处理原始用户参与事件数据时,这是一种广泛使用的方法,可以以正确的方式获取聚合活动。
这种方法的好处是我们不需要依赖数据工程师及其流式传输技术或维护 Kafka 服务器
有了这个数据模型,回答用户分析问题就变得简单了。它可以是一个简单的事件计数,但现在是会话分析。例如,要计算平均会话持续时间,我们可以使用以下 SQL:
SELECT
COUNT(*) AS sessions_count,
AVG(duration) AS average_session_duration
FROM (
SELECT session_id
, DATEDIFF(minutes, MIN(events.timestamp), MAX(events.timestamp)) AS duration
FROM sessions
LEFT JOIN events on events.user_id = sessions.user_id
AND events.timestamp >= events.session_start_at
AND (events.timestamp < sessions.next_session_start_at OR sessions.next_session_start_at is null)
GROUP BY 1
)使用 NTILE()
NTILE() 是一个有用的数字函数,通常用于分析以获取指标的分布,即销售额、收入等。使用 NTILE() 的最常见 SQL 如下所示:
SELECT
NTILE(4) OVER ( ORDER BY amount ) AS sale_group,
product_id,
product_category,
soccer_team,
amount as sales_amount
FROM sales
WHERE sale_date >= '2024-12-01' AND sale_date <= '2024-12-31';amount 它返回按 4 个偶数桶排序的销售额分布。
我发现它对于跟踪移动应用的登录时长(以秒为单位)等指标特别有用。例如,将我的应用连接到 Firebase 后,我可以监控每个用户的登录过程所用的时间。
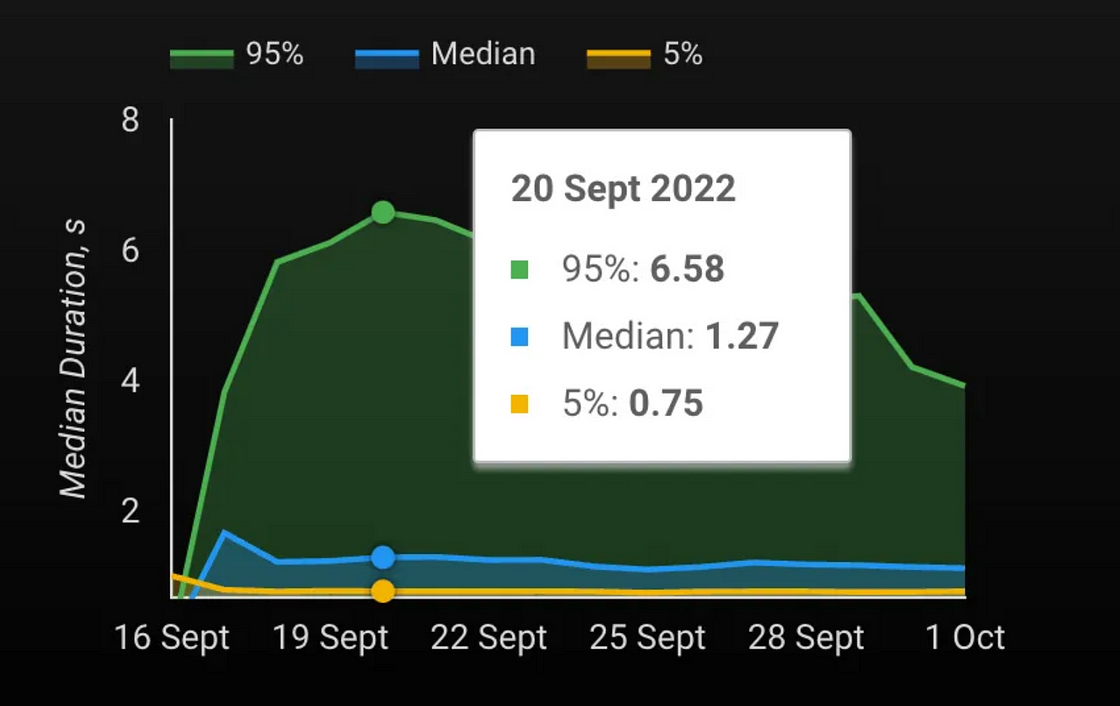
图片来自作者
此函数根据行的顺序将行划分为指定数量的存储桶,并为每行分配一个存储桶编号+1— 一个常量整数表达式。每个存储桶内的行数相差不能超过 1。将总行数除以存储桶数所得的任何余数均会从存储桶 1 开始均匀分布在各个存储桶中。如果指定的存储桶数为 NULL、0 或负数,则会产生错误。下面的 SQL 解释了我如何计算中位登录持续时间:
-- Looker Studio dataset:
select (case when tile = 50 then 'median' when tile = 95 then '95%' else '5%' end) as tile
