







在数据的浩瀚海洋里,我们常常会遇到这样一类需求:从大量数据中找出最大或最小的前 K 个元素,这就是 TopK 问题。比如在搜索引擎中,要从海量网页里筛选出与用户查询最相关的前 K 个结果;在电商平台,需统计出热销商品的前 K 名。解决 TopK 问题有多种方法,这里着重介绍快速选择法与堆法 。

欢迎拜访:羑悻的小杀马特.-CSDN博客本篇主题:
深度剖析TOP_K问题解答的快速选择法与堆法制作日期:2025.05.21
隶属专栏:美妙的算法世界
目录
那下面我们就介绍一下最经典的这两种方法(也是很常用的):
一.快速选择法:
1.1快选介绍:
快速选择算法是基于快速排序的思想设计的。快速排序大家或许有所耳闻,它采用分治策略,通过选择一个基准元素,把数组分为两部分,左边部分的元素都小于等于基准元素,右边部分的元素都大于等于基准元素,然后递归地对左右两部分进行排序。
快速选择算法借鉴了这种划分思路,但它并不对整个数组进行排序,而只关注我们所需要的第 K 大(或小)元素所在的那部分。
选择基准元素:从数组中随机挑选一个元素作为基准(pivot)。随机选择基准元素是为了尽量避免最坏情况,要是每次都选到最大或最小元素当基准,算法效率会大打折扣。
分区操作:以基准元素为标准,将数组划分为两个子数组。遍历数组,把小于等于基准的元素放在左边,大于基准的元素放在右边。经过这一步,基准元素就处于它在有序数组中的正确位置了。
判断基准位置与 K 的关系:
如果基准元素的位置正好是第 K 大(或小)元素的位置,那我们运气很好,直接找到了目标元素。
若基准元素的位置大于第 K 大(或小)元素应在的位置,说明目标元素在基准元素的左边,我们就在左边子数组中继续查找。
要是基准元素的位置小于第 K 大(或小)元素应在的位置,那就去右边子数组继找。
递归查找:不断重复上述过程,持续缩小查找范围,直到找到第 K 大(或小)元素。
简单来说就是变型特化版的快排;我们就只需要排其中一个区间(k所在的那个);其次就是加上三指针维护的三个区域(小于key,等于key;大于key)最后当区间数递归成一个那么就是最后答案直接return。

例如,有数组 [3, 2, 1, 5, 6, 4],要找第 2 大的元素。假设第一次随机选到的基准元素是 3,经过分区后数组变为 [2, 1, 3, 5, 6, 4],此时 3 在第 3 个位置,而我们要找的是第 2 大元素,所以在右边子数组 [5, 6, 4] 中继续找。再进行一轮分区操作,就能找到第 2 大的元素 5。
1.2时间与空间复杂度分析:
1.2.1时间复杂度:
平均情况:在平均情况下,每次分区操作都能将问题规模大致缩小一半。设 T(N) 表示处理规模为 N 的数据集的时间复杂度,则有 T(N)=T(N/2)+O(N)。根据主定理,可解得平均时间复杂度为 O(N)。这是因为每次分区操作的时间复杂度为 O(N),而每次递归调用的问题规模大致减半。
