







到目前为止,它是数据科学的最佳框架。您可以将其用于您的团队或仅供您自己使用。以下是我使用它的方式。
添加图片注释,不超过 140 字(可选)
虽然软件工程实践要求问题的产生是为了适应不断变化的客户需求,但我们需要能够适应我们自己研究所决定的不断变化的需求的实践。欢迎来到雲闪世界。
内容
-
您可能已经尝试过 Agile……
-
为什么敏捷不适用于数据科学……
-
数据科学生命周期流程 (DSLP)
-
DSLP 的五个步骤
-
示例项目:检测信用卡欺诈
-
新项目 — 创建提问问题
-
探索数据 — 数据问题
-
这种布局导致了传统的敏捷项目
-
对数据科学有意义的看板
-
结论
您可能已经尝试过 Agile……
让我们面对现实,我们都曾尝试过使用敏捷方法来管理我们的数据科学项目。
而且我敢肯定,你和你的团队已经看到它慢慢地崩溃了——每个人都在说他们在以前的站立会议上说过同样的话,项目看板从未得到维护,冲刺变得毫无意义。
最后你会觉得整件事都毫无意义,但又说不出为什么它没有起到作用。
因此,您不知道如何改进它或改变什么。
为什么敏捷不适用于数据科学……

添加图片注释,不超过 140 字(可选)
敏捷框架是为软件工程而构建的,在软件工程结束时需要交付产品。
基于这一最终目标,敏捷框架试图让项目与可能随时间变化的最终用户需求保持一致。它旨在保持开发人员和最终用户之间的反馈循环紧密,以便项目能够保持对变化的“敏捷性”。
同时,开发人员彼此之间保持高度沟通,以便快速识别不断变化的需求、识别阻碍因素并传递知识。
这就是为什么你要进行冲刺和站立会议(或 scrum),同时利用看板来跟踪你的工作。
然而,对于数据科学项目来说,这个框架很快就会崩溃。
为什么?
因为数据科学从根本上来说是一个研发项目,所以一开始并没有想要构建的最终产品的概念。需要进行研究来确定最终产品可能是什么样子。
只有在研发完成后,你才知道你需要什么数据,需要进行哪些预处理/特征工程,以及你将要使用什么模型,你最终才知道你要构建什么。
这意味着敏捷框架仅当您尝试将模型投入生产时才适用,对于数据科学项目而言,这是项目的最后一步。
