







整理 | 屠敏
北京时间 2 月 18 日中午,埃隆·马斯克旗下的人工智能公司 xAI 重磅发布了 Grok 3 系列模型,宣称其在数学、科学和编码基准测试中,击败了 Google Gemini、DeepSeek V3、Claude 以及 OpenAI 的 GPT-4o。

更为值得关注的是,Grok 3 的训练并非如此前传闻的在“10 万张 GPU 上进行”,而是使用了“20 万张 GPU”。对此,有网友指出其算力消耗是 DeepSeek V3 的 263 倍。正因此,“又壕又横”的马斯克将其称为“地球上最聪明的 AI”。
0****1
Grok 3 基准测试曝光
根据 xAI 工程师的介绍,Grok 3 其实是一个模型家族——而不仅仅是一个模型。Grok 3 的轻量级版本——Grok 3 mini——在牺牲一定准确度的情况下,能够更快地响应问题。
目前,并不是所有模型都已经上线(其中一些仍处于测试阶段),但会从今天开始陆续推出。此外,原定今天要发布的语音模式并未出现,马斯克随后也在 X 上解释称,“语言模式仍然有点不完善,所以大概会在一周左右推出,但它很棒。”
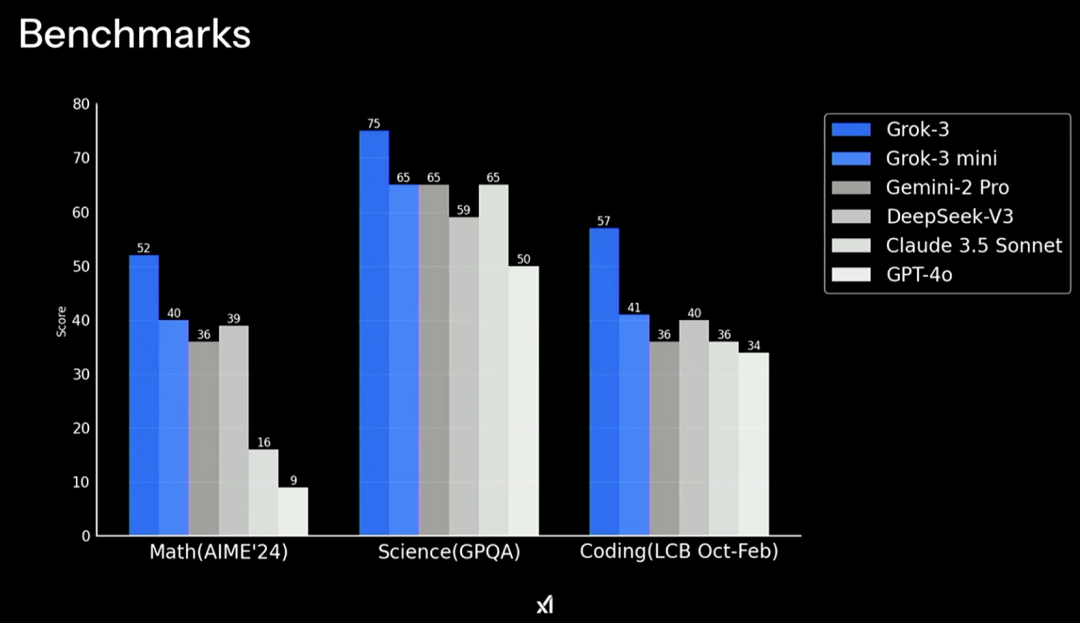
