






0.背景介绍
本项目将演示如何通过小样本样本进行模型微调,快速且准确抽取快递单中的目的地、出发地、时间、打车费用等内容,形成结构化信息。辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。
数据集情况:
waybill.jsonl文件是快递单信息数据集:
{“id”: 57, “text”: “昌胜远黑龙江省哈尔滨市南岗区宽桥街28号18618391296”, “relations”: [], “entities”: {“id”: 111, “start_offset”: 0, “end_offset”: 3, “label”: “姓名”}, {“id”: 112, “start_offset”: 3, “end_offset”: 7, “label”: “省份”}, {“id”: 113, “start_offset”: 7, “end_offset”: 11, “label”: “城市”}, {“id”: 114, “start_offset”: 11, “end_offset”: 14, “label”: “县区”}, {“id”: 115, “start_offset”: 14, “end_offset”: 20, “label”: “详细地址”}, {“id”: 116, “start_offset”: 20, “end_offset”: 31, “label”: “电话”}}
{“id”: 58, “text”: “易颖18500308469山东省烟台市莱阳市富水南路1号”, “relations”: [], “entities”: {“id”: 118, “start_offset”: 0, “end_offset”: 2, “label”: “姓名”}, {“id”: 119, “start_offset”: 2, “end_offset”: 13, “label”: “电话”}, {“id”: 120, “start_offset”: 13, “end_offset”: 16, “label”: “省份”}, {“id”: 121, “start_offset”: 16, “end_offset”: 19, “label”: “城市”}, {“id”: 122, “start_offset”: 19, “end_offset”: 22, “label”: “县区”}, {“id”: 123, “start_offset”: 22, “end_offset”: 28, “label”: “详细地址”}}
doccano_ext.jsonl是打车数据集:
{“id”: 1, “text”: “昨天晚上十点加班打车回家58元”, “relations”: [], “entities”: {“id”: 0, “start_offset”: 0, “end_offset”: 6, “label”: “时间”}, {“id”: 1, “start_offset”: 11, “end_offset”: 12, “label”: “目的地”}, {“id”: 2, “start_offset”: 12, “end_offset”: 14, “label”: “费用”}}
{“id”: 2, “text”: “三月三号早上12点46加班,到公司54”, “relations”: [], “entities”: {“id”: 3, “start_offset”: 0, “end_offset”: 11, “label”: “时间”}, {“id”: 4, “start_offset”: 15, “end_offset”: 17, “label”: “目的地”}, {“id”: 5, “start_offset”: 17, “end_offset”: 19, “label”: “费用”}}
{“id”: 3, “text”: “8月31号十一点零四工作加班五十块钱”, “relations”: [], “entities”: {“id”: 6, “start_offset”: 0, “end_offset”: 10, “label”: “时间”}, {“id”: 7, “start_offset”: 14, “end_offset”: 16, “label”: “费用”}}
{“id”: 4, “text”: “5月17号晚上10点35分加班打车回家,36块五”, “relations”: [], “entities”: {“id”: 8, “start_offset”: 0, “end_offset”: 13, “label”: “时间”}, {“id”: 1, “start_offset”: 18, “end_offset”: 19, “label”: “目的地”}, {“id”: 9, “start_offset”: 20, “end_offset”: 24, “label”: “费用”}}
{“id”: 5, “text”: “2009年1月份通讯费一百元”, “relations”: [], “entities”: {“id”: 10, “start_offset”: 0, “end_offset”: 7, “label”: “时间”}, {“id”: 11, “start_offset”: 11, “end_offset”: 13, “label”: “费用”}}
结果展示预览
输入:
代码语言:txt
复制
城市内交通费7月5日金额114广州至佛山
从百度大厦到龙泽苑东区打车费二十元
上海虹桥高铁到杭州时间是9月24日费用是73元
上周末坐动车从北京到上海花费五十块五毛
昨天北京飞上海话费一百元
输出:
代码语言:txt
复制
{"出发地": [{"text": "广州", "start": 15, "end": 17, "probability": 0.9073772252165782}], "目的地": [{"text": "佛山", "start": 18, "end": 20, "probability": 0.9927365183877761}], "时间": [{"text": "7月5日", "start": 6, "end": 10, "probability": 0.9978010396512218}]}
