






近几个月,几乎每个行业的小伙伴都了解到了ChatGPT的可怕能力。你知道么,ChatGPT之所以如此厉害,是因为它用到了几万张NVIDA Tesla A100显卡做AI推理和图形计算。
本文就简单分享下GPU的相关内容,欢迎阅读。
GPU是什么?
GPU的英文全称Graphics Processing Unit,图形处理单元。
说直白一点:GPU是一款专门的图形处理芯片,做图形渲染、数值分析、金融分析、密码破解,以及其他数学计算与几何运算的。GPU可以在PC、工作站、游戏主机、手机、平板等多种智能终端设备上运行。
GPU和显卡的关系,就像是CPU和主板的关系。前者是显卡的心脏,后者是主板的心脏。有些小伙伴会把GPU和显卡当成一个东西,其实还有些差别的,显卡不仅包括GPU,还有一些显存、VRM稳压模块、MRAM芯片、总线、风扇、外围设备接口等等。

①人工智能/大模型学习路线
②AI产品经理入门指南
③大模型方向必读书籍PDF版
④超详细海量大模型实战项目
⑤LLM大模型系统学习教程
⑥640套-AI大模型报告合集
⑦从0-1入门大模型教程视频
⑧AGI大模型技术公开课名额
GPU和CPU谁最强呢?
这个其实不好说,好点的GPU内部的晶体管数量可以超过CPU,CPU的强项是做逻辑运算,GPU的强项是做数学运算和图形渲染。这就ChatGPT用大量高性能显卡做AI推理的原因。
接下来,我们做个简单的对比。
- 结构组成不同
CPU和GPU都是运算的处理器,在架构组成上都包括3个部分:运算单元ALU、控制单元Control和缓存单元Cache。
但是,三者的组成比例却相差很大。
在CPU中缓存单元大概占50%,控制单元25%,运算单元25%;
在GPU中缓存单元大概占5%,控制单元5%,运算单元90%。

结构组成上的巨大差异说明:CPU的运算能力更加均衡,但是不适合做大量的运算;GPU更适合做大量运算。
这倒不是说GPU更牛X,实际上GPU更像是一大群工厂流水线上的工人,适合做大量的简单运算,很复杂的搞不了。但是简单的事情做得非常快,比CPU要快得多。
相比GPU,CPU更像是技术专家,可以做复杂的运算,比如逻辑运算、响应用户请求、网络通信等。但是因为ALU占比较少、内核少,所以适合做相对少量的复杂运算。

- 缓存不同
在CPU里面,大概50%是缓存单元,并且是四级缓存结构;而在GPU中,缓存是一级或者二级的。
- 浮点运算方式不同
CPU性能更加注重线程的性能,在控制部分做的事情较多,这样做就是为了确保控制指令不能中断,在浮点计算上功耗少。
相较于CPU,GPU的结构更为简单,基本上它也只做单精度或双精度浮点运算。GPU的运算速度更快,吞吐量也更高。
- 响应方式不同
CPU基本上是实时响应,采用多级缓存来保障多个任务的响应速度。
GPU往往采用的是批处理的机制,即:任务先排好队,挨个处理。
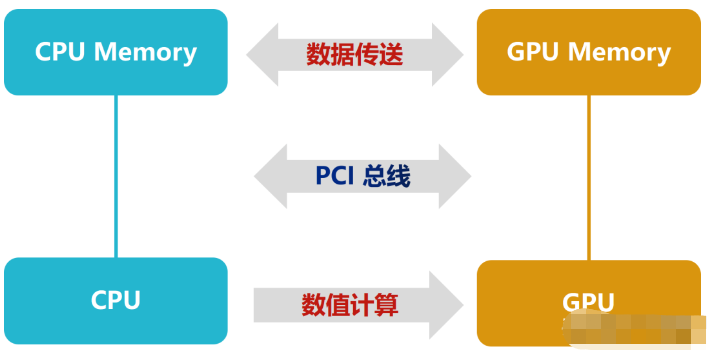
GPU对于图形处理
我们假设在实时渲染中,一帧1080*720P的图片,那么这张图就有大概777600个像素点。如果按照最基本的24帧/秒的帧率计算。1秒钟就要求计算机处理18662400个,即:1866.24万个像素点。
这还是高清的情况下,如果是1090*1080、2K、4K甚至8K的视频渲染,可想而知,这个计算量是何其巨大。尤其是在像游戏这样的实时渲染场景下,显然仅仅依靠CPU渲染是会超时的。
实际上,在屏幕中显示的三维物体都要经过多重的坐标变换,并且物体的表面会受到环境中各种光线的影响,呈现不同的颜色和阴影。这就包括了光线的漫射、折射、透射、散射等。

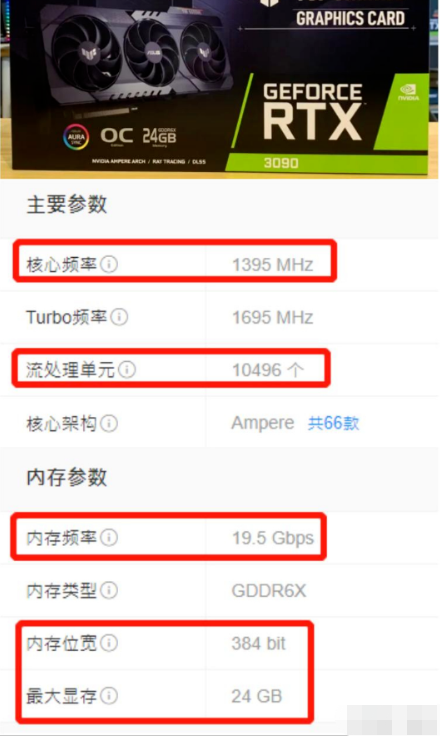
接下来,我们以英伟达NVIDIA RTX3090 为例,看下GPU是如何进行渲染的。
RTX3090的流式多处理器有10496个,每个内核都有具备整数运算和浮点运算的部分,还有用于在操作数中排队和收集结果的部分。
所谓流式多处理器可以认为是一个独立的任务处理单元,也可以认为一颗GPU包含了10496个CPU同时处理各个图片处理任务。
我们就可以通过算法和程序,对1秒钟18662400个像素点的整体任务进行切割分片,让10496颗处理器并行计算。
这样的话,每个处理器负责大概每秒处理18662400/10496,即1778个像素点的渲染任务就行了。
如下图所示,在GPU中会划分为多个流式处理区,每个处理区包含数百个内核,每个内核相当于一颗简化版的CPU,具备整数运算和浮点运算的功能,以及排队和结果收集功能。

注意,除了流处理器CUDA以外,影响GPU性能的还有
-
核心频率:频率越高,性能越强、功耗也越高。
-
显示位宽:单位是bit,位宽决定了显卡同时可以处理的数据量,越大越好。
-
显存容量:显存容量越大,代表能缓存的数据就越多。
-
显存频率:单位是MHz或bps,显存频率越高,图形数据传输速度就越快。
总结
一言以蔽之,GPU不管是处理图形渲染、数值分析,还是处理AI推理。底层逻辑都是将极为繁重的数学进行任务拆解,化繁为简。
然后,利用GPU多流处理器的机制,将大量的运算拆解为一个个小的、简单的运算,并行处理。我们也可以认为一个GPU就是一个集群,里面每个流处理器都是一颗CPU,这样就容易理解了。

以上是关于GPU概念、工作原理的简要介绍。说是简单,其实在图形处理方面,还有很多深层次的处理逻辑没有展开,比如像素位置变换、三角原理等等。感兴趣的小伙伴可以深入研究下。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}