






本文为[P365天深度学习训练营](https://mp.weixin.qq.com/s/0 dvHCa0oFnW8SCp3 JpzKxg)中的学习记录博客
原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)
一、理论知识储备
1.CNN算法发展
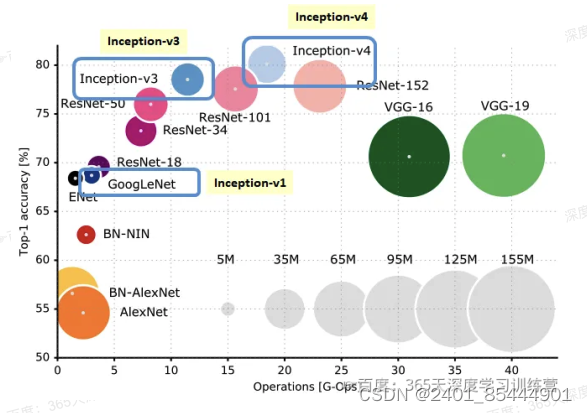
首先借用一下来自于网络的插图,在这张图上列出了一些有里程碑意义的、经典卷积神经网络。评估 网络的性能,一个维度是识别精度,另一个维度则是网络的复杂度(计算量)。从这张图里,我们能看到:
(1)2012年,AlexNet是由Alex Krizhevsky、ya Sutskever和Geoffrey Hinton在2012年ImageNet 图像分类竞赛中提出的一种经典的卷积神经网络。AlexNet:是首个深层卷积神经网络,同时也引入了ReLU 激活函数、局部归一化、数据增强和Dropout处理。
(2)VGG-16和VGG-19,这是依靠多层卷积+池化层堆叠而成的一个网络,其性能在当时也还不
但是计算量巨大。VGG-16的网络结构在前面已经总结过,是将深层网络结构分为几个组,每组堆叠数量不等的Conv-ReLU层,并在最后一层使用MaxPool缩减特征图尺寸。
(3)GoogLeNet(也就是Inception V1),这是一个提出了使用并联卷积结构、且在每个通路中使
用不同卷积核的网络,并且随后衍生出V2、V3、V4等一系列网络结构,构成一个家族。
(4)ResNet,。有V1、V2、NeXt等不同的版本,这是一个提出恒等映射概念、具有短路直接路径、
莫块化的网络结构,可以很方便地扩展为18~1001层(ResNet-18、ResNet-34、ResNet--50、ResNet-- 01中的数字都是表示网络层数)。
65天深度学习训练营
(5)DenseNet,这是一种具有前级特征重用、层间直连、结构递归扩展等特点的卷积网络。
2. 残差网络的由来
深度残差网络ResNet(deep residual network)在2015年由何恺明等提出,因为它简单与实用并存,
随后很多研究都是建立在ResNet-50或者ResNet-101基础上完成。
ResNet:主要解决深度卷积网络在深度加深时候的“退化”问题。在一般的卷积神经网络中,增大网络深度后带来的第一个问题就是梯度消失、爆炸,这个问题Szegedy?提出BN层后被顺利解决。BN层能对各层的输出做归一化,这样梯度在反向层层传递后仍能保持大小稳定,不会出现过小或过大的情况。但是作者发现加了BN后再加大深度仍然不容易收敛,其提到了第二个问题--准确率下降问题:层级大到一定程度时准确率就会饱和,然后迅速下降,这种下降即不是梯度消失引起的也不是过拟合造成的,而是由于网络过于复杂,以至于光靠不加约束的放养式的训练很难达到理想的错误率。
准确率下降问题不是网络结构本身的问题,而是现有的训练方式不够理想造成的。当前广泛使用的优化器,无论是SGD,还是RMSProp,或是Adam,都无法在网络深度变大后达到理论上最优的收敛结果。
作者在文中证明了只要有合适的网络结构,更深的网络肯定会比较浅的网络效果要好。证明过程也很简单:假设在一种网络A的后面添加几层形成新的网络B,如果增加的层级只是对A的输出做了个恒等映射(identity mapping),即A的输出经过新增的层级变成B的输出后没有发生变化,这样网络A和网络B 的错误率就是相等的,也就证明了加深后的网络不会比加深前的网络效果差。口口
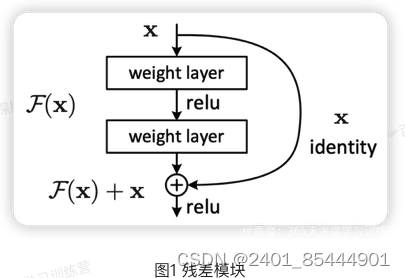
何恺明提出了一种残差结构来实现上述恒等映射(图):整个模块除了正常的卷积层输出外,还有一个分支把输入直接连到输出上,该分支输出和卷积的输出做算术相加得到最终的输出,用公式表达就是H(x)=F(x)十xX是输入,F(x)是卷积分支的输出,H(x)是整个结构的输出。可以证明如果F(x)分支中所有参数都是0H(x)就是个恒等映射。残差结构人为制造了恒等映射,就能让整个结构朝着恒等映射的方向去收敛,确保最终的错误率不会因为深度的变大而越来越差。如果一个网络通过简单的手工设置参数值就能达到想要的结果,那这种结构就很容易通过训练来收敛到该结果,这是一条设计复杂的网络时通用的规则。
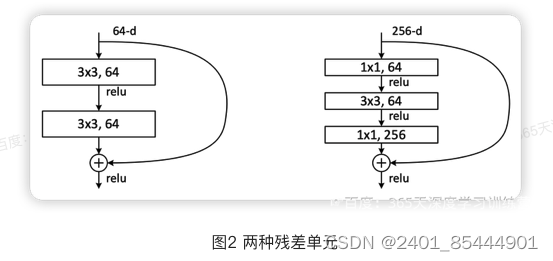
图2左边的单元为ResNet两层的残差单元,两层的残差单元包含两个相同输出的通道数的3x3卷
积,只是用于较浅的ResNet网络,对较深的网络主要使用三层的残差单元。三层的残差单元又称为 bottleneck结构,先用一个1x1卷积进行降维,然后3x3卷积,最后用1x1升维恢复原有的维度。另外,如果有输入输出维度不同的情况,可以对输入做一个线性映射变换维度,再连接后面的层。三层的残差单元对于相同数量的层又减少了参数量,因此可以拓展更深的模型。通过残差单元的组合有经典的ResNet-50,ResNet-101等网络结构。
import torch
import torchvision
import torch.nn as nn
import os, PIL, pathlib, warnings
from torchvision import transforms, datasets
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
data_dir = './data/bird_photos'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob("*"));
classeNames = [str(path).split("/")[-1] for path in data_paths]
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
total_data = datasets.ImageFolder('./data/bird_photos', transform=train_transforms)