{"出发地": [{"text": "百度大厦", "start": 1, "end": 5, "probability": 0.968825147409472}], "目的地": [{"text": "龙泽苑东区", "start": 6, "end": 11, "probability": 0.9877913072493669}]}
{"目的地": [{"text": "杭州", "start": 7, "end": 9, "probability": 0.9929172180094881}], "时间": [{"text": "9月24日", "start": 12, "end": 17, "probability": 0.9953342057701597}]}
{#"出发地": [{"text": "北京", "start": 7, "end": 9, "probability": 0.973048366717471}], "目的地": [{"text": "上海", "start": 10, "end": 12, "probability": 0.988486130309397}], "时间": [{"text": "上周末", "start": 0, "end": 3, "probability": 0.9977407699595275}]}
{"出发地": [{"text": "北京", "start": 2, "end": 4, "probability": 0.974188953533556}], "目的地": [{"text": "上海", "start": 5, "end": 7, "probability": 0.9928200521486445}], "时间": [{"text": "昨天", "start": 0, "end": 2, "probability": 0.9731559534465504}]}
1.数据集加载(快递单数据、打车数据)
doccano_file: 从doccano导出的数据标注文件。
save_dir: 训练数据的保存目录,默认存储在data目录下。
negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。
splits: 划分数据集时训练集、验证集所占的比例。默认为0.8, 0.1, 0.1表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。
task_type: 选择任务类型,可选有抽取和分类两种类型的任务。
options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为"正向", “负向”。
prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。
is_shuffle: 是否对数据集进行随机打散,默认为True。
seed: 随机种子,默认为1000.
*separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为"##"。
代码语言:python
复制
!python doccano.py \
--doccano_file ./data/doccano_ext.jsonl \
--task_type 'ext' \
--save_dir ./data \
--splits 0.8 0.1 0.1 \
--negative_ratio 5
代码语言:python
复制
[2022-07-14 11:34:26,474] [ INFO] - Converting doccano data...
100%|████████████████████████████████████████| 40/40 [00:00<00:00, 42560.16it/s]
[2022-07-14 11:34:26,477] [ INFO] - Adding negative samples for first stage prompt...
100%|███████████████████████████████████████| 40/40 [00:00<00:00, 161009.75it/s]
[2022-07-14 11:34:26,478] [ INFO] - Converting doccano data...
100%|██████████████████████████████████████████| 5/5 [00:00<00:00, 21754.69it/s]
[2022-07-14 11:34:26,479] [ INFO] - Adding negative samples for first stage prompt...
100%|██████████████████████████████████████████| 5/5 [00:00<00:00, 44057.82it/s]
[2022-07-14 11:34:26,479] [ INFO] - Converting doccano data...
100%|██████████████████████████████████████████| 5/5 [00:00<00:00, 26181.67it/s]
[2022-07-14 11:34:26,480] [ INFO] - Adding negative samples for first stage prompt...
100%|██████████████████████████████████████████| 5/5 [00:00<00:00, 45689.59it/s]
[2022-07-14 11:34:26,482] [ INFO] - Save 160 examples to ./data/train.txt.
[2022-07-14 11:34:26,482] [ INFO] - Save 20 examples to ./data/dev.txt.
[2022-07-14 11:34:26,482] [ INFO] - Save 20 examples to ./data/test.txt.
