






int len = bos.writtenBytes(); //@4
checkPayload(channel, len);
Bytes.int2bytes(len, header, 12); //@5
Step2:编码请求体(body),协议的设计,一般是基于 请求头部+请求体构成。
代码@1:对buffer做一个简单封装,返回ChannelBufferOutputStream实例。
代码@2:根据序列化器,将通道的URL进行序列化,变存入buffer中。
代码@3:根据请求类型,事件或请求对Request.getData()请求体进行编码,encodeEventData、encodeRequestData不同的编码器会重写该方法,下文详细看一下DubboCode的实现。
代码@4:最后得到bos的总长度,该长度等于 (header+body)的总长度,也就是一个完整请求包的长度。
代码@5:将包总长度写入到header的header[12-15]中。
从ExchangeCodec#encodeRequest这个方法可以得知,Dubbo的整体传输协议由下图所示:
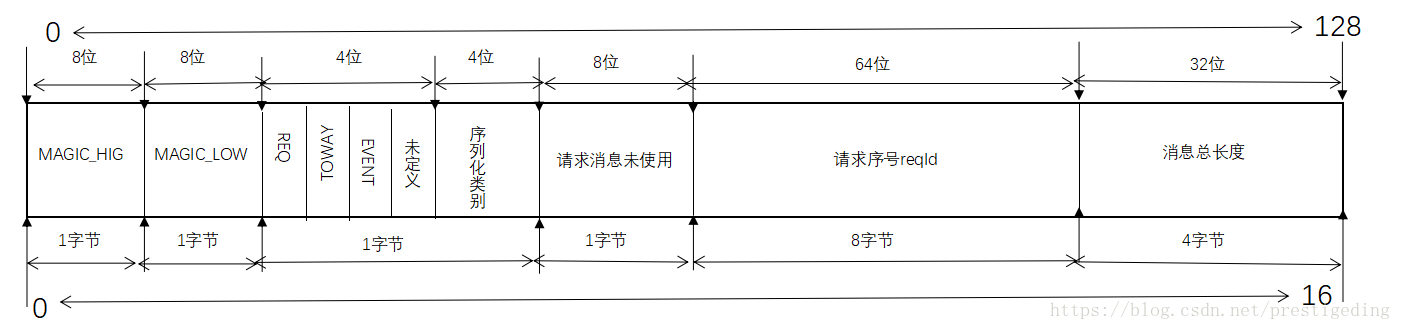
2.3 Dubbo协议体编码
2.3.1 Dubbo协议请求体(body)编码规则
在ExchangeCodec#encodeRequest中,将会调用encodeRequestData对body进行编码
protected void encodeRequestData(Channel channel, ObjectOutput out, Object data) throws IOException {
RpcInvocation inv = (RpcInvocation) data;
out.writeUTF(inv.getAttachment(Constants.DUBBO_VERSION_KEY, DUBBO_VERSION));
out.writeUTF(inv.getAttachment(Constants.PATH_KEY));
out.writeUTF(inv.getAttachment(Constants.VERSION_KEY));
out.writeUTF(inv.getMethodName());
out.writeUTF(ReflectUtils.getDesc(inv.getParameterTypes()));
Object[] args = inv.getArguments();
if (args != null)
for (int i = 0; i < args.length; i++) {
out.writeObject(encodeInvocationArgument(channel, inv, i));
}
out.writeObject(inv.getAttachments());
}
该方法,依次将 dubbo、服务path(interface name)、版本号、方法名、方法参数类型描述,参数值、附加属性(例如参数回调等,该部分会在服务调用相关章节重点分析)。上述内容,根据不同的序列化实现,其组织方式不同,当然,其基本组织方式(标记位、长度 、 具体内容),将在下节中重点分析序列化的实现。
2.3.2 Dubbo响应数据包编码规则
protected void encodeResponseData(Channel channel, ObjectOutput out, Object data) throws IOException {
Result result = (Result) data;
Throwable th = result.getException();
if (th == null) {
Object ret = result.getValue();
if (ret == null) {
out.writeByte(RESPONSE_NULL_VALUE);
} else {
out.writeByte(RESPONSE_VALUE);
out.writeObject(ret);
}
} else {
out.writeByte(RESPONSE_WITH_EXCEPTION);
out.writeObject(th);
}
}
1字节(请求结果),取值:RESPONSE_NULL_VALUE:表示空结果;RESPONSE_WITH_EXCEPTION:表示异常,RESPONSE_VALUE:正常响应。N字节的请求响应,使用readObject读取即可。
3、ExchangeCodec解码实现原理
ExchangeCodec#decode
public Object decode(Channel channel, ChannelBuffer buffer) throws IOException {
int readable = buffer.readableBytes();
byte[] header = new byte[Math.min(readable, HEADER_LENGTH)]; // @1
buffer.readBytes(header); // @2
return decode(channel, buffer, readable, header); // @3
}
代码@1:创建一个byte数组,其长度为 头部长度和可读字节数取最小值。
代码@2:读取指定字节到header中。
代码@3:调用decode方法尝试解码。
ExchangeCodec#decode
protected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header)
Step1:解释一下方法的参数:
-
Channel channel :网络通道
-
ChannelBuffer buffer : 通道读缓存区
-
int readable :可读字节数。
-
byte[] header :已读字节数,(尝试读取一个完整头部)
ExchangeCodec#decode
// check magic number.