total_data.class_to_idx
train_size = int(len(total_data)*0.8)
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
batch_size = 8
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, num_workers=1)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
import torch.nn.functional as F
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class IdentityBlock(nn.Module):
def __init__(self,in_channels,kernel_size,out_channels):
super(IdentityBlock, self).__init__()
out_channels1, out_channels2, out_channels3 = out_channels
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels1, kernel_size=1),
nn.BatchNorm2d(out_channels1),
nn.ReLU(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(out_channels1, out_channels2, kernel_size=kernel_size, padding=autopad(kernel_size)),
nn.BatchNorm2d(out_channels2),
nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv2d(out_channels2, out_channels3, kernel_size=1),
nn.BatchNorm2d(out_channels3)
)
def forward(self,x):
x1 = self.conv1(x)
x1 = self.conv2(x1)
x1 = self.conv3(x1)
x = x1 + x
x = nn.ReLU()(x)
return x
class ConvBlock(nn.Module):
def __init__(self, in_channels, kernel_size, out_channels, stride=2):
super(ConvBlock, self).__init__()
out_channels1, out_channels2, out_channels3 = out_channels
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels1, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels1),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(out_channels1, out_channels2, kernel_size=kernel_size, padding=autopad(kernel_size)),
nn.BatchNorm2d(out_channels2),
nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv2d(out_channels2, out_channels3, kernel_size=1),
nn.BatchNorm2d(out_channels3),
nn.ReLU()
)
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels3, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels3)
)
def forward(self, x):
x1 = self.conv1(x)
x1 = self.conv2(x1)
x1 = self.conv3(x1)
x2 = self.shortcut(x)
x = x1 + x2
nn.ReLU()(x)
return x
class ResNet50(nn.Module):
def __init__(self, classes=1000):
super(ResNet50, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 7, stride=2, padding=3, padding_mode="zeros"),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.conv2 = nn.Sequential(
ConvBlock(64, 3, [64,64,256], stride=1),
IdentityBlock(256, 3, [64,64,256]),
IdentityBlock(256, 3, [64,64,256])
)
self.conv3 = nn.Sequential(
ConvBlock(256, 3, [128, 128, 512]),
IdentityBlock(512, 3, [128, 128, 512]),
IdentityBlock(512, 3, [128, 128, 512]),
IdentityBlock(512, 3, [128, 128, 512])
)
self.conv4 = nn.Sequential(
ConvBlock(512, 3, [256, 256, 1024]),
IdentityBlock(1024, 3, [256, 256, 1024]),
