






目录
引入
对数几率模型与Logistic回归
逻辑回归
逻辑回归损失函数
交叉熵
相对熵
本章节讲解逻辑回归的基本原理、逻辑回归模型构建过程。课程环境使用Jupyter notebook环境
引入
首先,在引入LR(Logistic Regression)模型之前,非常重要的一个概念是,该模型在设计之初是用来解决0/1二分类问题,虽然它的名字中有回归二字,但只是在其线性部分隐含地做了一个回归,最终目标还是以解决分类问题为主。
代码语言:javascript
复制
# 科学计算模块
import numpy as np
import pandas as pd
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
之前我们研究了线性回归模型的原理与应用,线性回归模型可以简写为:f(x) = w^Tx + b
当我们希望线性模型的预测值逼近真实标记Y,这样就是线性模型,那可否令模型的预测值逼近y的衍生物呢? 比如,是在线性回归基础上,在等号的左边或右边加上了一个函数,这个函数对线性结果进行了一系列的非线性转换,从而能够让模型更好的捕捉一般规律,此时该模型就被称为广义线性模型,y的衍生物生成函数,我们称之为联系函数。
y = e{wTx+b}这就是对数线性回归(log-linear regression),它实际上是在e{wTx+b}试图让逼近,上式形式上是线性回归,但实际上已是在求输入空间到输出空间的非线性函数映射。
我们通过一个例子先来熟一下线性回归模型的不足:
先看一下方法:np.linalg.lstsq(x, y, rcond=-1)
- NumPy 中用于求解最小二乘问题的函数,它返回最小二乘解,即找到一个最接近输入数据的解,使得残差平方和最小。
代码语言:javascript
复制
# 随机生成100个数
np.random.seed(216)
x = np.linspace(0,10,100).reshape(-1,1) # ...行1列
该模型还需要引入一个截距参数:
代码语言:javascript
复制
x = np.concatenate((x, np.ones_like(x)), axis=1)
# 在给定的轴(axis)上将两个数组合并
数据标签:
代码语言:javascript
复制
y = np.exp(x[:,0] + 1).reshape(-1,1)
如果我们使用简单线性回归模型来对数据进行预测 y= w^T X + b
- # 权重向量 ( w ) 的转置,与自变量向量 ( x ) 进行点积运算
使用最小二乘法来进行计算,则模型输出结果为:
代码语言:javascript
复制
np.linalg.lstsq(x, y, rcond=-1)
(array([[ 2968.68189529],
[-8611.71543123]]),
array([8.22208992e+09]),
2,
array([58.52647642, 4.9819583 ]))
通过结果发现,通过最小二乘法计算出模型参数为 2968.68和-8611.71,即 y=2968.68x-8611.71
我们最后将原始数据导入模型中,计算出模型预测值,再进行可视化:
代码语言:javascript
复制
yhat = x[:,0] * 2968.68 - 8611.71
plt.scatter(x[:,0], y)
plt.plot(x[:,0], yhat,'r')
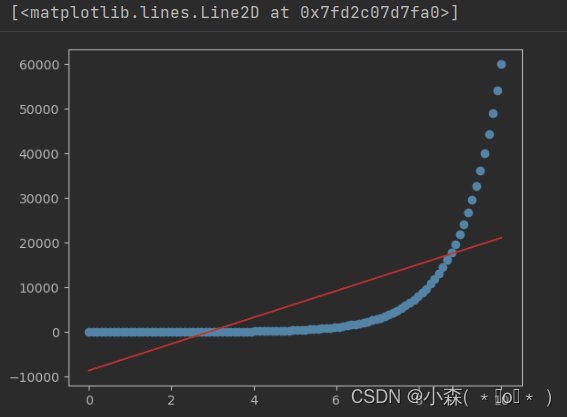
红色的是我们预测出的模型,蓝色的点是真实的数,可以将方程改写为:

代码语言:javascript
复制
np.linalg.lstsq(x, np.log(y), rcond=-1)