if (readable > 0 && header[0] != MAGIC_HIGH
|| readable > 1 && header[1] != MAGIC_LOW) {
int length = header.length;
if (header.length < readable) {
header = Bytes.copyOf(header, readable);
buffer.readBytes(header, length, readable - length);
}
for (int i = 1; i < header.length - 1; i++) {
if (header[i] == MAGIC_HIGH && header[i + 1] == MAGIC_LOW) {
buffer.readerIndex(buffer.readerIndex() - header.length + i);
header = Bytes.copyOf(header, i);
break;
}
}
return super.decode(channel, buffer, readable, header);
}
Step2:检查魔数,判断是否是dubbo协议,如果不是dubbo协议,则调用父类的解码方法,例如telnet协议。
如果至少读取到一个字节,如果第一个字节与魔数的高位字节不相等或至少读取了两个字节,并且第二个字节与魔数的地位字节不相等,则认为不是 dubbo协议,则调用父类的解码方法,如果是其他协议的化,将剩余的可读字节从通道中读出,提交其父类解码。
ExchangeCodec#decode
// check length.
if (readable < HEADER_LENGTH) {
return DecodeResult.NEED_MORE_INPUT;
}
Step3:如果是dubbo协议,判断可读字节的长度是否大于协议头部的长度,如果可读字节小于头部字节,则跳过本次读事件处理,待读缓存区中更多的数据到达。
ExchangeCodec#decode
// get data length.
int len = Bytes.bytes2int(header, 12);
checkPayload(channel, len);
int tt = len + HEADER_LENGTH;
if (readable < tt) {
return DecodeResult.NEED_MORE_INPUT;
}
Step4:如果读取到一个完整的协议头,然后读取消息体长度,如果当前可读自己小于消息体+header的长度,返回NEED_MORE_INPUT,表示放弃本次解码,待更多数据到达缓冲区时再解码。
ExchangeCodec#decode
// limit input stream.
ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len); // @1
try {
return decodeBody(channel, is, header); // @2
} finally {
if (is.available() > 0) {
try {
if (logger.isWarnEnabled()) {
logger.warn("Skip input stream " + is.available());
}
StreamUtils.skipUnusedStream(is); // @3
} catch (IOException e) {
logger.warn(e.getMessage(), e);
}
}
}
代码@1:创建一个ChannelBufferInputStream,并限制最多只读取len长度的字节。
代码@2:调用decodeBody方法解码协议体。
代码@3:如果本次并未读取len个字节,则跳过这些字节,保证下一个包从正确的位置开始处理。
这个其实就是典型的网络编程(自定义协议)的解码实现。
由于本文只关注Dubbo协议的解码,故decodeBody方法的实现,请看DubboCodec#decodeBody。
3.1 DubboCodec#decodeBody 详解
byte flag = header[2], proto = (byte) (flag & SERIALIZATION_MASK);
Serialization s = CodecSupport.getSerialization(channel.getUrl(), proto);
// get request id.
long id = Bytes.bytes2long(header, 4);
Step1:根据协议头获取标记为(header[2])(根据协议可知,包含请求类型、序列化器)。
DubboCodec#decodeBody
if ((flag & FLAG_REQUEST) == 0) { // @1
// decode response.