, dt
, max(cast( round(duration/1000) as numeric)/1000 ) max_duration_s
, min(cast( round(duration/1000) as numeric)/1000 ) min_duration_s
from (
select
trace_info.duration_us duration
, ntile(100) over (partition by (date(event_timestamp)) order by trace_info.duration_us) tile
, date(event_timestamp) dt
from firebase_performance.my_mobile_app
where
date(_partitiontime) >= parse_date('%y%m%d', @ds_start_date) and date(_partitiontime) <= parse_date('%y%m%d', @ds_end_date)
and
date(event_timestamp) >= parse_date('%y%m%d', @ds_start_date)
and
date(event_timestamp) <= parse_date('%y%m%d', @ds_end_date)
and lower(event_type) = "duration_trace"
and lower(event_name) = 'logon'
) x
WHERE tile in (5, 50, 95)
group by dt, tile
order by dt
;中位数和第 k 百分位数是分析数据的宝贵统计数据
使用 FOLLOWING 和 PRECEDING
当我们需要检查特定记录之前或之后的窗口时,我们会使用 FOLLOWING 和 PRECEDING SQL 运算符。
移动平均线
这通常用于计算移动(滚动)平均值。考虑下面的 SQL。它解释了如何执行此操作,这是数据分析中的一项标准任务。
-- mock data
with temperatures as (
select 'A' as city, timestamp_add(current_timestamp(), interval -1 day) as timestamp ,15 as temperature union all
select 'A' as city, timestamp_add(current_timestamp(), interval -3 day) as timestamp ,15 union all
select 'A' as city, timestamp_add(current_timestamp(), interval -5 day) as timestamp ,15 union all