那么还有什么其他选择呢?
添加图片注释,不超过 140 字(可选)
数据科学生命周期流程 (DSLP)
在研究数据科学项目管理领域之后,我遇到了数据科学生命周期流程,它似乎将其他资源提供的所有关键见解都融入到一个框架中,可以直接合并到 Github 项目或任何其他基于看板的项目管理工具中。
我已经将它用于我自己的数据科学团队的项目管理,事实证明这是迄今为止对我们工作流程的最佳改进。 我们看到了什么好处?举几个例子,
-
在整个项目生命周期中改进项目文档,其中每个设计选择和研究都记录在一个地方,
-
这有助于知识的无缝转移,并完全消除交接过程中的摩擦,
-
并改善了数据科学家之间的研究合作。
-
更好地确定项目的优先次序,减少在定义不明确的项目上浪费的时间,
-
鼓励基于任务的工作流程,该工作流程可以无缝融入现有的看板工作流程,只需进行最少的更改,
-
这最终促进了 Agile 所追求的迭代方法,但适用于数据科学,而不是软件工程。
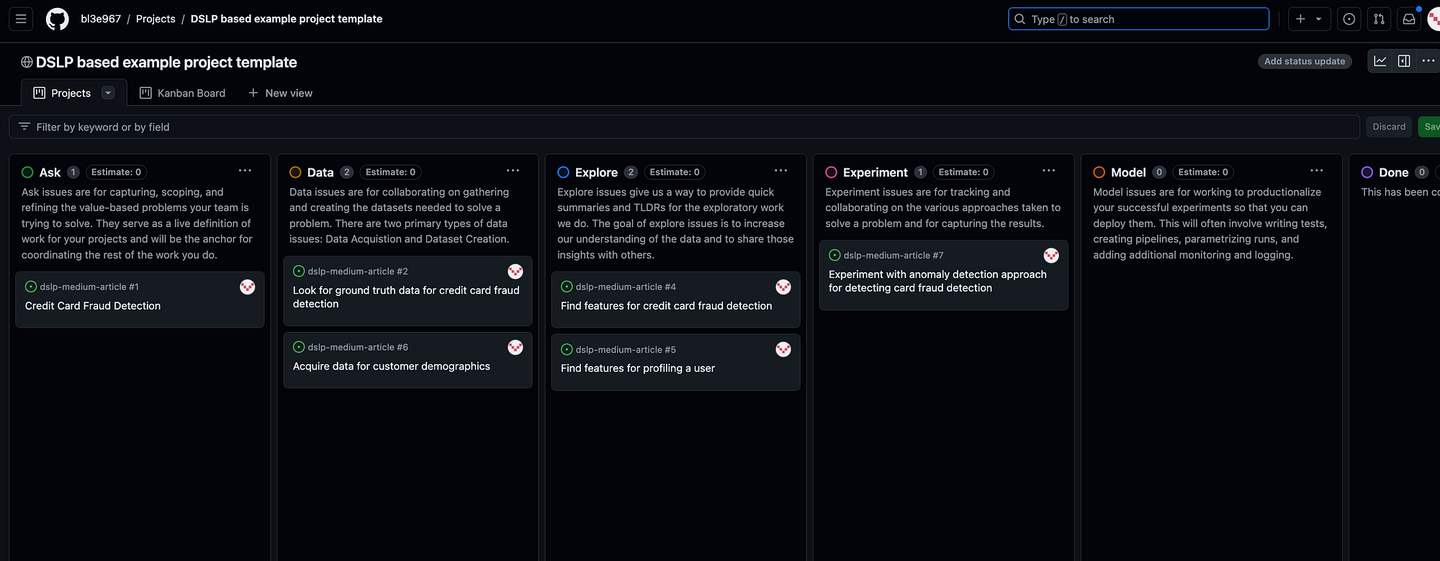
以上并非详尽的清单,只是我能想到的直接要点。听起来好得令人难以置信,但请继续阅读下文,看看如何实现上述所有目标(以及更多目标)。 DSLP 的 5 个步骤 我们将使用我的模板 Github 项目作为示例来说明如何使用 DSLP。
添加图片注释,不超过 140 字(可选)
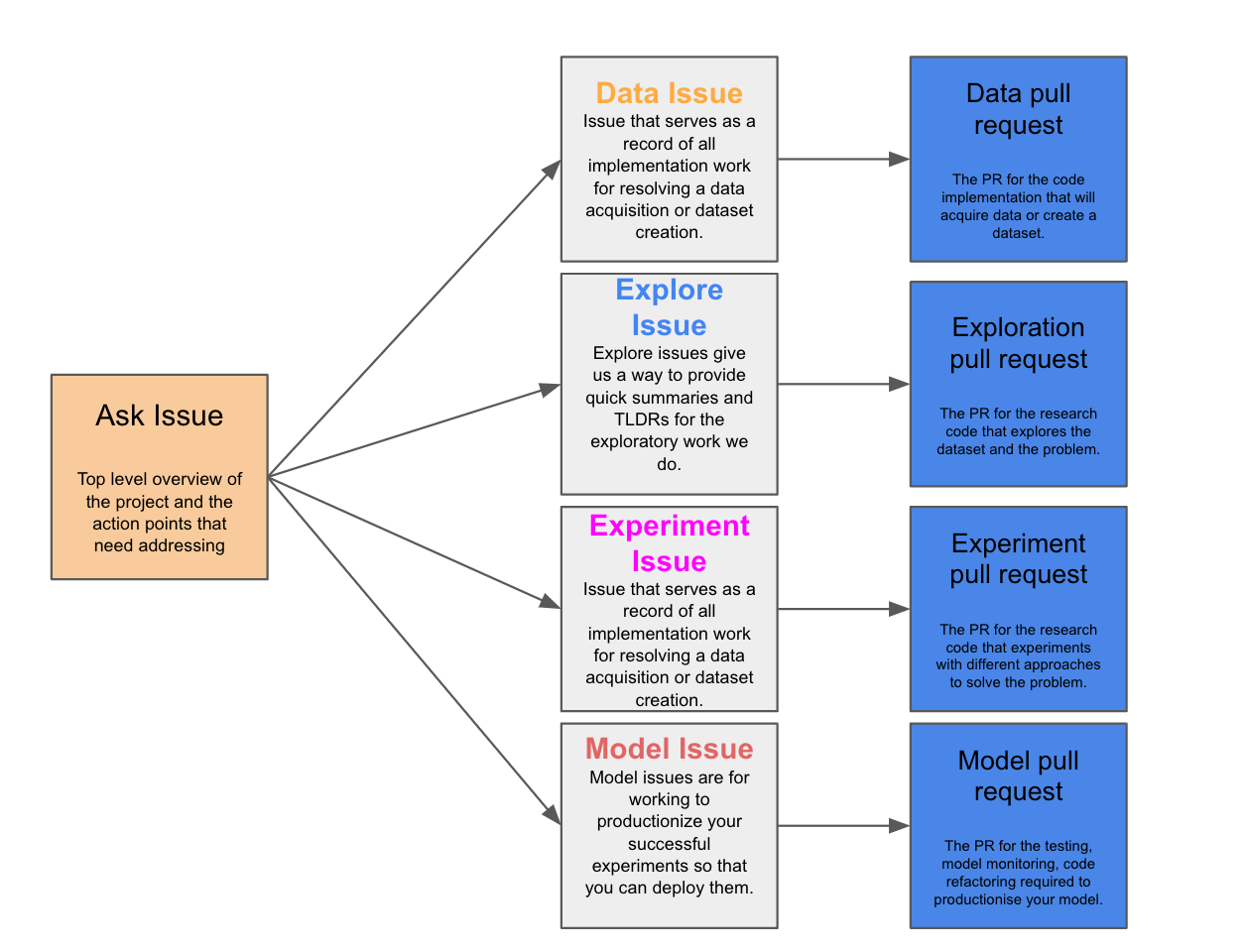
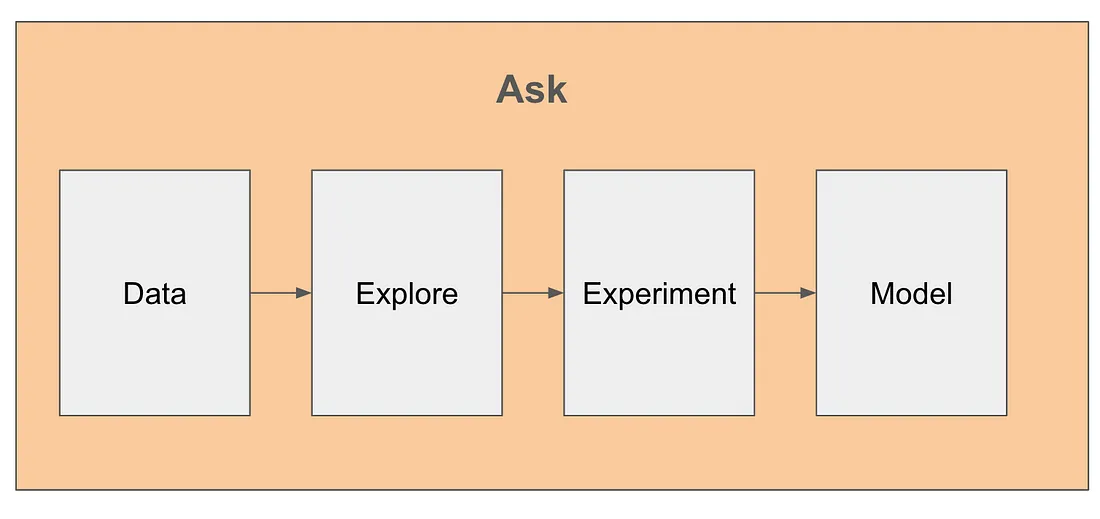
从现在起我所参考的任何相关代码或内容都将在此项目模板中提供。 本文使用的所有图像均由作者生成。 DSLP 包含五个项目生命周期步骤,包括询问、数据、探索、实验和模型。在每个步骤中,您都需要在Github 项目中为您的数据科学团队提出一个GitHub 问题。
添加图片注释,不超过 140 字(可选)