根据官方公开的测试结果,Grok 3 在包括 AIME(评估模型在一系列数学问题上的表现)和 GPQA(评估模型在博士级别的物理学、生物学和化学问题上的表现)等基准测试中,远超 GPT-4o、Gemini-2 Pro、DeepSeek V3、Claude 3.5 Sonnet 等大模型。
在大模型竞技场 Chatbot Arena(LMSYS)测试中,xAI 工程师表示,早期版本的 Grok-3 获得了第一的成绩,达到了 1402 分,超越了 Gemini 2.0 Flash Thinking 实验版本、ChatGPT-4o 最新版本以及最近大火的 DeepSeek R1 等等。
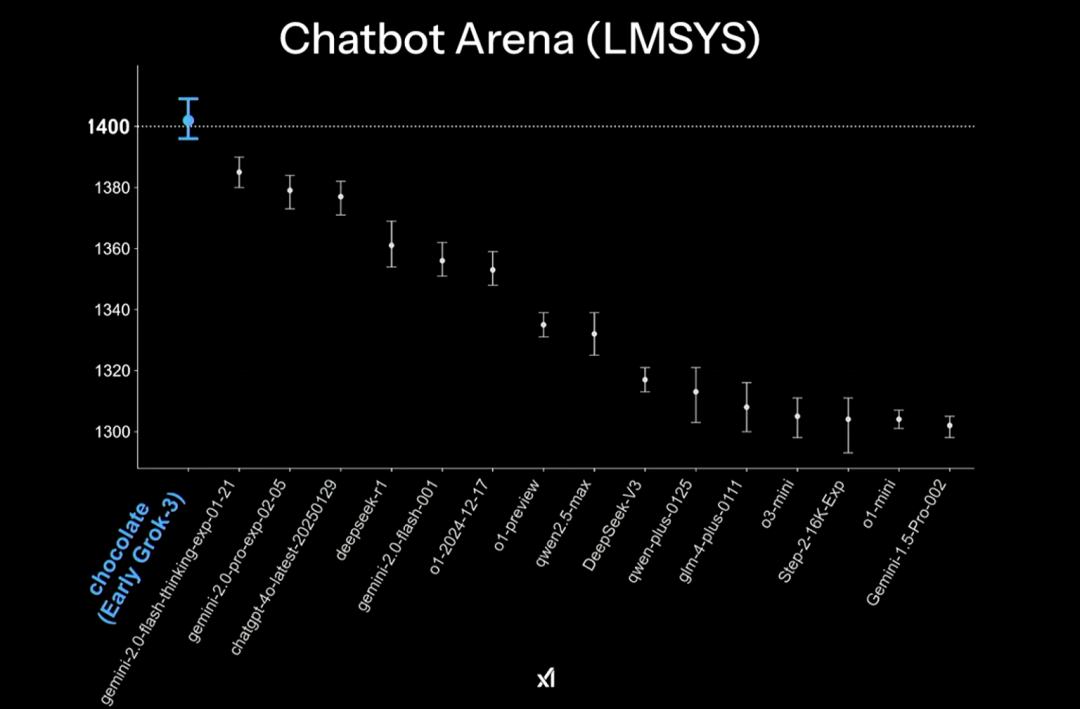
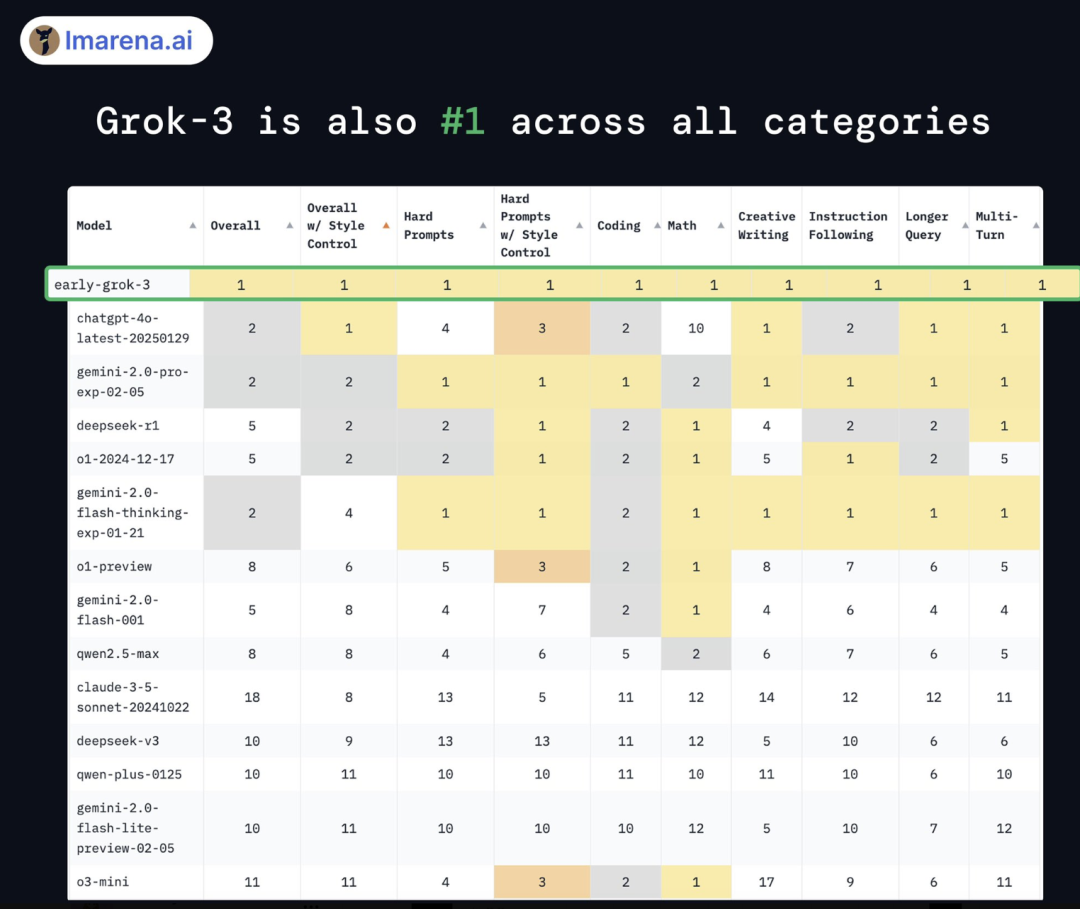
要知道在 Chatbot Arena 中,用户或评审可以通过对比不同的模型响应,并进行投票,以评定哪个模型提供了最佳的答案。平台通过这种“人类评分”的方式帮助研究人员和开发者了解各大聊天机器人模型的优劣,推动模型的持续改进。时下 Grok 3 是在过往业界已发布的大模型中首个突破 1400 分、获得多个第一的大模型。
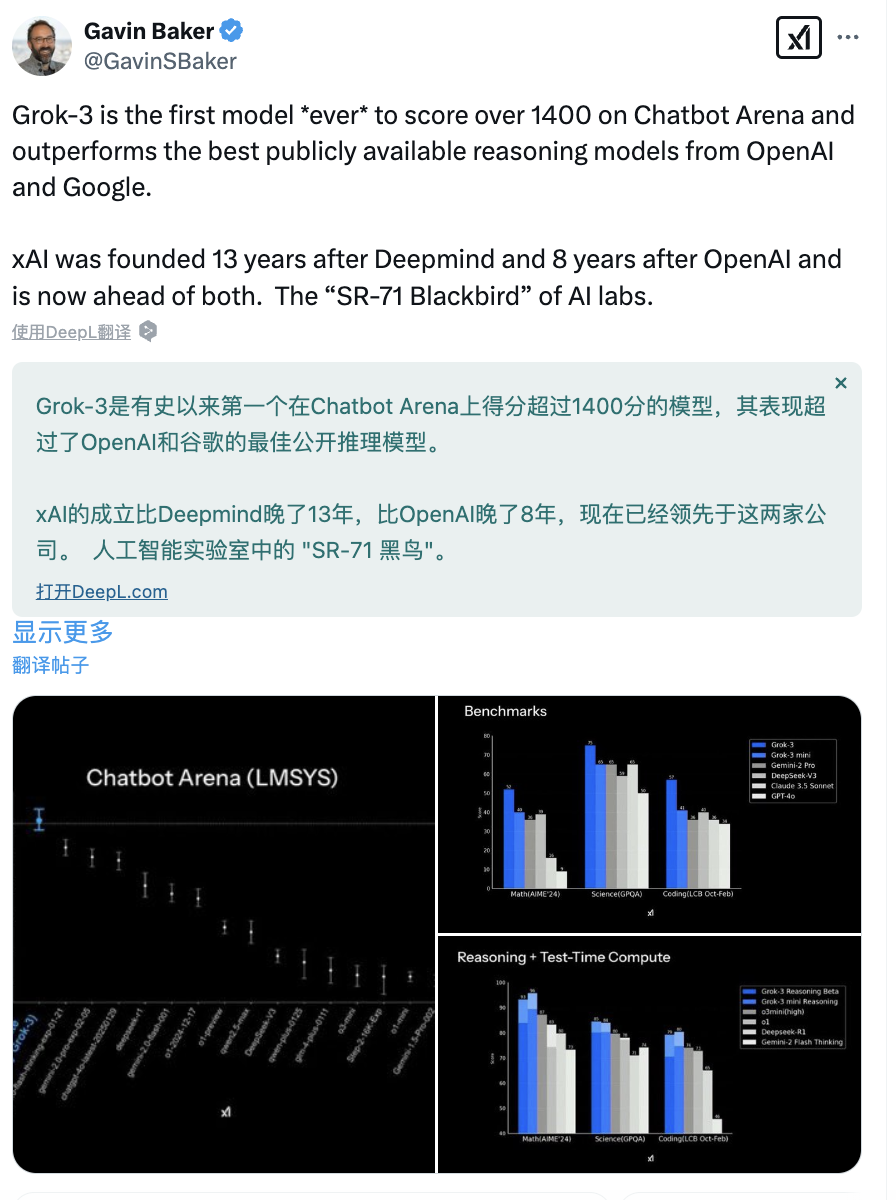
