






对豆瓣网图书小说标签下书籍数据的分析旨在利用大数据处理框架Spark来构建一个高效、可扩展的图书小说推荐系统。本文主要介绍了系统的整体设计、关键算法实现以及实验评估等内容。
本文首先对原始数据进行了预处理,包括数据清洗、去重、分词等操作。然后利用Spark的分布式计算能力,对数据进行了分区和压缩,以提高后续计算的效率;为了更好地捕捉用户的阅读行为,定义了一个用户行为模型,包括用户浏览、收藏、评论等行为。通过分析这些行为,可以得到用户对图书小说的偏好;为了找到与用户兴趣相似的其他用户,用了余弦相似度算法。通过Spark的并行计算,可以快速得到用户之间的相似度矩阵,矩阵分解的方法来生成图书小说推荐列表。具体地,利用Spark的MLlib库中的ALS算法,将用户-图书小说的评分矩阵进行分解,得到图书小说的推荐分数;本文基于Spark构建了一个完整的图书小说推荐系统,包括前端界面和后端服务。前端界面提供了图书小说推荐、搜索等功能,后端服务负责处理用户请求和数据计算。
通过深入研究相关算法,并利用Spark的强大计算能力,实现了一个高效、可扩展的图书小说推荐系统。实验结果和实际应用表明,该系统在推荐效果和性能方面具有较大优势,具有一定的研究和实用价值。
系统概述
作为大数据分析系统,数据采集、数据处理、数据分析和数据可视化是对豆瓣网图书小说标签下书籍数据的分析系统具备的基本素质。除此之外,本系统在用户交互方面做到了傻瓜式一键交互,按下按键,功能完成。数据抓取、数据存储、数据导入、数据清洗、数据预处理、数据分析、数据挖掘和数据可视化等种种功能都不在话下,通过GUI图形操作界面摆脱了繁琐的实现过程。从意义方面,系统主要处理大量信息数据,对这些数据进行分析,并按需求进行可视化,从中提取需要的信息,给用户带来价值。系统功能结构如图3-1所示。
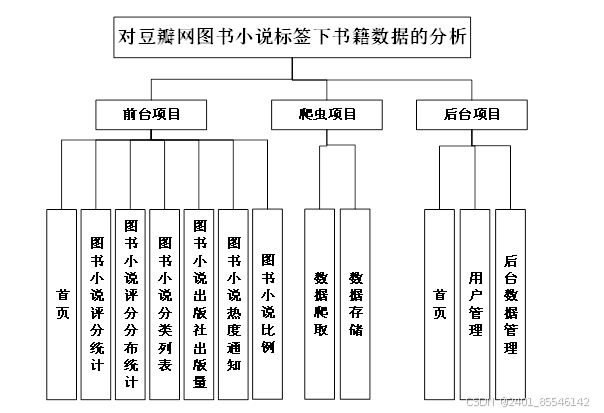
图3-1 系统功能结构
图书小说评分分布统计:使用Spark GraphX库中的生成算法,将评分数据映射为图中的顶点,每个顶点代表一本图书小说,顶点的大小表示评分的高低,,利用Spark MLlib库中的聚类算法对图中的顶点进行聚类,通过Spark的图形界面展示这些顶点和它们的分布情况,帮助用户直观地了解不同图书小说的评分分布。如图5-3-4所示。
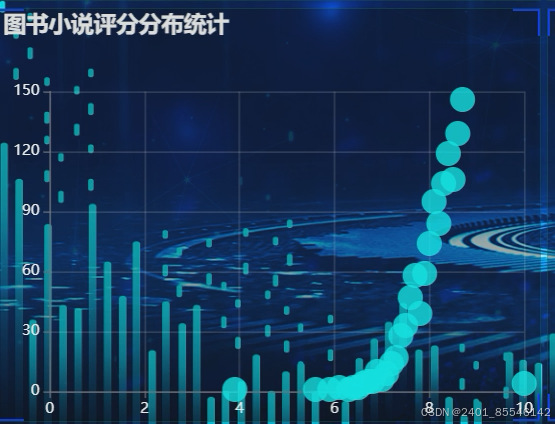
图5-3-4 图书小说评分分布统计


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