[2022-07-14 11:34:26,482] [ INFO] - Finished! It takes 0.01 seconds
输出部分展示:
代码语言:txt
复制
{"content": "上海到北京机票1320元", "result_list": [{"text": "上海", "start": 0, "end": 2}], "prompt": "出发地"}
{"content": "上海到北京机票1320元", "result_list": [{"text": "北京", "start": 3, "end": 5}], "prompt": "目的地"}
{"content": "上海到北京机票1320元", "result_list": [{"text": "1320", "start": 7, "end": 11}], "prompt": "费用"}
{"content": "上海虹桥到杭州东站高铁g7555共73元时间是10月14日", "result_list": [{"text": "上海虹桥", "start": 0, "end": 4}], "prompt": "出发地"}
{"content": "上海虹桥到杭州东站高铁g7555共73元时间是10月14日", "result_list": [{"text": "杭州东站", "start": 5, "end": 9}], "prompt": "目的地"}
{"content": "上海虹桥到杭州东站高铁g7555共73元时间是10月14日", "result_list": [{"text": "73", "start": 17, "end": 19}], "prompt": "费用"}
{"content": "上海虹桥到杭州东站高铁g7555共73元时间是10月14日", "result_list": [{"text": "10月14日", "start": 23, "end": 29}], "prompt": "时间"}
{"content": "昨天晚上十点加班打车回家58元", "result_list": [{"text": "昨天晚上十点", "start": 0, "end": 6}], "prompt": "时间"}
{"content": "昨天晚上十点加班打车回家58元", "result_list": [{"text": "家", "start": 11, "end": 12}], "prompt": "目的地"}
{"content": "昨天晚上十点加班打车回家58元", "result_list": [{"text": "58", "start": 12, "end": 14}], "prompt": "费用"}
{"content": "2月20号从南山到光明二十元", "result_list": [{"text": "2月20号", "start": 0, "end": 5}], "prompt": "时间"}
2.模型训练
代码语言:python
复制
!python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint" \
--learning_rate 1e-5 \
--batch_size 8 \
--max_seq_len 512 \
--num_epochs 100 \
--model "uie-base" \
--seed 1000 \
--logging_steps 10 \
--valid_steps 50 \
--device "gpu"
代码语言:python
复制
部分训练效果展示:**具体输出已折叠**
[2022-07-12 15:09:47,643] [ INFO] - global step 250, epoch: 13, loss: 0.00045, speed: 3.90 step/s
[2022-07-12 15:09:47,910] [ INFO] - Evaluation precision: 1.00000, recall: 1.00000, F1: 1.00000
[2022-07-12 15:09:50,399] [ INFO] - global step 260, epoch: 13, loss: 0.00043, speed: 4.02 step/s
[2022-07-12 15:09:52,966] [ INFO] - global step 270, epoch: 14, loss: 0.00042, speed: 3.90 step/s
[2022-07-12 15:09:55,464] [ INFO] - global step 280, epoch: 14, loss: 0.00040, speed: 4.00 step/s
[2022-07-12 15:09:58,028] [ INFO] - global step 290, epoch: 15, loss: 0.00039, speed: 3.90 step/s
[2022-07-12 15:10:00,516] [ INFO] - global step 300, epoch: 15, loss: 0.00038, speed: 4.02 step/s
[2022-07-12 15:10:00,781] [ INFO] - Evaluation precision: 1.00000, recall: 1.00000, F1: 1.00000
[2022-07-12 15:10:03,348] [ INFO] - global step 310, epoch: 16, loss: 0.00036, speed: 3.90 step/s
[2022-07-12 15:10:05,836] [ INFO] - global step 320, epoch: 16, loss: 0.00035, speed: 4.02 step/s
[2022-07-12 15:10:08,393] [ INFO] - global step 330, epoch: 17, loss: 0.00034, speed: 3.91 step/s
[2022-07-12 15:10:10,888] [ INFO] - global step 340, epoch: 17, loss: 0.00033, speed: 4.01 step/s
代码语言:python
复制
推荐使用GPU环境,否则可能会内存溢出。CPU环境下,可以修改model为uie-tiny,适当调下batch_size。
增加准确率的话:--num_epochs 设置大点多训练训练
可配置参数说明:
