






前言
最近时间序列基础模型领域,迎来了里程碑式的突破。
TimeGPT作为首个原生基础模型,于去年八月问世,一发布就震撼了预测领域。
众多其他基础模型也相继发布,包括但不限于:
-
TimesFM
-
MOIRAI
-
Tiny Time Mixers(TTM)
-
MOMENT
本文将深入探讨这些更新内容——包括新的基准测试和改进后的模型变体。
TimesFM——谷歌的基础模型
最新更新: 模型权重最近已在Hugging Face上公开!
谷歌凭借TimesFM这一拥有2000亿参数的基础模型,正式加入了时间序列基础模型的竞争行列。
构建大型时间序列模型的一大难题在于数据的稀缺性,找到优质且多样化的公开时间序列数据极具挑战性。
而TimesFM团队通过利用Google Trends和WikiPage浏览量等数据源,扩展了训练数据集。
最终模型在1000亿个真实世界的时间点上进行了预训练。
从架构上看,TimesFM是一款基于Transformer的模型,它利用规模优势进行时间序列预测(如图1所示):

TimesFM 架构概述
TimesFM的秘密在于它巧妙地结合了patching技术(而这对语言模型大有裨益)和生成式预训练模型中的仅解码器风格。
那么,patching技术是如何工作的呢?
就像文本模型预测下一个单词一样,时间序列基础模型则预测下一个时间点段的patching。
patching之所以有效,是因为它将一段时间点窗口视为一个标记,从而利用局部时间信息创建丰富的表示。
这有助于TimesFM更有效地捕捉时间动态,从而做出更准确的预测(如图2所示):

图2:使用TimesFM进行时间序列预测,多步预测的时间范围为30个数据点,频率为每半小时一次。
作者已经发布了针对单变量情况的模型权重和推理代码,并计划发布带有扩展API的新模型变体,以便进行微调。
现在就差公开预训练数据集了

MOIRAI——Salesforce的基础模型
**最新更新:**Salesforce已将该模型、权重、预训练数据集以及新模型变体开源!
您可以在AI Projects文件夹中找到MOIRAI的动手教程!
Salesforce发布MOIRAI的时间与TimesFM大致相同。MOIRAI因其独特的Transformer编码器架构而脱颖而出,该架构旨在处理时间序列数据的异质性和复杂性。
MOIRAI的关键特性包括:
-
多补丁层:MOIRAI通过为每个频率学习不同的补丁大小来适应多种频率。
-
任意变量注意力:一种优雅的注意力机制,尊重各变量之间的排列差异,并捕捉数据点之间的时间动态。
-
参数分布混合:MOIRAI优化学习分布的混合体,而非假设单一分布。
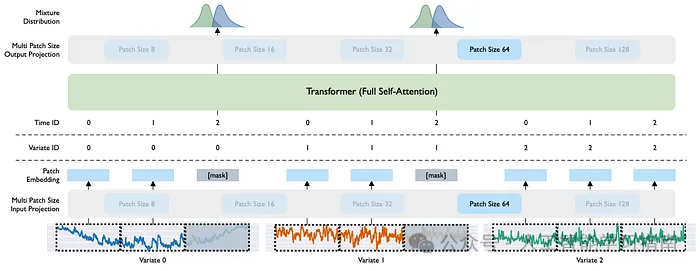
MOIRAI 架构
与TimesFM相比,MOIRAI为时间序列引入了众多新颖特性。
它改进了传统的注意力机制(任意变量注意力),并考虑了不同的时间序列频率。
但MOIRAI(以及每个基础模型)的有效性在很大程度上取决于其预训练数据集。
MOIRAI在LOTSA数据集上进行了预训练,LOTSA是一个包含九个领域、共计270亿条观测记录的庞大数据集。(该数据集也已公开)
这一广泛的数据集结合模型的创新架构,使得MOIRAI成为理想的零样本预测器——能够迅速且准确地预测未见过的数据。
图4和图5展示了MOIRAI-large在日前能源预测任务中的表现(来自AI Projects文件夹中的MOIRAI教程):
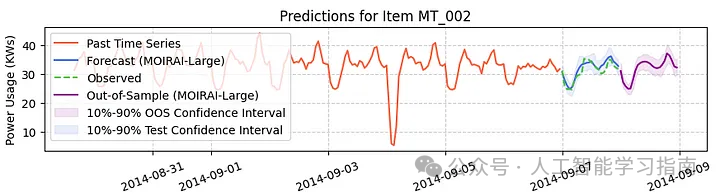
图4:MOIRAI的次日能量预测(千瓦时),包含预测区间(图片由作者提供)。”