select 'A' as city, timestamp_add(current_timestamp(), interval -36 day) as timestamp ,20 union all
select 'A' as city, timestamp_add(current_timestamp(), interval -75 day) as timestamp ,25
)
SELECT
city,
day,
AVG(temperature) OVER(PARTITION BY city ORDER BY UNIX_DATE(date(timestamp))
RANGE BETWEEN 14 PRECEDING AND CURRENT ROW) AS rolling_avg_14_days,
AVG(temperature) OVER(PARTITION BY city ORDER BY UNIX_DATE(date(timestamp))
RANGE BETWEEN 30 PRECEDING AND CURRENT ROW) AS rolling_avg_30_days
FROM (
SELECT date(timestamp) day, city, temperature, timestamp
FROM temperatures
)我们模拟了一些数据来说明计算,输出如下:
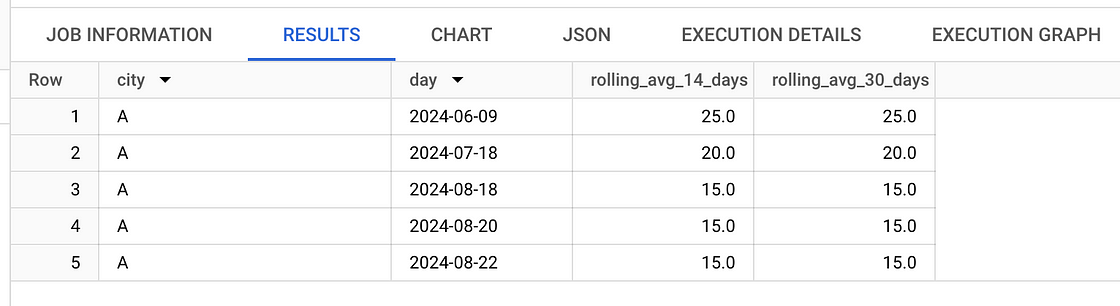
移动平均线。图片由作者提供。
事实上,只要简单看一眼上面的图片就很容易证明它确实有效。
计算移动平均线收敛散度 (MACD)
移动平均线收敛散度 (MACD) 被投资者广泛使用,是一种用于确定买入或卖出的最佳市场切入点的技术指标。
MACD 也可以使用 PRECEDING 来计算
我们需要一条 26 周期的指数移动平均线 (EMA),然后将其从 12 周期的 EMA 中减去。有助于解释 MACD 的信号线是 MACD 线本身的 9 周期 EMA。
下面的 SQL 解释了如何计算它:
-- mock data
with temperatures as (
select 'A' as city, timestamp_add(current_timestamp(), interval -1 day) as timestamp ,15 as temperature union all
select 'A' as city, timestamp_add(current_timestamp(), interval -3 day) as timestamp ,15 union all
select 'A' as city, timestamp_add(current_timestamp(), interval -5 day) as timestamp ,15 union all
