







最近几个月,随着ChatGPT的现象级表现,大模型如雨后春笋般涌现。而模型推理是抽象的算法模型触达具体的实际业务的最后一公里。
但是在这个环节中,仍然还有很多已经是大家共识的痛点和诉求,比如:
- 任何线上产品的用户体验都与服务的响应时长成反比,复杂的模型如何极致地压缩请求时延?
- 模型推理通常是资源常驻型服务,如何通过提升服务单机性能从而增加QPS,同时大幅降低资源成本?
- 端-边-云是现在模型服务发展的必然趋势,如何让离线训练的模型“瘦身塑形”从而在更多设备上快速部署使用?
因此,模型推理的加速优化成为了AI界的重要研究领域。
本文给大家分享大模型推理加速引擎FasterTransformer的基本使用。
①人工智能/大模型学习路线
②AI产品经理入门指南
③大模型方向必读书籍PDF版
④超详细海量大模型实战项目
⑤LLM大模型系统学习教程
⑥640套-AI大模型报告合集
⑦从0-1入门大模型教程视频
⑧AGI大模型技术公开课名额
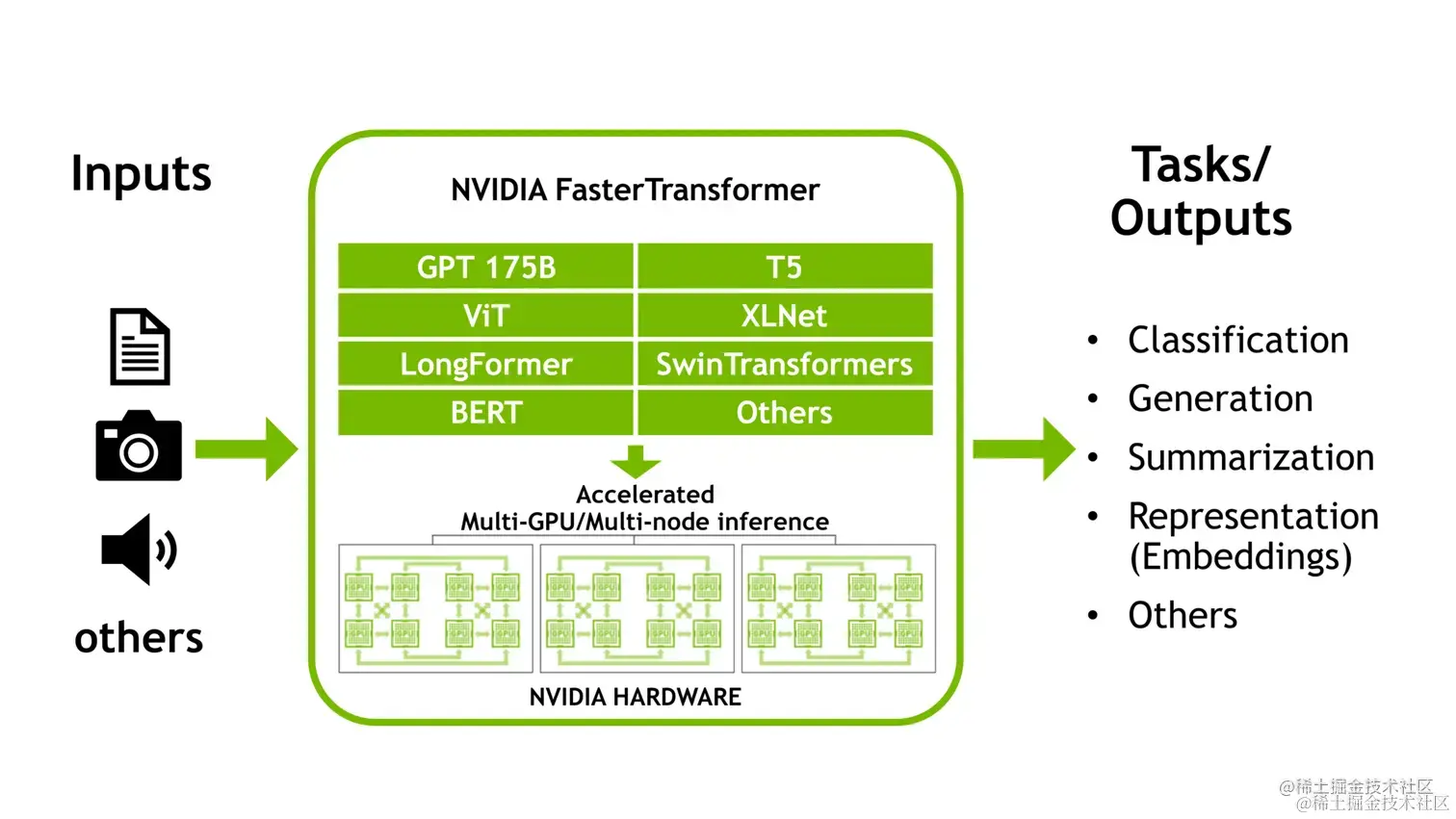
FasterTransformer简介
NVIDIA FasterTransformer (FT) 是一个用于实现基于Transformer的神经网络推理的加速引擎。 它包含Transformer块的高度优化版本的实现,其中包含编码器和解码器部分。使用此模块,您可以运行编码器-解码器架构模型(如:T5)、仅编码器架构模型(如:BERT)和仅解码器架构模型(如: GPT)的推理。
FT框架是用C++/CUDA编写的,依赖于高度优化的 cuBLAS、cuBLASLt 和 cuSPARSELt 库,这使您可以在 GPU 上进行快速的 Transformer 推理。
与NVIDIA TensorRT等其他编译器相比,FT 的最大特点是它支持以分布式方式进行 Transformer 大模型推理。
下图显示了如何使用张量并行 (TP) 和流水线并行 (PP) 技术将基于Transformer架构的神经网络拆分到多个 GPU 和节点上。
- 当每个张量被分成多个块时,就会发生张量并行,并且张量的每个块都可以放置在单独的 GPU 上。在计算过程中,每个块在不同的 GPU 上单独并行处理;最后,可以通过组合来自多个 GPU 的结果来计算最终张量。
- 当模型被深度拆分,并将不同的完整层放置到不同的 GPU/节点上时,就会发生流水线并行。
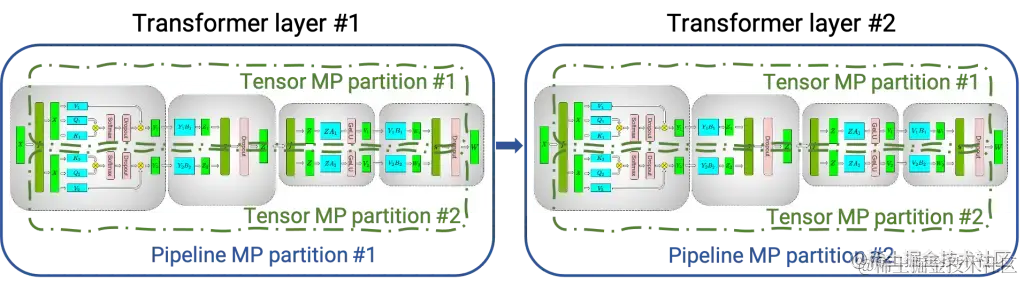
