






背景
AB实验可谓是互联网公司进行产品迭代增加用户粘性的大杀器。但人们对AB实验的应用往往只停留在开实验算P值,然后let it go。。。let it go 。。。
让我们把AB实验的结果简单的拆解成两个方面:
P(实验结果显著) = P(统计检验显著|实验有效)× P(实验有效) 如果你的产品改进方案本来就没啥效果当然怎么开实验都没用,但如果方案有效,请不要让 statictical Hack 浪费一个优秀的idea
如果预期实验效果比较小,有哪些基础操作来增加实验显著性呢?
通常情况下为了增加一个AB实验的显著性,有两种常见做法:增加流量或者增长实验时间。但对一些可能对用户体验产生负面影响或者成本较高的实验来说,上述两种方法都略显粗糙。
对于成熟的产品来说大多数的改动带来的提升可能都是微小的!
在数据为王的今天,我们难道不应该采用更精细化的方法来解决问题么?无论是延长实验时间还是增加流量一方面都是为了增加样本量,因为样本越多,方差越小,p值越显著,越容易检测出一些微小的改进。
因此如果能合理的通过统计方法降低方差,就可能更快,更小成本的检测到微小的效果提升
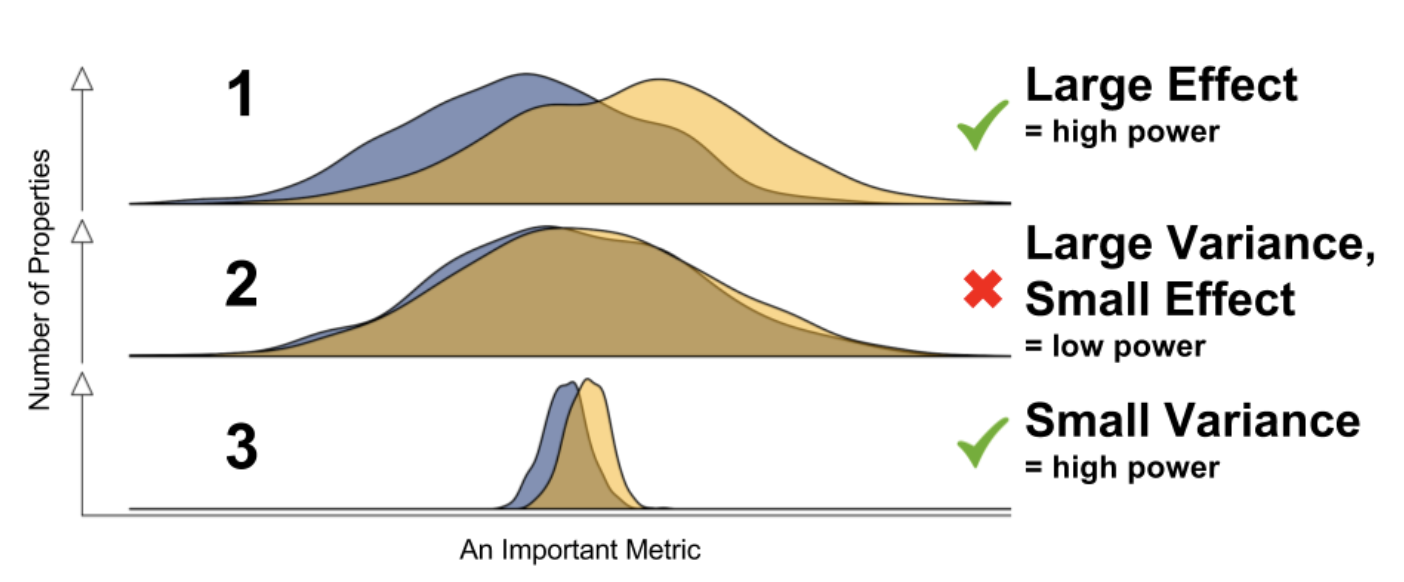
image.png-172.7kB
CUPED(Controlled-experiment Using Pre-Experiment Data)应运而生。 下面我会简单总结一下论文的核心方法,还有几个Bing, Netflix 以及Booking的应用案例。
论文
Deng A, Xu Y, Kohavi R, Walker T. Improving the Sensitivity of Online Controlled Experiments by Utilizing Pre-experiment Data. Proceedings of the Sixth ACM International Conference on Web Search and Data Mining. New York, NY, USA: ACM; 2013. pp. 123–132. Paper链接
核心方法总结
论文的核心在于通过实验前数据对实验核心指标进行修正,在保证无偏的情况下,得到方差更低, 更敏感的新指标,再对新指标进行统计检验(p值)。
这种方法的合理性在于,实验前核心指标的方差是已知的,且和实验本身无关的,因此合理的移除指标本身的方差不会影响估计效果。
作者给出了stratification和Covariate两种方式来修正指标,同时给出了在实际应用中可能碰到的一些问题以及解决方法.
