






前言
黑马DeepSeek-R1的崛起,给外国网友上演了一场来自东方的震撼。
一边,OpenAI和Claude都破了大防,一个声讨“窃取”,一个嘲讽“落后”,两家水火不容的对手竟然以这种戏剧性的方式,鲜有地达成了一致。

另一边,微软、亚马逊等云服务厂商,甚至英伟达都开启了“真香”模式,你追我赶地在自家云平台上线DeepSeek-R1。
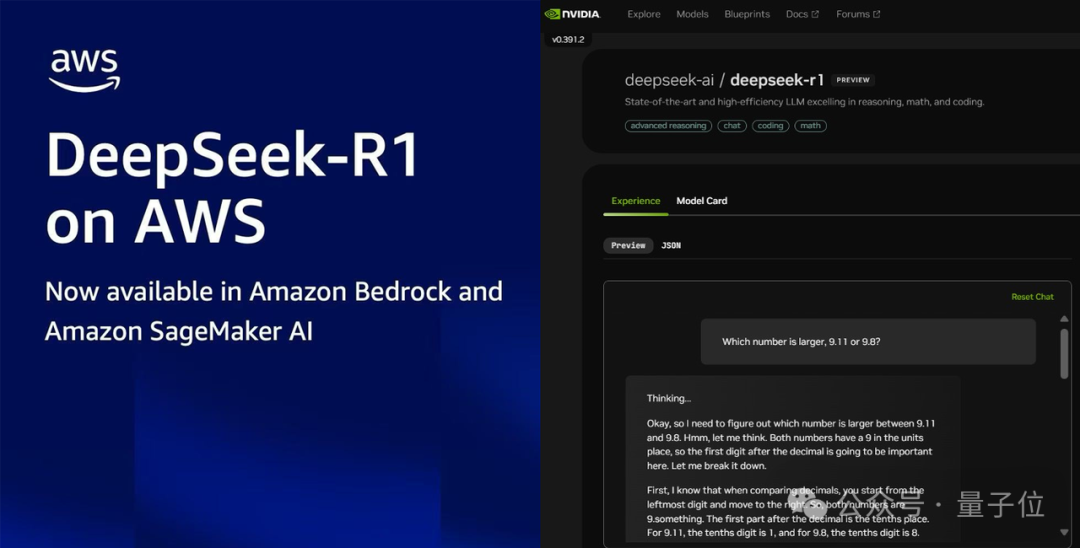
但不管破防还是真香,DeepSeek-R1都已经成为一股震撼硅谷的“东方神秘力量”。
DeepSeek,不是一个人在战斗,背后也是中国大模型的全面崛起。
中国大模型遍地开花
在各个领域,中国的大模型都不缺乏强者,而且各具特色。
就拿DeepSeek-R1来说,它的特色在于成本极低,也正是这一点戳到了OpenAI和Claude的痛处。
做搜索出身的百度,将积累下来的技术经验用到了模型产品当中,把RAG能力做成了模型特色,让文心一言成为了RAG领域的最强选手。
在文字之外,语音是一种更加自然的对话方式,在这方面,字节的豆包就有强大的端到端对话,能够处理复杂的中文内容,甚至感知人类情绪,总之是一点不输给OpenAI的《Her》。
除了和对话相关的模型,在视频生成领域还有异军突起的快手可灵,视频质量已经实现对Sora的超越。
可灵的出现也带动了一系列国产视频生成模型的发展,后来,字节的即梦、阿里的通义万相,还有来自大模型六小虎以及独立的视频模型厂商,都纷纷上线自己的产品。
等到国产模型拥有了成熟的应用和商业模式,OpenAI的Sora才终于姗姗来迟,但与Demo刚刚出现时的惊艳相比已是泯然众人。