在底层,节点间或节点内通信依赖于 MPI 、 NVIDIA NCCL、Gloo等。因此,使用FasterTransformer,您可以在多个 GPU 上以张量并行运行大型Transformer,以减少计算延迟。同时,TP 和 PP 可以结合在一起,在多 GPU 节点环境中运行具有数十亿、数万亿个参数的大型 Transformer 模型。
除了使用 C ++ 作为后端部署,FasterTransformer 还集成了 TensorFlow(使用 TensorFlow op)、PyTorch (使用 Pytorch op)和 Triton作为后端框架进行部署。当前,TensorFlow op 仅支持单 GPU,而 PyTorch op 和 Triton 后端都支持多 GPU 和多节点。
目前,FT 支持了 Megatron-LM GPT-3、GPT-J、BERT、ViT、Swin Transformer、Longformer、T5 和 XLNet 等模型。您可以在 GitHub 上的 FasterTransformer库中查看最新的支持矩阵。
FT 适用于计算能力 >= 7.0 的 GPU,例如 V100、A10、A100 等。
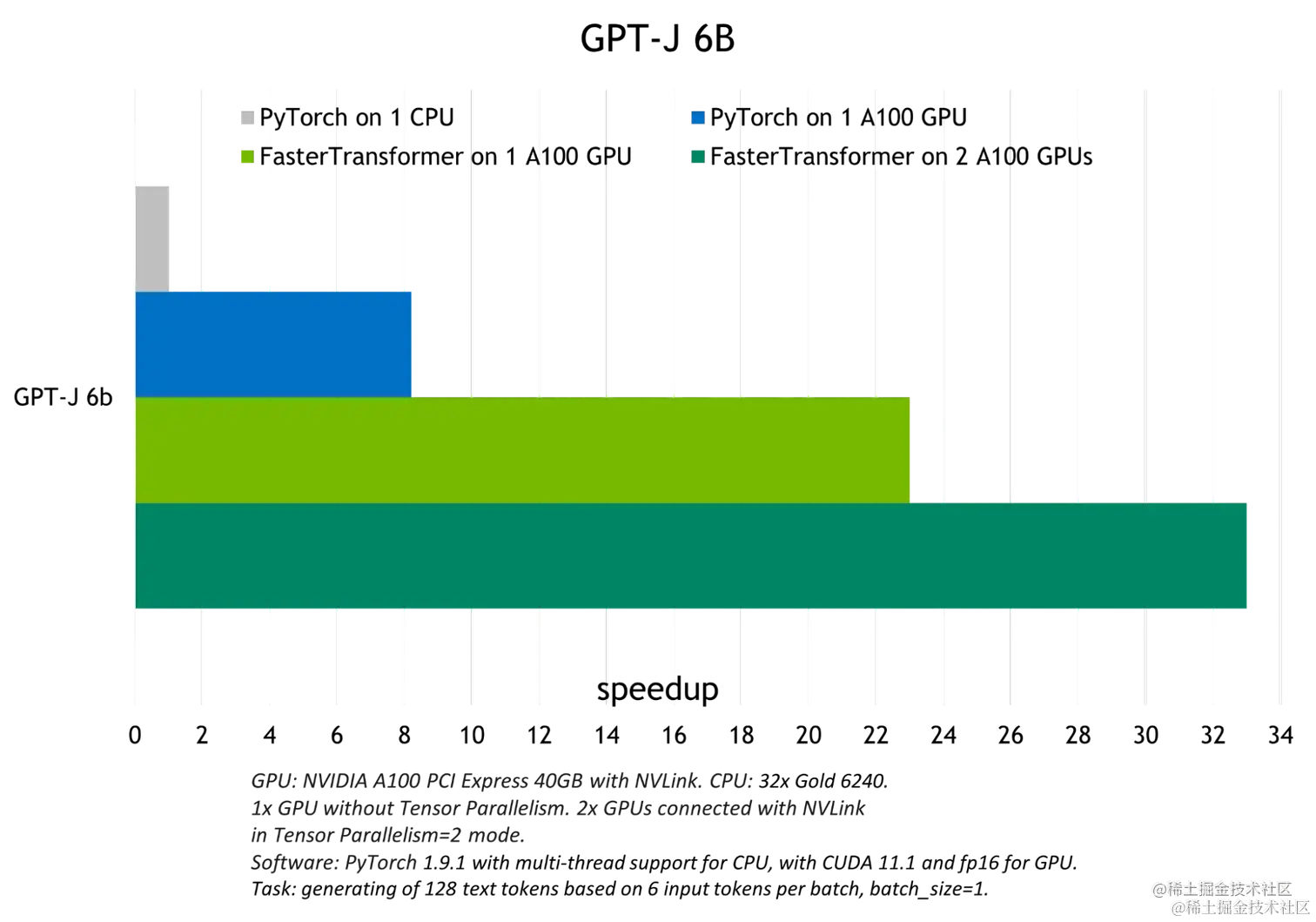
下图展示了 GPT-J 6B 参数的模型推断加速比较:
FasterTransformer 中的优化技术
与深度学习训练的通用框架相比,FT 使您能够获得更快的推理流水线以及基于 Transformer 的神经网络具有更低的延迟和更高的吞吐量。 FT 对 GPT-3 和其他大型Transformer模型进行的一些优化技术包括:
- 层融合(Layer fusion)
这是预处理阶段的一组技术,将多层神经网络组合成一个单一的神经网络,将使用一个单一的核(kernel)进行计算。 这种技术减少了数据传输并增加了数学密度,从而加速了推理阶段的计算。 例如, multi-head attention 块中的所有操作都可以合并到一个核(kernel)中。
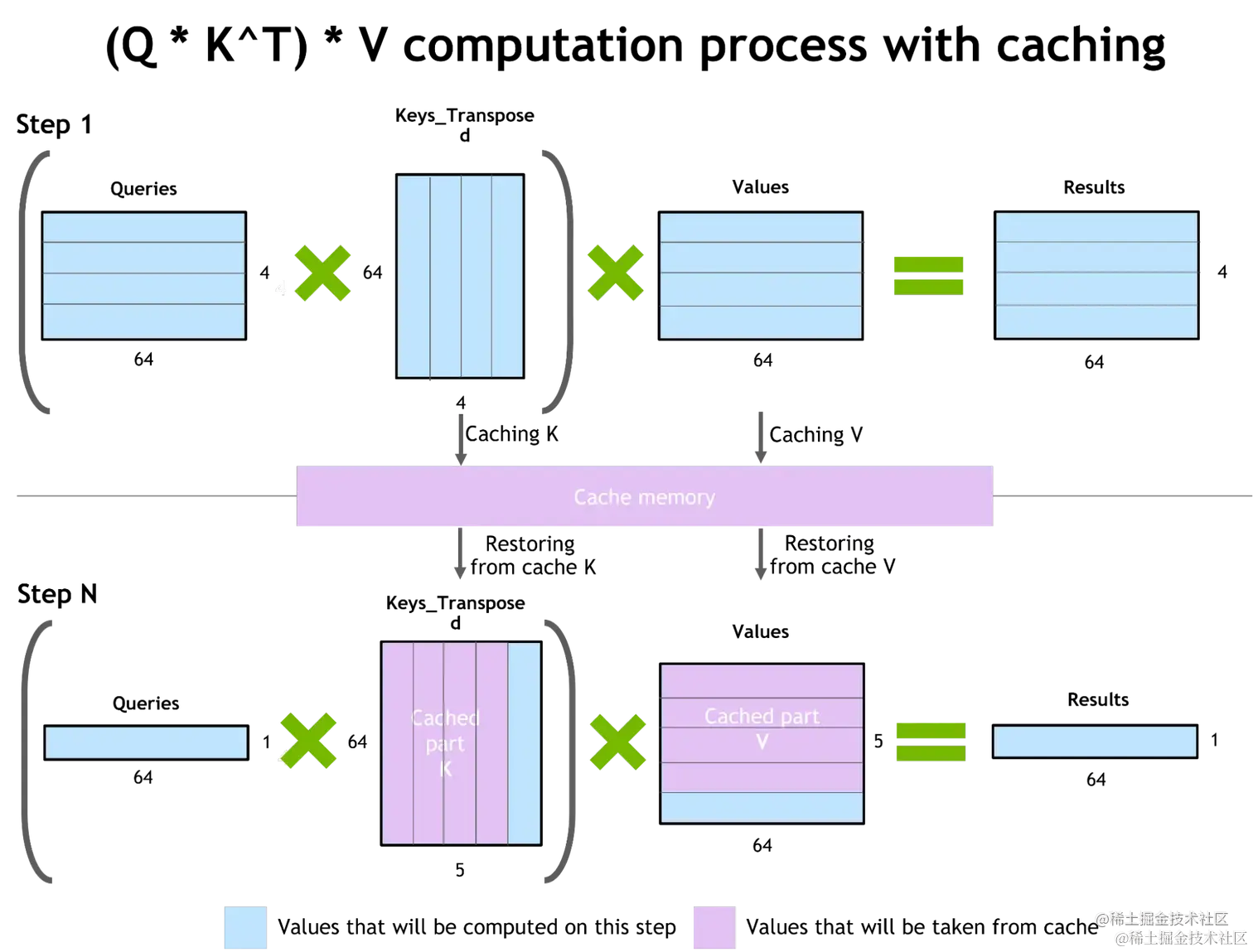
- 自回归模型的推理优化(激活缓存)
为了防止通过Transformer重新计算每个新 token 生成器的先前键和值,FT 分配了一个缓冲区来在每一步存储它们。
虽然需要一些额外的内存使用,但 FT 可以节省重新计算的成本。该过程如下图所示。相同的缓存机制用于 NN 的多个部分。
- 内存优化
与 BERT 等传统模型不同,大型 Transformer 模型具有多达数万亿个参数,占用数百 GB 存储空间。即使我们以半精度存储模型,GPT-3 175b 也需要 350 GB。因此有必要减少其他部分的内存使用。
