






如今,在科学技术飞速发展的情况下,信息化的时代也已因为计算机的出现而来临,信息化也已经影响到了社会上的各个方面。它可以为人们提供许多便利之处,可以大大提高人们的工作效率。随着计算机技术的发展的普及,各个领域也都体会到其强大的数据处理能力,这也成为各行各业不可或缺的工具。所以计算机技术被广泛应用于信息管理系统和数据处理等方面。通过它可以大大减少相关的工作处理步骤,也可以提高信息和数据的安全性。
本文对信息的问题进行了分析,发现目前线下管理和数据安全方面一些所存在的问题,所以决定通过计算机技术,使用MySQL和Django框架技术来实现公共自行车数据分布式存储与计算。管理员可以通过本系统进行查看相关信息。管理员也可以在本系统上进行一些信息管理,如单车品牌、公共站点、系统简介等。从而是能够加快公共公司的发展,节省公共公司资源,为公共公司的可持续发展提供良好的基础。
公共自行车数据分布式存储与计算是一种网络化的管理软件,于是本系统提供了单车品牌、公共站点,登录退出等功能,为本行业节省了大量的时间和人力成本。同时,该系统还提供了灵活的权限管理和角色分配功能,以及良好的用户体验和可扩展性,可根据用户的具体需求进行二次开发和定制。
系统结构设计
本次系统设计结构主要分为两大部分,为前端模块和管理员后端模块,根据面向对的用户不同,所实现的功能也不相同,管理员可以在系统页面经过操作查看自己的基本信息等,而管理员通过系统可以对用户信息进行一系列的管理操作,并可以在系统上发布公示信息。
通过系统结构设计创建出系统结构图,更简单明了的理解系统,并设计系统,更清楚的表现系统的结构模式,主要将系统分析阶段的系统逻辑模式转化为此次目标系统的物理模型,主要将系统分为两大部分,然后确立了两大部分之下的诸多功能模块,确定了模块功能之间的数据联系和信息关系。
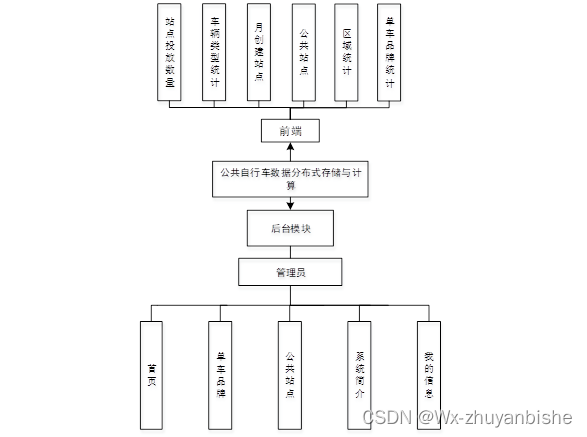
图4.2 系统结构图
公共自行车数据分布式存储与计算看板展示
对公共自行车数据分布式存储与计算获取之后,开始对站点投放数量、车辆类型统计、月创建站点、公共站点(单车数量TOP10)、区域统计、单车品牌统计,这些数据进行可视化分析,如图5.2所示:

图5.2 公共自行车数据分布式存储与计算看板界面图















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









