







使用 Indexify 进行文档查询的分步指南。欢迎来到雲闪世界。

添加图片注释,不超过 140 字(可选)
总结:
-
传统的数据提取方法通常会错过非结构化内容的更深层次的见解,尤其是在房地产领域。
-
本文探讨使用 Indexify(一种用于实时、多模式数据提取的开源框架)来更好地分析财产文件。
-
您将学习设置 Indexify,包括服务器设置、提取图形创建、文档提取和数据查询,以及如何创建自定义提取器。
-
实施 Indexify 可以增强财产文件分析,从而获得更准确的见解、更好的决策和简化的管理。
传统的数据提取方法通常无法挖掘隐藏在非结构化内容中的更深层次、更复杂的见解。大多数方法只能捕获表面信息,无法揭示更深层次的见解。随着企业的发展和文档收集的扩大,对高级工具的需求变得至关重要,这些工具可以解析、分析和理解这一浩瀚的信息海洋。这种深度对于推动明智的决策、识别趋势和保持竞争优势至关重要。
房地产行业已准备好接受人工智能驱动的转型。通过集成先进的人工智能解决方案,组织可以增强文档分析、解析房地产记录并简化管理流程。更好的数据提取策略可以改善房地产数据分析,并提供更准确、更可操作的房地产文档洞察,从而实现高效的维护、销售等。
在本文中,我将探索使用Tensorlake的开源框架 Indexify 进行数据提取和检索。我还将展示这个可扩展系统在处理和分析与财产相关的文书工作方面的能力。
Indexify 概述
Indexify是一个开源提取和提取引擎,旨在实时为 LLM 应用程序提供支持。它能够以极低的延迟从非结构化源实时提取数据。它还支持可应用于各种用例的多模式提取工作流,包括从文档中提取和嵌入实体、音频转录、摘要以及从图像甚至视频中检测对象。
它还支持高效的索引、存储和检索数据,使其成为可扩展实时 RAG 系统的有力候选者。
任何工作流程都可以通过 4 个基本步骤轻松实现:
-
启动 Indexify 服务器和提取器。
-
创建提取图。
-
以您所需的格式(视频、图像、音频、pdf 等)提取数据。
-
检索提取的数据。
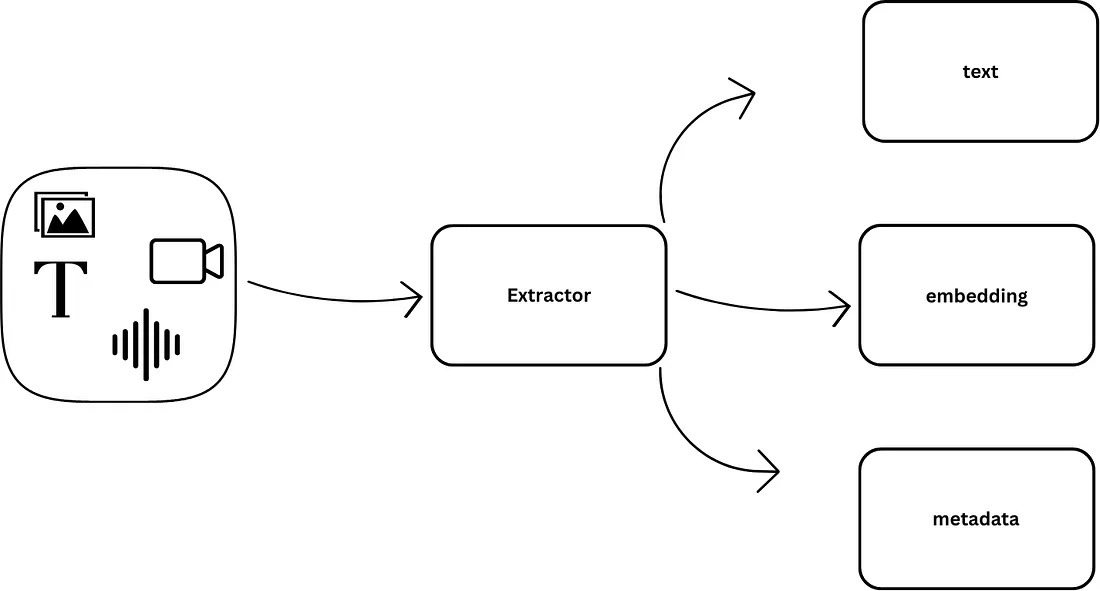
提取器
提取器模块是 Indexify 的核心功能。提取器可以从任何形式的非结构化数据中提取并返回结构化信息。例如,从 JSON 格式的 PDF 中获取特定信息、将数据转换为嵌入,以及识别视频中的面部或物体。
添加图片注释,不超过 140 字(可选)
提取器通常接收非结构化数据作为输入,并生成内容对象和特征列表作为输出。非结构化数据的原始字节存储在 blob 存储中,提取的特征作为索引存储在向量存储和结构化存储中以供检索。任何用于处理非结构化数据的模型或算法都可以通过扩展提取器 SDK 中提供的抽象类来实现为提取器。
协调员
这些是 Indexify 中使用的高性能任务调度程序。它们在开始提取数据时将任务分配给提取器,从而帮助实现卓越的速度和性能。
有关 Indexify 的更多深入信息,请查看其文档。
本教程的先决条件
对于本教程,请确保您拥有 Python 版本 3.11 或更高版本以获得最佳性能。其他安装说明将在稍后提供。
我将使用Groq作为 LLM 引擎。首先,请转到此页面并创建 API 密钥。
添加图片注释,不超过 140 字(可选)
另外,安装库。
pip install groq对于数据,我准备了一些房地产宣传册的 PDF 版本。您可以随意使用自己收集的与物业管理相关的文档。
设置 Indexify 进行高级文档分析
安装和配置 Indexify
在 Linux 系统上设置 Indexify 很容易。对于开发,您需要运行 3 个终端窗口。
-
终端 1:用于下载和运行 Indexify 服务器。
-
终端 2:用于运行 Indexify 提取器,处理结构化提取、分块和嵌入。
-
终端 3:用于运行 Python 脚本以从 Indexify 服务器加载和查询数据。
您可以使用以下命令启动并运行 Indexify 服务器。记得检查命令在哪些终端上运行。
TERMINAL 1
curl https://getindexify.ai | sh
./indexify server -d.服务器将在http://localhost:8900上运行。
接下来,创建一个 Python 环境并安装所有必要的库和提取器。我将详细讨论本教程所需的特定提取器。
TERMINAL 2
pip3 install indexify-extractor-sdk indexify wikipedia
indexify-extractor download tensorlake/paddleocr_extractor
indexify-extractor download tensorlake/minilm-l6
indexify-extractor download tensorlake/chunk-extractor下载后,使用以下命令运行提取服务器:
TERMINAL 2
indexify-extractor join-server系统现已准备好进行开发。我将在整个教程中保持这两个终端运行。
准备文件集
第一步是整理您的文档集合。我将在此工作流程中使用 PDF 文档。对于多个文档,您可以按如下方式构造目录:将所有文档作为 PDF 添加到数据目录。对于其他数据类型,您必须使用其他提取器或定义自定义提取器,我将在本博客的后面部分讨论。
└── data
├── doc1
├── doc2
├── doc3
├── doc4
├── venv
├── indexify file
├── ingest_document.py
├── query_doc.py
└── setup_extraction_graph.py 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