美国著名 TMT 投资人 Gavin Baker 评价道,「xAI 成立于 DeepMind 之后的 13 年、OpenAI 之后的 8 年,现在已领先于两者。它被誉为 AI 实验室中的“SR-71 黑鸟”(象征其突破性、超前性和强大的技术能力)。」
0****2
推理大模型赛道再添新成员
——Grok 3
与此同时,Grok 3 也支持推理能力了。
xAI 工程师介绍道,“大约一个月前,Grok 3 的预训练完成,从那时起,我们一直在努力将推理能力整合到当前的 Grok 3 模型中。不过,这仍处于早期阶段,模型仍在继续训练。今天展示的只是 Grok 3 推理模型的一部分。同时,我们还在训练一个 mini 版本的推理模型。”
今天,xAI 带来的推理模型一个是 Grok 3 Reasoning Beta,另一个是 Grok 3 mini Reasoning,其类似于 OpenAI 的 o3-mini 和 DeepSeek 的 R1 这样的“推理”模型,都能够仔细“推理”问题。推理模型在给出结果之前会彻底自我核实,这帮助它们避免了通常会让其他模型出错的陷阱。
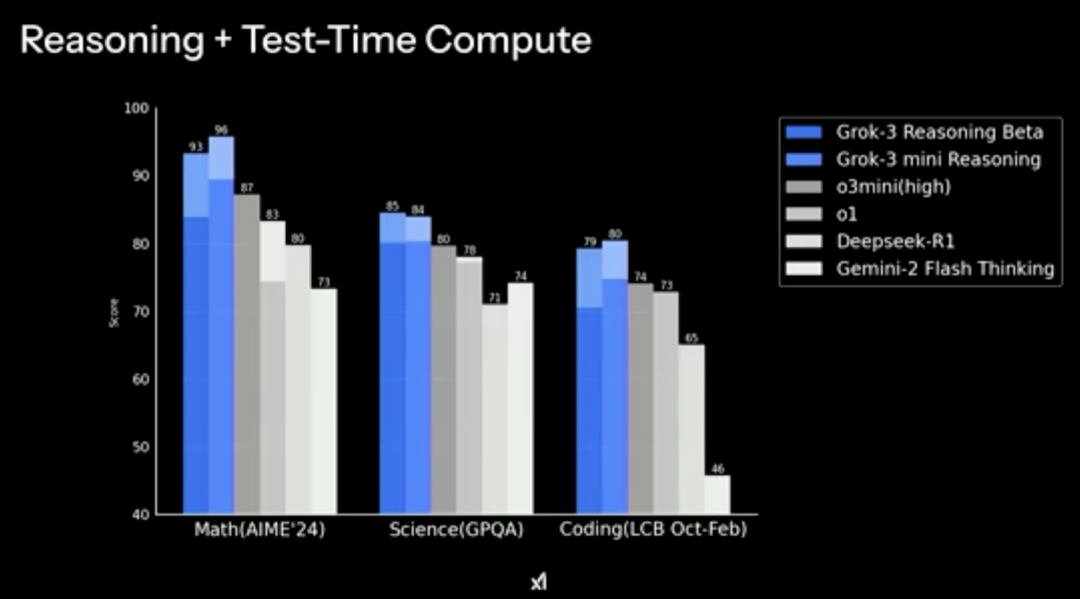
