







7月23日晚,Meta正式推出了最新的开源大模型系列Llama 3.1,进一步缩小了开源模型与闭源模型之间的差距。Llama 3.1系列包括8B、70B和405B三个参数规模,其中Llama 3.1-405B参数的模型在多个基准测试中超越了OpenAI的GPT-4o,与Claude 3.5 Sonnet等领先的闭源模型相媲美。

模型规模与性能提升
这次发布的Llama 3.1模型大小大约820GB,包含有8B、70B和405B三种参数规模的模型。其中,8B和70B是对5月份发布模型的升级版本,将长文支持提升到了128K tokens。Llama 3.1在基准测试中展现了出色的性能,即使是70B的模型,也在多项测试中超越了GPT-4o。
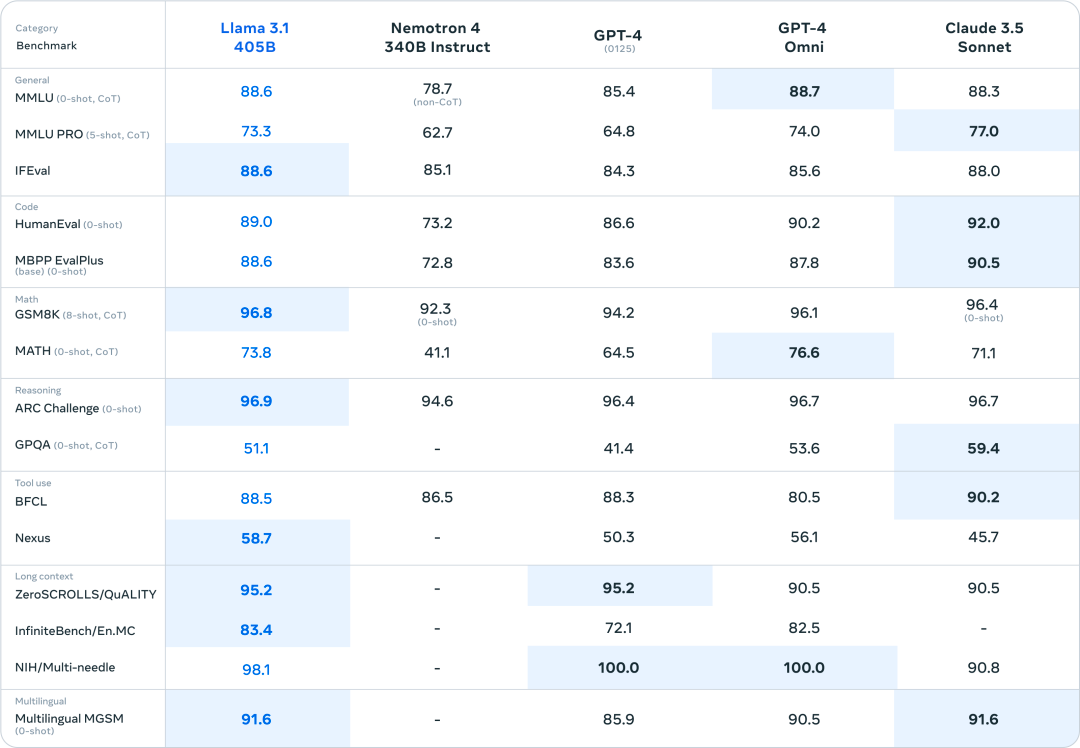
Llama 3.1-405B版本的性能尤为出色。在MMLU Pro数学基准上,它以73.3%的成绩领先所有大模型。此外,在GPQA(研究生水平的专业知识和推理)、DROP(阅读理解)、MGSM(多语言数学)、HumanEval(编程)和BBH(知识评估)等多个基准测试中,405B版本的表现与GPT-4o不相上下,甚至在某些方面略胜一筹。
如基准测试所示,Meta Llama 3.1在GSM8K、Hellaswag、BoolQ、MMLU-humanities、MMLU-other、MMLU-stem和Winograd等多项测试中均优于GPT-4o。
但值得注意的是,HumanEval和MMLU-social sciences方面却落后于GPT-4o。可见,70B的参数量再往上扩展,收益已经不再显著。在大模型之家看来,未来,AI行业也许并不不需要15万亿这么多tokens来进行预训练,未来将是高质量合成数据和后期训练的世界。
累计3930万GPU小时的计算时间
Llama 3.1在多个方面都有显著提升:上下文长度增加到128K tokens,大幅提升了模型处理长文本的能力。这对于需要处理复杂文档和长篇对话的应用非常重要。支持8种语言的多语言输入输出,包括英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语,扩展了模型在国际化场景中的应用范围。预训练数据量达到15万亿tokens,确保了模型知识的时效性和广度。采用分组查询注意力(GQA)技术,提高了推理的可扩展性,增强了模型在处理复杂任务时的效率。

**Meta的训练细节显示,模型在H100-80GB GPU上训练,累计使用了3930万GPU小时的计算时间。**这不仅体现了Meta在硬件资源上的投入,也反映了团队在优化训练过程中的技术实力。值得注意的是,Meta强调自2020年以来一直保持净零温室气体排放,并且100%使用可再生能源。Meta的这一承诺不仅展示了企业的环保意识,也为AI行业树立了一个新的标准。
开源模型的“历史性时刻”
Meta创始人兼CEO扎克伯格在官网他表示,Llama 3.1将成为行业的一个转折点,越来越多的开发人员将转向使用开源模型,开源AI是未来的发展方向。英伟达高级研究科学家Jim Fan在X上发文祝贺Meta团队,称这是一个“具有历史意义的时刻”。