例如,在 FasterTransformer 中,我们在不同的解码器层重用了激活/输出的内存缓冲(buffer)。由于 GPT-3 中的层数为 96,因此我们只需要 1/96 的内存量用于激活。
- 使用 MPI 和 NCCL 实现节点间/节点内通信并支持模型并行
FasterTransormer 同时提供张量并行和流水线并行。 对于张量并行,FasterTransformer 遵循了 Megatron 的思想。 对于自注意力块和前馈网络块,FT 按行拆分第一个矩阵的权重,并按列拆分第二个矩阵的权重。 通过优化,FT 可以将每个 Transformer 块的归约(reduction)操作减少到两次。
对于流水线并行,FasterTransformer 将整批请求拆分为多个微批,隐藏了通信的空泡(bubble)。 FasterTransformer 会针对不同情况自动调整微批量大小。
- MatMul 核自动调整(GEMM 自动调整)
矩阵乘法是基于Transformer的神经网络中最主要和繁重的操作。 FT 使用来自 CuBLAS 和 CuTLASS 库的功能来执行这些类型的操作。 重要的是要知道 MatMul 操作可以在“硬件”级别使用不同的底层(low-level)算法以数十种不同的方式执行。
GemmBatchedEx 函数实现了 MatMul 操作,并以cublasGemmAlgo_t作为输入参数。 使用此参数,您可以选择不同的底层算法进行操作。
FasterTransformer 库使用此参数对所有底层算法进行实时基准测试,并为模型的参数和您的输入数据(注意层的大小、注意头的数量、隐藏层的大小)选择最佳的一个。 此外,FT 对网络的某些部分使用硬件加速的底层函数,例如: __expf、__shfl_xor_sync。
- 低精度推理
FT 的核(kernels)支持使用 fp16 和 int8 等低精度输入数据进行推理。 由于较少的数据传输量和所需的内存,这两种机制都会加速。 同时,int8 和 fp16 计算可以在特殊硬件上执行,例如:Tensor Core(适用于从 Volta 开始的所有 GPU 架构)和即将推出的 Hopper GPU 中的Transformer引擎。
除此之外还有快速的 C++ BeamSearch 实现、当模型的权重部分分配到八个 GPU 之间时,针对 TensorParallelism 8 模式优化的 all-reduce。
上面简述了FasterTransformer,下面将演示针对 Bloom 模型以 PyTorch 作为后端使用FasterTransformer。
FasterTransformer GPT 简介
