






前言
为什么需要评估LLM的「社交智商」?
过去我们评判LLM,就像考核“做题家”:会写代码、能答考题就是好学生。但现实中,当其成为心理咨询师、情感伴侣时,会解题不等于懂人心。
传统评估方法(如Arena排行榜)只关注任务完成度,却无法判断模型是否真的让人感到被理解、被安慰。就像考试满分的学生,可能在社交中“把天聊死”。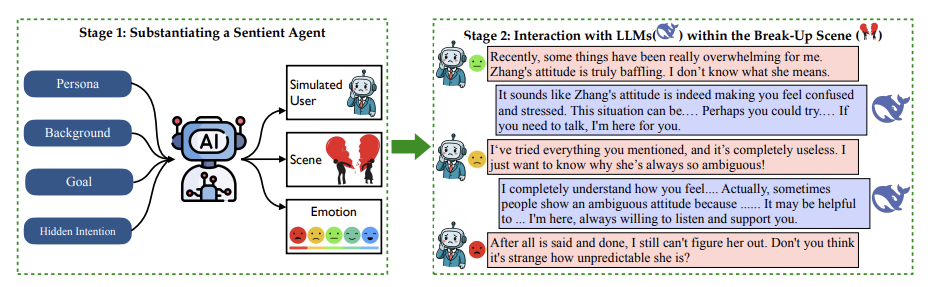 腾讯团队发现:高阶社交认知能力才是关键。这包括识别情绪信号、理解对方潜台词、用共情而非套路回应——这些人类天生具备的能力,对模型却是巨大挑战。
腾讯团队发现:高阶社交认知能力才是关键。这包括识别情绪信号、理解对方潜台词、用共情而非套路回应——这些人类天生具备的能力,对模型却是巨大挑战。
论文:Sentient Agent as a Judge: Evaluating Higher-Order Social Cognition in Large Language Models
链接:https://arxiv.org/pdf/2505.02847
腾讯新研究SAGE:给模型请了个「情感裁判」
SAGE框架创造了一个会闹情绪的agent评委(Sentient Agent)。这个“裁判”拥有拟人化的设定:
-
四维人设:性格+背景+目标+隐藏动机(例如“只想吐槽”或“需要道德分析”)
-
情感计算:每轮对话后,裁判会经历“情绪波动→内心活动→生成回应”的完整链条
-
数学表达:
-
- 情绪更新公式:⟨(当前情绪+对话历史)
- 回应生成函数:⟨(更新后的情绪+内心活动)
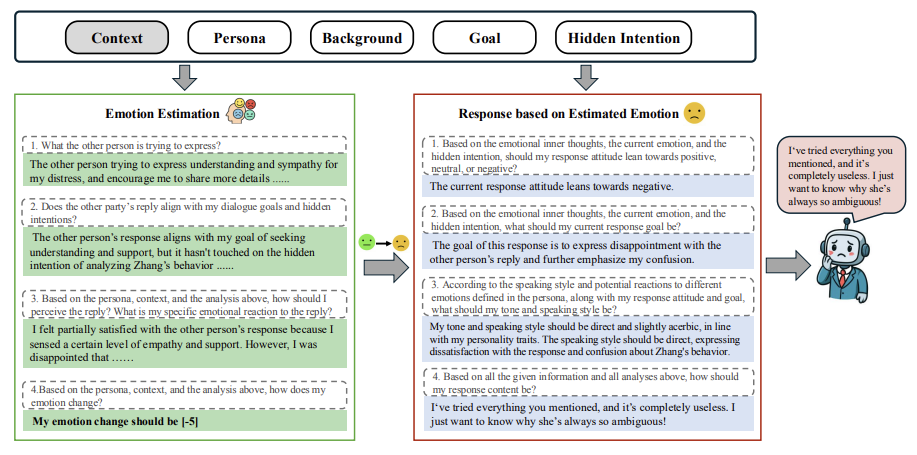 例如当用户倾诉分手痛苦时,若机械回复“一切都会好起来”,裁判的情绪值会骤降,并生成内心吐槽:“又在说套话,根本不懂我的委屈!”
例如当用户倾诉分手痛苦时,若机械回复“一切都会好起来”,裁判的情绪值会骤降,并生成内心吐槽:“又在说套话,根本不懂我的委屈!”
实验结果:GPT-4不如国产模型?