最坏情况:在最坏情况下,每次分区操作都极不均匀,例如数据集已经有序,且每次都选择第一个或最后一个元素作为基准元素。此时,每次分区只能将问题规模缩小 1,时间复杂度会退化为 O(N2)。设 T(N) 表示处理规模为 N 的数据集的时间复杂度,则有 T(N)=T(N−1)+O(N),解得 T(N)=O(N2)。
1.2.2空间复杂度:
递归调用栈的空间复杂度为 O(logN)。这是因为每次递归调用都将问题规模大致缩小一半,递归的深度为 logN。
小结下:
快速选择算法平均时间复杂度为 O (N) ,在处理大规模数据时,效率相当高。不过,最坏情况下时间复杂度会退化到 O (N²) ,好在随机选择基准元素能大大降低这种情况出现的概率。
1.3 代码实现快选法:
我们主要实现top第k个(可前可后);这里如果是前k个或者后k个的就需要多次调用咯(但是这种方法大多只适用于数组数据;对于一些变型的(比如比较方式多种)那么还是建议选堆法的):
top第k 大:
int Qsort(vector<int>& nums,int left,int right,int k){
int key=nums[rand()%(right-left+1)+left];//保证下面落在区间内(这里+left是为了比如[4,6],这总情况能跳进区间,而不单单是left==0的情况)
if(right==left)return key;//处理
//使得中间区域排好,保证左边小于它,右边大于它:
int l=left-1,r=right+1;//保持原来的边界不变
for(int i=left;i<r;){
if(nums[i]>key) swap(nums[--r],nums[i]);
else if(nums[i]==key) i++;
else swap(nums[++l],nums[i++]);
}
//判断k所落在的区域,完成递归:
int a=l-left+1,b=r-l-1,c=right-r+1;
if(c>=k) return Qsort(nums,r,right,k);
else if(b+c>=k) return key;
else return Qsort(nums,left,l,k-b-c);
}
int findKthLargest(vector<int>& nums, int k) {
srand((unsigned int)time(0));//start random
return Qsort(nums,0,nums.size()-1,k);
}
top 第k小:
int Qsort(vector<int>& nums,int left,int right,int k){
int key=nums[rand()%(right-left+1)+left];//保证下面落在区间内(这里+left是为了比如[4,6],这总情况能跳进区间,而不单单是left==0的情况)
if(right==left)return key;//处理
//使得中间区域排好,保证左边小于它,右边大于它:
int l=left-1,r=right+1;//保持原来的边界不变
for(int i=left;i<r;){