select 'A' as city, timestamp_add(current_timestamp(), interval -12 day) as timestamp ,20 union all
select 'A' as city, timestamp_add(current_timestamp(), interval -26 day) as timestamp ,25
)
, data as (
SELECT
city,
day,
temperature,
AVG(temperature) OVER(PARTITION BY city ORDER BY UNIX_DATE(date(timestamp))
RANGE BETWEEN 12 PRECEDING AND CURRENT ROW) AS rolling_avg_12_days,
AVG(temperature) OVER(PARTITION BY city ORDER BY UNIX_DATE(date(timestamp))
RANGE BETWEEN 26 PRECEDING AND CURRENT ROW) AS rolling_avg_26_days
FROM (
SELECT date(timestamp) day, city, temperature, timestamp
FROM temperatures
)
)
select s.day,
s.temperature,
s.rolling_avg_12_days,
s.rolling_avg_26_days,
s.rolling_avg_12_days - l.rolling_avg_26_days as macd
from
data s
join
data l
on
s.day = l.day输出:
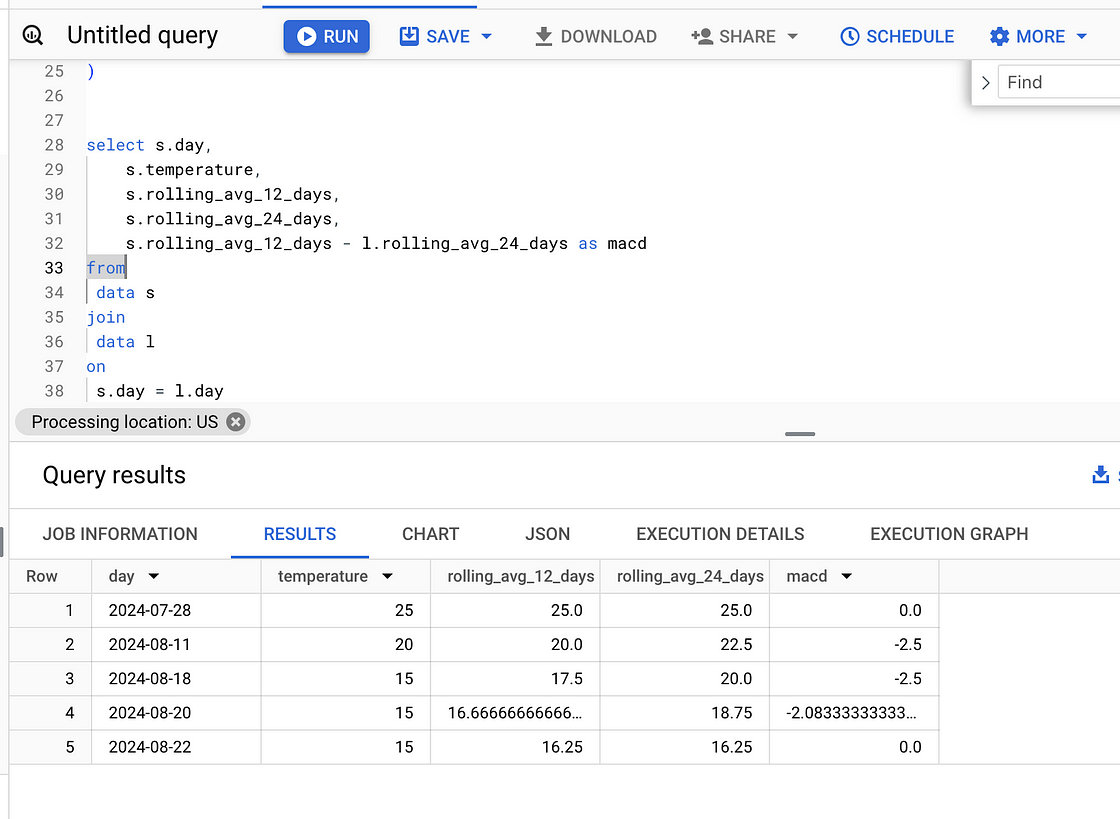
图片来自作者。
百分比变化
此标准指标也可以使用 LEAD 和 LAG 来计算。下面的 SQL 解释了如何执行此操作。
-- mock data
with temperatures as (
select 'A' as city, timestamp_add(current_timestamp(), interval -1 day) as timestamp ,15 as temperature union all
select 'A' as city, timestamp_add(current_timestamp(), interval -3 day) as timestamp ,15 union all
select 'A' as city, timestamp_add(current_timestamp(), interval -5 day) as timestamp ,15 union all