下文将会使用BLOOM模型进行演示,而 BLOOM 是一个利用 ALiBi(用于添加位置嵌入) 的 GPT 模型的变体,因此,本文先简要介绍一下 GPT 的相关工作。GPT是仅解码器架构模型的一种变体,没有编码器模块,使用GeLU作为激活。
FasterTransformer GPT 工作流程
下图展示了 FasterTransformer GPT 的工作流程。 与 BERT(仅编码器结构) 和编码器-解码器结构不同,GPT 接收一些输入 id 作为上下文,并生成相应的输出 id 作为响应。 在此工作流程中,主要瓶颈是 GptDecoderLayer(transformer块),因为当我们增加层数时,时间会线性增加。 在 GPT-3 中,GptDecoderLayer 占用了大约 95% 的总时间。
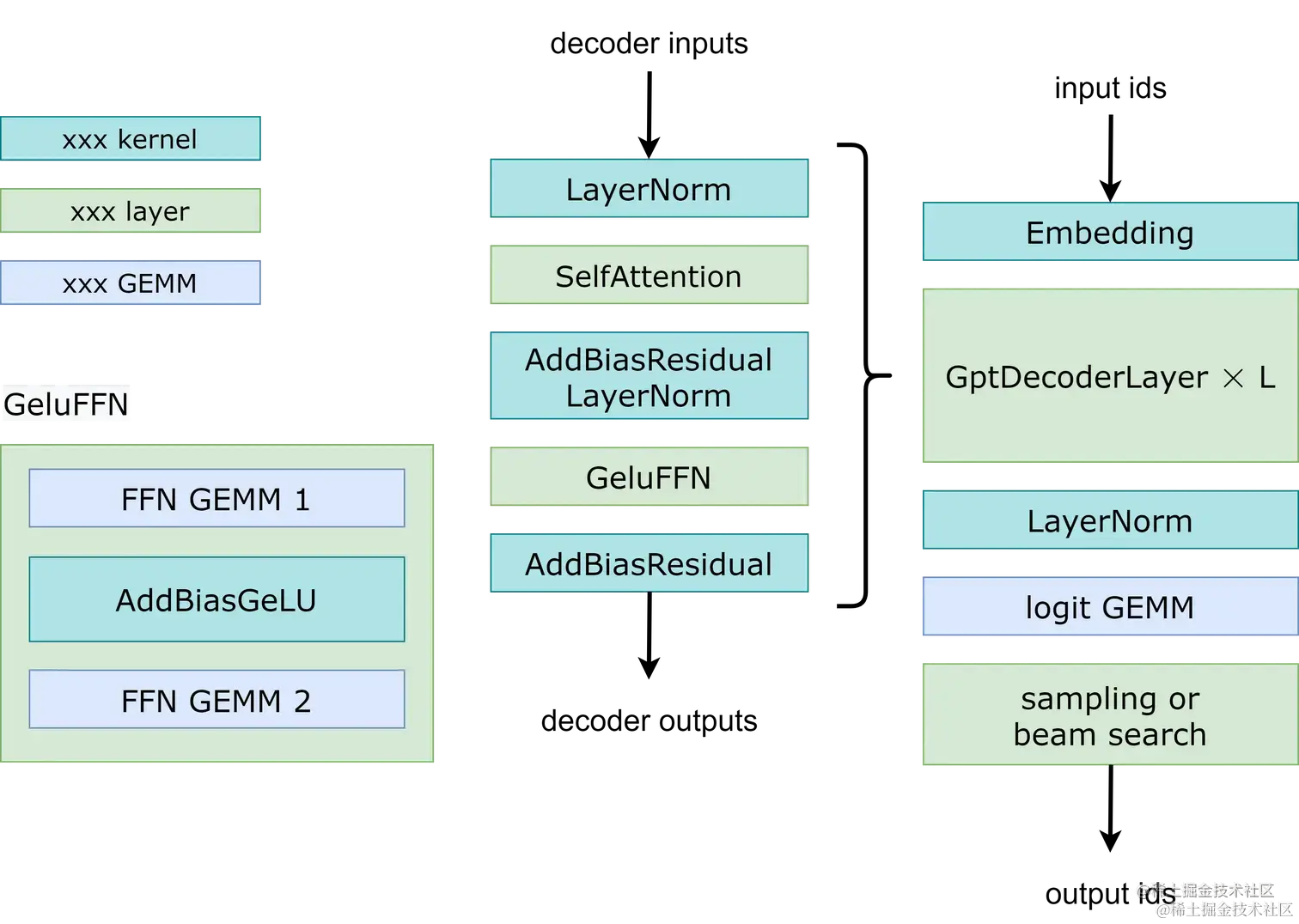
FasterTransformer 将整个工作流程分成两部分。
- 第一部分是“计算上下文(输入 ids)的 k/v 缓存”。
- 第二部分是“自回归生成输出 ids”。
这两部分的操作类似,只是SelfAttention中张量的形状不同。 因此,我们使用 2 种不同的实现来处理两种不同的情况,如下图所示。
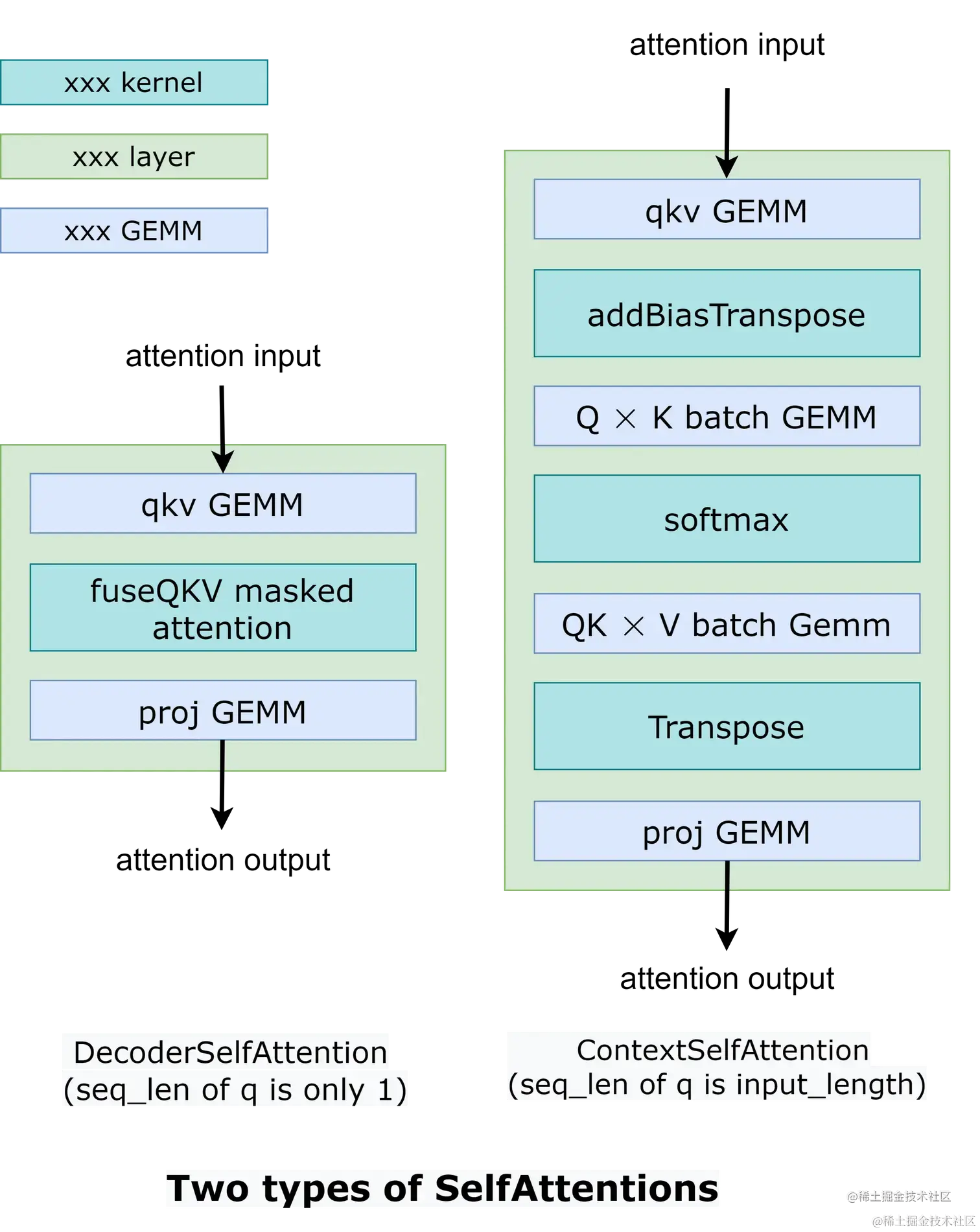
在 DecoderSelfAttention 中,查询的序列长度始终为 1,因此我们使用自定义的 fused masked multi-head attention kernel 来处理。 另一方面,ContextSelfAttention 中查询的序列长度是最大输入长度,因此我们使用 cuBLAS 来利用tensor core。
以下的示例演示了如何运行多 GPU 和多节点的 GPT 模型。
examples/cpp/multi_gpu_gpt_example.cc:它使用MPI来组织所有的GPU。examples/cpp/multi_gpu_gpt_triton_example.cc:它在节点内使用线程,在节点间使用 MPI。 此示例还演示了如何使用基于 FasterTransformer 的 Triton 后端 API 来运行 GPT 模型。examples/pytorch/gpt/multi_gpu_gpt_example.py:这个例子和examples/cpp/multi_gpu_gpt_example.cc类似,但是通过PyTorch OP封装了FasterTransformer的实例。
总之,运行 GPT 模型的工作流程是:
- 通过 MPI 或线程初始化 NCCL 通信并设置张量并行和流水线并行的ranks
- 按张量并行、流水线并行和其他模型超参数的ranks加载权重。