if(nums[i]>key) swap(nums[--r],nums[i]);
else if(nums[i]==key) i++;
else swap(nums[++l],nums[i++]);
}
//判断k所落在的区域,完成递归:
int a=l-left+1,b=r-l-1,c=right-r+1;
if(a>=k) return Qsort(nums,left,l,k);
else if(a+b>=k) return key;
else return Qsort(nums,r,right,k-a-b);
}
int findKthLargest(vector<int>& nums, int k) {
srand((unsigned int)time(0));//start random
return Qsort(nums,0,nums.size()-1,k);
}
对于前k或者后k这里就不写了;只不过是多次多次调用罢了。
当然了,这里也有很多细节处理:
比如:
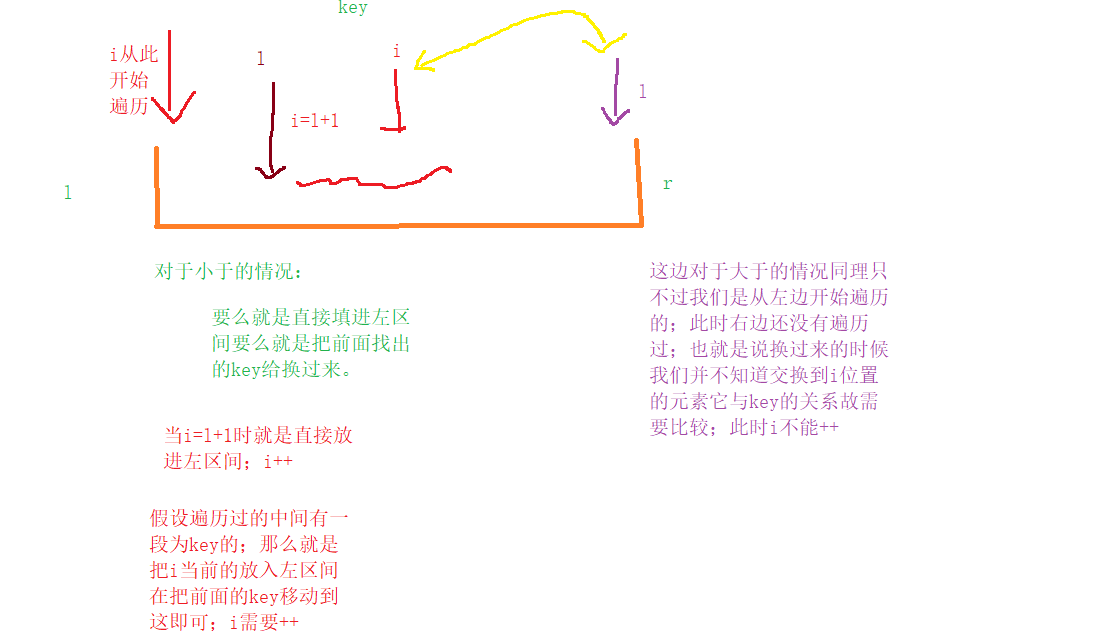
①三指针划分区域的时候;需要注意的就是i的++;然而左边不会出错;容易出错的就是右边了;因为如果x大于key那么就需要于右边的元素交换但是右边的没有遍历过呢因此这个位置i还要判断;故不++;如果换到左边;那么因为左边的元素都遍历过了故i直接可以++(这里换来的要么是自己与自己换;要么就是中间区域有很多key,又把key换到这了;因此是不影响的)。
②其次就是为了避免每次选最大或者最小导致时间复杂度退化成O(N^2)(此时选范围相当于只能剔除一个数据这样-->就类似两层for循环了)-->这里随机选key降低概率。
③再者就是寻找k所在区域一定要仔细。

1.4快选优缺点:
1.4.1优点:
平均效率高:平均时间复杂度为 (O(N)),在处理大规模数据集时效率较高。与堆法的 (O(NlogK)) 相比,当 K 接近 N 时,快速选择法的优势更加明显。
原地操作:快速选择法可以在原数据集上进行操作,不需要额外的存储空间,空间复杂度较低。
1.4.2缺点:
最坏情况性能差:最坏情况下时间复杂度为 \(O(N^2)\),性能不稳定。为了避免最坏情况的发生,可以采用随机选择基准元素的方法,这样可以使算法的性能更加接近平均情况。
实现复杂度较高:快速选择法的实现相对复杂,需要正确处理分区操作和递归调用,容易出现错误
1.5应用场景:
数据挖掘:在数据挖掘中,需要从大量的数据中找出前 K 个异常值或重要特征。可以使用快速选择法快速定位这些值。
算法竞赛:在算法竞赛中,快速选择法是解决 TopK 问题的常用方法之一,因为它在平均情况下的时间复杂度较低。
二·堆法:
2.1堆法介绍:
何为堆:
堆是一种特殊的完全二叉树结构,分为大顶堆和小顶堆。大顶堆中每个节点的值都大于或等于其子节点的值,堆顶是整个堆中的最大值;小顶堆则相反,每个节点的值都小于或等于其子节点的值,堆顶是最小值。
那么堆法如何解决我们上述的top k问题?