select 'A' as city, timestamp_add(current_timestamp(), interval -12 day) as timestamp ,20 union all
select 'A' as city, timestamp_add(current_timestamp(), interval -26 day) as timestamp ,25
)
SELECT
city,
day,
temperature,
(temperature - lag(temperature) over (order by day))*1.0/lag(temperature) over (order by day)*100
FROM (
SELECT date(timestamp) day, city, temperature, timestamp
FROM temperatures
)输出:
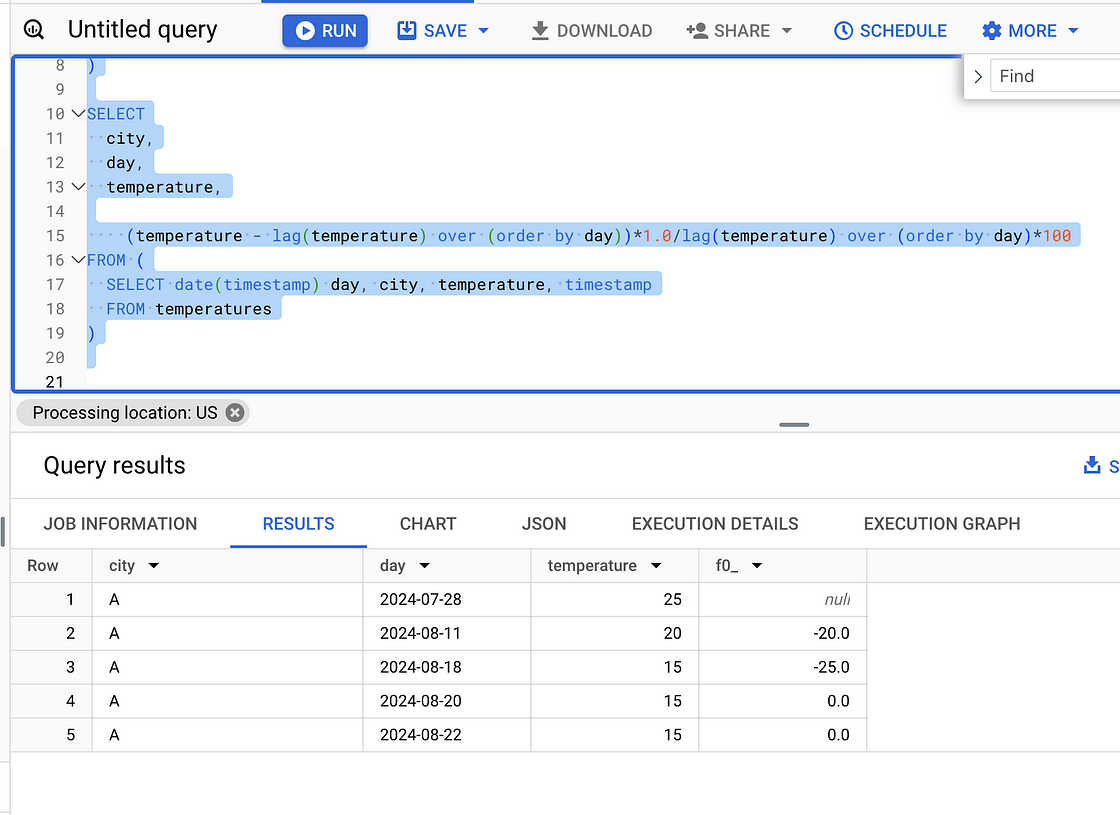
图片来自作者。
使用关注和无限关注进行营销分析
与 PRECEDING 类似,当我们需要编译项目列表(例如事件或购买)以创建漏斗数据集时,此功能特别有用。使用PARTITION BY可以将每个分区内的所有后续事件分组,而不管其数量多少。
这一概念的一个很好的例子就是营销漏斗。
我们的数据集可能包含一系列相同类型的重复事件,但理想情况下,您希望将每个事件链接到不同类型的后续事件。
假设我们需要获取用户join_group在其渠道中发生事件后的所有事件。以下代码解释了如何执行此操作:
-- mock some data
with d as (
select * from unnest([
struct('0003f' as user_pseudo_id, 12322175 as user_id, timestamp_add(current_timestamp(), interval -1 minute) as event_timestamp, 'join_group' as event_name),
('0003',12,timestamp_add(current_timestamp(), interval -1 minute),'set_avatar'),
('0003',12,timestamp_add(current_timestamp(), interval -2 minute),'set_avatar'),
('0003',12,timestamp_add(current_timestamp(), interval -3 minute),'set_avatar'),
('0003',12,timestamp_add(current_timestamp(), interval -4 minute),'join_group'),
('0003',12,timestamp_add(current_timestamp(), interval -5 minute),'create_group'),