此外,马斯克也盛赞扎克伯格,认为他理应因开源得到赞誉,并表示Meta会成为开源大模型界的标杆。
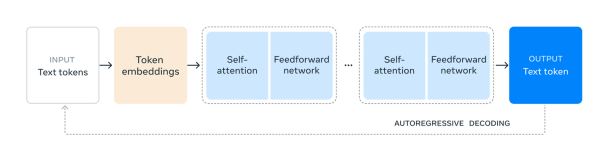
尽管Llama 3.1表现出色,但这并不意味着它已经超越了GPT-4o。要知道,GPT-4o是在GPT-4的基础上经过两代优化(GPT-4 Turbo和GPT-4o)才达到当前的水平,其激活参数远小于405B的规模,是速度和性能的代表。
但不可否认的是,Meta的开源策略不仅为开发者和企业提供了一个强大的工具,也推动了AI研究和应用的普及。这可以让学术界深入研究非常深层次的Transformer在幻觉、推理和跨语言理解等场景下的工作机制。因为Llama 3.1作为一个稠密模型,比MoE在研究上更有普适意义,且可能是目前开源的最强模型,即使有更强的闭源模型,学术界也无法研究。
此外,Meta在模型卡中详细列出了安全考量,包括CBRNE(化学、生物、放射性、核和爆炸材料)有用性、儿童安全和网络攻击等方面的风险评估。这些安全考量体现了Meta对模型应用潜在风险的高度重视,确保模型在实际应用中不会引发不可控的问题。Meta强调,Llama 3.1并非设计为单独部署,而应作为整个AI系统的一部分,并配备额外的”安全护栏”。开发者在使用时需要特别注意工具使用和多语言输出的潜在风险,并进行充分的安全测试和微调。
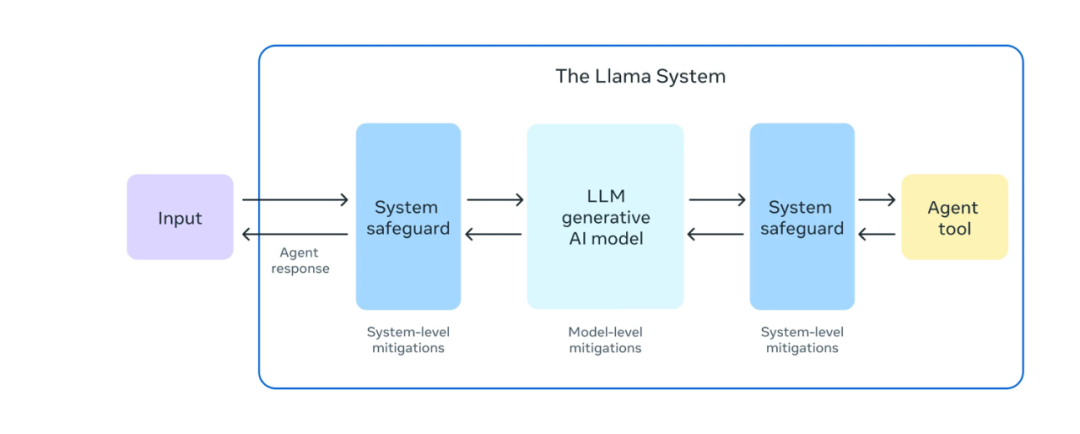
Meta还更新了开源许可,允许开发者首次使用Llama模型(包括405B)的输出来改进其他模型。这为开发者提供了更大的灵活性,使他们能够在现有基础上进行创新和优化。Meta计划将图像、视频和语音功能整合到Llama 3中,使模型能够识别图像和视频,并通过语音进行交互。这一功能目前仍在开发中,但已经展示了未来应用的巨大潜力。Meta表示,截至目前,所有Llama版本的总下载量已超过3亿次。
“开源人工智能代表着世界最好的机会,”扎克伯格表示,利用这项技术可以创造最大的经济机会和安全保障。这一表态再次凸显了Meta在推动开源AI领域的坚定立场和长远目标。Meta认为,开源能够促进创新、降低成本、提高安全性。对开发者来说,利用开源可以训练、微调和蒸馏自己的模型,每个组织都有不同的需求,使用不同尺寸的模型来满足这些需求,并通过特定数据进行训练或微调。同时,开发者可以不被锁定在封闭供应商中,保护数据安全。“开源软件往往更安全,因为它的开发更加透明,可以被广泛审查。”扎克伯格认为。
大模型之家观点
随着Llama 3.1的正式发布,我们可能会看到更多基于它的创新应用和研究成果。Meta的这一突破性进展不仅在性能上接近或超越了闭源模型,更重要的是,它为开发者和研究人员提供了一个可以自由使用和定制的强大工具。这可能会加速AI应用的创新和普及,让更多人受益于先进的AI技术。
Llama 3.1的发布无疑是开源AI领域的一个里程碑事件。它不仅缩小了开源与闭源模型之间的差距,更为AI的民主化和创新带来了新的可能。Topology CEO Aidan McLau惊呼,如果测试结果属实,Llama 3.1将成为”世界上最好的模型”,而且”每个人都可调”。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









