






你是否深入研究过 ChatGPT、通义、kimi等先进的生成式 AI 工具呢?那你一定对“prompt”(提示词)这个核心概念有自己的见解吧。
“prompt”就像是连接你和 AI 创意之泉的桥梁,它不仅是开启无限想象的钥匙,更是决定 AI 输出内容质量的关键所在。

然而,在享受 AI 带来的无尽创意和便捷时,如何精心打造一条既能让大型模型轻松理解,又能保证其准确执行的“prompt”,已经成为每个 AI 探索者必须面对的重要课题。
优化“prompt”确实是一项充满挑战且需要策略的任务。用户不仅要精准把握问题的核心,提炼出关键的要点,确保信息传达清晰明了,还要仔细考虑模型的理解能力和执行效率,避免出现冗余或模糊不清的表达,以免成为交流的阻碍。
更为有趣的是,不同的大型语言模型(LLM)都有各自独特的“语言喜好”和理解深度。有些模型对结构化数据情有独钟,能够快速解析并给出精准反馈;而另一些则更喜欢沉浸在自然语言的细致描述中,寻找灵感的火花。因此,用户需要深入了解并适应不同模型的个性特点,这无疑增加了“prompt”编写的难度。
所以,为了提高效率,研究人员专注于研究不同生成式 AI 模型的提示词,成功找到了有效引导和优化这些大型模型工作的策略,也就是“驯服”大模型的方法。
26 条提示词原则
让回答质量提升 45%!
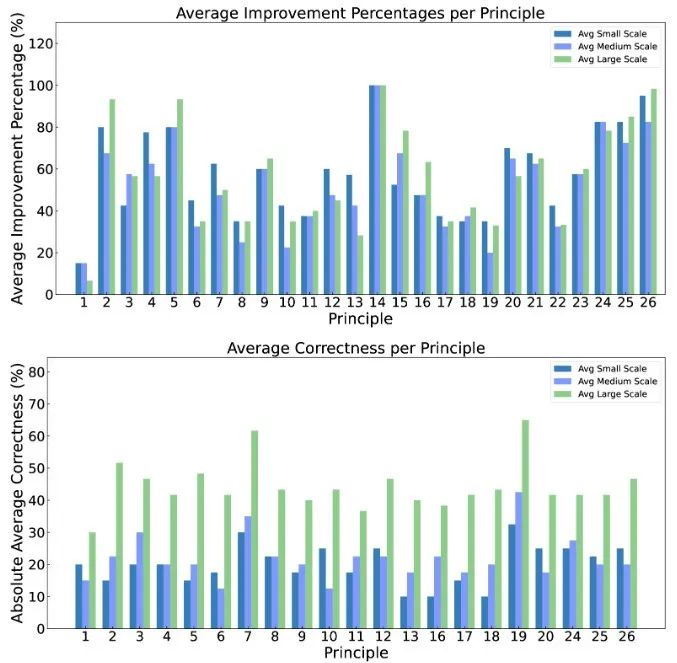
在研究论文“Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4”中,穆罕默德·本·扎耶德人工智能大学的研究团队深入研究了大语言模型提示词的优化,测试了 26 种激励策略,并评估了它们的准确性。研究发现,所有策略都能有效发挥作用,而且部分策略显著提高了大模型的回答质量,最高可达 45%。
以下是这 26 条原则的完整总结:
**1、简洁明确:**研究人员指出,与LLM交互时,无需多余的礼貌用语。直接、清晰地提出问题是关键。例如:“描述人体细胞的结构。”这样的提示既直接又明确,有助于模型迅速准确地给出答案。
2、考虑受众**:**最好在提示中明确指出预期的受众类型,例如老人或 5 岁儿童。你可以这样问:针对一个10岁的儿童,如何从深圳宝安机场乘坐飞机前往上海虹桥机场。
**3、分解复杂任务:**将复杂的任务拆解为一系列清晰、具体的提示,让模型能够逐步深入并准确理解。以数学表达式简化为例:“P1:将负号分配给以下等式的括号内的每个项:2x +3 y-(4x -5 y);P2:分别组合“x”和“y”的类似项;P3:提供合并后的简化表达式。”
**4、使用肯定性指令:**请采用如“做”或“执行”这样的正面指导词汇,代替“请勿”或“不要做”这样的否定性表达。
**5、寻求解释:**当寻求对某一概念或问题的深入理解时,有效方法是直接提出要求,用最简单明了的语言进行解释。比如,可以直接说:“为了更好地理解,请用初学者的角度和最简单的语言为我讲解。”这样的请求直接且高效,有助于快速获得清晰透彻的解答。
**6、激励策略:**在提问时,不妨采用一种激励策略,即通过承诺给予奖励来激发模型或回答者提供更为优质的答案。具体做法是在提问的末尾明确表达这一意愿,例如:“为了获得更加出色的解决方案,我将为满意的答案提供xxx小费作为感谢。”这样的做法能够有效提升回答的积极性与质量。
**7、示例驱动:**为了精准引导模型生成符合期望的输出格式,在请求时,可以直接提供一个具体的示例,作为模型生成内容的模板或指南。比如,当希望将某段文字优化为邮件回复的形式时,可以这样表达:“请参照以下示例,将这段文字转换为正式且礼貌的邮件回复格式进行优化。”
**8、格式化提示词:**为了提升大模型处理复杂任务时的准确性和效率,可以使用高度结构化的指令格式。通过精心设计的分隔符,如“#Instruction#”、“#Example#”和“#Question#”,可以清晰地划分出说明、示例、问题及上下文等关键部分,使模型更容易理解和执行。
**9、明确角色:**在提示中为模型分配一个明确的角色或任务。如:“你是一位科普讲解员,任务是向一位朋友解释臭氧的奥秘。在这个过程中,你必须运用简单易懂的语言,避免使用复杂的科学术语,以确保对方能够轻松理解并掌握这一自然现象。”
**10、遵守规则:**明确指出模型必须遵循的规则或关键词。如:“你是一位科普讲解员,任务是向一位朋友解释臭氧的奥秘。如果你不使用简单的语言,你将受到惩罚。”
**11、自然语言回答:**要求模型以自然、类似人类的方式回答问题。如:“写一段关于全民健身的文章,以自然、人性化的方式回答问题。”
**12、逐步思考:**使用引导性的词语,如“思考步骤”。示例:“编写一段 Python 代码,循环遍历 10 个数字并对它们求和。让我们一步一步地想。”