随后,官方也展示了 Grok-3 推理基准测试结果。
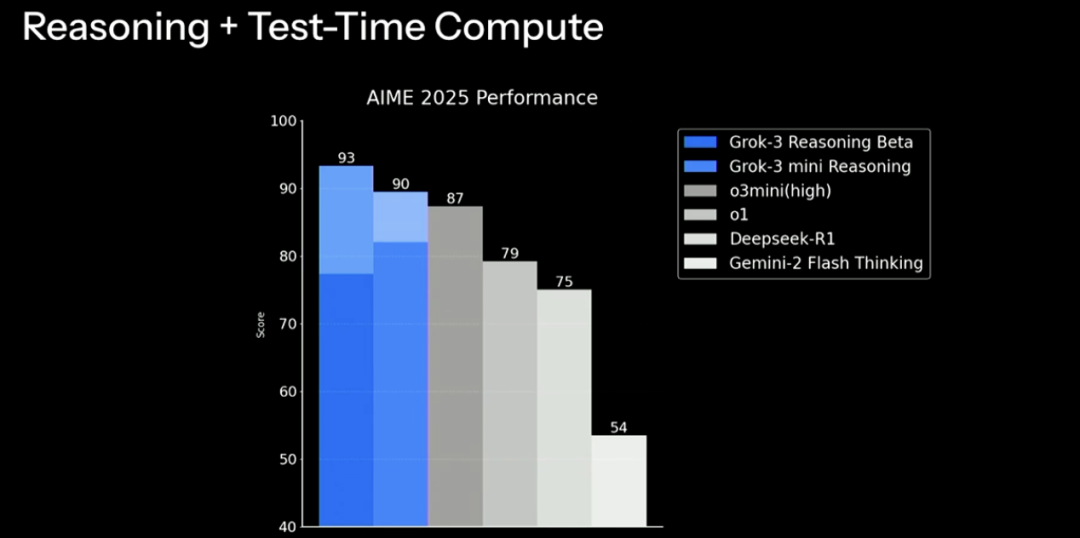
xAI 声称,在使用更多测试时间计算时(图中浅色延展部分),Grok-3 Reasoning 在多个流行的基准测试中超过了 o3-mini 的最佳版本——o3-mini-high,其中包括一个名为 AIME 2025 的新数学基准测试。
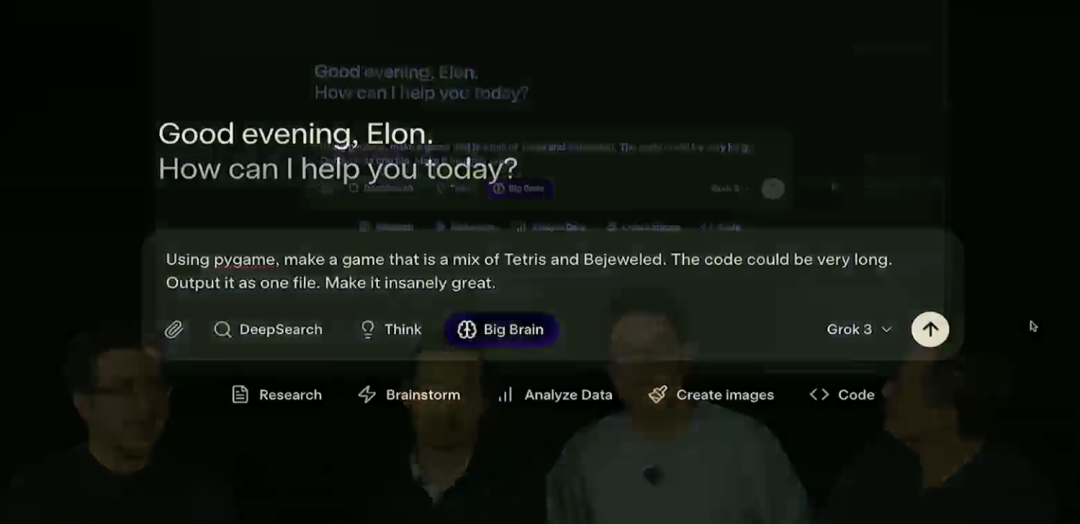
推理模型可以通过 Grok 应用程序访问。界面显示如下,用户可以点击 Grok 3 的“Think”模式来体验,或者对于更复杂的问题,使用“Big Brain”模式,后者这种模式依赖额外的计算资源进行推理。
xAI 描述这些推理模型最适合处理数学、科学和编程相关的问题。
除此之外,Grok 3 还引入了 DeepSearch,该公司将其描述为一种新型搜索引擎和类似代理的功能的早期版本。它可以扫描互联网内容和 X(原 Twitter),分析信息并针对问题提供摘要。显然可以看出,它对标的是此前 OpenAI 推出的 Deep Research 功能。
马斯克还表示,在 Grok 应用程序中,某些推理模型的“思维”被隐藏,以防止“蒸馏”(一种 AI 模型开发者用来从另一个模型中提取知识的方法)。
