






一、教程概述
近期,一本名为《Build a Large Language Model (From Scratch)》的教程在全网引起了广泛关注,其Github仓库的星标数已突破18K,显示出极高的热度和认可度。这本教程虽然目前还是英文版本且未正式出版,但已经凭借其详尽的内容和实用的指导,成为了许多对GPT大模型感兴趣的学习者的首选资料。

二、教程内容概览
该教程主要分为以下几个部分,每个部分都深入浅出地讲解了构建大语言模型(LLM)的关键知识和步骤:
-
理解大型语言模型
:
- 介绍LLM的基本概念、Transformer架构以及训练大型语言模型所需的基础知识。
- 帮助读者建立对LLM的宏观认识,为后续的学习打下坚实基础。
-
文本数据处理
:
- 详细讲解如何准备和处理用于训练LLM的文本数据。
- 包括数据收集、清洗、预处理等步骤,确保训练数据的质量和一致性。
-
注意力机制编程
:
- 深入探讨注意力机制的原理及其在LLM中的应用。
- 通过代码实现这些机制,让读者深入理解注意力机制如何提升模型的性能。
-
从零实现GPT模型
:
- 提供一步步的指导,帮助读者从头开始构建一个GPT模型。
- 通过实践,让读者掌握LLM的构建流程和关键技术。
-
无标签数据的预训练
:
- 讨论如何在没有标签的数据上进行预训练,使模型能够捕捉语言的复杂性和上下文关系。
- 这是提升模型泛化能力和表现的重要步骤。
-
模型微调
:
- 解释如何在特定任务或领域的数据上微调预训练的模型。
- 通过微调,可以进一步提升模型在特定应用中的表现。
三、教程特点
- 实践性强:教程主要使用PyTorch框架,通过大量的代码示例和动手实践,帮助读者掌握LLM的构建技术。
- 资源友好:考虑到许多学习者的算力有限,教程中的所有操作都设计为可以在笔记本上实现,无需高性能计算资源。
- 内容丰富:教程不仅涵盖了LLM的理论知识,还提供了详尽的实践指导和代码实现,让读者能够全面了解LLM的构建过程。
四、总结
《Build a Large Language Model (From Scratch)》这本教程以其详尽的内容、实用的指导和广泛的认可度,成为了当前构建大语言模型(LLM)的热门学习资料。无论是对于初学者还是有一定基础的学习者来说,这本教程都是一本不可多得的宝贵资源。通过学习这本教程,读者可以掌握LLM的构建技术,为未来的研究和应用打下坚实的基础。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
资源分享

大模型AGI学习包


资料目录
- 成长路线图&学习规划
- 配套视频教程
- 实战LLM
- 人工智能比赛资料
- AI人工智能必读书单
- 面试题合集
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
3.LLM
大家最喜欢也是最关心的LLM(大语言模型)
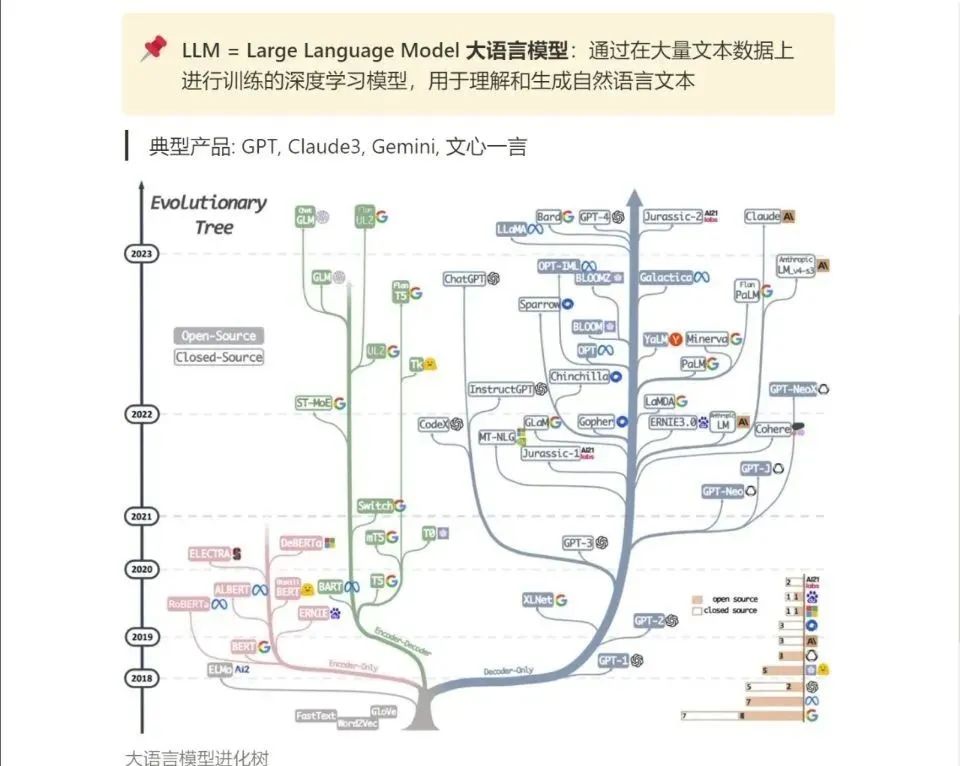
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!















 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









