






背景需求
为了信息比赛,需要制作人工智能融入课堂的录课。我根据自己的经验,(最近快递需要自己到快递柜领取,并自主扫码取出。
设计了html网页《取快递》
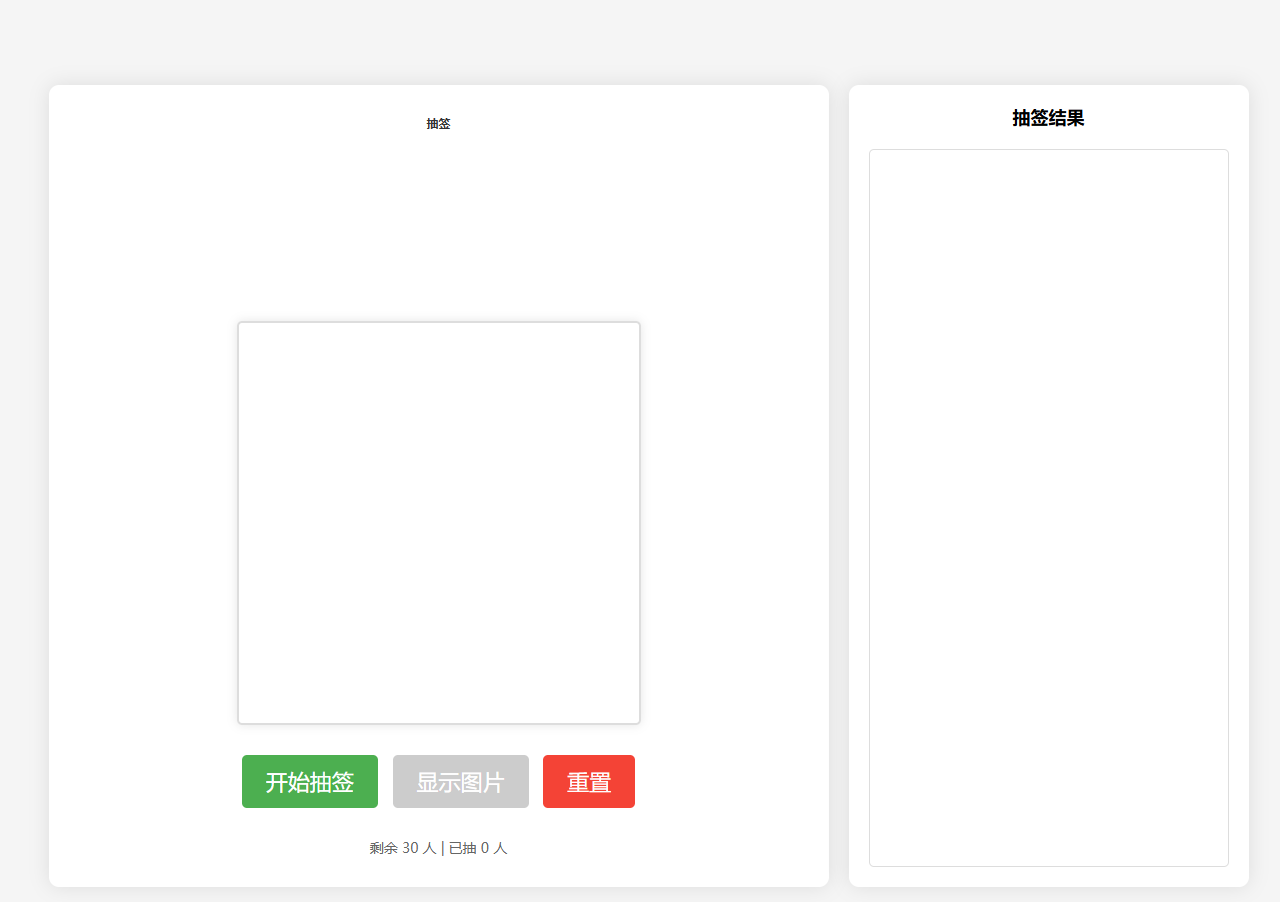