**train_path:** 训练集文件路径。
**dev_path:** 验证集文件路径。
**save_dir:** 模型存储路径,默认为./checkpoint。
**learning_rate:** 学习率,默认为1e-5。
**batch_size:** 批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数,默认为16。
**max_seq_len:** 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。
**num_epochs:** 训练轮数,默认为100。
**model** 选择模型,程序会基于选择的模型进行模型微调,可选有uie-base和uie-tiny,默认为uie-base。
**seed:** 随机种子,默认为1000.
**logging_steps:** 日志打印的间隔steps数,默认10。
**valid_steps:** evaluate的间隔steps数,默认100。
**device:** 选用什么设备进行训练,可选cpu或gpu。
3模型评估
代码语言:python
复制
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/test.txt \
--batch_size 16 \
--max_seq_len 512
代码语言:python
复制
[2022-07-11 13:41:23,831] [ INFO] - -----------------------------
[2022-07-11 13:41:23,831] [ INFO] - Class Name: all_classes
[2022-07-11 13:41:23,832] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-07-11 13:41:35,024] [ INFO] - -----------------------------
[2022-07-11 13:41:35,024] [ INFO] - Class Name: 出发地
[2022-07-11 13:41:35,024] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-07-11 13:41:35,139] [ INFO] - -----------------------------
[2022-07-11 13:41:35,139] [ INFO] - Class Name: 目的地
[2022-07-11 13:41:35,139] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-07-11 13:41:35,246] [ INFO] - -----------------------------
[2022-07-11 13:41:35,246] [ INFO] - Class Name: 费用
[2022-07-11 13:41:35,246] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2022-07-11 13:41:35,313] [ INFO] - -----------------------------
[2022-07-11 13:41:35,313] [ INFO] - Class Name: 时间