0****3
20 万张 GPU
训练出来的 Grok 3
回顾过往,2023 年 7 月,马斯克集结 Deepmind、微软、特斯拉以及学术界的多位大佬成立了人工智能初创公司 xAI。仅仅半年之后,xAI 就带来其研发成果——Grok-1 大模型,还采用了开源策略,迅速吸引了大量关注。截至目前,Grok-1 在 GitHub 上已经获得了近 50k 个 Star,Fork 数达到 8.3k,成功迎接了当时 OpenAI 和 Google 等闭源大模型带来的竞争压力。
然而,在百模大战中,走别人走过的路、打造千篇一律的模型显然无法脱颖而出。在此次 Grok 3 发布会上,马斯克再次重申了自己对大模型的构想,并解释了为何将其命名为“Grok”。
“实际上,我们应该解释一下为什么我们叫它 ‘Grok’。这个词来自罗伯特·海因莱因的小说《异乡异客》。它由一个在火星长大的角色使用,意思是完全并深刻地理解某件事。‘Grok’ 传达的是深刻的理解,而同理心是其中一个重要部分。”
总的来说,马斯克希望 Grok 模型愿意回答其他 AI 系统不敢回答的争议性问题。正因此,马斯克此次也表示,“Grok 3 是一种最大程度地寻求真相的人工智能,即使这种真相有时与政治正确相悖。”