IdentityBlock(1024, 3, [256, 256, 1024]),
IdentityBlock(1024, 3, [256, 256, 1024]),
IdentityBlock(1024, 3, [256, 256, 1024]),
IdentityBlock(1024, 3, [256, 256, 1024])
)
self.conv5 = nn.Sequential(
ConvBlock(1024, 3, [512, 512, 2048]),
IdentityBlock(2048, 3, [512, 512, 2048]),
IdentityBlock(2048, 3, [512, 512, 2048])
)
self.pool = nn.AvgPool2d((7,7))
self.fc = nn.Linear(2048, 4)
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.pool(x)
x = torch.flatten(x, start_dim=1)
x = self.fc(x)
return x
model = ResNet50().to(device)
model
import torchsummary as summary
summary.summary(model, (3, 224, 224))
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0,0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == y ).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_loss, test_acc
import copy
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
loss_fn = nn.CrossEntropyLoss()
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 保存最佳模型到 best_model
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss,epoch_test_acc * 100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
print('Done')
import matplotlib.pyplot as plt
# 隐藏警告
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
from PIL import Image
classes = list(total_data.class_to_idx)
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
plt.imshow(test_img) # 展示预测的图片
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_, pred = torch.max(output, 1)
pred_class = classes[pred]
print(f'预测结果是:{pred_class}')
predict_one_image(image_path='./data/bird_photos/Bananaquit/007.jpg',
model=model,
transform=train_transforms,
classes=classes)
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
print(epoch_test_acc, epoch_test_loss)
print(epoch_test_acc)
输出
device(type='cuda')
total_data.class_to_idx
total_data.class_to_idx
{'Bananaquit': 0,
'Black Skimmer': 1,
'Black Throated Bushtiti': 2,
'Cockatoo': 3}
Shape of X [N, C, H, W]: torch.Size([8, 3, 224, 224])
Shape of y: torch.Size([8]) torch.int64
ResNet50(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): ConvBlock(
(conv1): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(shortcut): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(conv3): Sequential(
(0): ConvBlock(
(conv1): Sequential(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(shortcut): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(conv4): Sequential(
(0): ConvBlock(
(conv1): Sequential(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(shortcut): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(4): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(conv5): Sequential(
(0): ConvBlock(
(conv1): Sequential(