Response res = new Response(id); // @2
if ((flag & FLAG_EVENT) != 0) {
res.setEvent(Response.HEARTBEAT_EVENT); // @3
}
// get status.
byte status = header[3]; // @4
res.setStatus(status);
if (status == Response.OK) {
try {
Object data;
if (res.isHeartbeat()) {
data = decodeHeartbeatData(channel, deserialize(s, channel.getUrl(), is));
} else if (res.isEvent()) { // @5
data = decodeEventData(channel, deserialize(s, channel.getUrl(), is));
} else {
DecodeableRpcResult result;
if (channel.getUrl().getParameter(
Constants.DECODE_IN_IO_THREAD_KEY,
Constants.DEFAULT_DECODE_IN_IO_THREAD)) { // @6
result = new DecodeableRpcResult(channel, res, is,
(Invocation) getRequestData(id), proto);
result.decode();
} else {
result = new DecodeableRpcResult(channel, res, // @7
new UnsafeByteArrayInputStream(readMessageData(is)),
(Invocation) getRequestData(id), proto);
}
data = result;
}
res.setResult(data);
} catch (Throwable t) {
if (log.isWarnEnabled()) {
log.warn("Decode response failed: " + t.getMessage(), t);
}
res.setStatus(Response.CLIENT_ERROR);
res.setErrorMessage(StringUtils.toString(t));
}
} else {
res.setErrorMessage(deserialize(s, channel.getUrl(), is).readUTF());
}
return res;
}
Step2:解码响应消息请求体。
代码@1:根据flag标记相应标记为,如果与FLAG_REQUEST进行逻辑与操作,为0说明不是请求类型,那对应的就是响应数据包。
代码@2:根据请求ID,构建响应结果。
代码@3:如果是事件类型。
代码@4:获取响应状态码。
代码@5:如果是心跳事件,则直接调用readObject完成解码即可。
代码@6:获取decode.in.io的配置值,默认为true,表示在IO线程中解码消息体,如果decode.in.io设置为false,则会在DecodeHanler中执行(受Dispatch事件派发模型影响)。
代码@7:不在IO线程池中完成解码操作,实现方式也就是不在io线程中调用DecodeableRpcInvocation#decode方法。
上述介绍了协议解码的经典实现流程,下文就不详细去探究具体针对dubbo协议进行解码,因为只要从一个完整的二进制流(ByteBuffer)按格式进行字节的读取,主要就是针对ByteBuffer API的应用。
其他协议,将在主流程分析完成后,再选择一两个进行介绍。
总目录展示
该笔记共八个节点(由浅入深),分为三大模块。
高性能。 秒杀涉及大量的并发读和并发写,因此支持高并发访问这点非常关键。该笔记将从设计数据的动静分离方案、热点的发现与隔离、请求的削峰与分层过滤、服务端的极致优化这4个方面重点介绍。
一致性。 秒杀中商品减库存的实现方式同样关键。可想而知,有限数量的商品在同一时刻被很多倍的请求同时来减库存,减库存又分为“拍下减库存”“付款减库存”以及预扣等几种,在大并发更新的过程中都要保证数据的准确性,其难度可想而知。因此,将用一个节点来专门讲解如何设计秒杀减库存方案。
高可用。 虽然介绍了很多极致的优化思路,但现实中总难免出现一些我们考虑不到的情况,所以要保证系统的高可用和正确性,还要设计一个PlanB来兜底,以便在最坏情况发生时仍然能够从容应对。笔记的最后,将带你思考可以从哪些环节来设计兜底方案。
篇幅有限,无法一个模块一个模块详细的展示(这些要点都收集在了这份《高并发秒杀顶级教程》里),麻烦各位转发一下(可以帮助更多的人看到哟!)


由于内容太多,这里只截取部分的内容。
数据的动静分离方案、热点的发现与隔离、请求的削峰与分层过滤、服务端的极致优化这4个方面重点介绍。
一致性。 秒杀中商品减库存的实现方式同样关键。可想而知,有限数量的商品在同一时刻被很多倍的请求同时来减库存,减库存又分为“拍下减库存”“付款减库存”以及预扣等几种,在大并发更新的过程中都要保证数据的准确性,其难度可想而知。因此,将用一个节点来专门讲解如何设计秒杀减库存方案。
高可用。 虽然介绍了很多极致的优化思路,但现实中总难免出现一些我们考虑不到的情况,所以要保证系统的高可用和正确性,还要设计一个PlanB来兜底,以便在最坏情况发生时仍然能够从容应对。笔记的最后,将带你思考可以从哪些环节来设计兜底方案。
篇幅有限,无法一个模块一个模块详细的展示(这些要点都收集在了这份《高并发秒杀顶级教程》里),麻烦各位转发一下(可以帮助更多的人看到哟!)
[外链图片转存中…(img-V8YXAGGI-1721880856272)]
[外链图片转存中…(img-uE3lHEXJ-1721880856272)]
由于内容太多,这里只截取部分的内容。















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