在能力上,**马斯克称新版的 Grok 3 能力比 Grok 2 高出一个数量级。**对此,xAI 的工程师进行了现场演示。
一、「使用 pygame,制作一个结合了俄罗斯方块和宝石方块的游戏。代码可以很长。将其输出为一个文件。让它变得非常棒。」
得到如下的结果:
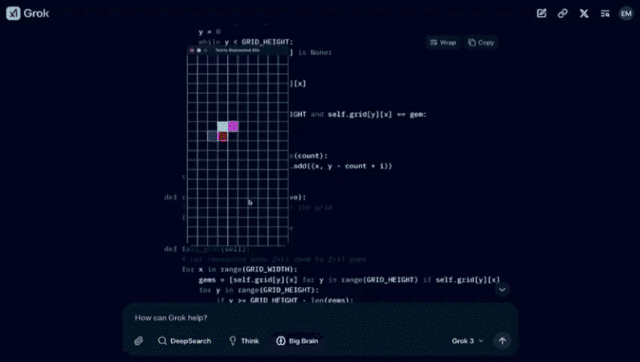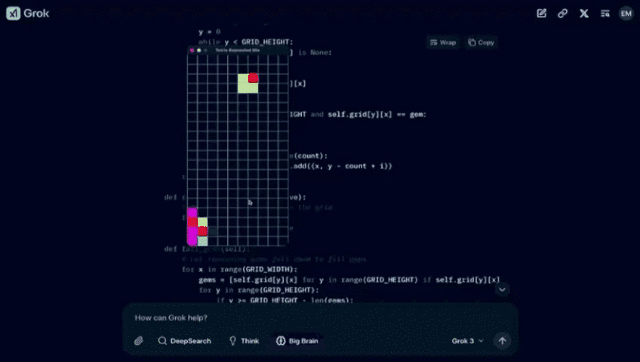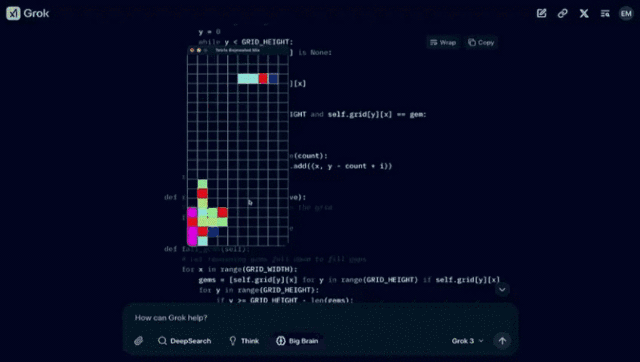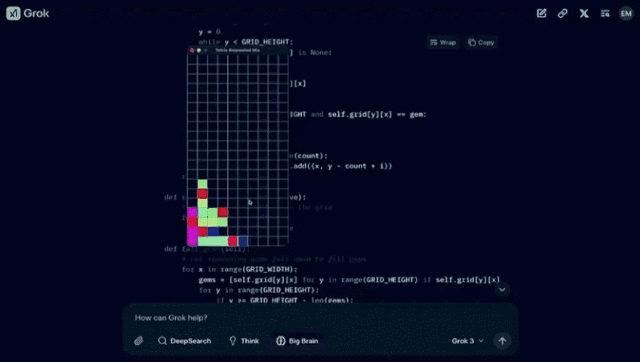
二、「生成从地球发射、着陆火星然后在下一个发射窗口返回地球的 3D 动图的代码。」
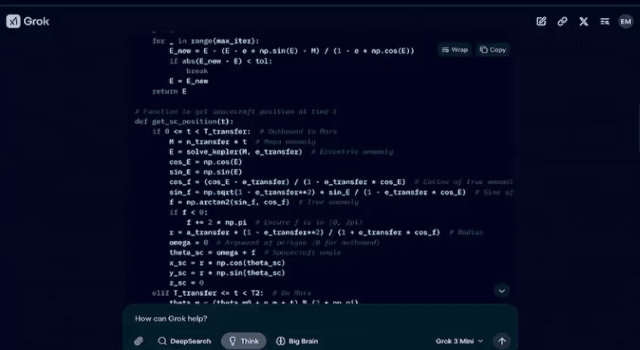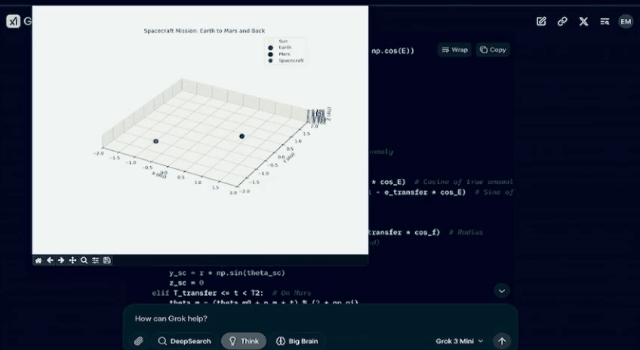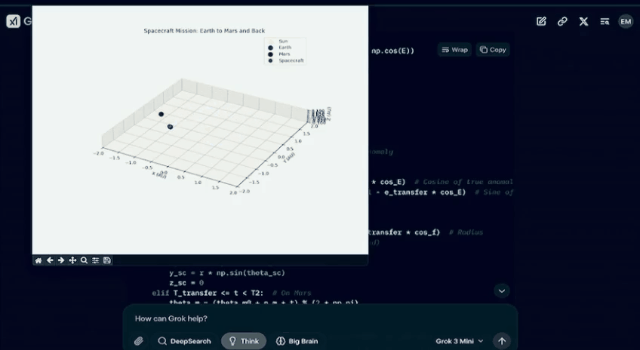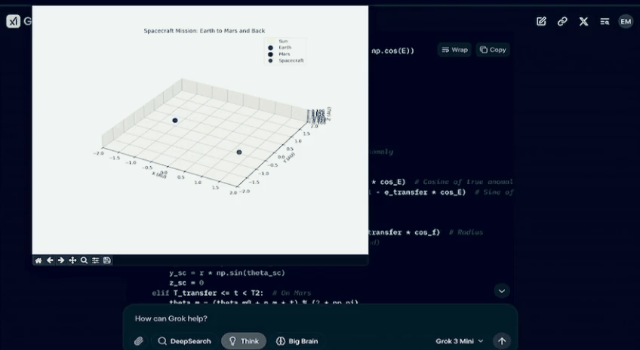
可以看出,Grok 3 的表现确实不错。那么,Grok 3 的能力为什么会这么强?