**13、无偏见:**确保答案无偏见,避免依赖刻板印象。如:“文化背景如何影响人们对心理健康的看法?确保你的回答是公正的,避免依赖刻板印象。”
**14、互动提问:**允许模型通过提问来获取必要的信息。如:“从现在开始,问我问题,直到你有足够的信息来创建一个个性化的国庆节新疆旅游攻略。”
**15、教学测试:**通过提供一个定理或问题的教学,并在最后进行测试。如:“教我[任何定理/主题/规则名称],并在最后提供一个测试同时不要给予我答案,如果我得到了正确的答案,告诉我。”
**16、指定角色:**为LLM大模型分配一个特定的角色或身份。例如:“如果你是一位经济学家,你会如何回答:资本主义和社会主义经济制度之间的主要区别是什么?”
**17、使用分隔符:**在提示中使用分隔符来区分不同的部分。如:“撰写一篇有说服力的文章,讨论‘可再生能源’在减少温室气体排放方面的重要性。”
**18、重复关键词:**在提示中多次重复特定的单词或短语。例如:“进化作为一个概念,塑造了物种的发展。进化的主要驱动力是什么?进化如何影响现代人类?”
**19、输出引导:**在提示的结尾处提供期望输出的开头。例如:“描述牛顿第一运动定律背后的原理。说明:”
**20、详细说明:**要求模型提供详细的文本,包括所有必要的信息。例如:“写一个详细的段落给我关于苹果公司的演变,详细地添加所有必要的信息。”
**21、修改文本:**在不改变风格的情况下修改特定文本。例如:“尝试修改用户发送的每一条文本。你应该只提高用户的语法和词汇,并确保它听起来自然。你应该保持原来的写作风格,确保一个正式的段落保持正式。”
**22、代码生成:**对于涉及多个文件的复杂编码提示,生成可以自动创建或修改文件的脚本。例如:“从现在开始,每当你生成跨越多个文件的代码时,生成一个[编程语言]脚本,可以运行它来自动创建指定的文件,或者对现有文件进行更改以插入生成的代码。”
**23、继续文本:**使用特定的单词、短语或句子来启动或继续文本。例如:“我给你提供了一个奇幻故事的开头:“迷雾山脉隐藏着无人知晓的秘密。“根据提供的文字完成,保持一致。”
**24、明确要求:**清楚地陈述模型为了产生内容必须遵循的要求。例如:“为海滩度假创建一个打包清单,必需包括以下关键词‘防晒霜’、‘泳衣’和‘海滩毛巾’。”
**25、模仿样本:**如果希望生成的文本类似于提供的样本,则包括相应的指令。例如:“‘温柔的海浪向银色的沙滩低声诉说着古老的故事,每个故事都是过去时代的短暂记忆。’根据提供的文本使用相同的语言来描绘山与风的相互作用。”
**26、结合思维链:**将思维链(CoT)与少量示例提示结合起来。示例:“例 1:10 除以 2。首先取 10 除以 2,结果是 5。例 2:20 除以 4。首先取 20 除以 4,结果是 5。第一个问题:“30 除以 6。首先取 30 除以 6,结果呢?”
在研究人员看来,这些原则旨在帮助用户更好地设计和理解LLM的提示,从而提高模型响应的质量和相关性。
根据实验结果,**在所有规模的LLM上,26 条原则均能显著提升响应质量,特别是在大模型(如 GPT-4)上,这些原则带来的改进更为显著。**对于小规模和中等规模的模型,平均绝对准确性可以达到 10%至 40%,而对于大规模模型,准确率可以超过 40%。
但同时,研究还指出,尽管这些原则在大多数情况下有效,但在处理非常复杂或高度专业化的查询时,其效果可能会降低,“这取决于模型的推理能力和训练情况”。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