(0): Conv2d(1024, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(shortcut): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): IdentityBlock(
(conv1): Sequential(
(0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv3): Sequential(
(0): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(pool): AvgPool2d(kernel_size=(7, 7), stride=(7, 7), padding=0)
(fc): Linear(in_features=2048, out_features=4, bias=True)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,472
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 55, 55] 0
Conv2d-5 [-1, 64, 55, 55] 4,160
BatchNorm2d-6 [-1, 64, 55, 55] 128
ReLU-7 [-1, 64, 55, 55] 0
Conv2d-8 [-1, 64, 55, 55] 36,928
BatchNorm2d-9 [-1, 64, 55, 55] 128
ReLU-10 [-1, 64, 55, 55] 0
Conv2d-11 [-1, 256, 55, 55] 16,640
BatchNorm2d-12 [-1, 256, 55, 55] 512
ReLU-13 [-1, 256, 55, 55] 0
Conv2d-14 [-1, 256, 55, 55] 16,640
BatchNorm2d-15 [-1, 256, 55, 55] 512
ConvBlock-16 [-1, 256, 55, 55] 0
Conv2d-17 [-1, 64, 55, 55] 16,448
BatchNorm2d-18 [-1, 64, 55, 55] 128
ReLU-19 [-1, 64, 55, 55] 0
Conv2d-20 [-1, 64, 55, 55] 36,928
BatchNorm2d-21 [-1, 64, 55, 55] 128
ReLU-22 [-1, 64, 55, 55] 0
Conv2d-23 [-1, 256, 55, 55] 16,640
BatchNorm2d-24 [-1, 256, 55, 55] 512
IdentityBlock-25 [-1, 256, 55, 55] 0
Conv2d-26 [-1, 64, 55, 55] 16,448
BatchNorm2d-27 [-1, 64, 55, 55] 128
ReLU-28 [-1, 64, 55, 55] 0
Conv2d-29 [-1, 64, 55, 55] 36,928
BatchNorm2d-30 [-1, 64, 55, 55] 128
ReLU-31 [-1, 64, 55, 55] 0
Conv2d-32 [-1, 256, 55, 55] 16,640
BatchNorm2d-33 [-1, 256, 55, 55] 512
IdentityBlock-34 [-1, 256, 55, 55] 0
Conv2d-35 [-1, 128, 28, 28] 32,896
BatchNorm2d-36 [-1, 128, 28, 28] 256
ReLU-37 [-1, 128, 28, 28] 0
Conv2d-38 [-1, 128, 28, 28] 147,584
BatchNorm2d-39 [-1, 128, 28, 28] 256
ReLU-40 [-1, 128, 28, 28] 0
Conv2d-41 [-1, 512, 28, 28] 66,048
BatchNorm2d-42 [-1, 512, 28, 28] 1,024
ReLU-43 [-1, 512, 28, 28] 0
Conv2d-44 [-1, 512, 28, 28] 131,584
BatchNorm2d-45 [-1, 512, 28, 28] 1,024
ConvBlock-46 [-1, 512, 28, 28] 0
Conv2d-47 [-1, 128, 28, 28] 65,664
BatchNorm2d-48 [-1, 128, 28, 28] 256
ReLU-49 [-1, 128, 28, 28] 0
Conv2d-50 [-1, 128, 28, 28] 147,584
BatchNorm2d-51 [-1, 128, 28, 28] 256
ReLU-52 [-1, 128, 28, 28] 0
Conv2d-53 [-1, 512, 28, 28] 66,048
BatchNorm2d-54 [-1, 512, 28, 28] 1,024
IdentityBlock-55 [-1, 512, 28, 28] 0
Conv2d-56 [-1, 128, 28, 28] 65,664
BatchNorm2d-57 [-1, 128, 28, 28] 256
ReLU-58 [-1, 128, 28, 28] 0
Conv2d-59 [-1, 128, 28, 28] 147,584
BatchNorm2d-60 [-1, 128, 28, 28] 256
ReLU-61 [-1, 128, 28, 28] 0
Conv2d-62 [-1, 512, 28, 28] 66,048
BatchNorm2d-63 [-1, 512, 28, 28] 1,024
IdentityBlock-64 [-1, 512, 28, 28] 0
Conv2d-65 [-1, 128, 28, 28] 65,664
BatchNorm2d-66 [-1, 128, 28, 28] 256