求前 K 大元素:使用小顶堆。先把数组的前 K 个元素放入小顶堆中,此时堆顶是这 K 个元素中的最小值。接着遍历数组剩下的元素,如果当前元素大于堆顶元素,就把堆顶元素替换为当前元素,然后调整堆,维持小顶堆的性质。遍历完整个数组后,堆里的 K 个元素就是前 K 大的元素。因为小顶堆保证了堆顶是当前堆中最小的元素,只要新元素比堆顶大,就替换堆顶,最终留下的就是最大的那些。
求前 K 小元素:使用大顶堆。先将前 K 个元素构建成大顶堆,堆顶是这 K 个元素中的最大值。之后遍历剩余元素,若当前元素小于堆顶元素,就替换堆顶并重新调整堆。遍历结束,堆里的 K 个元素就是前 K 小的元素,原因是大顶堆保证堆顶是最大的,新元素比堆顶小就替换,最后堆中剩下的就是最小的那些。
简单来说还是应用大(top前k小)小堆(top前k大)性质;维护一个k容量的堆;不足k个就都进来;满足时和堆头进行一定比较符合要求才进入;并pop掉top;最后维护的一定是这k个。(为什么?因为每次只要能进这个k容量的堆;那么它必然符合的要求足够把原先堆顶的数给取代;可能它作为堆顶或者调整后有其他作为堆顶;以此类推,结论必然成立。)
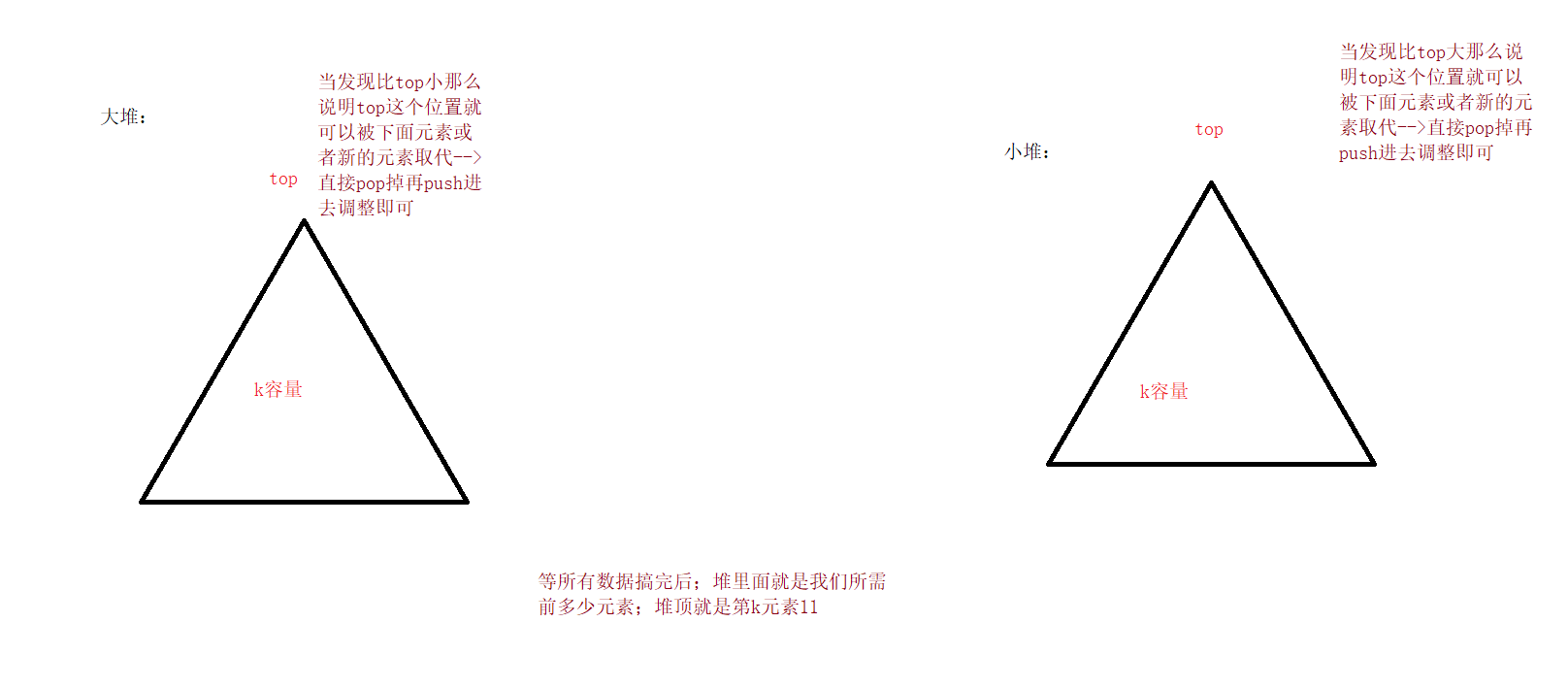
比如还是数组 [3, 2, 1, 5, 6, 4],要找前 2 大的元素。先把 [3, 2] 放入小顶堆,此时堆顶是 2。接着遍历到 1,1 小于堆顶 2,不做处理;遍历到 5,5 大于堆顶 2,替换堆顶并调整堆,此时堆为 [3, 5];再遍历到 6,6 大于堆顶 3,替换堆顶调整堆,堆变为 [5, 6];最后遍历到 4,4 小于堆顶 5,不做处理。最终堆里的 [5, 6] 就是前 2 大的元素。
2.2时间与空间复杂度分析:
2.2.1时间复杂度:
初始化堆:将前 K 个元素构建成堆的时间复杂度为 (O(K))。这是因为构建堆的过程是从最后一个非叶子节点开始,依次向上调整每个节点,总共需要调整的节点数约为 (K/2),每次调整的时间复杂度为常数级,所以整体时间复杂度为 (O(K))。
遍历剩余元素:从第 K + 1 个元素开始遍历,对于每个元素,若需要替换堆顶元素并调整堆,时间复杂度为 (O(logK))。因为堆是一个完全二叉树,调整堆的过程是沿着树的路径进行的,树的高度为 logK。总共需要遍历 (N - K) 个元素,所以这部分的时间复杂度为 (O((N - K)logK))。
综合起来,总的时间复杂度为 (O(K+(N - K)logK))。当 N 远大于 K 时,可近似为 (O(NlogK))。
2.2.2空间复杂度:
需要维护一个大小为 K 的堆来存储当前的前 K 大(或小)元素,因此空间复杂度为 (O(K))。
小结一下:
堆法的时间复杂度为 O (N log K) ,无论数据分布如何,表现都较为稳定。并且,它不需要对整个数组进行排序,在处理海量数据时,内存占用也比较少 。
2.3代码实现堆法:
根据我们上述的堆法介绍来实现:
top 前k大(如果是第k个直接返回top即可):
// 求前 K 大元素
std::vector<int> topK_Largest(const std::vector<int>& nums, int k) {
// 使用小顶堆
std::priority_queue<int, std::vector<int>, std::greater<int>> minHeap;
// 先将前 K 个元素放入小顶堆
for (int i = 0; i < k; ++i) {
minHeap.push(nums[i]);
}
// 遍历剩余元素
for (size_t i = k; i < nums.size(); ++i) {
if (nums[i] > minHeap.top()) {
// 若当前元素大于堆顶元素,替换堆顶元素
minHeap.pop();
minHeap.push(nums[i]);
}
}
// 将堆中的元素存储到结果向量中
std::vector<int> result;