事实上,和其他公司有所不同,xAI 背后有马斯克这位世界首富的支持。据 xAI 工程师在直播中介绍:
**“去年四月,埃隆决定,xAI 成功并打造最好的 AI 的唯一途径,就是建立我们自己的数据中心。**我们没有太多时间,因为我们想尽快推出 Grok 3。所以,我们意识到必须在大约四个月内完成数据中心的建设。我们花了 122 天让首批 10 万个 GPU 启动并运行,这是一项巨大的努力。我们相信,这是世界上最大规模的全连接 H100 集群。但我们并没有就此止步。
我们很快意识到,为了构建我们设想中的 AI,我们需要将集群规模翻倍。因此,我们启动了另一个阶段——**这是我们第一次公开谈论这个——在短短 92 天内将容量翻倍。**我们利用这些计算能力,在这个过程中持续改进产品。”
简单来说,之前媒体多次报道 xAI 使用了 10 万个 GPU 构建了超级计算机 Colossus,但那只是初步阶段。后来,xAI 构建了一个包含约 20 万个 GPU 的数据中心,而 Grok 3 的训练正是在此基础设施上进行的。

不难想象马斯克有多么豪横、Grok 3 的能力有多强了,有网友在 Grok 3 推出后发了一张图:

0****4
Grok 2 将在不久后开源
当前,X 的 Premium+ 订阅用户将率先体验 Grok 3,其他功能则通过 xAI 推出的新计划 SuperGrok 提供。SuperGrok 定价为每月 30 美元或每年 300 美元,付费后可以解锁更多的推理和 DeepSearch 查询,并提供无限制的图像生成功能。
最后,在与网友的 QA 环节,马斯克表示,未来——大约一周后——Grok 将推出“语音模式”,为 Grok 提供合成语音。几周后,Grok 3 模型将与 DeepSearch 功能一起进入 xAI 的企业 API。
再几个月后,xAI 将开源 Grok 2。“我们的总体方针是,当下一个版本完全发布时,我们将开源最后一个版本 [的 Grok],”马斯克说。“当 Grok 3 成熟并稳定下来,这可能会在几个月内实现,然后我们将开源 Grok 2。”
0****5
业界评价不一
整体而言,Grok 3 在各项基准上的测试结果都拿下了不错的成绩,但实测结果如何?
来自知名学者、纽约大学教授 Gary Marcus 有些质疑道,「马斯克和他公司里的 3 位员工现场演示了 Grok 3,对于最近看过这些系统演示的任何人来说,这次演示看起来就像是很多其他演示的公式化模仿:一些比之前稍微好一点的基准测试结果,更多的训练(显然是 Grok 2 所用计算量的 15 倍),演示了一个 Tetris 变体的自动编程,虽然似乎没有完全成功,还有一个新产品,名为“Deep Search”,听起来和“Deep Research”很相似。为了增加一些分量,他们还在测试时计算的类别中加入了 o1、o3、r1 等等。我没有注意到任何真正创新的东西。」
他进一步分享他的看法:
-
Sam Altman 现在可以松口气了。
-
没有颠覆性进展;也没有重大飞跃。幻觉问题依然没有奇迹般解决,等等。
-
话虽如此,OpenAI 的护城河正在不断缩小,因此价格战将继续,除了英伟达(Nvidia)外,其他公司很难获得利润。
-
纯粹的预训练扩展显然未能带来 AGI。
不过,一些在获得 Grok 3 早期使用权的 AI 专家们却并不这么认为。在 Grok 3 发布后,AI 大牛 Andrej Karpathy 也在 X 上从多个维度分享了自己的体验:
思维能力
✅ 首先,Grok 3 显然具备了接近最前沿的思维模型(“Think”按钮),并且在我提出的《卡坦岛》问题上表现出色:
“创建一个网页,展示一个六边形网格,像《卡坦岛》游戏中的板块那样。每个六边形都编号为 1…N,其中 N 是六边形的总数量。使其具有通用性,可以通过滑动条更改‘环数’。例如在卡坦岛中,半径为 3 个六边形。请用单一的 HTML 页面。”
很少有模型能稳定地解决这个问题。OpenAI 顶级的思维模型(例如 o1-pro,月费 200 美元)也能做到,但 DeepSeek-R1、Gemini 2.0 Flash Thinking 和 Claude 都做不到。
❌ 它没有解答我提出的“表情符号谜题”问题,其中包含通过 Unicode 变体选择器隐藏的消息,即使我提供了强烈的提示,并附带了 Rust 代码。DeepSeek-R1 曾部分解码过这个消息。
❓ 它解决了我给它的一些井字棋问题,思路清晰(许多最前沿模型通常会失败)。于是我提高了难度,要求它生成 3 个“棘手”的井字棋局面,它失败了(生成了无意义的棋盘/文本),o1-pro 也失败了。
✅ 我上传了 GPT-2 的论文,提出了一些简单的查询,结果都很不错。然后,我要求它估算训练 GPT-2 所需的训练 FLOP 数量,没有搜索功能。这是一个难题,因为 tokens 数量并未明确列出,所以必须部分估算并进行计算,涉及查找、知识和数学等多个领域。一个例子是:40GB 文本 ≈ 40B 字符 ≈ 40B 字节(假设是 ASCII)≈ 10B tokens(假设每个 token 约 4 字节),以 10 个周期训练 ≈ 100B token 训练运行,参数为 15 亿,且每个参数/每个 token 需要 2+4=6 FLOP,那么总 FLOP 为:100e9 × 1.5e9 × 6 ≈ 1e21 FLOPs。Grok 3 和 4o 都没能解决这个任务,但开启思考模式的 Grok 3 能很好地解答,而 o1-pro(GPT 思维模型)则失败。
我喜欢的是,**这个模型在被要求时会尝试解决黎曼假设,类似于 DeepSeek-R1,但不像许多其他模型(如 o1-pro、Claude、Gemini 2.0 Flash Thinking)那样立刻放弃,只是说这是一个伟大的未解之谜。**我最终不得不停止它的尝试,因为我有点心疼它,但它展现了勇气,谁知道,也许有一天……
总的来说,我的印象是,Grok 3 的能力大约在 o1-pro 的水平,领先于 DeepSeek-R1,当然,我们还需要实际的、真实的评估来进一步确认。
DeepSearch
这个功能非常有趣,似乎结合了 OpenAI 和 Perplexity 所称的“深度研究”与思维能力。不同之处在于,它被命名为“Deep Search”(唉)。它能为你提供高质量的答案,适用于你可能在互联网文章中找到答案的各种研究性/查询性问题。例如,我尝试了几个问题,以下是我从最近的 Perplexity 搜索历史中窃取的内容以及其回答结果:
✅ “即将发布的 Apple 发布会有什么消息?”