[2022-07-11 13:41:35,313] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。
test_path: 进行评估的测试集文件。
batch_size: 批处理大小,请结合机器情况进行调整,默认为16。
max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。
model: 选择所使用的模型,可选有uie-base, uie-medium, uie-mini, uie-micro和uie-nano,默认为uie-base。
debug: 是否开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。
4 结果预测
代码语言:python
复制
from pprint import pprint
import json
from paddlenlp import Taskflow
def openreadtxt(file_name):
data = []
file = open(file_name,'r',encoding='UTF-8') #打开文件
file_data = file.readlines() #读取所有行
for row in file_data:
data.append(row) #将每行数据插入data中
return data
data_input=openreadtxt('./input/nlp.txt')
schema = ['出发地', '目的地','时间']
few_ie = Taskflow('information_extraction', schema=schema, batch_size=1,task_path='./checkpoint/model_best')
results=few_ie(data_input)
with open("./output/test.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾
for result in results:
line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False
f.write(line + "\n")
print("数据结果已导出")
输入文件展示:
代码语言:txt
复制
城市内交通费7月5日金额114广州至佛山
从百度大厦到龙泽苑东区打车费二十元
上海虹桥高铁到杭州时间是9月24日费用是73元
上周末坐动车从北京到上海花费五十块五毛
昨天北京飞上海话费一百元
输出展示:
代码语言:txt
复制
{"出发地": [{"text": "广州", "start": 15, "end": 17, "probability": 0.9073772252165782}], "目的地": [{"text": "佛山", "start": 18, "end": 20, "probability": 0.9927365183877761}], "时间": [{"text": "7月5日", "start": 6, "end": 10, "probability": 0.9978010396512218}]}
{"出发地": [{"text": "百度大厦", "start": 1, "end": 5, "probability": 0.968825147409472}], "目的地": [{"text": "龙泽苑东区", "start": 6, "end": 11, "probability": 0.9877913072493669}]}