stratifiaction
这种方式针对离散变量,一句话概括就是分组算指标。如果已知实验核心指标的方差很大,那么可以把样本分成K组,然后分组估计指标。这样分组估计的指标只保留了组内方差,从而剔除了组间方差。
k=1,2,…,KYstrat=K∑k=1wk∗(1nk∗∑xi∈kYi)Var(Y)=Varwithin_strat+Varbetween_strat=K∑k=1wknσ2k+K∑k=1wkn(μk−μ)2>=K∑k=1wknσ2k=Var(^Ystrat)
Covariate
Covariate适用于连续变量。需要寻找和实验核心指标(Y)存在高相关性的另一连续特征(X),然后用该特征调整实验后的核心指标。X和Y相关性越高方差下降幅度越大。因此往往可以直接选择实验前的核心指标作为特征。只要保证特征未受到实验影响,在随机AB分组的条件下用该指标调整后的核心指标依旧是无偏的。
Ycovi=Yi−θ(Xi−E(x))Ycov=Y−θ(¯x−E(x))θ=cov(X,Y)/cov(X)Var(Ycov)=Var(Y)∗(1−θ2)
stratification和Covariate其实是相同的原理,从两个角度来看:
- 从回归预测的角度,实验核心指标是Y,降低Y的方差就是寻找和Y相关的自变量X来解释Y中信息的过程(提升
(R2)
),X可以是连续也可以是离散的
- 从投资组合的角度,Y是组合中的一项资产,想要降低交易Y的风险(方差),就要做空和Y相关的X资产来对冲风险,相关性越高对冲效果越好
下图摘自Booking的案例,他们的核心指标是每周的房间预定量,Covariate是实验前的每周房间预定量,博客链接在案例分享里。