ReLU-67 [-1, 128, 28, 28] 0
Conv2d-68 [-1, 128, 28, 28] 147,584
BatchNorm2d-69 [-1, 128, 28, 28] 256
ReLU-70 [-1, 128, 28, 28] 0
Conv2d-71 [-1, 512, 28, 28] 66,048
BatchNorm2d-72 [-1, 512, 28, 28] 1,024
IdentityBlock-73 [-1, 512, 28, 28] 0
Conv2d-74 [-1, 256, 14, 14] 131,328
BatchNorm2d-75 [-1, 256, 14, 14] 512
ReLU-76 [-1, 256, 14, 14] 0
Conv2d-77 [-1, 256, 14, 14] 590,080
BatchNorm2d-78 [-1, 256, 14, 14] 512
ReLU-79 [-1, 256, 14, 14] 0
Conv2d-80 [-1, 1024, 14, 14] 263,168
BatchNorm2d-81 [-1, 1024, 14, 14] 2,048
ReLU-82 [-1, 1024, 14, 14] 0
Conv2d-83 [-1, 1024, 14, 14] 525,312
BatchNorm2d-84 [-1, 1024, 14, 14] 2,048
ConvBlock-85 [-1, 1024, 14, 14] 0
Conv2d-86 [-1, 256, 14, 14] 262,400
BatchNorm2d-87 [-1, 256, 14, 14] 512
ReLU-88 [-1, 256, 14, 14] 0
Conv2d-89 [-1, 256, 14, 14] 590,080
BatchNorm2d-90 [-1, 256, 14, 14] 512
ReLU-91 [-1, 256, 14, 14] 0
Conv2d-92 [-1, 1024, 14, 14] 263,168
BatchNorm2d-93 [-1, 1024, 14, 14] 2,048
IdentityBlock-94 [-1, 1024, 14, 14] 0
Conv2d-95 [-1, 256, 14, 14] 262,400
BatchNorm2d-96 [-1, 256, 14, 14] 512
ReLU-97 [-1, 256, 14, 14] 0
Conv2d-98 [-1, 256, 14, 14] 590,080
BatchNorm2d-99 [-1, 256, 14, 14] 512
ReLU-100 [-1, 256, 14, 14] 0
Conv2d-101 [-1, 1024, 14, 14] 263,168
BatchNorm2d-102 [-1, 1024, 14, 14] 2,048
IdentityBlock-103 [-1, 1024, 14, 14] 0
Conv2d-104 [-1, 256, 14, 14] 262,400
BatchNorm2d-105 [-1, 256, 14, 14] 512
ReLU-106 [-1, 256, 14, 14] 0
Conv2d-107 [-1, 256, 14, 14] 590,080
BatchNorm2d-108 [-1, 256, 14, 14] 512
ReLU-109 [-1, 256, 14, 14] 0
Conv2d-110 [-1, 1024, 14, 14] 263,168
BatchNorm2d-111 [-1, 1024, 14, 14] 2,048
IdentityBlock-112 [-1, 1024, 14, 14] 0
Conv2d-113 [-1, 256, 14, 14] 262,400
BatchNorm2d-114 [-1, 256, 14, 14] 512
ReLU-115 [-1, 256, 14, 14] 0
Conv2d-116 [-1, 256, 14, 14] 590,080
BatchNorm2d-117 [-1, 256, 14, 14] 512
ReLU-118 [-1, 256, 14, 14] 0
Conv2d-119 [-1, 1024, 14, 14] 263,168
BatchNorm2d-120 [-1, 1024, 14, 14] 2,048
IdentityBlock-121 [-1, 1024, 14, 14] 0
Conv2d-122 [-1, 256, 14, 14] 262,400
BatchNorm2d-123 [-1, 256, 14, 14] 512
ReLU-124 [-1, 256, 14, 14] 0
Conv2d-125 [-1, 256, 14, 14] 590,080
BatchNorm2d-126 [-1, 256, 14, 14] 512
ReLU-127 [-1, 256, 14, 14] 0
Conv2d-128 [-1, 1024, 14, 14] 263,168
BatchNorm2d-129 [-1, 1024, 14, 14] 2,048
IdentityBlock-130 [-1, 1024, 14, 14] 0
Conv2d-131 [-1, 512, 7, 7] 524,800
BatchNorm2d-132 [-1, 512, 7, 7] 1,024
ReLU-133 [-1, 512, 7, 7] 0
Conv2d-134 [-1, 512, 7, 7] 2,359,808
BatchNorm2d-135 [-1, 512, 7, 7] 1,024
ReLU-136 [-1, 512, 7, 7] 0
Conv2d-137 [-1, 2048, 7, 7] 1,050,624
BatchNorm2d-138 [-1, 2048, 7, 7] 4,096
ReLU-139 [-1, 2048, 7, 7] 0
Conv2d-140 [-1, 2048, 7, 7] 2,099,200
BatchNorm2d-141 [-1, 2048, 7, 7] 4,096