{"目的地": [{"text": "杭州", "start": 7, "end": 9, "probability": 0.9929172180094881}], "时间": [{"text": "9月24日", "start": 12, "end": 17, "probability": 0.9953342057701597}]}
{"出发地": [{"text": "北京", "start": 7, "end": 9, "probability": 0.973048366717471}], "目的地": [{"text": "上海", "start": 10, "end": 12, "probability": 0.988486130309397}], "时间": [{"text": "上周末", "start": 0, "end": 3, "probability": 0.9977407699595275}]}
{"出发地": [{"text": "北京", "start": 2, "end": 4, "probability": 0.974188953533556}], "目的地": [{"text": "上海", "start": 5, "end": 7, "probability": 0.9928200521486445}], "时间": [{"text": "昨天", "start": 0, "end": 2, "probability": 0.9731559534465504}]}
5.可视化显示visualDL
详细文档可以参考:
https://aistudio.baidu.com/aistudio/projectdetail/1739945?contributionType=1
有详细讲解,具体实现参考代码,
核心是:添加一个初始化记录器
下面是结果展示:
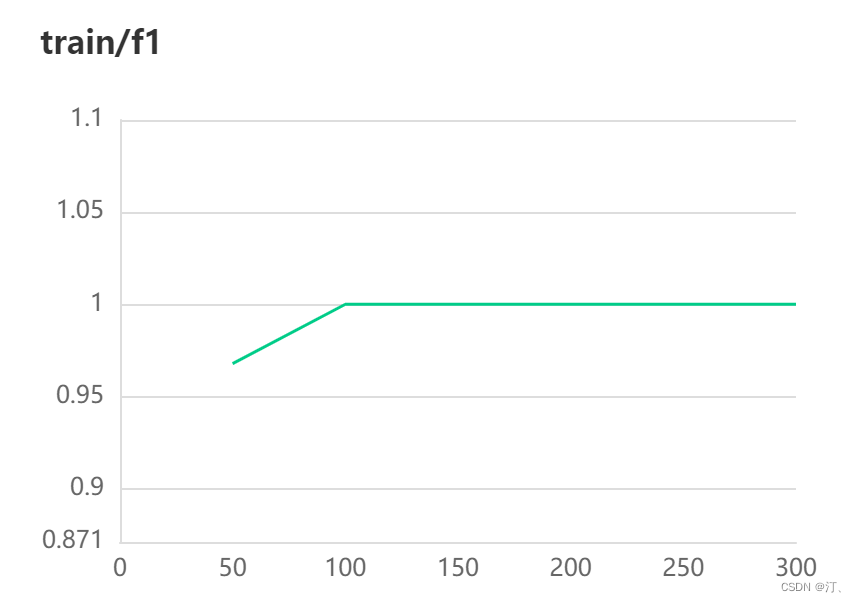
在这里插入图片描述
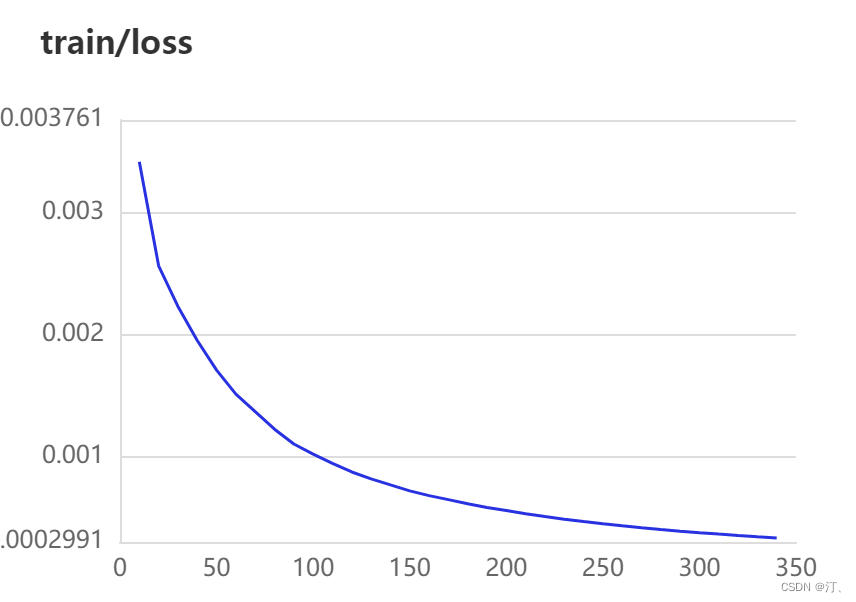
在这里插入图片描述
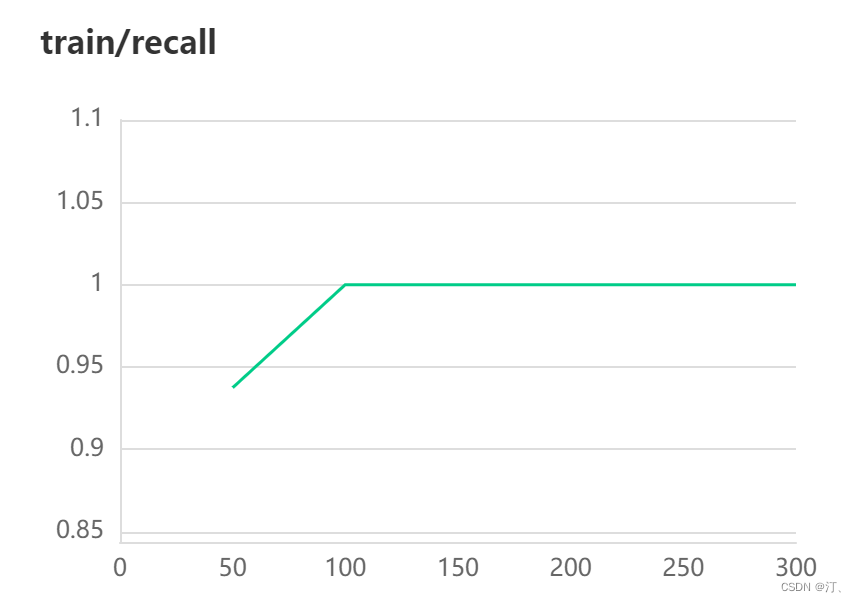
在这里插入图片描述
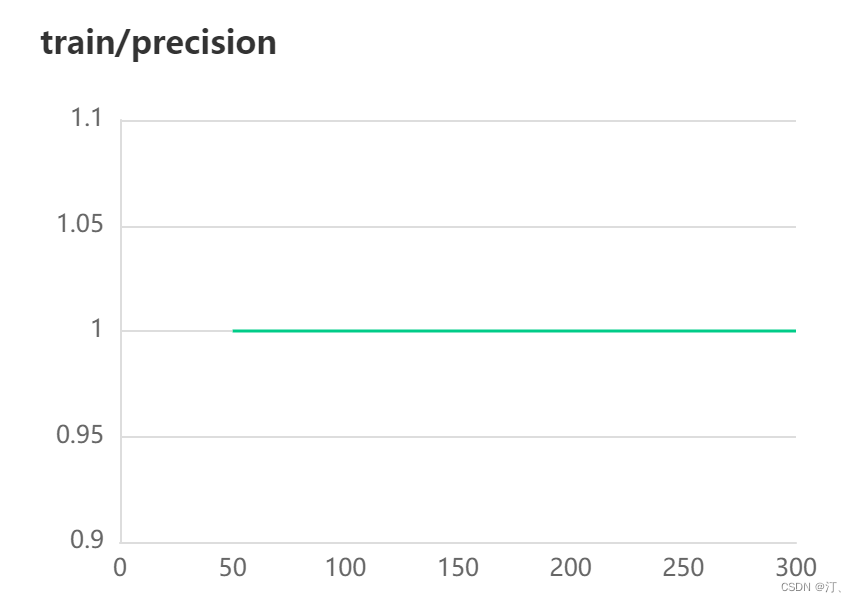
在这里插入图片描述
6.小技巧:获取paddle开源数据集
数据集网站:https://paddlenlp.readthedocs.io/zh/latest/data_prepare/dataset_list.html#id2
数据集名称 简介 调用方法
CoLA 单句分类任务,二分类,判断句子是否合法 paddlenlp.datasets.load_dataset(‘glue’,‘cola’)
SST-2 单句分类任务,二分类,判断句子情感极性
paddlenlp.datasets.load_dataset(‘glue’,‘sst-2’)
MRPC 句对匹配任务,二分类,判断句子对是否是相同意思 paddlenlp.datasets.load_dataset(‘glue’,‘mrpc’)
STSB 计算句子对相似性,分数为1~5 paddlenlp.datasets.load_dataset(‘glue’,‘sts-b’)
QQP 判定句子对是否等效,等效、不等效两种情况,二分类任务 paddlenlp.datasets.load_dataset(‘glue’,‘qqp’)
MNLI 句子对,一个前提,一个是假设。前提和假设的关系有三种情况:蕴含(entailment),矛盾(contradiction),中立(neutral)。句子对三分类问题 paddlenlp.datasets.load_dataset(‘glue’,‘mnli’)
