






多模态大型语言模型(MM-LLMs)近期取得显著进步,通过有效训练策略,使模型能处理多模态输入输出,保留并增强语言模型的推理决策能力。MM-LLMs不仅限于文本,还能处理图像、视频和音频等其他模态数据,推动下游任务性能提升。
MM-LLMs改进了训练流程,增强交互能力和采用更高效架构。其迭代包括从预训练到微调,再到基于人类反馈的强化学习,体现了模型的持续优化和进步。总体而言,MM-LLMs正朝着更广泛模态支持、更高质量数据利用和更有效模型设计的方向发展。
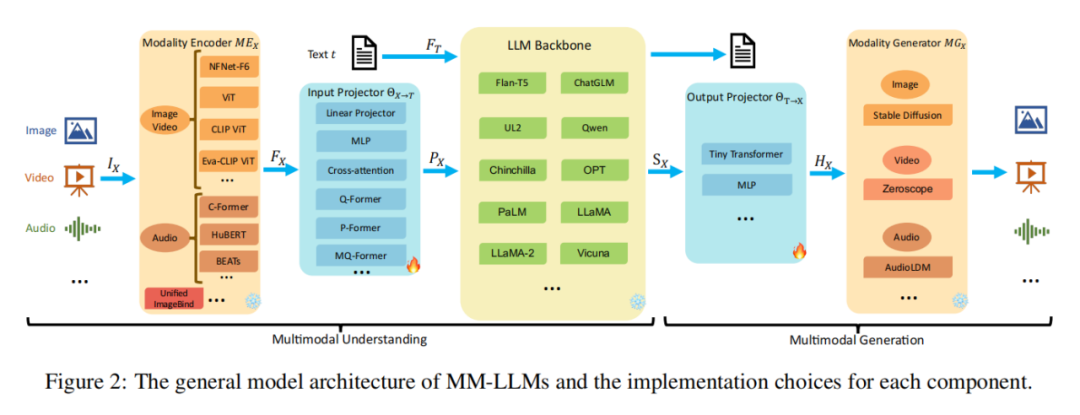
1 MM-LLMs的基本架构
多模态大型语言模型(MM-LLMs)的架构由五个主要组件构成:模态编码器、输入投影器、LLM主干、输出投影器和模态生成器。
-
模态编码器(Modality Encoder):
模态编码器的主要功能是将不同模态的输入转换成对应的特征表示FX。例如,它可以将图像、视频、音频等非文本信息转化为模型可理解的特征向量。这个转换过程通过预训练的编码器实现,如针对图像的ViT或针对音频的特定音频编码器。
-
输入投影器(Input Projector):
输入投影器的作用是将模态编码器产生的特征映射到语言模型主干可以理解的空间。它确保了不同模态信息可以被整合并传递给模型的核心部分进行处理。
-
LLM主干(LLM Backbone):
这是模型的中心部分,基于预训练的文本型语言模型。在训练过程中,这部分一般保持冻结状态,以保留模型原有的语言理解和生成能力。LLM主干负责处理从输入投影器接收到的特征,并生成中间表示。
-
输出投影器(Output Projector):
输出投影器与输入投影器相反,它将从LLM主干得到的中间表示转换为目标模态的输出,例如将中间表示转化为文本、图像或其他模态的输出。
-
模态生成器(Modality Generator):
模态生成器用于生成新模态的数据,比如根据文本描述生成图像。它在需要生成输出模态时发挥作用,例如视觉描述或语音合成。
2 MM-LLMs的训练流程
多模态大型语言模型(MM-LLMs)的训练流程主要包括两个阶段:多模态预训练(MM PT)和多模态指令微调(MM IT)。
-
多模态预训练(MM PT)****:
MM PT阶段利用X-Text数据集,旨在训练输入投影器和输出投影器,使它们能够实现不同模态间的对齐。对于仅涉及多模态理解的模型,优化主要集中在使输入投影器能将不同模态输入映射到统一表示空间。对于涉及多模态生成的模型,优化包括使输入投影器、输出投影器以及模态生成器协同工作,实现模态间的转换和生成。X-Text数据集包含Image-Text、Video-Text和Audio-Text对,其中Image-Text有Image-Text配对和交错Image-Text语料库两种类型。
-
多模态指令微调(MM IT)****:
MM IT是指使用指令格式化数据集对预训练的MM-LLMs进行微调,让模型能够泛化到未见过的任务。这一过程使MM-LLMs能够更好地理解人类意图,增强对话交互能力,从而提升模型在实际应用中的性能。
3 MM-LLMs的未来发展
- 最新发展趋势:
-
提升视觉分辨率:模型采用更高分辨率图像,以捕获更精细的细节,如LLaVA-1.5、VILA、Qwen-VL和MiniGPT-v2。
-
高质量监督微调数据:整合高质量SFT数据,显著提升模型在特定任务上的性能。
-
改进训练策略:采用参数高效微调、交错图像-文本数据训练等方法。
2. 未来研究方向:
-
构建更通用智能模型:扩展模态支持,多样化LLMs,提升数据集质量,加强生成能力。
-
更具挑战性的基准测试:完善评估标准,全面衡量MM-LLMs的高级功能。
-
移动/轻量级部署:研究轻量化策略,以适应资源受限的平台。
-
具身智能:使模型能够像人类一样感知和互动,有效理解环境并进行操作。
4 结语
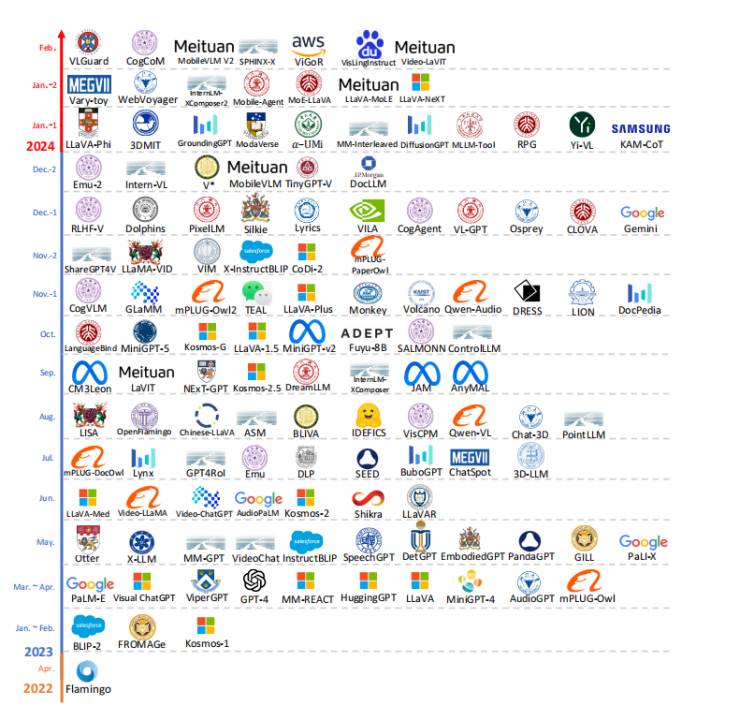
论文全面概述了多模态大型语言模型(MM-LLMs)的最新进展,从模型架构、训练策略到性能评估和未来方向,为推动该领域研究提供了详实的综述和资源。为了紧跟多模态大语言模型(MM-LLMs)的最新进展,作者创建了一个实时跟踪平台:https://mm-llms.github.io。该网站旨在促进知识共享,记录研究动态,并鼓励社区参与,对推动领域创新、避免重复劳动和加强学术交流具有重要作用。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