- 通过张量并行、流水线并行和其他模型超参数的ranks创建ParalelGpt实例。
- 接收来自客户端的请求并将请求转换为 ParallelGpt 的输入张量格式。
- 运行forward
- 将 ParallelGpt 的输出张量转换为客户端的响应并返回响应。
在C++示例代码中,我们跳过第4步和第6步,通过examples/cpp/multi_gpu_gpt/start_ids.csv加载该请求。 在 PyTorch 示例代码中,该请求来自 PyTorch 端。 在 Triton 示例代码中,我们有从步骤 1 到步骤 6 的完整示例。
源代码放在 src/fastertransformer/models/multi_gpu_gpt/ParallelGpt.cc 中。其中,GPT的构造函数参数包括head_num、num_layer、tensor_para、pipeline_para等,GPT的输入参数包括input_ids、input_lengths、output_seq_len等;GPT的输出参数包括output_ids(包含 input_ids 和生成的 id)、sequence_length、output_log_probs、cum_log_probs、context_embeddings。
FasterTransformer GPT 优化
- 核优化:很多核都是基于已经高度优化的解码器和解码码模块的核。为了防止重新计算以前的键和值,我们将在每一步分配一个缓冲区来存储它们。 虽然它需要一些额外的内存使用,但我们可以节省重新计算的成本。
- 内存优化:与 BERT 等传统模型不同,GPT-3 有 1750 亿个参数,即使我们以半精度存储模型也需要 350 GB。 因此,我们必须减少其他部分的内存使用。 在 FasterTransformer 中,我们将重用不同解码器层的内存缓冲。 由于 GPT-3 的层数是 96,我们只需要 1/96 的内存。
- 模型并行:在GPT模型中,FasterTransormer同时提供张量并行和流水线并行。 对于张量并行,FasterTransformer 遵循了 Megatron 的思想。 对于自注意力块和前馈网络块,我们按行拆分第一个矩阵乘法的权重,按列拆分第二个矩阵乘法的权重。 通过优化,我们可以将每个transformer block的归约操作减少到 2 次,工作流程如下图所示。对于流水线并行,FasterTransformer 将整批请求拆分为多个微批并隐藏通信空泡。 FasterTransformer 会针对不同情况自动调整微批量大小。 用户可以通过修改