以下是 DSLP 提供的关于每个步骤及其相应问题所涉及的内容的高级摘要。除了我在团队中使用的Github 问题模板和基于 Github 的工作流程之外,我们还将在下一节中通过一个实际示例深入探讨它们的实际工作方式。 问 提出问题是为了捕捉、确定范围和细化您的团队正在尝试解决的基于价值的问题。它们是您项目工作的实时定义,并将成为协调您其余工作的基础。它提供了已完成的所有工作和正在进行的工作的摘要。 这个问题成为您自己或任何需要有关该项目信息的人的第一个关注点,并且在其他步骤中创建的任何问题都应与此问题相关联(我们将在后面的示例中看到这有多么容易)。 数据 数据问题是为了协作收集和创建解决问题所需的数据集。 此问题与获取您的数据和创建您的输入数据集相关。 探索 探索问题让我们能够为我们所做的探索性工作提供快速摘要和 TLDR。探索问题的目标是加深我们对数据的理解并与他人分享这些见解。 这种问题类型类似于您在数据科学项目开始时进行的探索性数据分析,并且有助于记录所探索的内容并与其他数据科学家进行合作。 实验 实验问题用于跟踪和协作解决问题所采取的各种方法并获取结果。 一旦你理解了你的数据以及它与你的问题的关系,实验问题就会用于你要进行的建模。P 也许您将问题定义为异常检测模型?也许您考虑不同类型的模型?或者也许您尝试不同的超参数? 根据您的工作方式,每个问题都可以是单独的实验问题,也可以是一个大问题的一部分。 模型 模型问题用于将成功的实验投入生产,以便您可以部署它们。这通常涉及编写测试、创建管道、参数化运行以及添加额外的监控和日志记录。 正如 DSLP 所解释的那样,一旦您的实验阶段完成并且您知道想要投入生产什么,那么为将模型投入生产而进行的任何工作都应该成为模型问题的一部分。 有关每个步骤的更多详细信息可以在 DSLP 存储库中找到。 但是现在,让我们通过一个虚构的例子来深入了解我如何使用 GitHub 项目让我的数据科学团队真正地使用 DSLP 工作。 示例项目:检测信用卡欺诈 假设您是一家银行的数据科学家,信用卡欺诈运营团队的 SME(主题专家) John Doe 与您联系。 他们告诉您,信用卡欺诈已成为银行的业务重点,银行必须改进检测此类案件的流程。这是基于监管机构的反馈,该反馈指出,与其他银行相比,该银行在信用卡欺诈检测方面表现不佳。