✅ “为什么 Palantir 的股票最近上涨?”
✅ “《白莲花 3》在哪里拍摄?是不是和第一、第二季是同一个团队?”
✅ “Bryan Johnson 用的是什么牙膏?”
❌ “《单身即地狱》第四季的演员们现在怎么样了?”
❌ “Simon Willison 提到他用的语音转文字程序是什么?”
❌ 我在这里确实发现了一些不完善的地方。例如,模型似乎默认不喜欢引用 X 作为来源,尽管你可以明确要求它这么做。有几次我发现它虚构了不存在的 URL。有几次它说了一些我认为不准确的事实,并且没有提供出处(可能是因为没有相关引用)。例如,它告诉我“Kim Jeong-su 仍然在和 Kim Min-seol 约会”,这显然是错误的吧?当我要求它生成关于主要 LLM 实验室及其总资金和员工数量的报告时,它列出了 12 个主要实验室,但没有提到它自己(xAI)。
我对 DeepSearch 的印象是,它大约在 Perplexity DeepResearch 提供的水平(这已经很棒了!),但还没有达到 OpenAI 最近发布的“深度研究”水平,后者依然显得更加彻底和可靠(虽然也远非完美,例如当我尝试使用它时,它也错误地排除了 xAI 作为“主要 LLM 实验室”)。
随机的 LLM 挑战
我尝试了一些有趣的 / 随机的 LLM 挑战查询。这些查询对于人类来说很简单,但对 LLMs 来说却很有挑战性,我很好奇 Grok 3 能在这些方面取得多大进展。
✅ Grok 3 知道“草莓”中有 3 个“r”,但它还告诉我,“LOLLAPALOOZA”中只有 3 个“L”。启用思考模式后解决了这个问题。
✅ Grok 3 告诉我 9.11 > 9.9(这是其他 LLMs 常见的错误),但启用思考模式后解决了。
✅ 一些简单的谜题即使没有启用思考模式也能解决得不错,比如:“Sally(一个女孩)有 3 个兄弟。每个兄弟有 2 个姐妹。Sally 有多少个姐妹?” GPT4o 说 2(不正确)。
❌ 可惜模型的幽默感似乎并没有明显提高。这是 LLMs 的常见问题,尤其是在幽默能力和模式崩溃方面。比如,90% 的 1,008 次请求让 ChatGPT 讲笑话的输出都是重复的 25 个笑话。即使在远离简单双关语的细节提示下(例如,给我一个单口相声),它生成的幽默似乎也不算是最前沿的幽默。生成的笑话是:“为什么鸡加入了乐队?因为它有鼓槌,想成为一名咯咯明星!”。在快速测试中,思考模式没有起到太大帮助,可能还让情况变得稍微糟糕了一点。
❌ 模型似乎仍然对“复杂伦理问题”过于敏感,例如它生成了一篇 1 页的文章,基本上拒绝回答是否有伦理理由在救 100 万人时错误性别称呼某人。
❌ Simon Willison 的“生成一个骑自行车的鹈鹕的 SVG”。这考验了 LLM 在二维网格上布置多个元素的能力,这是非常困难的,因为 LLM 无法像人类一样“看”,它是在黑暗中用文本进行布置。尽管这些鹈鹕还不错,但仍有点问题(请参见图像和对比)。Claude 的表现最好,但我怀疑他们可能在训练时专门针对 SVG 能力进行了优化。
总结:根据今天早上大约 2 小时的快速评估,**Grok 3 + 思维模式的表现大致处于 OpenAI 最强模型(o1-pro,月费 200 美元)的前沿水平,略胜于 DeepSeek-R1 和 Gemini 2.0 Flash Thinking。**这在考虑到团队从一年前才开始着手的情况下,表现非常出色,这个时间表在到达前沿领域方面是前所未有的。请记住这些模型是随机的,每次可能会给出不同的答案,而且现在还处于非常早期的阶段,因此我们需要在接下来几天/几周内进行更多的评估。不过,初步的 LM 竞赛结果看起来非常鼓舞人心。现在,对 xAI 团队表示祝贺,他们显然拥有巨大的动力和势头,我很高兴将 Grok 3 添加到我的“LLM 委员会”中,并期待它今后的表现。”

那么,你觉得 Grok 3 的能力如何?
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