按照输出结果, 我们得到模型方程:lny=x+1,即解出原方程。
对数几率模型与Logistic回归
Logistic 回归也被称为“对数几率”回归
几率的概念与概率不同,几率是指:将y记作正例(某事件)发生的概率,而1-y作为负例的概率,那么两者的比值 称之为该事件的几率,在几率的基础之上,我们取对数进行操作,则构成了该事件的对数几率(logit):
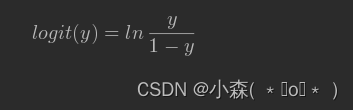
大家可以这么理解,几率表示“一件事情成功的几率”, 可以定义为成功的概率/失败的概率,如果明天晴天的概率是60%,则非晴天的概率是40%,则几率就是1.5 。
那么对数几率就是log1.5,从0.1到0.9的几率:
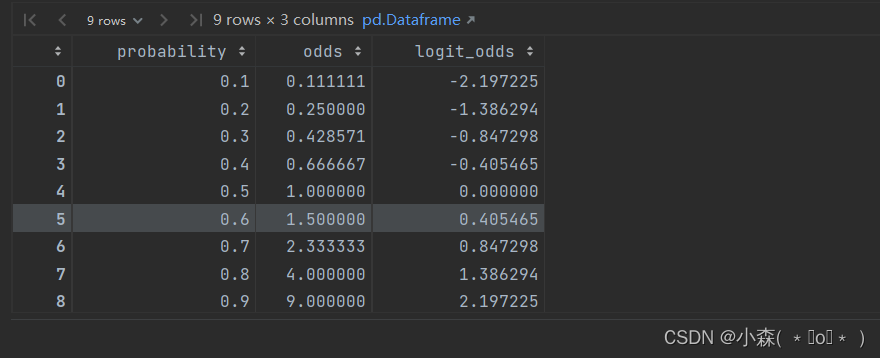
此时的广义线性模型就是 对数几率回归 logistic regression,也被称为逻辑回归。
逻辑回归
得到逻辑回归基本模型方程:

此时,y表示在现有样本的条件下,结果正例的概率
代码语言:javascript
复制
np.random.seed(216)
x = np.linspace(-15, 15, 100)
y = 1 / (1 + np.exp(-x))
plt.plot(x, y)
plt.show()
我们称这种有着优美的S型曲线的数学函数为Sigmoid函数,当然,Sigmoid函数是一类函数,但是逻辑回归函数在机器学习中是非常常见普遍的函数。
逻辑回归损失函数
交叉熵
我们又需要引入一个数学概念,熵(entropy)
第一个问题,如何量化信息? 信息论是应用数学的一个分支,主要研究的是对一个信号包含信息的多少进行量化。信息论的基本想法是一个不太可能的事件发生了,要比一个非常可能的事件发生,能提供更多的信息。
我们需要衡量信息的多少,第一步就是如何衡量信息量,信息量实际上是事件不确定度的度量,越不确定的事件,对其的描述就包含越多信息,假设我们听到了两件事,分别如下:
事件A:阿根廷进入了2022世界杯决赛圈。
事件B:中国队进入了2022世界杯决赛圈。
仅凭直觉来说,显而易见事件B的信息量比事件A的信息量要大。究其原因,是因为事件A发生的概率很大,事件B发生的概率很小。所以当越不可能的事件发生了,我们获取到的信息量就越大。越可能发生的事件发生了,我们获取到的信息量就越小。那么信息量应该和事件发生的概率有关。
我们可以总结一下:
- 信息量小,概率大的事件发生了
- 信息量大,概率小的事件发生了
越不可能的事件发生时,我们获取到的信息量就越大。越可能发生的事件发生了,我们获取到的信息量就越小,一个简单的例子就是,“明天太阳东边升起”,这句话是没有任何信息量的,因为我们都知道太阳总是东升西落。
在信息论中,总结了信息量的计算方法,我们假设X是一个离散型随机变量,概率分布函数:I(x_0) = - \log(p(x_0)):
代码语言:javascript
复制
x = np.linspace(0,1,100)
y = - np.log2(x)
plt.plot(x,y)
plt.show()
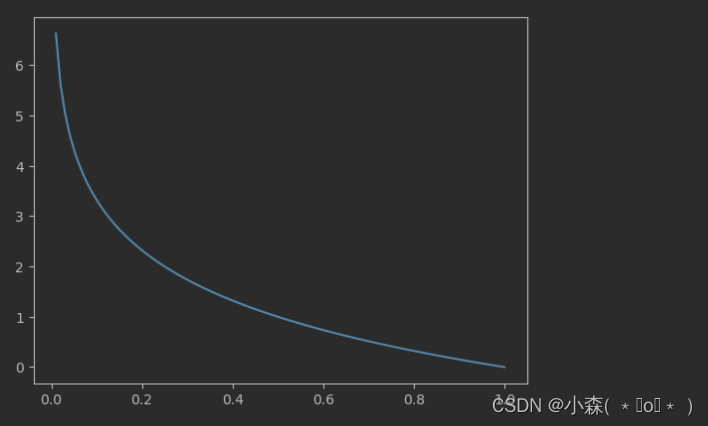
- 横坐标为概率p,纵坐标为信息量 I。概率越小,信息量越大,概率越大,信息量越小。
了解了信息量的计算方法之后,存在一个问题,对于某种事件,我们有很多可能性,每一种可能性都有概率,那么我们就可以计算出某一种可能性的信息量,举个列子,周末你和家人在公园放风筝,当松手的时候,我们假设预测有几种可能:
代码语言:javascript
复制
def entropy(ps):
def getI(p):
return -p * np.log2(p)
ent = 0
if ps.sum() != 1 :
print("输入值错误")
return np.nan