gpt_config.ini文件来调整模型并行度。 我们建议在节点内使用张量并行,在节点间使用流水线并行,因为,张量并行需要更多的 NCCL 通信。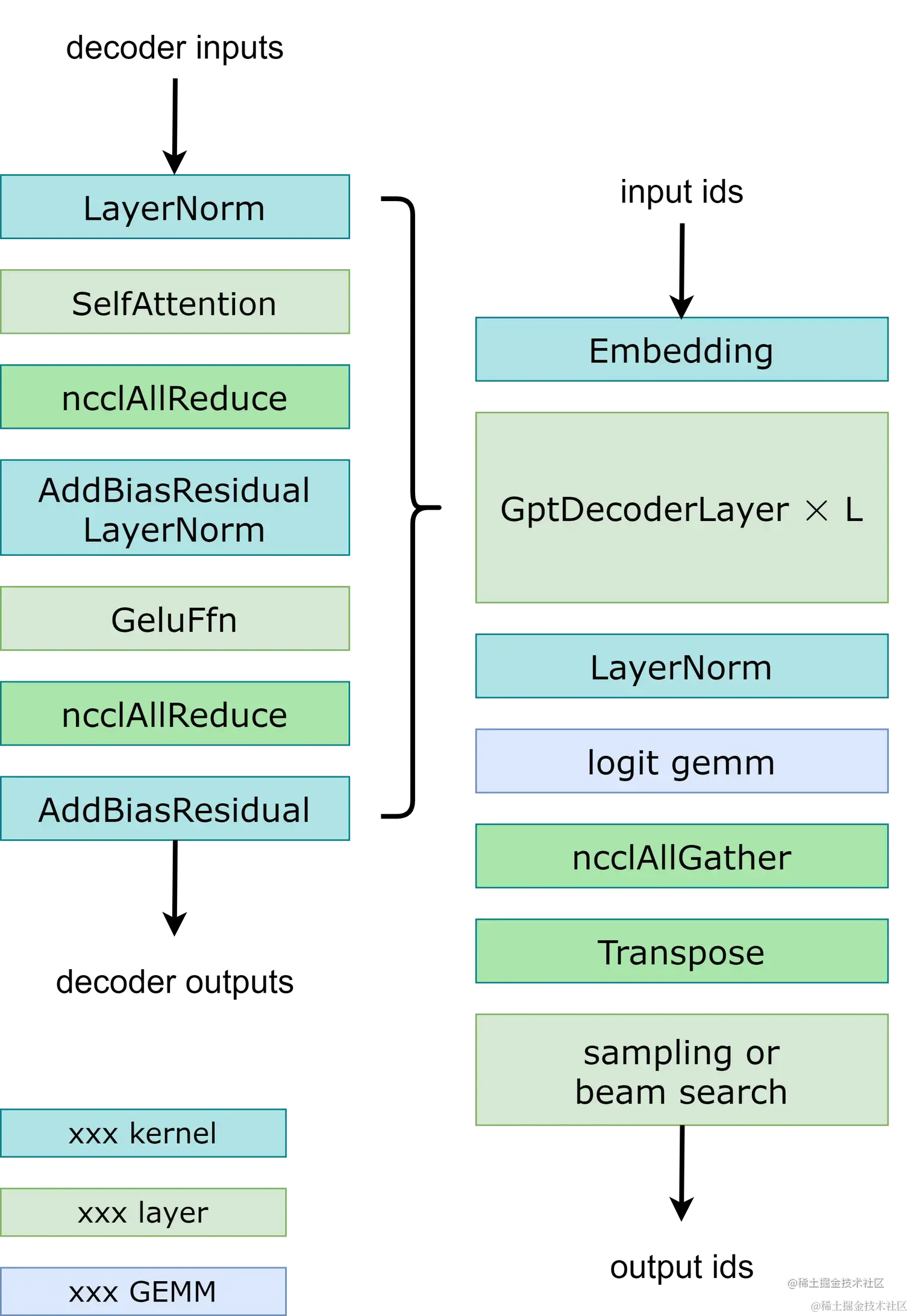
- 多框架:FasterTransformer除了c上的源代码,还提供了TensorFlow op、PyTorch op和Triton backend。 目前TensorFlow op只支持单GPU,而PyTorch op和Triton backend支持多GPU和多节点。 FasterTransformer 还提供了一个工具,可以将 Megatron 的模型拆分并转换为FasterTransformer二进制文件,以便 FasterTransformer 可以直接加载二进制文件,从而避免为模型并行而进行的额外拆分模型工作。
FasterTransformer GPT 推理选项
FasterTransformer GPT 还提供环境变量以针对特定用途进行调整。
| 名称 | 描述 | 默认值 | 可接受的值 |
|---|---|---|---|
FMHA_ENABLE |
启用融合多头注意力核 (fp16 accumulation) | disabled | ON = enable fmha, otherwise disabled |
CONTEXT_ATTENTION_BMM1_HALF_ACCUM |
对 qk gemm 使用 fp16 累加,并且只对未融合的多头注意力核产生影响 | fp32 accumulation | ON = fp32 accumulation, otherwise fp16 accumulation |
环境搭建
基础环境配置
首先确保您具有以下组件:
- NVIDIA Docker 和 NGC 容器
- NVIDIA Pascal/Volta/Turing/Ampere 系列的 GPU
基础组件版本要求:
- CMake: 3.13及以上版本
- CUDA: 11.0及以上版本
- NCCL: 2.10及以上版本
- Python: 3.8.13
- PyTorch: 1.13.0
这些组件在 Nvidia 官方提供的 TensorFlow/PyTorch Docker 镜像中很容易获得。
构建FasterTransformer
推荐使用Nvidia官方提供的镜像,如: nvcr.io/nvidia/tensorflow:22.09-tf1-py3 、 nvcr.io/nvidia/pytorch:22.09-py3等,当然也可以使用Pytorch官方提供的镜像。
首先,拉取相应版本的PyTorch镜像。
bash
复制代码