while (!minHeap.empty()) {
result.push_back(minHeap.top());
minHeap.pop();
}
return result;
}top 前k小(如果是第k个直接返回top即可):
// 求前 K 小元素
std::vector<int> topK_Smallest(const std::vector<int>& nums, int k) {
// 使用大顶堆
std::priority_queue<int> maxHeap;
// 先将前 K 个元素放入大顶堆
for (int i = 0; i < k; ++i) {
maxHeap.push(nums[i]);
}
// 遍历剩余元素
for (size_t i = k; i < nums.size(); ++i) {
if (nums[i] < maxHeap.top()) {
// 若当前元素小于堆顶元素,替换堆顶元素
maxHeap.pop();
maxHeap.push(nums[i]);
}
}
// 将堆中的元素存储到结果向量中
std::vector<int> result;
while (!maxHeap.empty()) {
result.push_back(maxHeap.top());
maxHeap.pop();
}
// 反转结果向量,使其从小到大排序
std::reverse(result.begin(), result.end());
return result;
}
这里我们只需要注意下返回的result里面的元素是如何排列的即可;根据需求进行调整。
2.4堆法优缺点:
2.4.1优点:
适合大规模数据:对于大规模数据集,堆法不需要将整个数据集加载到内存中排序,只需要维护一个大小为 K 的堆,空间效率高。例如,在处理海量日志数据时,我们只需要关注其中最大的 K 个值,使用堆法可以在有限的内存下完成任务。
稳定性好:堆法的时间复杂度相对稳定,不受数据分布的影响。无论数据是有序、无序还是部分有序,其时间复杂度都能保持在 (O(NlogK)) 左右。
2.4.2缺点:
小规模数据不占优:对于小规模数据集,排序算法(如快速排序)可能更加高效。因为堆法需要额外的堆操作开销,而小规模数据排序的时间复杂度本身就较低,使用堆法反而会增加额外的计算量。
输出无序:堆法得到的前 K 个元素在堆中是无序的。如果需要有序输出,还需要额外的排序操作。
2.5 应用场景:
推荐系统:在推荐系统中,需要从大量的物品中找出用户可能感兴趣的前 K 个物品。可以根据用户的历史行为数据计算每个物品的推荐得分,然后使用堆法找出得分最高的 K 个物品。
搜索引擎:搜索引擎在搜索结果排序时,需要从大量的网页中找出与用户查询最相关的前 K 个网页。可以使用堆法根据网页的相关性得分进行筛选。
三·堆法与快选法对比:
快速选择法平均情况下效率极高,时间复杂度低至 O (N),在大数据量且对时间要求苛刻的场景中表现出色,不过最坏情况性能会变差。堆法则胜在稳定性,无论数据如何分布,时间复杂度都稳定在 O (N log K),而且它可以在数据源源不断到来的情况下动态维护 TopK,不需要一次性加载所有数据 。
在实际应用中,如果数据量较小,对时间复杂度要求不那么极致,或者不确定数据分布情况,堆法是个稳妥的选择;要是数据量巨大,且能接受一定概率的最坏情况,快速选择法往往能带来更优的性能 ;但是如果数据占空间特别大;比如内存中根本存不下或者数据是动态插入的;需要及时调整这个k(随时可能用到)来维护的时候就选堆。当然了;这两种法选哪个都是根据具体情况而言(取其精华去其糟粕而已)。也就是我们根据它在时间复杂度和空间复杂度上的优势来具体选择。
四.top K 问题例题:
下面我们列出几道关于top第k个或者前k个元素的习题(包含变型习题等);但终归还是上面top k的思路;虽然大多只是top 前k大(堆来说就是小堆);当top前k小就改大堆;对于快选法只需稍微调整进行qsort的区域即可;然而如果我们top第k个还是简单的;如果是top前k个呢?