('0003',12,timestamp_add(current_timestamp(), interval -6 minute),'create_group'),
('0003',12,timestamp_add(current_timestamp(), interval -7 minute),'in_app_purchase'),
('0003',12,timestamp_add(current_timestamp(), interval -8 minute),'spend_virtual_currency'),
('0003',12,timestamp_add(current_timestamp(), interval -9 minute),'create_group'),
('0003',12,timestamp_add(current_timestamp(), interval -10 minute),'set_avatar')
]
) as t)
, event_data as (
SELECT
user_pseudo_id
, user_id
, event_timestamp
, event_name
, ARRAY_AGG(
STRUCT(
event_name AS event_name
, event_timestamp AS event_timestamp
)
)
OVER(PARTITION BY user_pseudo_id ORDER BY event_timestamp ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING ) as next_events
FROM d
WHERE
DATE(event_timestamp) = current_date()
)
-- Get events after each `join_group` event per user
select
*
from event_data t
where event_name = 'join_group'
;探索性数据分析
在进行 ML、AI、数据科学或工程任务之前,使用 SQL 直接对表中的数据进行分析通常更有效。事实上,您现在甚至可以使用 SQL 构建机器学习模型 - BigQuery ML 就是此功能的一个典型示例。趋势很明显:一切都在越来越多地转向数据仓库。
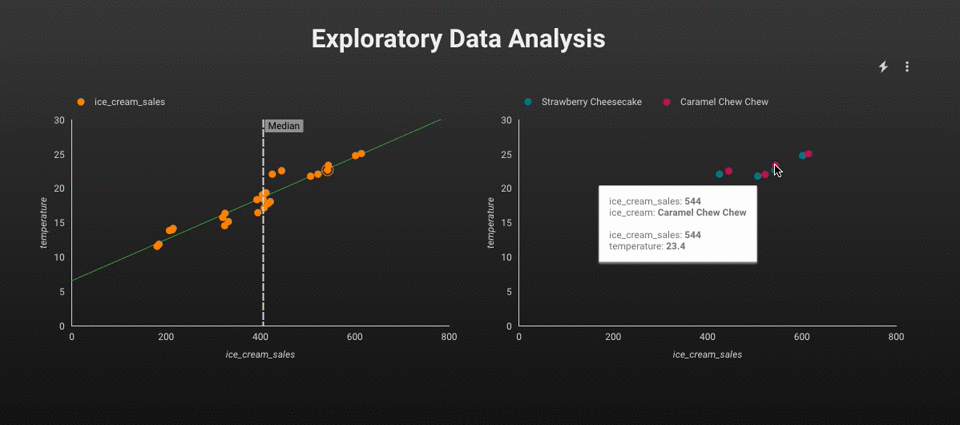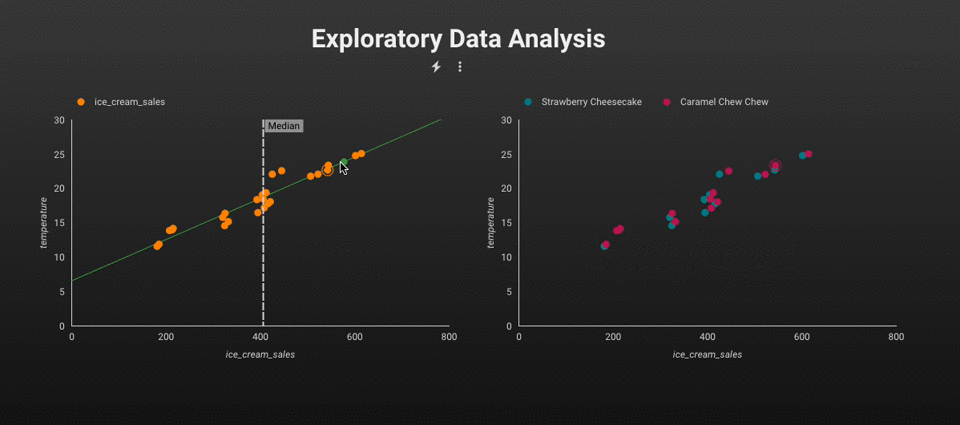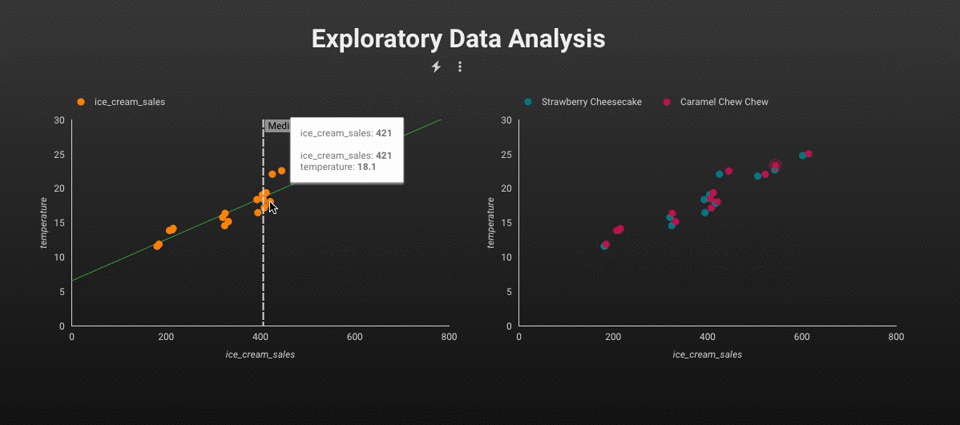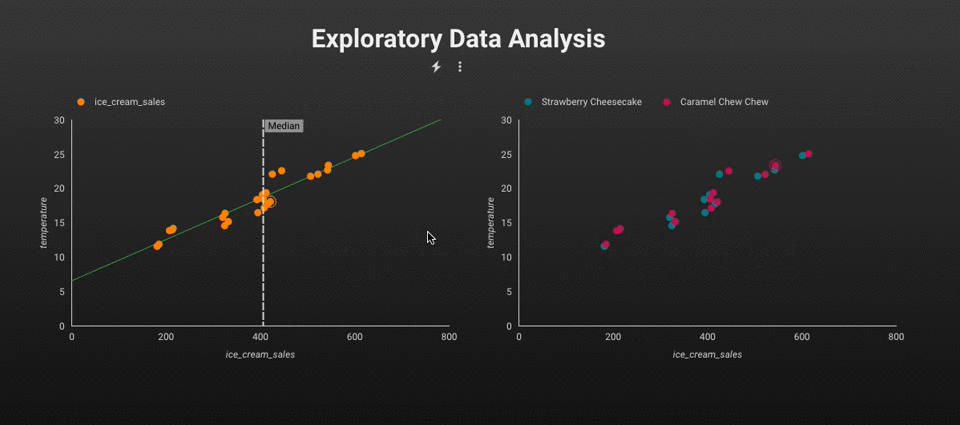
EDA。图片由作者提供。
使用 Pandas 可以轻松获取唯一列值,但是我们可以在 SQL 中做到这一点吗?