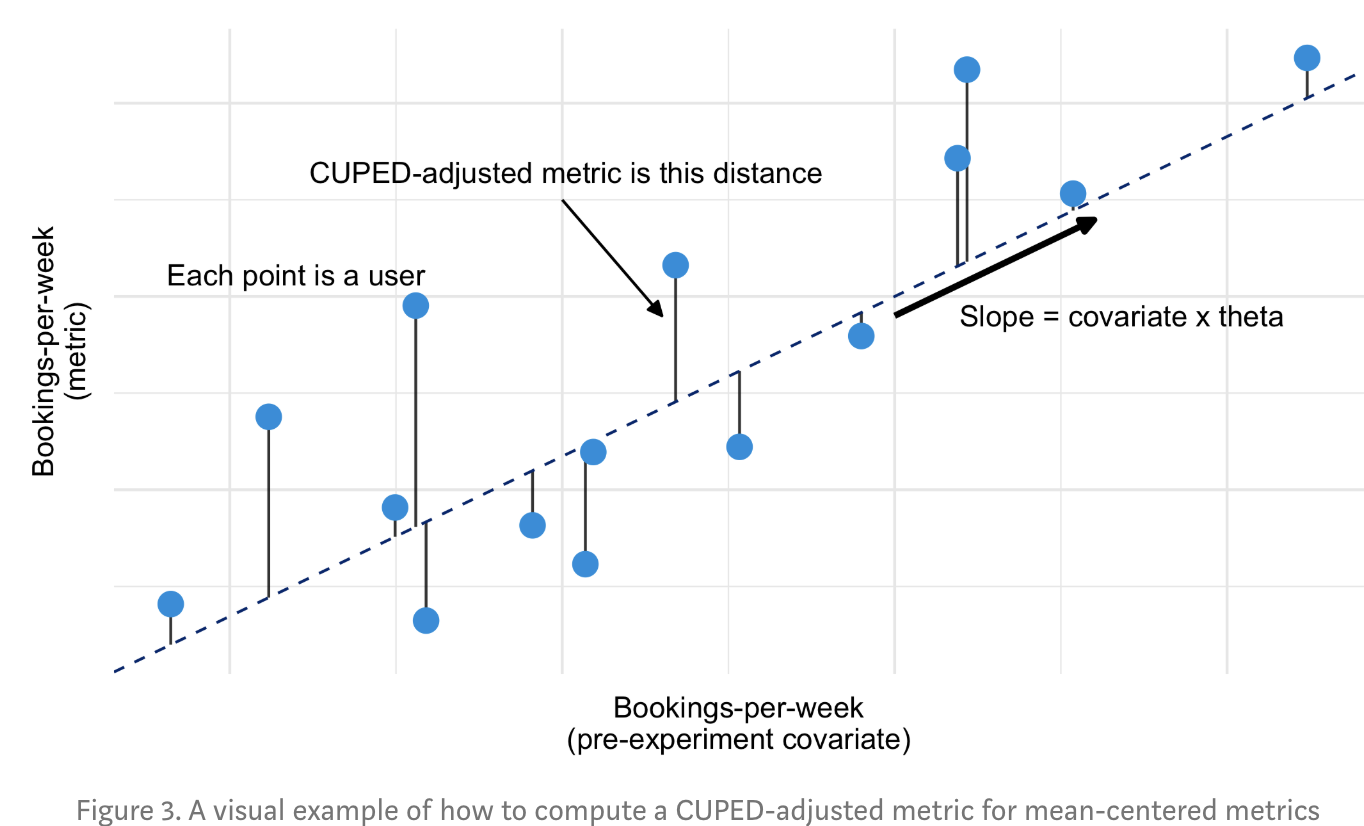
image.png-138.3kB
实战攻略
covariate的选择
这里的选择包括两个方面,特征的选择和计算特征的pre-experiment时间长度的选择。
核心指标在per-experiment的估计通常是很好的covariate的选择,且估计covariate选择的时间段相对越长效果越好。时间越长covariate的覆盖量越大,且受到短期波动的影响越小估计更稳定。
没有pre-experiment数据怎么办
这个现象在互联网中很常见,新用户或者很久不活跃的用户都会面临没有近期行为特征的问题。作者认为可以结合stratification方法对有/无covariate的用户进一步打上标签。或者其实不仅局限于pre-experiment特征,只要保证特征不受到实验影响post-experiment特征也是可以的。
而在Booking的案例中,作者选择对这部分样本不作处理,因为通常缺失值是用样本均值来填充,在上述式子中就等于是不做处理。
Attention
Covariate选择的核心是
(E(Xtreatment)=E(Xcontrol))
,这一点不论你选择什么特征, 是pre-experiment还是post-experiment都要保证。
当然也有用CUPED来矫正实验组对照组差异的,但这个内容不在这里讨论。
应用案例
Bing 加载时间对用户点击率的影响
论文中作者在实际AB实验中检验了CUPED的效果。Bing实验检测检测加载时间对用户点击率的影响。 一个原本运行两周只有个别天显著的实验在用CUPED调整后在第一天就显著,当把CUPED估计用的样本减少一半后显著性依旧超过直接使用T-test.