ConvBlock-142 [-1, 2048, 7, 7] 0
Conv2d-143 [-1, 512, 7, 7] 1,049,088
BatchNorm2d-144 [-1, 512, 7, 7] 1,024
ReLU-145 [-1, 512, 7, 7] 0
Conv2d-146 [-1, 512, 7, 7] 2,359,808
BatchNorm2d-147 [-1, 512, 7, 7] 1,024
ReLU-148 [-1, 512, 7, 7] 0
Conv2d-149 [-1, 2048, 7, 7] 1,050,624
BatchNorm2d-150 [-1, 2048, 7, 7] 4,096
IdentityBlock-151 [-1, 2048, 7, 7] 0
Conv2d-152 [-1, 512, 7, 7] 1,049,088
BatchNorm2d-153 [-1, 512, 7, 7] 1,024
ReLU-154 [-1, 512, 7, 7] 0
Conv2d-155 [-1, 512, 7, 7] 2,359,808
BatchNorm2d-156 [-1, 512, 7, 7] 1,024
ReLU-157 [-1, 512, 7, 7] 0
Conv2d-158 [-1, 2048, 7, 7] 1,050,624
BatchNorm2d-159 [-1, 2048, 7, 7] 4,096
IdentityBlock-160 [-1, 2048, 7, 7] 0
AvgPool2d-161 [-1, 2048, 1, 1] 0
Linear-162 [-1, 4] 8,196
================================================================
Total params: 23,542,788
Trainable params: 23,542,788
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 240.24
Params size (MB): 89.81
Estimated Total Size (MB): 330.62
----------------------------------------------------------------
Epoch: 1, Train_acc:65.3%, Train_loss:0.926, Test_acc:176.4%, Test_loss:0.513, Lr:1.00E-04
Epoch: 2, Train_acc:75.7%, Train_loss:0.685, Test_acc:164.5%, Test_loss:0.735, Lr:1.00E-04
Epoch: 3, Train_acc:81.6%, Train_loss:0.542, Test_acc:76.8%, Test_loss:0.681, Lr:1.00E-04
Epoch: 4, Train_acc:84.1%, Train_loss:0.429, Test_acc:41.5%, Test_loss:0.850, Lr:1.00E-04
Epoch: 5, Train_acc:89.8%, Train_loss:0.287, Test_acc:52.9%, Test_loss:0.752, Lr:1.00E-04
Epoch: 6, Train_acc:86.3%, Train_loss:0.359, Test_acc:48.9%, Test_loss:0.850, Lr:1.00E-04
Epoch: 7, Train_acc:90.9%, Train_loss:0.263, Test_acc:67.0%, Test_loss:0.752, Lr:1.00E-04
Epoch: 8, Train_acc:87.2%, Train_loss:0.376, Test_acc:50.3%, Test_loss:0.823, Lr:1.00E-04
Epoch: 9, Train_acc:91.8%, Train_loss:0.217, Test_acc:51.5%, Test_loss:0.832, Lr:1.00E-04
Epoch:10, Train_acc:94.0%, Train_loss:0.201, Test_acc:49.1%, Test_loss:0.858, Lr:1.00E-04
Done
预测结果是:Black Throated Bushtiti
二、个人总结
ResNet(残差网络)是深度学习领域的一种重要的神经网络架构,由微软研究院的Kaiming He等人在2015年提出。该模型通过引入了一种称为残差学习的框架来解决深度神经网络在训练过程中遇到的退化问题(随着网络深度的增加,网络精度先是增加然后骤降,这并非是过拟合导致)。以下是ResNet的关键特点和总结:
关键特点
1. 残差连接: ResNet的核心特点是其残差连接(或跳跃连接),每个残差块包含一个或多个普通的卷积层,和一个将输入直接连接到后面层的输出的快捷连接。这使得输入可以跳过中间的一些层。残差连接帮助梯度在训练过程中更有效地流动,从而解决了很深的网络中常见的梯度消失问题。
2. 残差块的设计: 每个残差块包含两个或三个卷积层,这些卷积层具有批归一化和ReLU激活函数。残差块的设计允许网络学习输入和输出之间的残差映射,而非直接学习一个未加工的输出映射。
3. 深度和变体: ResNet具有不同的变体,包括ResNet-18, ResNet-34, ResNet-50, ResNet-101和ResNet-152等,其中数字表示网络中卷积层的数量。ResNet-50及以上模型采用了“瓶颈”设计,每个残差块使用三层卷积(1x1, 3x3, 1x1),前后两个1x1卷积用于减少和增加维度,中间的3x3卷积用于处理特征















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