docker pull nvcr.io/nvidia/pytorch:22.09-py3
镜像下载完成之后,创建容器,以便后续进行编译和构建FasterTransformer。
bash
复制代码
nvidia-docker run -dti --name bloom_faster_transformer \
--restart=always --gpus all --network=host \
--shm-size 5g \
-v /home/gdong/workspace/code:/workspace/code \
-v /home/gdong/workspace/data:/workspace/data \
-v /home/gdong/workspace/model:/workspace/model \
-v /home/gdong/workspace/output:/workspace/output \
-w /workspace \
nvcr.io/nvidia/pytorch:22.09-py3 \
bash
进入容器。
bash
复制代码
docker exec -it bloom_faster_transformer bash
下载FasterTransformer代码。
bash
复制代码
cd code
git clone https://github.com/NVIDIA/FasterTransformer.git
cd FasterTransformer/
git submodule init && git submodule update
进入build构建FasterTransformer。
bash
复制代码
mkdir -p build
cd build
然后,执行cmake PATH命令生成 Makefile 文件。
ini
复制代码
cmake -DSM=80 -DCMAKE_BUILD_TYPE=Release -DBUILD_PYT=ON -DBUILD_MULTI_GPU=ON ..
注意:
第一点:脚本中-DMS=xx的xx表示GPU的计算能力。下表显示了常见GPU的计算能力。
| GPU | 计算能力 |
|---|---|
| P40 | 60 |
| P4 | 61 |
| V100 | 70 |
| T4 | 75 |
| A100 | 80 |
| A30 | 80 |
| A10 | 86 |
默认情况下,-DSM 设置为 70、75、80 和 86。当用户设置更多类型的 -DSM 时,需要更长的编译时间。 因此,我们建议只为您使用的设备设置 -DSM。