添加图片注释,不超过 140 字(可选)
他们向您征求意见,鉴于该银行先前将模型应用于其他领域所取得的成功,数据科学团队是否可以使用模型来提高银行的欺诈检测率。 显然,你一开始并不知道是否可以建立一个模型——你不知道有哪些数据可用,也不知道标签的质量是否足够好(或者它们是否存在)。 但您知道您的团队有能力启动一个新项目并对此进行研究。因此,您安排与 SME 和信用卡欺诈预防团队中的其他人员进行跟进电话会议,以了解他们面临的问题并了解该项目将涉及哪些内容。 新项目 — 创建提问问题 你回到办公桌前,脑子里想着新项目。你应该做的第一件事是使用 Ask 问题模板(可在此处找到)创建一个新的 Ask 问题。有关此模板中每个部分的更多信息,可在 markdown 模板中的注释中找到。
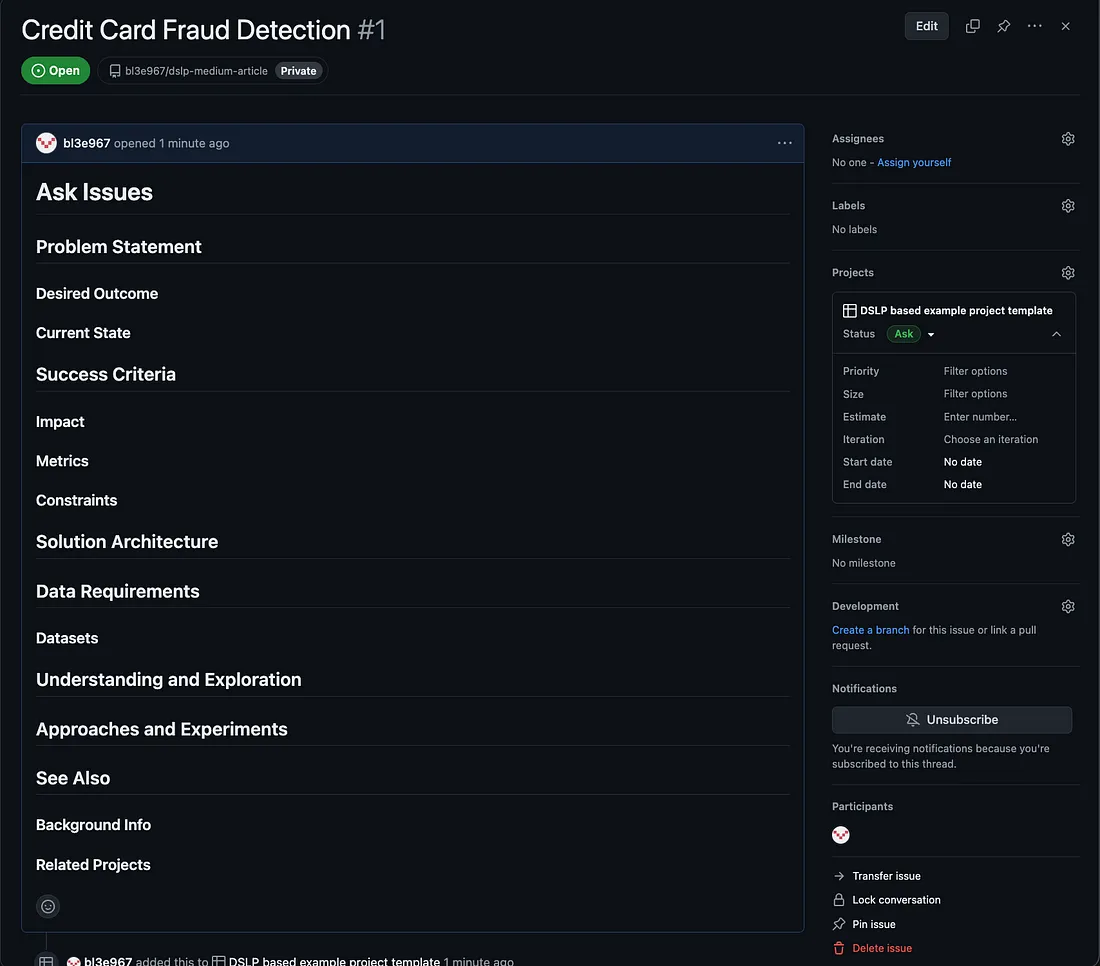
添加图片注释,不超过 140 字(可选)
提出问题是为了捕捉、确定范围和改进您的团队正在尝试解决的基于价值的问题。它们是您项目工作的实时定义,并将成为协调您其余工作的基础。 通过将工作定义纳入问题中,数据科学团队可以与其业务伙伴和领域专家合作,在对问题了解更多的同时完善和重新确定问题的范围。 您应该在 Ask 问题中链接到其他问题。这将让人们了解处理特定问题的原因。 随着您对问题的理解不断加深,您应该相应地更新您的提问问题。为了使问题更加清晰,您应该尽可能具体,并通过更新提问来解决歧义。 因此,我们正处于项目的开始阶段,目前我们掌握的信息很少甚至没有。但是,我们可以尽我们所知更新问题陈述。 问题陈述是对您要解决的问题及其原因的高级描述。它应该明确说明解决此问题将产生什么价值,还应明确说明问题中包含和不包含的内容。 我们将问题陈述更新如下: “业务重点发生了转变,预防信用卡欺诈已成为首要任务。 在与 John Doe 谈论这个问题后,我们需要比传统控制措施效果更好的控制措施。” 目前,根据我们之前简短的交谈,我们没有遇到任何具体问题,因此暂时保持现状不变。但为了使这个项目可行,我们需要跟进 John 和其他中小企业,更好地了解需求是什么,以及在他们眼中成功的结果是什么样子。 因此,您可以在 Ask 问题的评论部分写下推动该项目进展所需采取的后续步骤。