图5:MOIRAI-large的表现优于强大的统计模型。这些统计模型是针对每个时间序列单独训练的,而MOIRAI的预测则是零样本预测(即没有在这些数据上进行训练)。
最后,MOIRAI的一个显著优势在于其多变量预测能力,我们可以添加过去观测到的协变量或未来已知输入(如节假日)。
这使得MOIRAI特别适用于那些可以通过外部信息增强的时间序列案例(如交易、能源需求预测等)。
Tiny Time Mixers (TTM)
IBM研究团队的基础模型
**最新更新:**作者最初开源了一个快速版本TTM-Q。
几个月后,他们更新了论文,描述了具有新特性(如可解释性)的更好模型变体,并将这些变体也开源。
大家可以在AI Projects 文件夹中找到TTM-Q(零样本和微调)的动手项目!
TTM是一个独特的模型,它采用了与上述模型不同的方法:
它不是Transformer模型!
同时,TTM轻巧且性能优于其他更大的基础模型。
TTM的主要特点包括:
-
非Transformer架构:TTM使用全连接神经网络层而非注意力机制,因此速度极快。
-
TSMixer基础架构:TTM采用IBM突破性时间序列模型TSMixer
-
丰富的输入能力:TTM擅长处理多变量预测,能够接收额外通道、外生变量以及已知的未来输入。
-
快速且强大:TTM-quick版本在Monash数据集的2.44亿个样本上进行了预训练,仅使用6个A100 GPU便在不到8小时内完成。
图6展示了TTM架构的顶层视图:
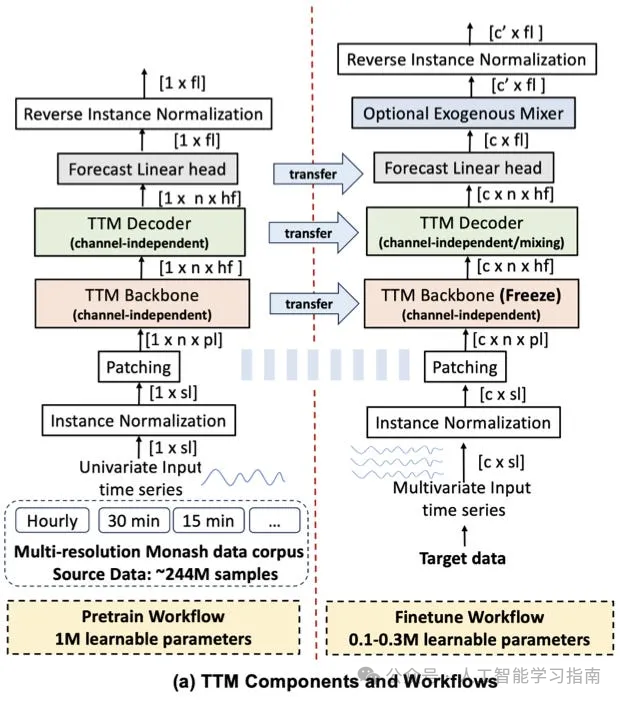
图6:TTM架构的顶层视图,左侧为预训练阶段,右侧为微调阶段。
TTM的运作分为两个阶段:预训练和微调
-
预训练阶段:模型仅使用单变量时间序列进行训练,充分利用历史信息和局部季节性模式。
-
微调阶段:模型接收多变量数据,并通过启用通道混合器过程(如图6所示)学习这些变量之间的相互依赖关系。
在微调过程中,核心层保持不变,使得整个过程轻量级。模型还可以选择性地通过激活外生变量混合器(如图7所示)来使用已知的未来协变量,以进一步提升性能。

图7:TTM-Q在温度预测任务中对CO2浓度(mmol/mol)的预测
此外,作者还创建了具有不同参数大小、上下文长度(sl)和预测长度(fl)的新模型变体:
-
**TTM-Base (TTM_B):**100万参数,sl=512,pl=64
-
**TTM-Enhanced (TTM_E):**400万参数,sl=1024,pl=128
-
**TTM-Advanced (TTM_A):**500万参数,sl=1536,pl=128
-
**Quick-TTM (TTMQ):**包含两个变体,分别对应sl/pl = (512,96)和(1024,96)。
作者展示了这些模型在基准测试中表现更佳。
在最终迭代中,作者还解决了可解释性问题,新变体能够提供特征重要性分析(如图8所示)。

总的来说,TTM是一款卓越的模型,其不依赖繁重的Transformer运算的方法为众多有趣的可能性开辟了道路。
MOMENT
**最新动态:**作者已开源了最大的变体MOMENT-large及其预训练数据集Time-Series Pile。
与以往的模型不同,MOMENT作为一款通用时间序列模型,能够胜任预测、分类、异常检测和插值等多种任务。
MOMENT在GPT4TS和TimesNet等同样面向多时间序列任务的模型基础上进行了改进。
以下是MOMENT的关键特性:
-
基于LLM:利用T5模型来处理五种时间序列任务。
-
轻量级执行:适合在有限资源下快速执行。
-
零样本预测:在零样本场景下表现出色,且可通过微调进一步优化性能。
-
采用patching技术:与上述模型类似,MOMENT将时间点子序列视为标记,从而提升推理速度。在预训练阶段,MOMENT会对时间点进行归一化处理,并将它们打包成嵌入表示。这些嵌入表示随后被处理以重建原始时间点。
因此,MOMENT的预训练过程类似于BERT的训练方式(掩码语言建模):随机遮挡输入时间序列的部分内容,并训练模型以最优方式重建它们(如图9所示)。

图9:MOMENT预训练阶段的顶层架构
使用T5编码器预训练了三个模型变体:T5-Small(4000万参数)、T5-Base(1.25亿参数)和T5-Large(3.85亿参数)。
这些变体在多样化的数据集(Time-Series Pile)上进行了预训练,使模型能够在未见过的数据上具备良好的泛化能力。
如何使用MOMENT
此外,MOMENT既可以作为零样本预测器使用,也可以通过微调来提升性能。
针对特定任务微调后的MOMENT模型系列(MOMENT-LP)在基准测试中展现出了令人鼓舞的结果,往往能够超越更大、更复杂的模型。
总结
基础NLP模型激发了人们对于大型语言模型(LLMs)在时间序列预测领域应用的浓厚兴趣。
TimeGPT自发布以来虽不足一年,但已吸引众多大型企业和研究人员投入时间与精力进行模型开发。
基础时间序列模型将对实际应用产生深远影响,时间序列数据广泛应用于零售、能源需求、经济分析以及医疗健康等多个领域。
类似GPT-4在文本处理中的广泛应用,一个基础时间序列模型也能以极高的准确性应用于各种时间序列案例。
当然,这一领域仍有巨大的提升空间,这也是本文所探讨的每个模型持续更新的原因所在。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









