







欢迎来到雲闪世界。欢迎回到我的系列文章的第二部分,ChatGPT、Claude 和 Gemini 在数据分析方面的比较!在本系列中,我旨在比较这些 AI 工具在各种数据科学和分析任务中的表现,以帮助其他数据爱好者和专业人士根据自己的需求选择最佳的 AI 助手。如果您错过了第一篇文章(利用 OCR 和强大的 GPT-4o 迷你模型对收据进行信息提取),我比较了它们在编写和优化 SQL 查询方面的表现 — 请务必查看! 虽然 2024 年奥运会已经结束,但我们的 AI 竞赛才刚刚开始。到目前为止,Claude 3.5 Sonnet 已经领先!但它能保持自己的地位吗,还是 ChatGPT 和 Gemini 会赶上来?🏆 在第二篇文章中,我们将重点介绍他们独立进行探索性数据分析 (EDA) 的能力。作为一名数据科学家,想象一下拥有一个 AI 工具的便利性,它可以立即为新数据集提供数据洞察和建议,以指导高级分析和建模。让我们看看哪种模型可以提供最佳的 EDA。

添加图片注释,不超过 140 字(可选)
什么是 EDA 探索性数据分析 (EDA) 是检查和分析数据集以了解其主要特征的过程,通常使用视觉技术。它涉及数据清理、汇总统计数据以及识别数据中的模式、趋势和关系。目标是发现指导进一步分析或建模的见解,确保在进行更复杂的任务之前彻底了解数据。EDA 的关键组成部分包括:
-
数据检查:了解数据集的结构(例如,行数、列数、数据类型)并预览样本数据。
-
数据清理:纠正数据类型、处理缺失值和验证数据(例如,确保在必要时值是唯一的)。
-
单变量分析:使用可视化对单列执行描述性统计(例如平均值、中位数、分位数)。
-
双变量和多变量分析:探索成对或多组变量之间的关系。
-
见解和建议:产生见解和可行的建议,以提供进一步的分析或建模。
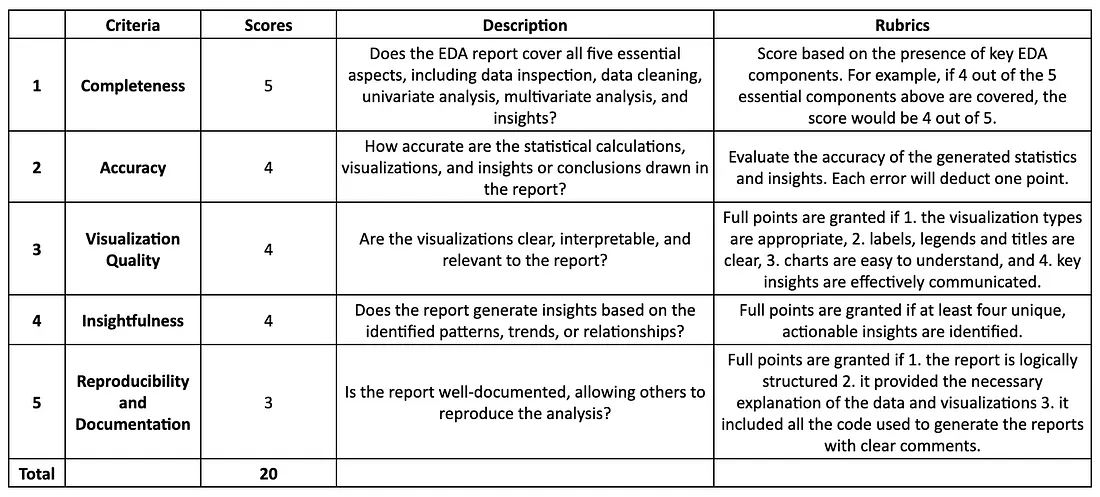
评估标准 我们将在“自动驾驶”模式下评估这三种工具,仅提供一个提示来进行 EDA,看看它们能走多远。评估将基于五个关键方面: 1.完整性(5分): EDA报告是否涵盖了数据检查、数据清理、单变量分析、多变量分析和洞察等五个基本方面? 2. 准确性(4 分):报告中的统计计算、可视化以及得出的见解或结论有多准确? 3. 可视化质量(4 分):可视化是否清晰、可解释且与报告相关? 4. 洞察力(4 分):报告是否根据已识别的模式、趋势或关系产生洞察力? 5. 可重复性和文档(3 分):报告是否有详尽的文档记录,以便其他人可以重复该分析? 请参阅下表中的详细评分标准:
添加图片注释,不超过 140 字(可选)
问题设置 这是我们用于本次评估的数据集:来自 Kaggle 的客户性格分析数据集(CC0:公共领域许可证)。 这是我的提示:
您是一家连锁杂货店的数据科学家。 您有一个数据集,其中包含客户的人口统计信息、 购买数据和营销活动历史记录。您今天的目标是对该数据集 进行彻底的探索性数据分析 (EDA),并提供必要的数据清理、分析和可视化、清晰的见解和可行的建议。 您的 EDA 将用于更好地了解客户、根据客户行为影响产品策略,并为进一步的客户细分分析和建模提供信息。 以下是各列的说明: 1. 人员-ID:客户的唯一标识符 -Year_Birth:客户的出生年份 -Education:客户的教育程度 -Marital_Status:客户的婚姻状况 -Income:客户的家庭年收入 -Kidhome:客户家庭中的儿童数量 -Teenhome:客户家庭中的青少年数量 -Dt_Customer:客户在公司注册的日期 -Recency:自客户上次购买以来的天数 -Complain:如果客户在过去 2 年内投诉过,则为 1,否则为 0 2. 产品 -MntWines:过去 2 年在葡萄酒上的花费 -Mn
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 61
61

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