下面的 SQL 代码片段提供了一个方便的脚本来实现这一点。在BigQuery中运行此代码(将“your-client”替换为您的项目名称):
DECLARE columns ARRAY<STRING>;
DECLARE query STRING;
SET columns = (
WITH all_columns AS (
SELECT column_name
FROM `your-client.staging.INFORMATION_SCHEMA.COLUMNS`
WHERE table_name = 'churn'
)
SELECT ARRAY_AGG((column_name) ) AS columns
FROM all_columns
);
SET query = (select STRING_AGG('(select count(distinct '||x||') from `your-client.staging.churn`) '||x ) AS string_agg from unnest(columns) x );
EXECUTE IMMEDIATE
"SELECT "|| query
;输出:
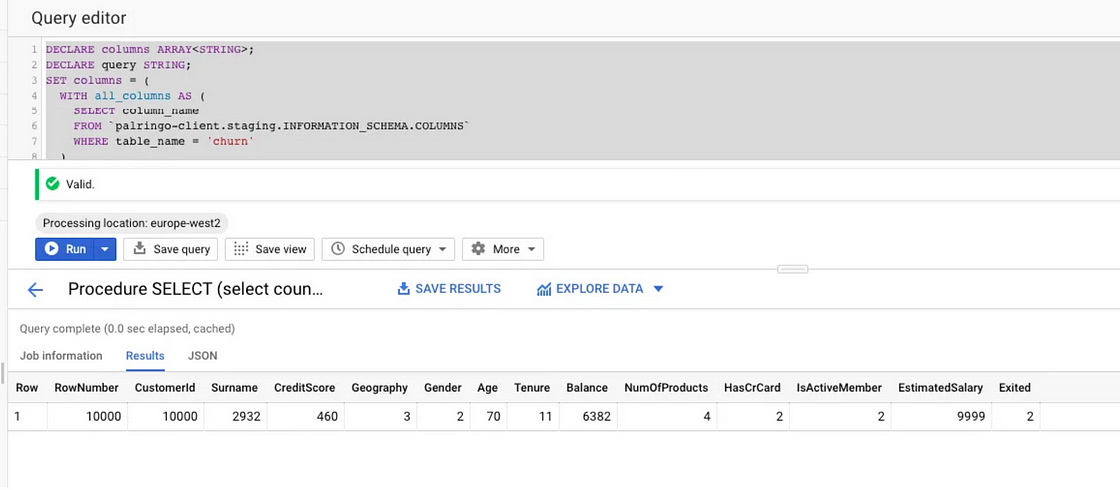
EDA。图片由作者提供。
描述数据集
我们可以使用 SQL 脚本来描述数据仓库中的表。我将稍微更改上面提到的 SQL,并添加平均值、最大值、最小值、中位数、0.75 瓦片、0.25 瓦片,因此最终的SQL将如下所示:
DECLARE columns ARRAY<STRING>;
DECLARE query1, query2, query3, query4, query5, query6, query7 STRING;
SET columns = (
WITH all_columns AS (
SELECT column_name
FROM `your-client.staging.INFORMATION_SCHEMA.COLUMNS`
WHERE table_name = 'churn'
and data_type IN ('INT64','FLOAT64')
)
SELECT ARRAY_AGG((column_name) ) AS columns
FROM all_columns
);
SET query1 = (select STRING_AGG('(select stddev( '||x||') from `your-client.staging.churn`) '||x ) AS string_agg from unnest(columns) x );
SET query2 = (select STRING_AGG('(select avg( '||x||') from `your-client.staging.churn`) '||x ) AS string_agg from unnest(columns) x );
SET query3 = (select STRING_AGG('(select PERCENTILE_CONT( '||x||', 0.5) over() from `your-client.staging.churn` limit 1) '||x ) AS string_agg from unnest(columns) x );
SET query4 = (select STRING_AGG('(select PERCENTILE_CONT( '||x||', 0.25) over() from `your-client.staging.churn` limit 1) '||x ) AS string_agg from unnest(columns) x );