for p in ps:
if p == 0 or p == 1:
ent = 0
else:
ent += getI(p)
return ent
信息量只能处理单个的输出。我们可以使用香农熵(Shannon entropy)来对整个概率分布中的不确定性总量进行量化!用熵来表示所有信息量的期望:
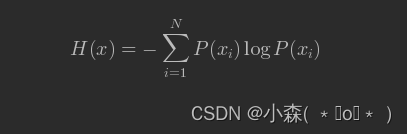
通过这个公式,计算一下放风筝这个事件的熵,我们可以得到熵值是:0.8841。
在分类问题中,我们也可以使用熵来计算样本集的信息熵值
为了后续计算方便,我们也可以定义信息熵的计算公式:
代码语言:javascript
复制
def entropy(ps):
def getI(p):
return -p * np.log2(p)
ent = 0
if ps.sum() != 1 :
print("输入值错误")
return np.nan
for p in ps:
if p == 0 or p == 1:
ent = 0
else:
ent += getI(p)
return ent
代码语言:javascript
复制
## 如果是二分类,那么熵的计算公式可以改一下。
def entropy_bin(p):
def getI(p):
return -p * np.log2(p)
if p == 0 or p == 1:
ent = 0
else:
ent = getI(p) + getI(1-p)
return ent
p = np.linspace(0, 1, 50)
ent_l = [entropy_bin(x) for x in p]
plt.plot(p, ent_l)
plt.scatter(0.5,entropy_bin(0.5))
plt.xlabel('P')
plt.ylabel('Entropy')
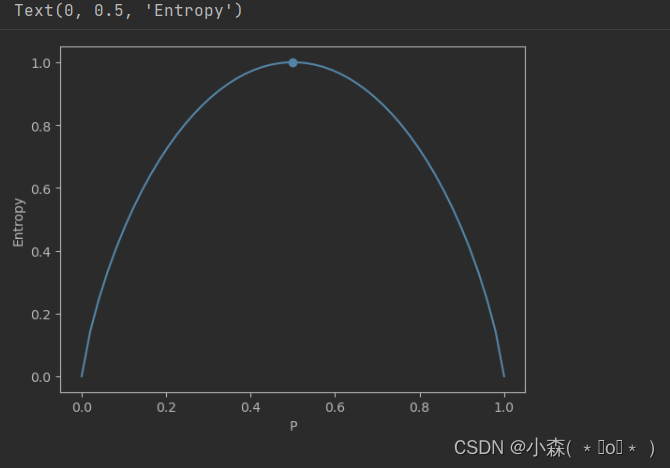
可以发现当P值为0.5的时候,熵值最大,也就是指,在二分类中,如果0、1类样本各占50%,那么熵值是最大的,也就是标签随机变量的不确定性已经达到峰值!如果Labels全为1,或者全为0,那么系统的熵值是最小的,是0,也就代表标签的取值整体呈现非常确定的状态,系统信息规整。也可以推测出,此时的熵的范围是【0,1】
相对熵
在机器学习过程中,我们其实可以得到两种数据集的分布,一种是原始特征和真实标签的数据集,一种是原始特征和模型预测值组成的数据集,我们如何比较真实标签和我们预测值的差异呢?这个也是损失函数的核心问题?这个又和现在讲解的熵有什么关系呢?
在这里我们需要引入另一个概念,就是相对熵
相对熵也被称为Kullback-Leibler散度(KL散度)或者信息散度(information divergence)。通常用来衡量两个随机变量分布的差异性。假设对同一个随机变量X,有两个单独的概率分布P(x)和Q(x),当X是离散变量时,我们可以通过如下相对熵计算公式来衡量二者差异:
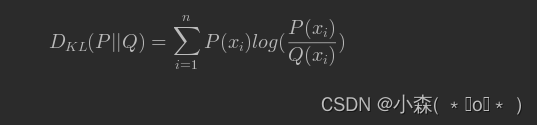
在机器学习中,P往往用来表示样本的真实分布,比如[1,0,0]表示当前样本属于第一类。Q用来表示模型所预测的分布,比如[0.7,0.2,0.1],直观的理解就是如果用P来描述样本,那么就非常完美。而用Q来描述样本,虽然可以大致描述,但是不是那么的完美,信息量不足,需要额外的一些“信息增量”才能达到和P一样完美的描述,这个信息增量可以理解为两种数据分布的差异,从本质上来说,相对熵刻画的是用概率分布Q来刻画概率分布P的困难程度。和信息熵类似,相对熵越小,表示两种分布越相似。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