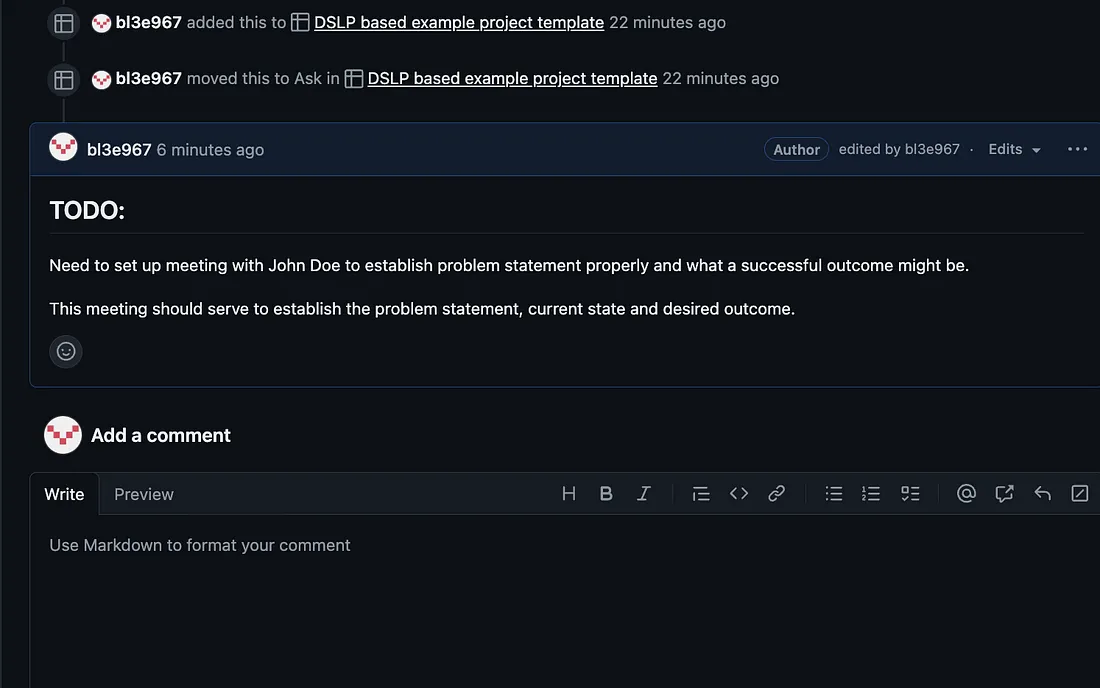
添加图片注释,不超过 140 字(可选)
评论部分的全部目的是记录您的项目的所有行动要点和设计选择。 它可以作为审计日志,您和其他人可以参考它来获取项目每一步的详细信息,而顶部的模板化提问问题可以作为项目重要点的高级摘要,成为与您的项目相关的任何疑问或问题的第一个停靠港。 因此,一旦您安排好会议,与 John 及其同事讨论了这一行动要点,那么您就可以更新评论或在会议记录中添加新评论。
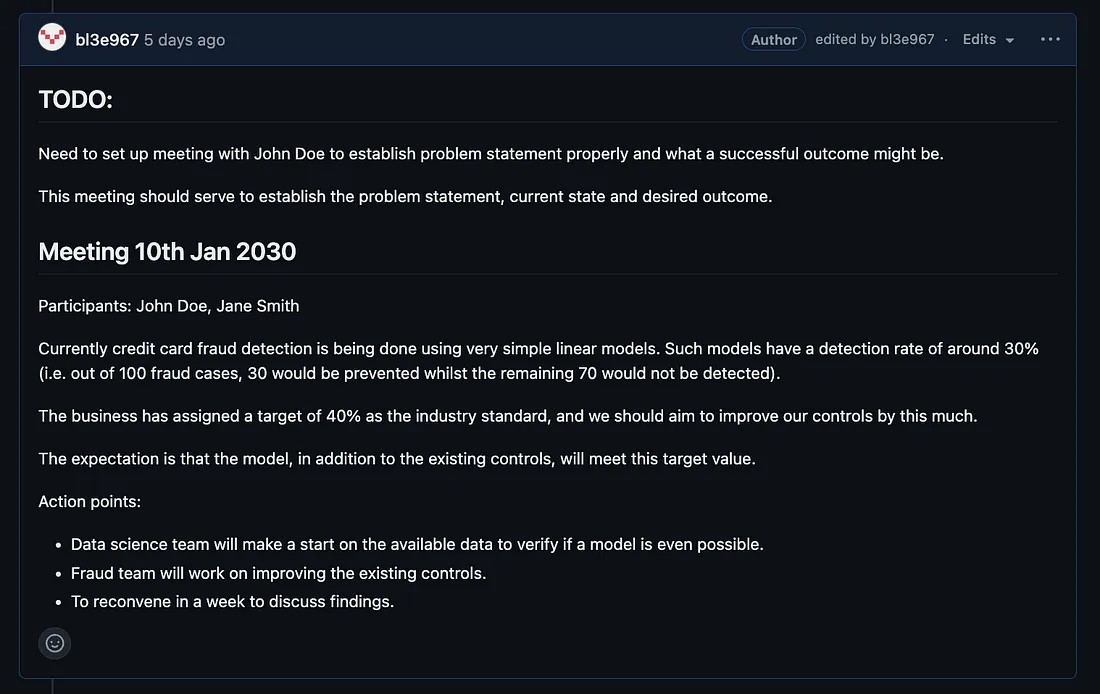
该评论现已包含会议结果
这次会议为我们提供了足够的信息来填写剩余的子部分(期望结果、当前状态、成功标准)。
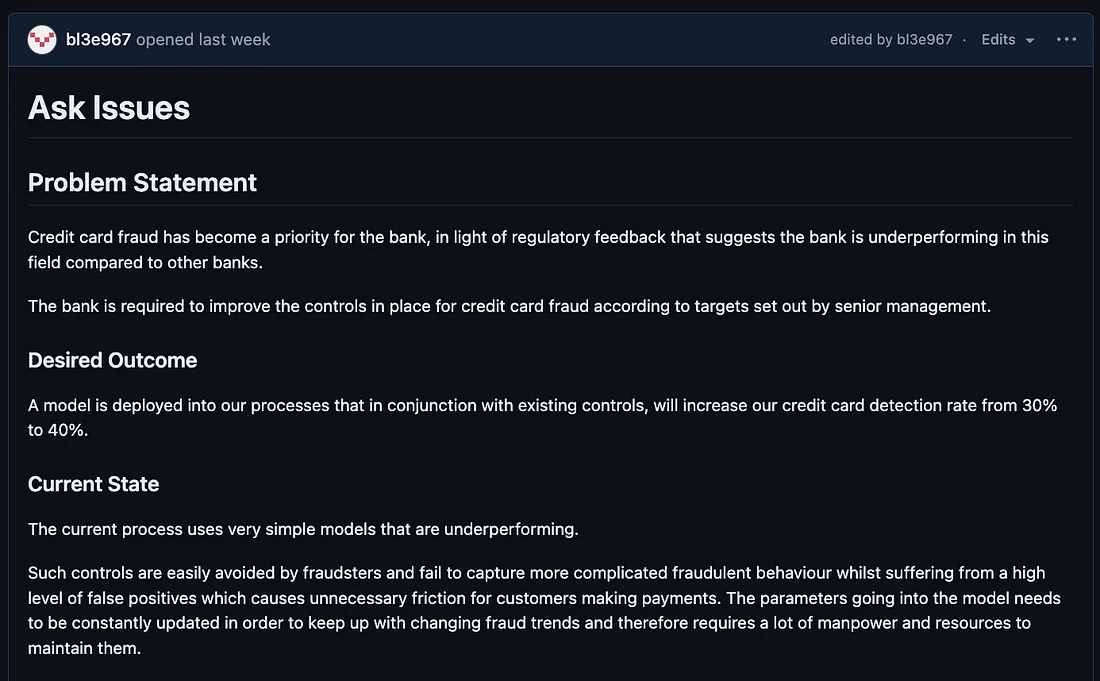
这是如何填充“期望结果”和“当前状态”字段的示例。有关此部分用途的更多详细信息,

这是如何填写“成功标准”字段的示例。有关此部分用途的更多详细信息,
请记住,随着项目的进展以及您能做什么/不能做什么变得越来越清晰,上述部分和模板中的任何其他部分都应该进行更改,以反映对项目最新的理解。 探索数据 — 数据问题 因此,在与 John 等人会面后,我们有一个行动要点: 数据科学团队将开始利用现有数据来验证模型是否可行。 第一步是搜索任何可作为信用卡欺诈检测任务标签的真实数据。 从评论部分的日志中,我们根据这个行动点创建了一个问题:
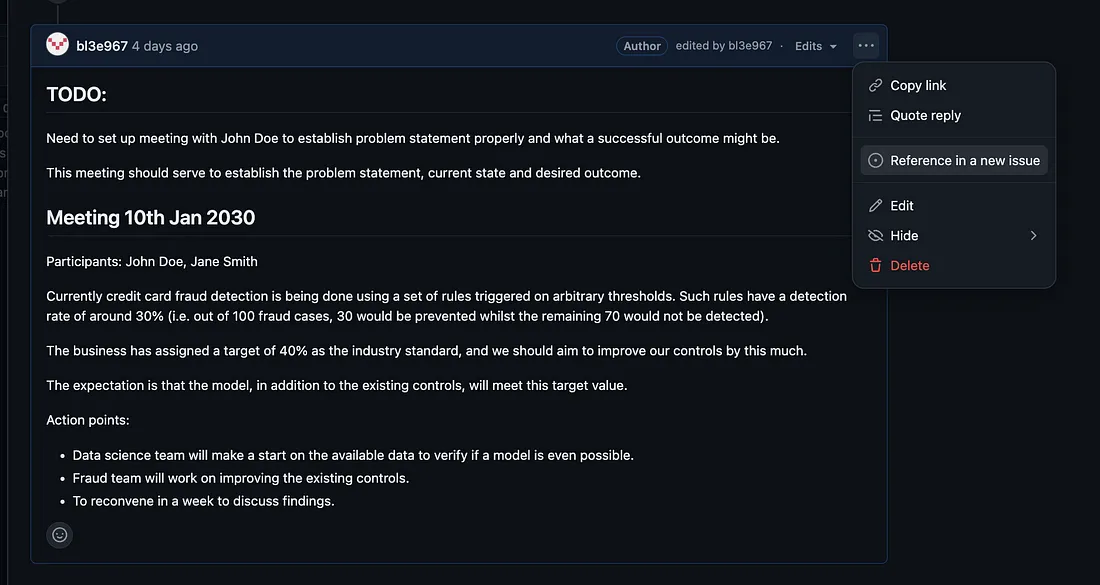
添加图片注释,不超过 140 字(可选)
然后填写新问题的详细信息,如下所示:
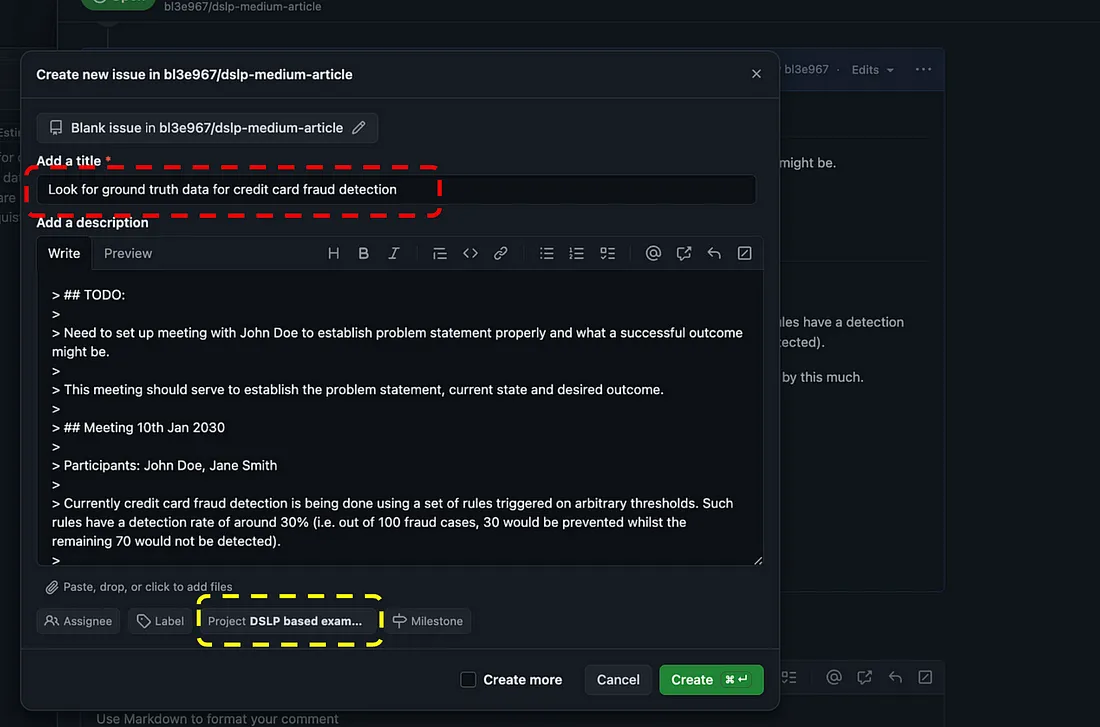
添加图片注释,不超过 140 字(可选)