第二点:本文使用Pytorch作为后端,因此,脚本中添加了-DBUILD_PYT=ON配置项。这将构建 TorchScript 自定义类。 因此,请确保 PyTorch 版本大于 1.5.0。
运行过程:
sql
复制代码
-- The CXX compiler identification is GNU 9.4.0
-- The CUDA compiler identification is NVIDIA 11.8.89
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Detecting CUDA compiler ABI info
-- Detecting CUDA compiler ABI info - done
-- Check for working CUDA compiler: /usr/local/cuda/bin/nvcc - skipped
-- Detecting CUDA compile features
-- Detecting CUDA compile features - done
-- Looking for C++ include pthread.h
-- Looking for C++ include pthread.h - found
-- Performing Test CMAKE_HAVE_LIBC_PTHREAD
-- Performing Test CMAKE_HAVE_LIBC_PTHREAD - Failed
-- Looking for pthread_create in pthreads
-- Looking for pthread_create in pthreads - not found
-- Looking for pthread_create in pthread
-- Looking for pthread_create in pthread - found
-- Found Threads: TRUE
-- Found CUDA: /usr/local/cuda (found suitable version "11.8", minimum required is "10.2")
CUDA_VERSION 11.8 is greater or equal than 11.0, enable -DENABLE_BF16 flag
-- Found CUDNN: /usr/lib/x86_64-linux-gnu/libcudnn.so
-- Add DBUILD_CUTLASS_MOE 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}