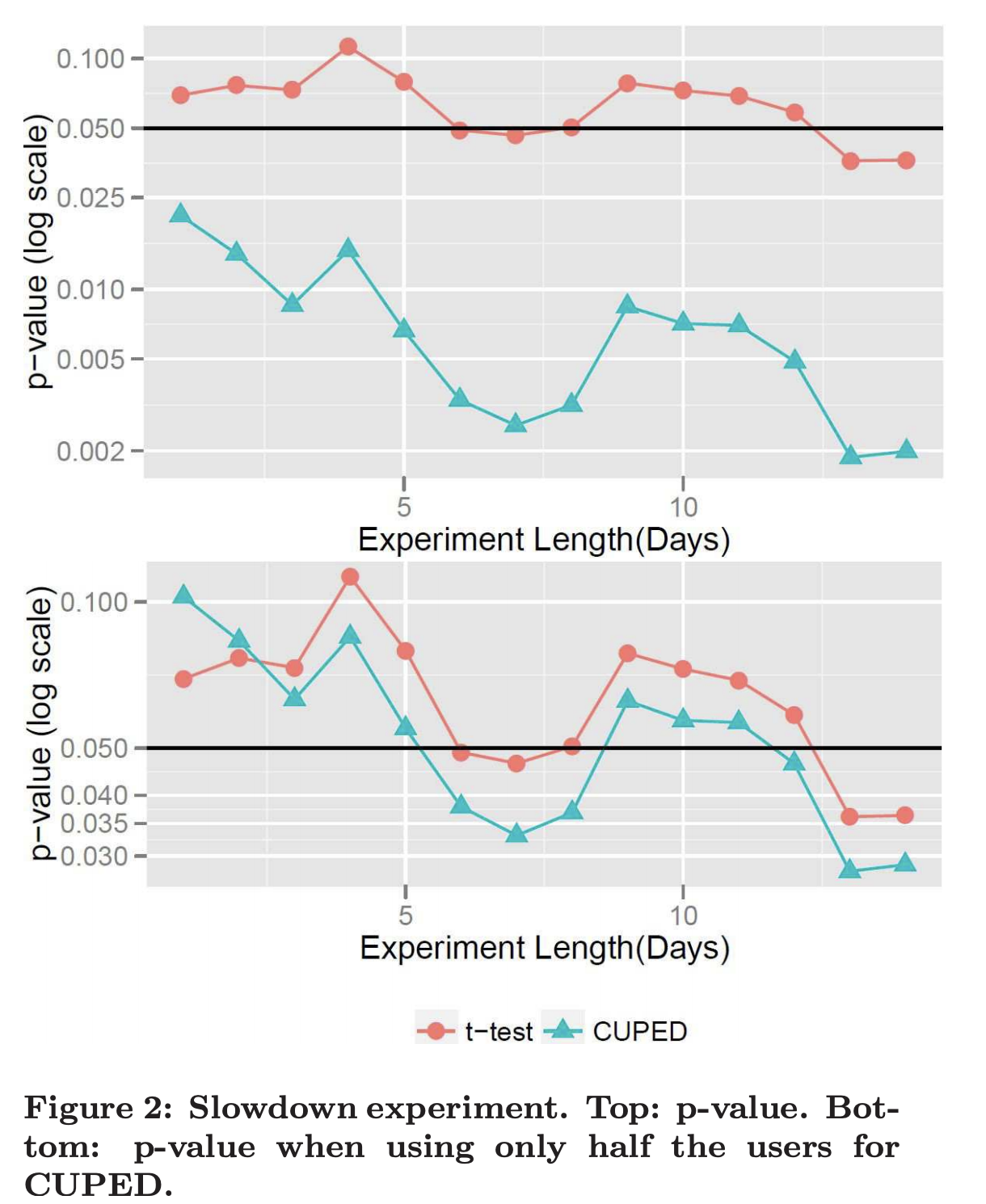
image.png-655.1kB
Netflix 多种方法的实际效果对比
Netflix尝试了一种新的stratification, 上述论文中的stratification被称作post-stratification因为它只在估计实验效果时用到分组,这时用pre-experiment估计的分组概率会和随机AB分组得到的实验中的分组概率存在一定差异,所以Netflix尝试在实验前就进行分层分组。通过多个实验结果,Netflix得到以下结论:
- 大样本下,post-strat在实际中更灵活和pre-strat表现相当