现在这个问题将出现在你的项目板上。将其拖放到Data列中,你的板应如下所示:
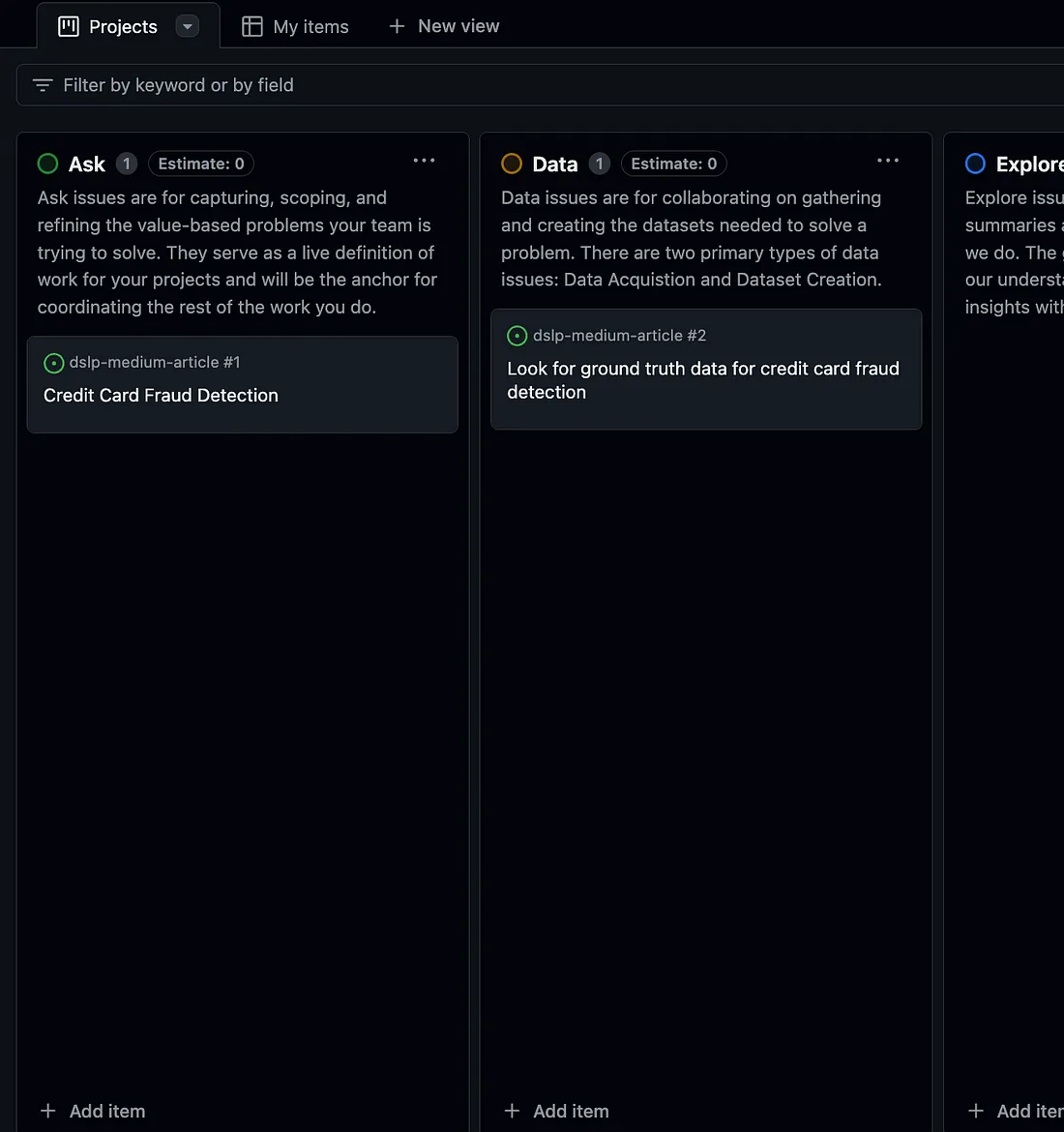
添加图片注释,不超过 140 字(可选)
因此,Data您创建的这个问题将记录与获取地面真实数据相关的所有内容,以及您做出的任何设计选择和数据的任何限制。 您编写的任何用于获取数据的代码都应通过此问题来创建,方法是直接从该问题创建一个分支:
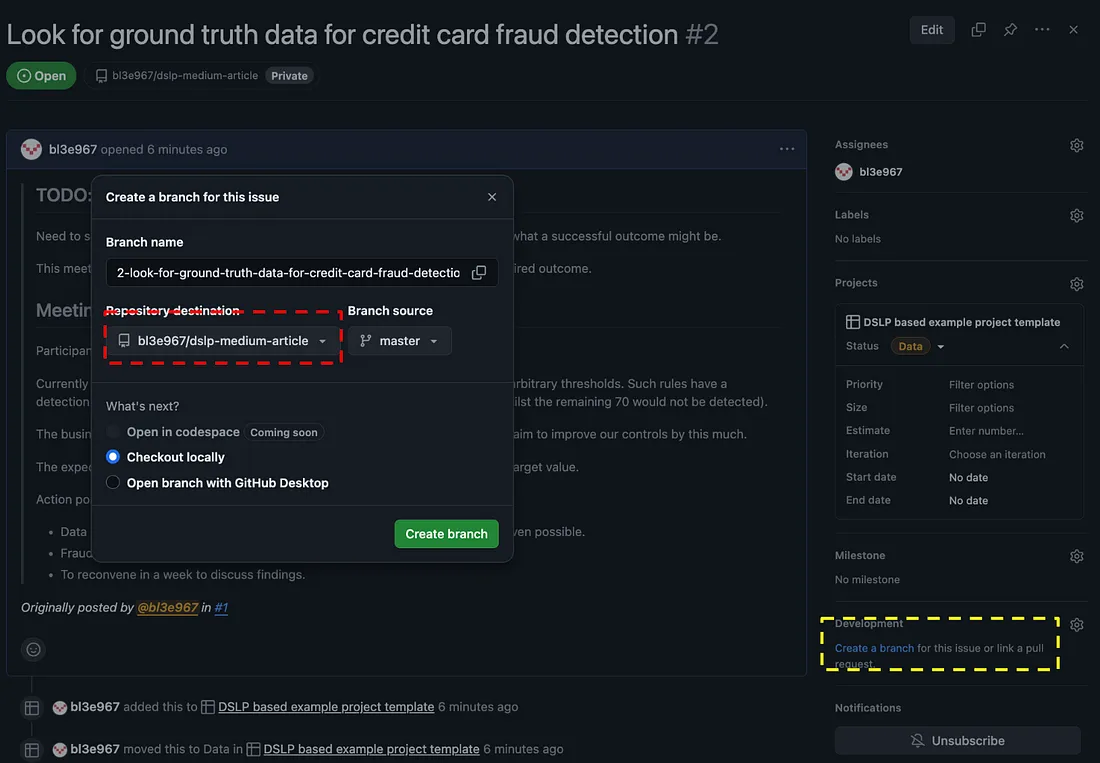
创建与此问题相关的分支(黄色),并选择该分支所属的 repo(红色)
最棒的是,您创建的分支可以与任何启用了问题的存储库相关联。如果您为数据科学堆栈的不同部分设置了单独的存储库,这将非常有用,因为您可以将与项目相关的所有内容都保存在一个面板中。
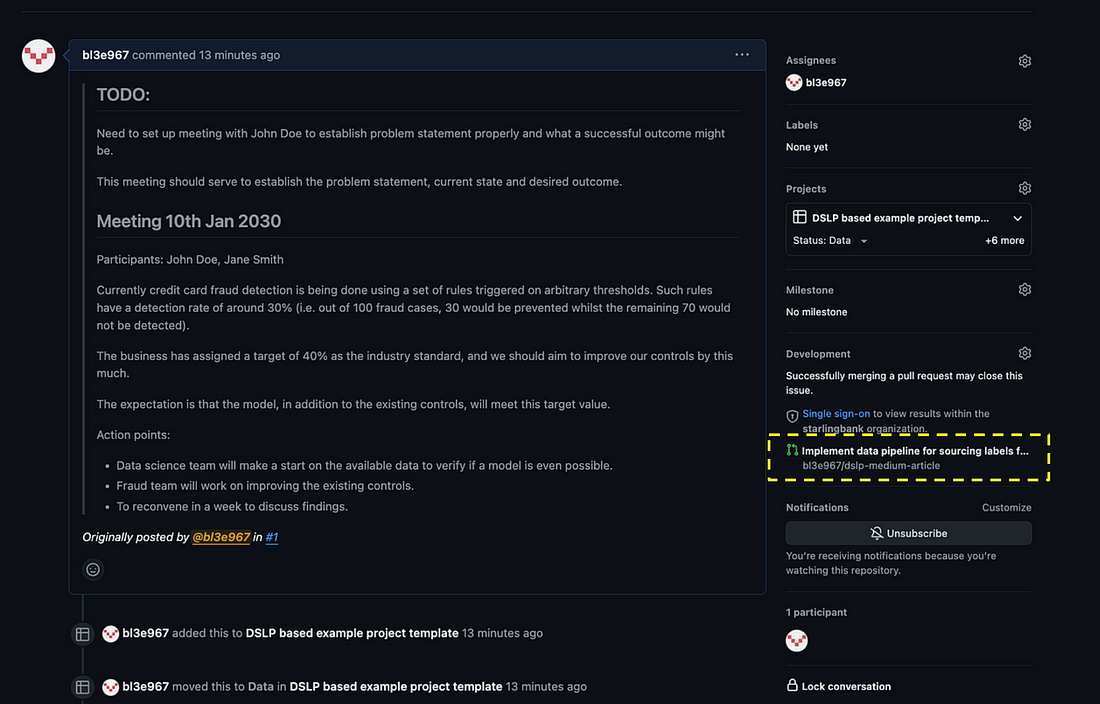
任何与此数据问题相关的 PR 都已链接。
最后,一旦您完成编码并为其提出 PR,它就会自动链接到您的Data问题。 目前我们拥有的……
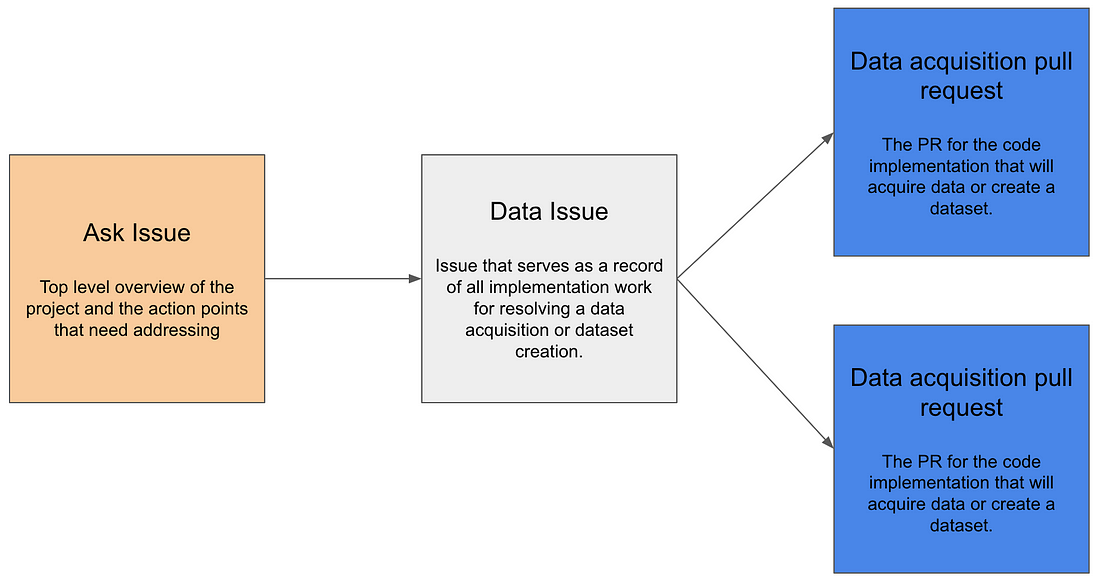
以问题和 PR 的形式概述了与 Ask 相关的所有开发是如何联系在一起的
通过这种方式,我们取得了两方面的成果:
-
所有设计选择和实施细节都链接到相关的 Ask 问题中,因此可以通过一个地方找到与项目相关的所有内容。
-
不存在信息丢失的余地,同时信息以分层格式进行总结——询问问题中的高级详细信息、数据问题中的低级详细信息、拉取请求中的实现细节,这使得协作或交接变得更加容易。
通过这种方式,我们可以继续构建我们的项目:
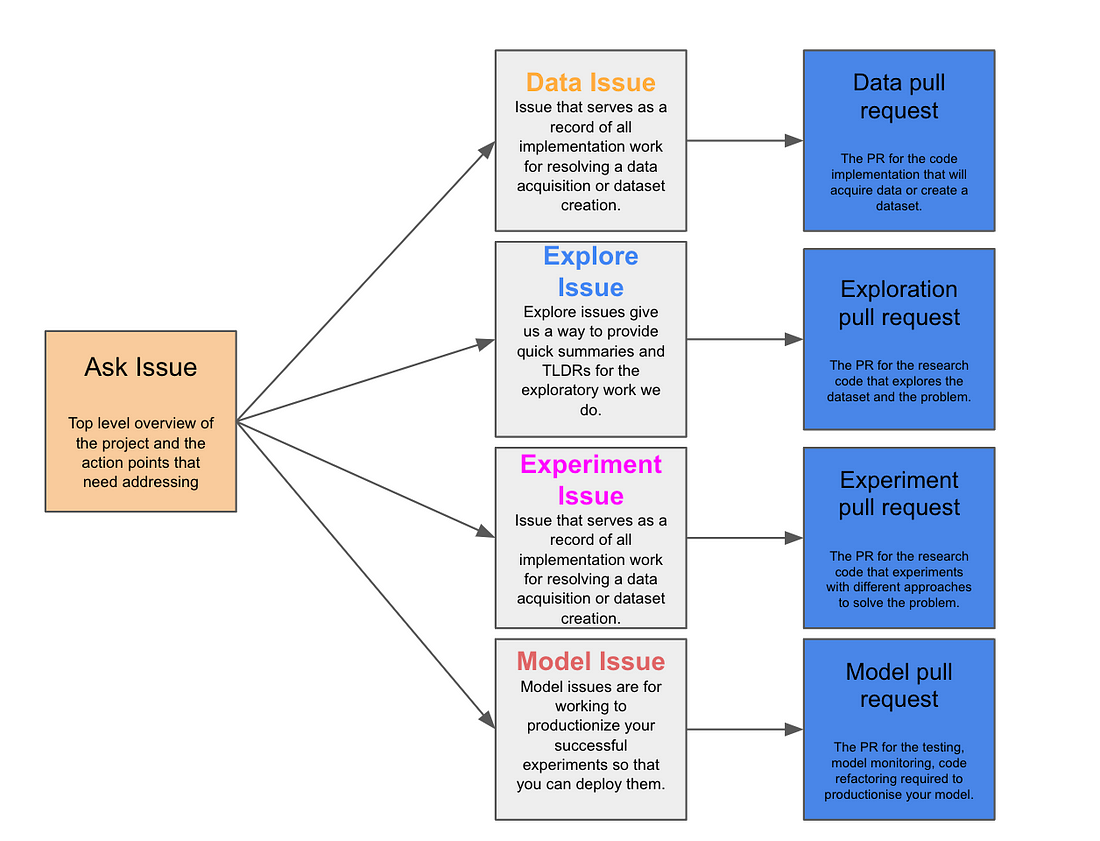
相同的询问问题,链接到后续的 DSLP 问题,如探索、实验、模型…