SET query5 = (select STRING_AGG('(select PERCENTILE_CONT( '||x||', 0.75) over() from `your-client.staging.churn` limit 1) '||x ) AS string_agg from unnest(columns) x );
SET query6 = (select STRING_AGG('(select max( '||x||') from `your-client.staging.churn`) '||x ) AS string_agg from unnest(columns) x );
SET query7 = (select STRING_AGG('(select min( '||x||') from `your-client.staging.churn`) '||x ) AS string_agg from unnest(columns) x );
EXECUTE IMMEDIATE (
"SELECT 'stddev' ,"|| query1 || " UNION ALL " ||
"SELECT 'mean' ,"|| query2 || " UNION ALL " ||
"SELECT 'median' ,"|| query3 || " UNION ALL " ||
"SELECT '0.25' ,"|| query4 || " UNION ALL " ||
"SELECT '0.75' ,"|| query5 || " UNION ALL " ||
"SELECT 'max' ,"|| query6 || " UNION ALL " ||
"SELECT 'min' ,"|| query7
)
;它生成所有标准 EDA 指标:
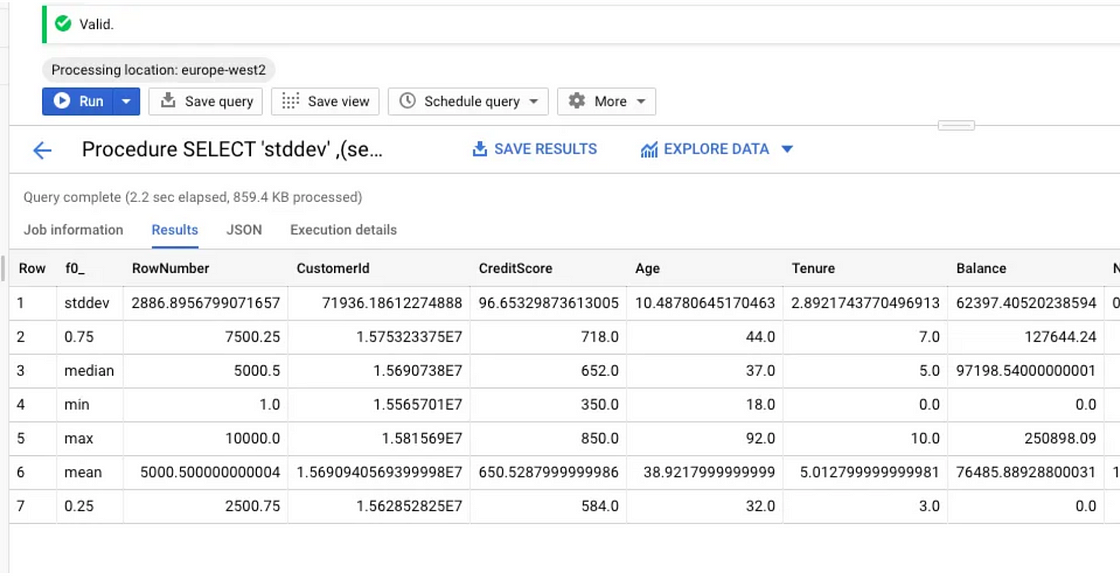
SQL 中的 Describe()。图片由作者提供。
可以使用 SQL 轻松执行 EDA
例如,我们可以应用 SQL 来分析两个变量(即CreditScore和Balance)之间的相关性。基于 SQL 的解决方案的优点在于,我们可以使用现代 BI 工具轻松地将结果可视化并在所有变量之间创建散点图。
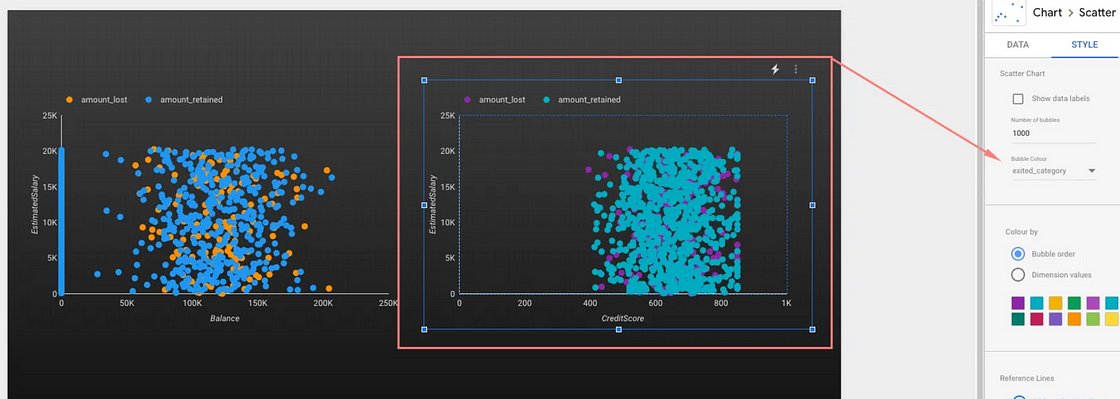
变量分布。图片由作者提供。
例如,在我之前的一篇文章中,我比较了 SQL 和 Pandas 中的 EDA,以计算标准差和相关矩阵等指标[3]。
结论
时间序列分析是数据科学的重要组成部分。在本文中,我介绍了数据科学用例中最流行的 SQL。我经常使用这些查询,希望这对您的数据科学项目有用。
使用 SQL 脚本,我们可以自动执行查询、执行探索性数据分析,并直接在任何商业智能工具中可视化结果。现代数据仓库具有内置的机器学习工具,即 BigQuery ML 等,它也简化了 ML 建模。
虽然 Python 仍然是数据科学家的强大工具,提供强大的脚本功能,但 SQL 也可以有效地处理 EDA 任务。对于可视化结果,类似 SQL 的设置提供了卓越的仪表板体验。配置仪表板后,无需重新运行查询或笔记本,使其成为简化流程的一次性设置。在此环境设置中添加现代数据建模工具将使一切达到更高的自动化水平,并具有强大的数据质量检查和单元测试。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