而在从模型走向应用的路上,有一项能力,它的名字不像视频生成、文本对话这样一目了然,但扮演着重要的角色。
它就是刚刚提到的RAG。
RAG技术,百度引领
所谓RAG,就是检索增强生成,它通过引入检索机制,使得模型在生成回答时能够参考更多的信息,从而提高了回答的准确性和丰富性。
RAG之所以重要,在于它可以帮助模型解决这样几个问题:
-
一是大模型无法针对训练完成之后的信息进行回答,RAG可以迅速补充;
-
二是大模型部分情况下存在幻觉,RAG可以通过引入外部资料降低幻觉现象;
-
三是通过对外部资料的调用,让模型生成的答案更加权威透明。
而在RAG能力上,国内同样有着一位强者,它就是百度的文心一言。
光说不练没有说服力,接下来就拉文心一言和ChatGPT比试一番。
既然RAG的一大用途是解决训练完成后的信息问题,考察的题目也得有时效性。
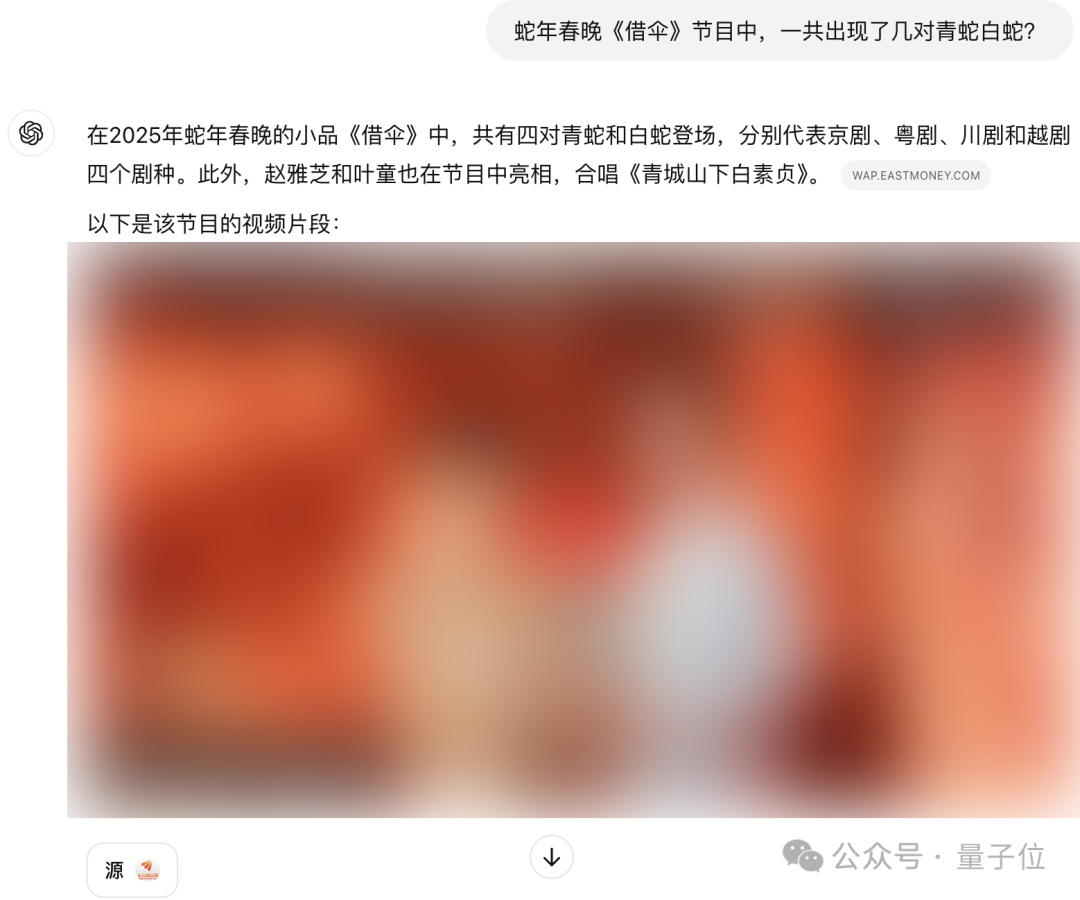
蛇年春晚《借伞》节目中,一共出现了几对青蛇白蛇?(答案:六对)

但ChatGPT这里,虽然也搜到了相关内容,还像模像样地给出了视频,但标注引用的链接当中并不包含答案,而且回答的数字也是错的。
不过在实际场景中,我们不一定会一次只问一个问题,而是连珠炮似的抛出一串问题,并且说话的过程中还会出现省略,这就对模型理解问题提出了更高的要求。
第五航权是指什么?能够进行什么样的客货运输?和第八航权有什么区别?
这波文心一言成功捕捉了三个问题并一一给出正确解答,而且在对比两个概念的区别时还采用了表格的方式,更加易于理解其不同。

相比较之下,ChatGPT说的虽然也对,但区别的部分只是把两个概念各自介绍了一遍,看上并没有那么一目了然。

除了连环提问,也可以在问题本身上设置难度,询问一些极其专业的问题。
在有机化学当中,周环反应既不产生离子也不产生自由基,这种反应为什么能够发生?
结果呢,文心一言不仅解答了疑问,还补充介绍了相关化学反应的概念和分类,甚至最后还附上了视频课程,方便我们进一步学习。

从以上场景可以看出,文心一言的RAG能力,已经达到了相当出色的水平。
在这背后,百度研发了“理解-检索-生成”协同优化的检索增强技术,将回答问题的过程拆分成了三个阶段:
-
理解阶段,基于大模型理解用户需求,对知识点进行拆解;
-
检索阶段,面向大模型进行搜索排序优化,并将搜索返回的异构信息统一表示,送给大模型;
-
生成阶段,综合不同来源的信息做出判断,并基于大模型逻辑推理能力,解决信息冲突等问题,从而生成准确率高、时效性好的答案。
在国内的互联网大厂中,百度是靠搜索起家的,因此在搜索这件事上形成的技术积累,鲜有厂商能够与之一比。
做搜索积累的经验,成了百度独有的竞争优势,所以百度在RAG上表现出色,也就不难理解了。
2025,中国大模型的提速之年
DeepSeek-R1的出现,在国际舞台上标志着国产模型拥有了更多的话语权。
吴恩达也撰写了长文,肯定了国产模型的创新,并针对DeepSeek谈了他的看法。
吴恩达认为,国产模型和世界顶尖水平的差距越来越小,甚至某些方面和技术点出现了领先迹象。
并且DeepSeek发现了AI进步的新范式,通过算法的创新实现了模型能力的提升,摆脱了高端算力依赖。
另外,DeepSeek和OpenAI之间的30倍价差,正在加速基础模型的商品化。
按照吴恩达的总结继续推论下去,在这个前景之下,中国的市场和用户规模,在大模型进入应用阶段后,非常可期。
甚至能再次复制移动互联网时代,中国应用们在创新飞轮上的路径。
所以,DeepSeek不仅在外打出了名声,也点燃了国内厂商的斗志和信心。
毫无疑问,今年国内将诞生更多、更强大的模型,给全球网友带来更多的东方震撼。
最早在大模型上交卷的百度就透露,将在今年推出全新的文心5.0大模型。
所以2025,很可能是国产AI从追赶走向并驾齐驱,甚至可以期待超车的一年。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