QNLI 判断问题(question)和句子(sentence)是否蕴含,蕴含和不蕴含,二分类 paddlenlp.datasets.load_dataset(‘glue’,‘qnli’)
RTE 判断句对是否蕴含,句子1和句子2是否互为蕴含,二分类任务 paddlenlp.datasets.load_dataset(‘glue’,‘rte’)
WNLI 判断句子对是否相关,相关或不相关,二分类任务 paddlenlp.datasets.load_dataset(‘glue’,‘wnli’)
LCQMC A Large-scale Chinese Question Matching Corpus 语义匹配数据集 paddlenlp.datasets.load_dataset(‘lcqmc’)
通过paddlenlp提供的api调用,可以很方便实现数据加载,当然你想要把数据下载到本地,可以参考我下面的输出就可以保存数据了。
代码语言:python
复制
#加载中文评论情感分析语料数据集ChnSentiCorp
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])
with open("./output/test2.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾
for result in test_ds:
line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False
f.write(line + "\n")
7 总结
UIE(Universal Information Extraction):Yaojie Lu等人在ACL-2022中提出了通用信息抽取统一框架UIE。该框架实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务间具备良好的迁移和泛化能力。PaddleNLP借鉴该论文的方法,基于ERNIE 3.0知识增强预训练模型,训练并开源了首个中文通用信息抽取模型UIE。该模型可以支持不限定行业领域和抽取目标的关键信息抽取,实现零样本快速冷启动,并具备优秀的小样本微调能力,快速适配特定的抽取目标。
UIE的优势
使用简单: 用户可以使用自然语言自定义抽取目标,无需训练即可统一抽取输入文本中的对应信息。实现开箱即用,并满足各类信息抽取需求。
降本增效: 以往的信息抽取技术需要大量标注数据才能保证信息抽取的效果,为了提高开发过程中的开发效率,减少不必要的重复工作时间,开放域信息抽取可以实现零样本(zero-shot)或者少样本(few-shot)抽取,大幅度降低标注数据依赖,在降低成本的同时,还提升了效果。
效果领先: 开放域信息抽取在多种场景,多种任务上,均有不俗的表现。
本人本次主要通过实体抽取这个案例分享给大家,主要对开源的paddlenlp的案例进行了细化,比如在结果可视化方面以及结果输入输出的增加,使demo项目更佳完善。
当然标注问题是所有问题的痛点,可以参考我的博客来解决这个问题
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
四、AI大模型商业化落地方案
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1710
1710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