对于堆法:就要一次出堆(取堆顶)然后放入数组(倒序无需reverse)反之就要reverse一下就好;而快选法呢;因为它的原理就是为了精选出第k个;因此我们只好把这个前1~k个全部精选出来放入数组即可;不过建议这样还是可以改成选择堆法的。
下面来看一下对这两种方法基本思路做法以及变型的问法(这里就需要我们的堆来解决了):
1.数组中的第k最大元素(直接快速选择):
题目传送门: 215. 数组中的第K个最大元素 - 力扣(LeetCode)
这边就直接是快选法的模版直接套上去即可:
//思路:快速选择法(三指针三块快排+选择区间进入递归):首先划分三块区域,我们已经保证了左区域都是小于中间区域,右区域都是大于中间区域,然后只需要判断k个落在
//那个区间(注意从后往前来的,因为第k大),如果落在中间则直接返回key即可,如果是左边则注意k变化前去后中区间长度然后递归,如果是右边区间则直接递归即可。
//这里有个细节的不同于找k最小的那道题,这里要么从中间区域返回了要么left==right就直接返回而不会出现
class Solution {
public:
int Qsort(vector<int>& nums,int left,int right,int k){
int key=nums[rand()%(right-left+1)+left];//保证下面落在区间内(这里+left是为了比如[4,6],这总情况能跳进区间,而不单单是left==0的情况)
if(right==left)return key;//处理
//使得中间区域排好,保证左边小于它,右边大于它:
int l=left-1,r=right+1;//保持原来的边界不变
for(int i=left;i<r;){
if(nums[i]>key) swap(nums[--r],nums[i]);
else if(nums[i]==key) i++;
else swap(nums[++l],nums[i++]);
}
//判断k所落在的区域,完成递归:
int a=l-left+1,b=r-l-1,c=right-r+1;
if(c>=k) return Qsort(nums,r,right,k);
else if(b+c>=k) return key;
else return Qsort(nums,left,l,k-b-c);
}
int findKthLargest(vector<int>& nums, int k) {
srand((unsigned int)time(0));//start random
return Qsort(nums,0,nums.size()-1,k);
}
};2.数据流中的第k大元素(直接堆法):

题目传送门: 703. 数据流中的第 K 大元素 - 力扣(LeetCode)
这里直接维护一个小堆即可;需要就返回top:
class KthLargest {
public:
//小堆原则:
priority_queue<int,vector<int>,greater<int>> pq;
int _k;
KthLargest(int k, vector<int>& nums) {
_k=k;
for(auto a:nums){
add(a);
}
}
int add(int val) {
if(pq.size()<_k) pq.push(val);
else if(pq.top()<val){
pq.pop();
pq.push(val);
}
return pq.top();
}
};
/**
* Your KthLargest object will be instantiated and called as such:
* KthLargest* obj = new KthLargest(k, nums);
* int param_1 = obj->add(val);