我们已经介绍了数据和探索问题,它们相当于数据科学的数据采集和 EDA 部分。 实验是实际的建模,并将涉及您创建的 Jupyter Notebook 来尝试不同的方法和不同的模型。 模型是与生产相关的所有事项的最后一步——单元测试、代码重构、模型监控等。 它们的工作原理与我们上面介绍的相同。有关这些步骤的更多详细信息,请查看 DSLP 页面或示例项目板。但现在,我们将跳到下一部分。 这种布局导致了传统的敏捷项目 那么,让我们向前跳转,大概到我们的示例项目的未来两周。 到目前为止,您已经完成了获取所需数据的必要工作,并对数据和潜在特征进行了一些探索,此外还尝试构建了第一个迭代模型。
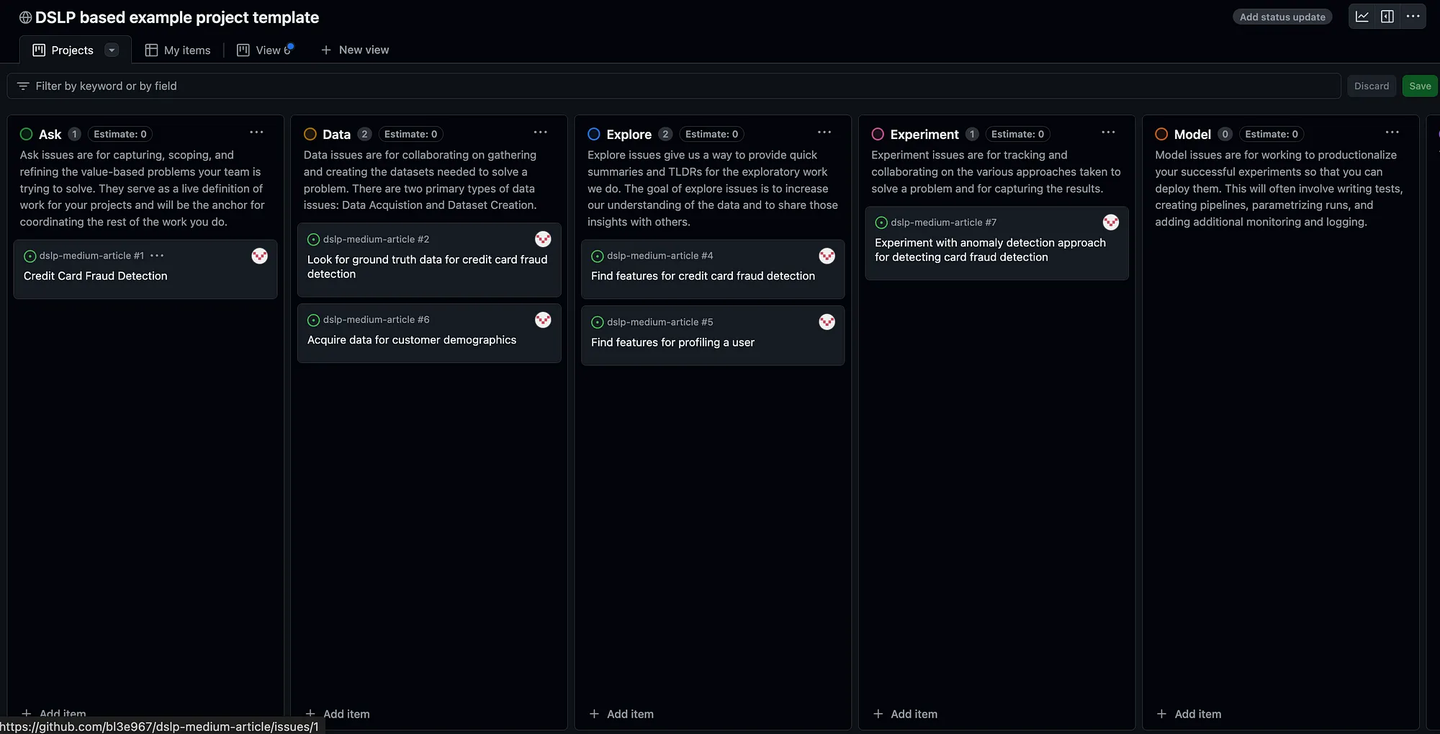
针对单个 Ask 问题一次打开多个问题的示例。
该项目很可能同时存在多个未解决的问题。
-
探索问题或实验问题可能会被数据问题阻止,因为您意识到在继续之前需要提供一些不同的数据。
-
其他一些问题可能需要代码审查,您需要催促审查人员为您完成此事。
-
有些问题您或许已经忘记了,甚至还没有开始处理。
我们需要一种方法来追踪所有这些问题,一些熟悉的方法……

添加图片注释,不超过 140 字(可选)
对数据科学有意义的看板 我们现在要做的是进入项目设置并创建一个Progress可以分配给我们的问题的字段。

单击右上角的 (...) 按钮(以红色突出显示)即可找到设置。
如下所示,我使用字段类型创建了四个标签Single select:To Do、In Progress和。当然,这是为我量身定制Blocked的Waiting for Review,您可以决定想要什么。
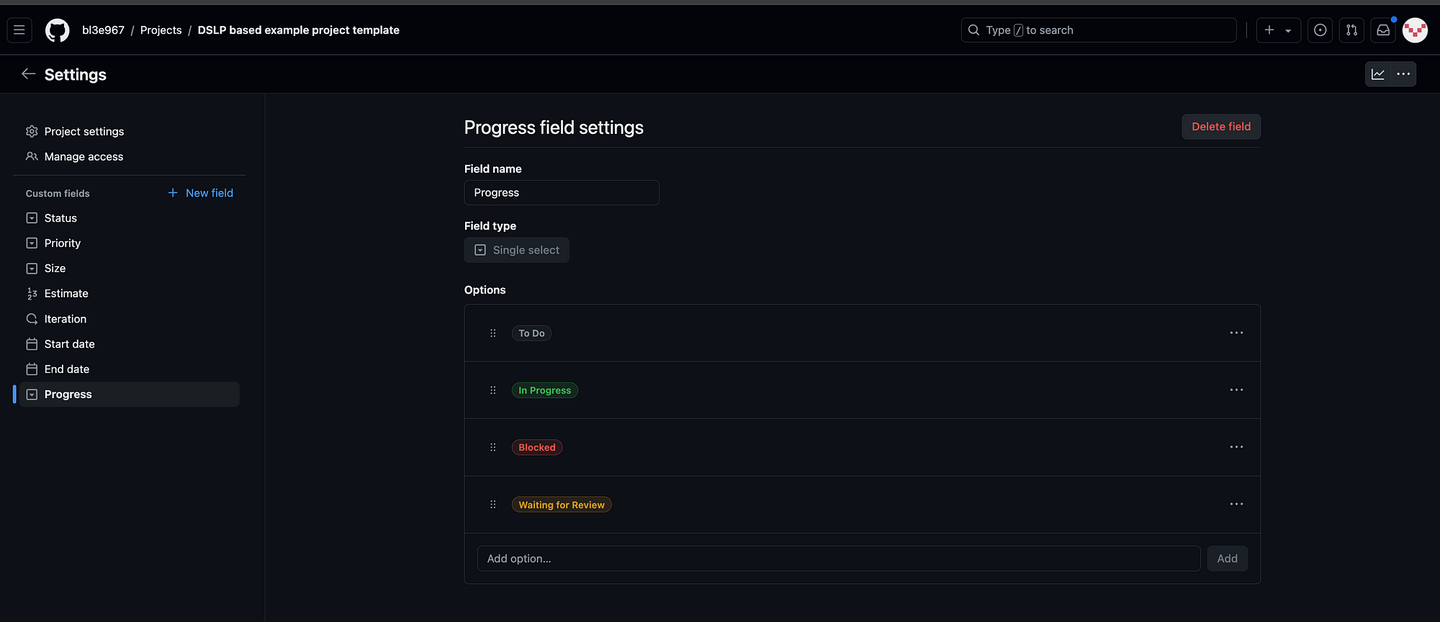
使用单选字段类型创建的四个进度字段。
现在,回到项目板,我可以创建一个名为的新视图Kanban Board,并使用下拉按钮,将列配置为基于Progress我们刚刚创建的字段(以红色突出显示)。 将“进度”字段分配给项目中的每个问题,
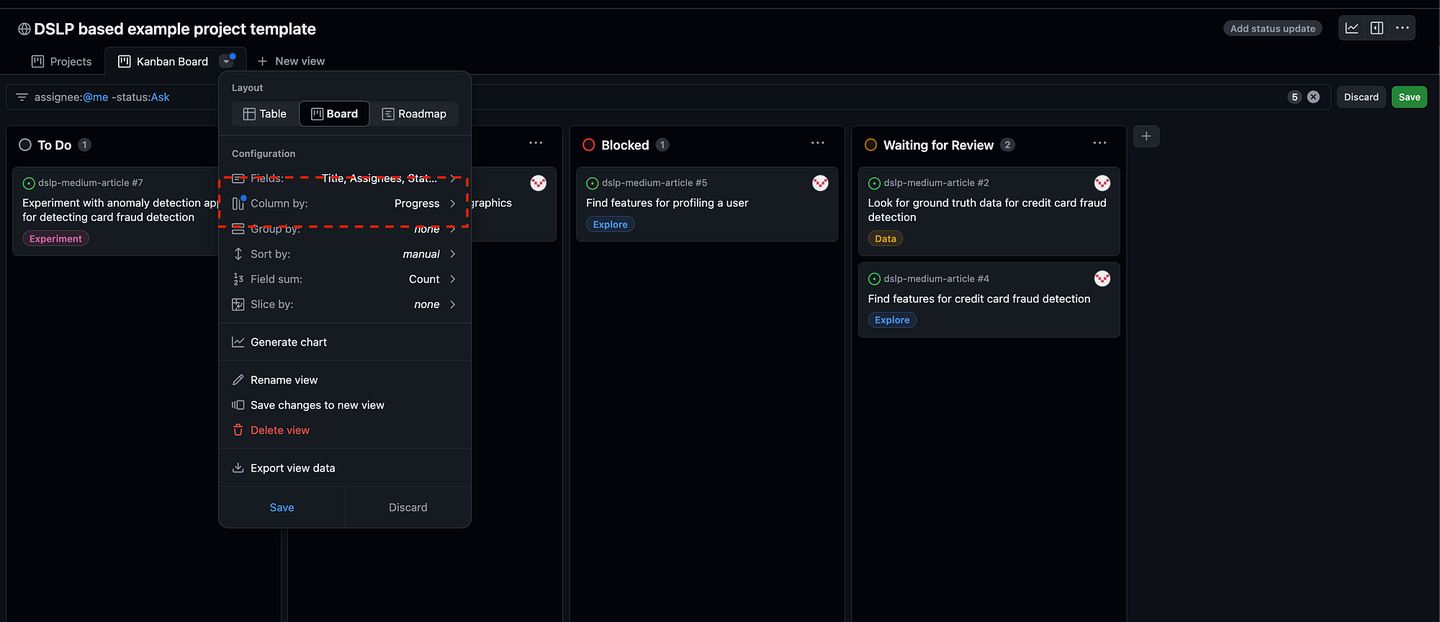
创建一个新视图并将列字段配置为进度,以红色突出显示。
瞧! 您拥有自己的看板,可用于组织会议并跟踪数据科学项目的进度!