- 能否成功找到和实验核心指标相关的covariate是成功的关键
Booking.com 新日历交互对用户影响
How Booking.com increases the power of online experiments with CUPED
实验效果对比如下,CUPED用更少的样本更短的时间得到了显著的结果。了解细节请戳上面的博客,作者讲的非常通俗易懂。
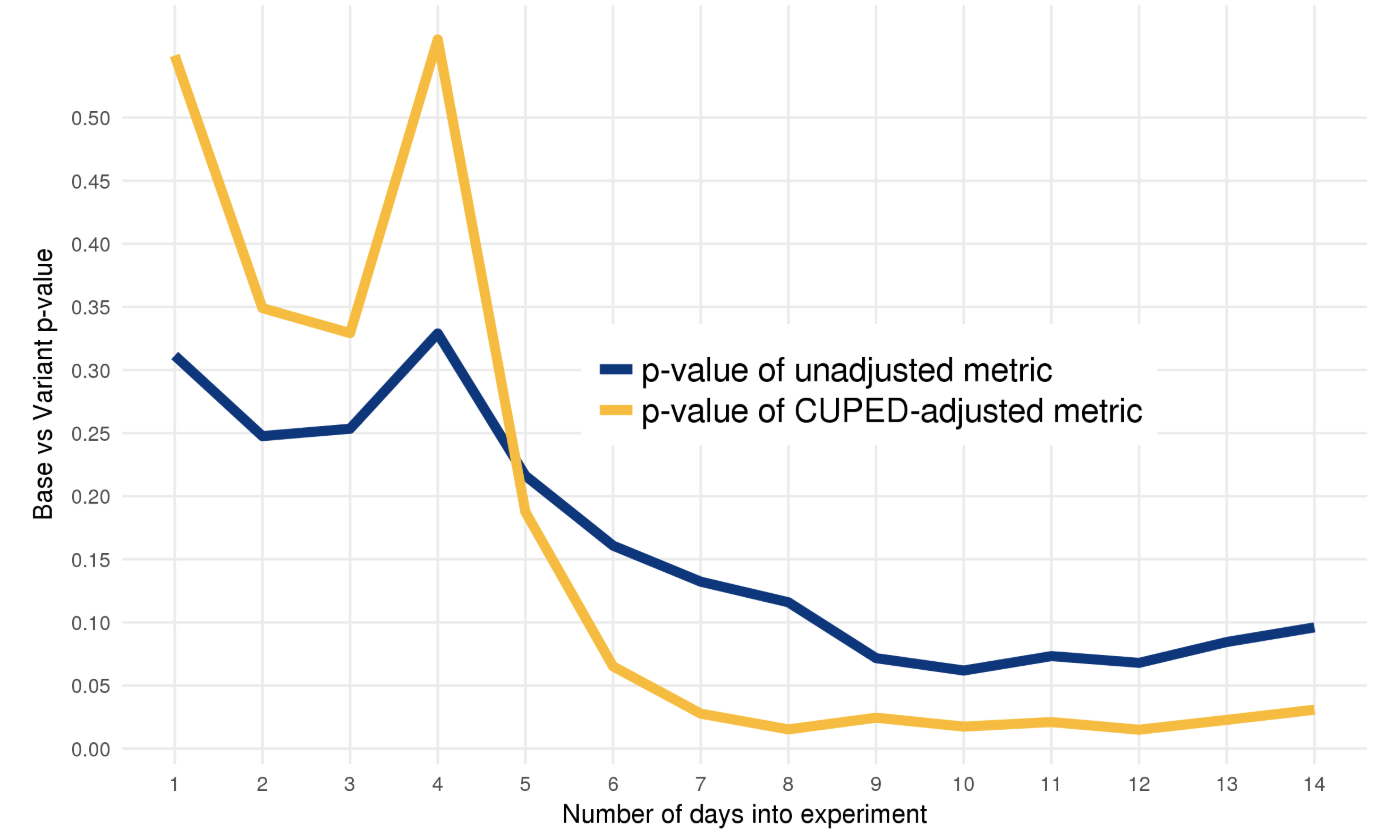
image.png-152.8kB
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