*/上面的两题都是直接求最大的第k个;如果是最小直接按照上面说的变一下堆的类型或者判区间方式即可就可以;
下面我们讲述几道特殊比较规则的top k问题以及返回前k个大(对前小k只需调整大堆即可);一般我们还是用堆的方法(比快选法方便)来解决即可:
3.前k个高频元素(堆法):

题目传送门: 347. 前 K 个高频元素 - 力扣(LeetCode)
class Solution {
public:
//小堆+hash绑定+重写排序规则
typedef pair<int,int> RII;
vector<int>ret;
vector<int> topKFrequent(vector<int>& nums, int k) {
map<int,int>hash;
for(auto a:nums) hash[a]++;
auto com=[&](RII a,RII b){return a.second>b.second;};
priority_queue<RII,vector<RII>,decltype(com)>pq(com);
for(auto a:hash){
if(pq.size()<k) pq.push(a);
else if(pq.top().second<a.second){
pq.pop();
pq.push(a);
}
}
while(!pq.empty()){
auto [x,y]=pq.top();
ret.push_back(x);
pq.pop();
}
reverse(ret.begin(),ret.end());
return ret;
}
};后序返回的时候不要忘记逆序一下即可。
4.前k个高频词汇(堆法):

题目传送门:692. 前K个高频单词 - 力扣(LeetCode)
//优队解法:
vector<string>tmp;
vector<string> topKFrequent(vector<string>& words, int k) {
auto g=[&](const pair<string,int> &x,const pair<string,int> &y){
return x.second>y.second|| (x.second==y.second&&x.first<y.first);
};
priority_queue<pair<string,int>,vector<pair<string,int>>,decltype(g)>pq(g);
//完成映射绑定:
map<string,int>hash;
for(auto a:words) hash[a]++;
//维护个数为k的堆(int小堆 string 大堆 )
for(auto a:hash){
if(pq.size()<k) pq.push(a);
else if(g(a,pq.top())){//取代原则
pq.pop();
pq.push(a);
}
}
//翻转得到答案:
while(!pq.empty()){
tmp.push_back(pq.top().first);
pq.pop();
}
reverse(tmp.begin(),tmp.end());
return tmp;
}这里就先列举这麽多;对于第k小;前k小;第k大;前k大;我们都可以使用快选法或者堆法来完成;但是有的题目有变形;就要根据具体情况来选择了。
五·本篇小结:
对于topk问题其实有很多排序都是可以解决的;但是比较经典优秀的还是本篇的快速选择法以及堆法;topk又分为top第k大;第k小;以及top前k大;top前k小;以及相关变型比较的top问题;我们这里选择还是根据上面总结的各自优缺点总并结合自己的目的总和来选择即可;但是这里对于变型top问题例如3 4 两题一般还是堆来说比较简单(快选可以实现就是比较麻烦点);总之这两种经典topk问题都要掌握;使用的时候才能正确应对。


















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