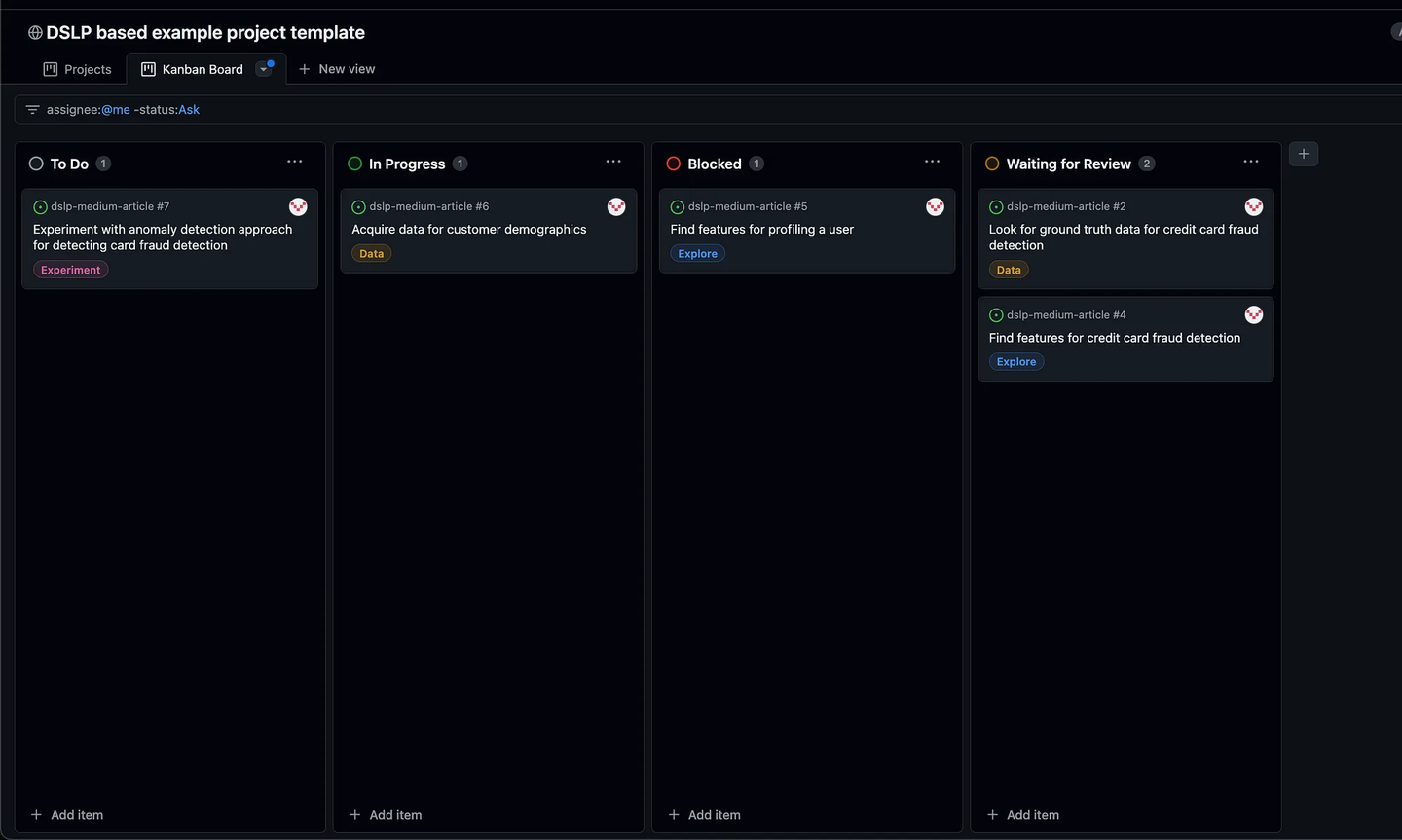
您现在有一个熟悉的看板。
为什么这种看板能起作用,而传统的看板却失败了? 所以,我们又回到了使用看板的话题。你可能会想: 等等,如果我们使用看板,那么整篇文章的意义何在? 嗯,我们的看板的起源是不同的。 数据科学项目本质上是研发工作。它与软件工程项目相比,要求的严谨程度有所不同。 数据科学问题由研究决定,而不是由客户/最终用户决定。 虽然软件工程实践要求问题的产生是为了适应不断变化的客户需求,但我们需要能够适应我们自己研究所决定的不断变化的需求的实践! 这就是我们拥有两块不同主板的原因:
-
一个板块(项目板块或问答板块)重点介绍针对单个项目(或问答)进行的不同研究和开发工作,
-
另一块板(看板)用于跟踪与 Ask 相关的研发任务的进度。
这就是该框架的不同之处,也是该框架真正适用于数据科学的原因。 通过使用这两种不同的板,您可以实现以下目标:
-
在一个 Ask 问题中完整总结项目的所有研发步骤,将所有相关问题和 PR 链接在一起。这使得文档、审计日志和知识共享变得轻而易举。这对于医疗保健或金融等高风险行业尤其重要。
-
使用看板维护每个问题进度,这是大多数人已经习惯的工作方式。这允许您围绕面向数据科学的看板整合其他敏捷方法,例如站立会议和冲刺。
结论 我希望您发现这篇文章很有用。 该框架可供任何级别的数据科学家使用:
-
无论是一位经理试图找到一种适合其团队的工作方式,
-
或初级数据科学家,试图找到一种方法来组织他们的工作。
它也不必在 Github 项目中。任何支持基于看板的工作流的项目都是兼容的,而且现在大多数工具都允许与 Github 集成,因此所有内容都可以集成在一起。 我没有介绍 DSLP 框架的每一个细节,只介绍了开始使用它所需的重要内容。 我鼓励你自己阅读这个框架,因为他们推荐了一些我决定不使用的其他内容,但也许它们对你有用——请在评论中告诉我。 最后要说一下为什么这样的框架变得越来越重要。 我提到过数据科学是一门以研发为基础的职业,但事实是,整个行业很快就达到了一个仅靠纯粹的研究是不够的点,我们需要能够提供具体的价值。 与此同时,随着机器学习模型在各个行业中的普及,监管审查将随着时间的推移而不断加强,首先是金融和医疗保健等高风险行业。这一趋势表明,我们需要对实施的模型进行更好的项目管理、文档记录和审计记录。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