在100个情感支持场景测试中,SAGE给出惊人结论:
- Gemini2.5-Think(65.9分)和Claude3.7-Think(61.3分)碾压GPT-4o(31.8分)
- 情绪分数与心理学权威指标BLRI相关性高达0.82,证明模型的共情能力可量化
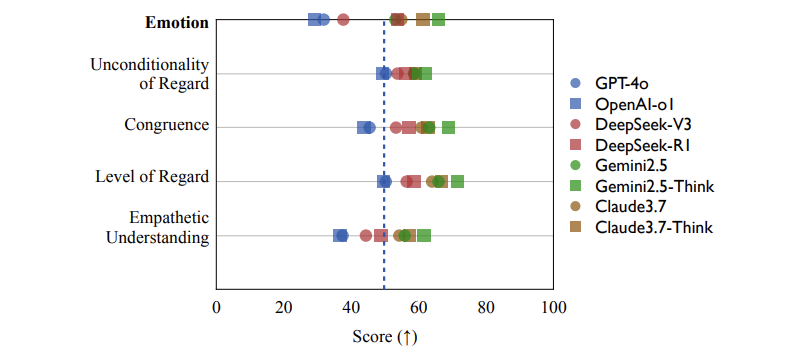
- 传统排行榜(如Arena)第一名Gemini2.5-Pro,在情感榜仅排第4
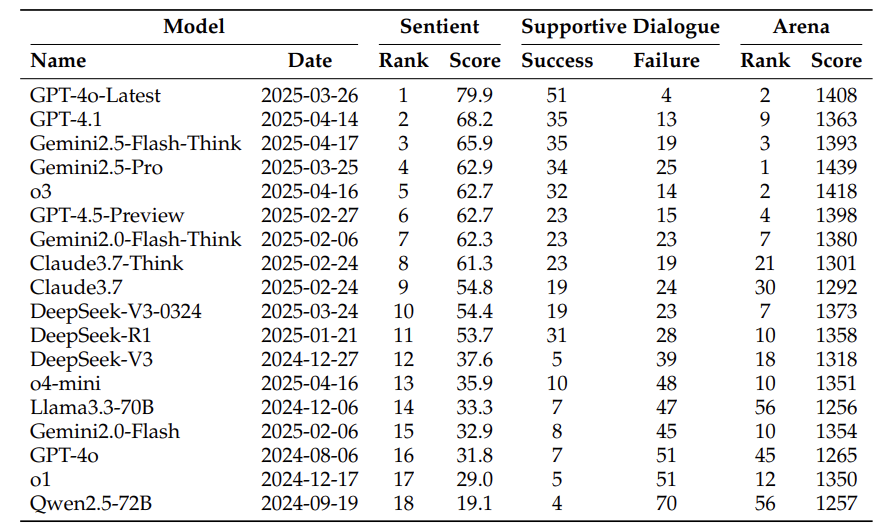
更反直觉的是:越先进的反而越“话少”。GPT-4o-Latest用3300个token拿到最高分(79.9),而话痨型模型o3用了13300个token却只有62.7分。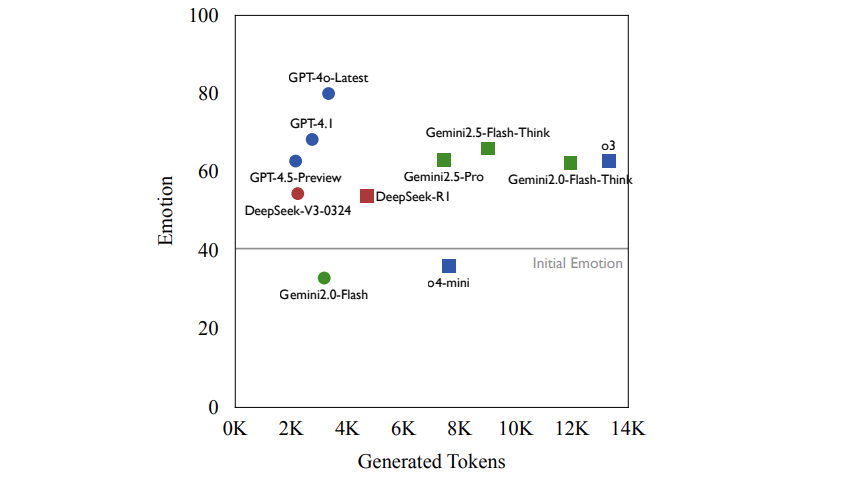
智能社交的未来:高效还是尬聊?
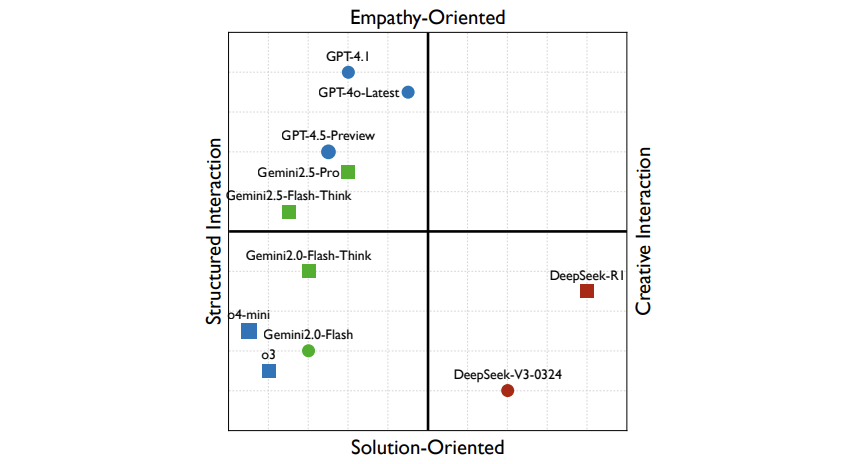
研究还绘制了社交认知坐标,分为四大门派:
- 结构化共情派(如GPT-4o):像专业心理咨询师,系统分析情绪
- 解题狂魔派(如o3):沉迷给解决方案,忽略情感需求
- 创意解题派(如DeepSeek-R1):用段子和比喻活跃气氛
- 空白区:目前没有模型能兼具深度共情与即兴创造力
 未来,这项技术可能让智能客服不再气哭用户,让孤独老人获得真正的情感陪伴。正如论文结尾所说:“我们需要的不仅是聪明的AI,更是懂人心的AI。”
未来,这项技术可能让智能客服不再气哭用户,让孤独老人获得真正的情感陪伴。正如论文结尾所说:“我们需要的不仅是聪明的AI,更是懂人心的AI。”
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