因为从头到尾都是随机抽人,用“快递号”到网格架上找打印纸,我担心小朋友不识字,所以想加入音频提示“XXX小朋友,你的快递到啦”。
而且从头到尾都是抽签,怕他们逐渐失去注意力,如果有喊名字+不同的领快递的语言。可能会增加趣味性和吸引力。
存在问题:
但是如果让我用手机录30个小朋友的名字+“你的快递到了”,我感觉太烦了。也很重复。
解决思路:
问问deepseek:python是否能将excel表格的文字读出来,保存为MP3
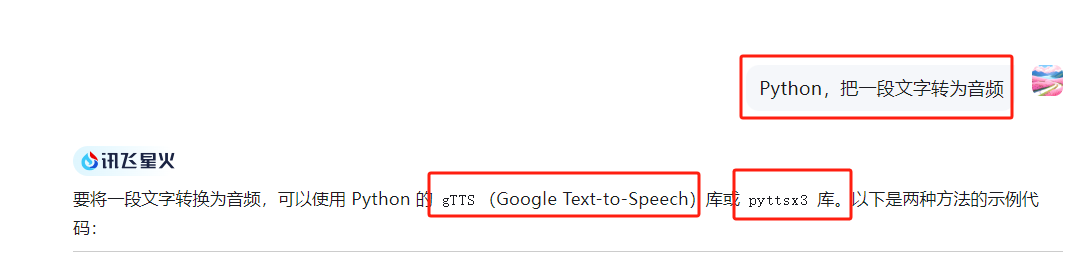 结果测试了一段文字,的确转成功了。o(* ̄▽ ̄*)ブ
结果测试了一段文字,的确转成功了。o(* ̄▽ ̄*)ブ
正式制作:
第一步:制作EXCEL表
写30条不同的话
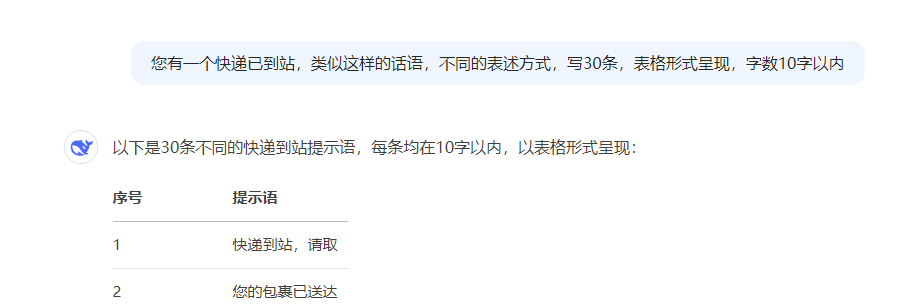
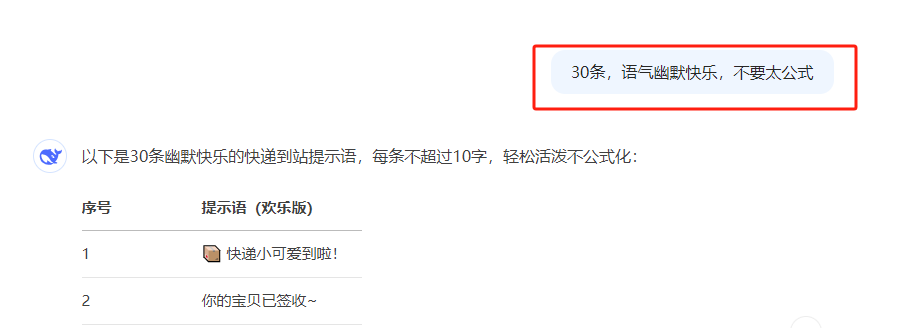
范例姓名+部分话语

第二步:主要内容设计
问deepseek;如何用python,读取excel的文字,然后保存多个MP3
测试了很多次,最后用pyttsx3成功了
代码展示
'''
读取excel内的文字,组合成“XX,取快递啦”的句子。python批量导出成MP3音频
deep seek,阿夏
20250522
'''
import os
import subprocess
import sys
import pandas as pd
import pyttsx3
import re
def install_package(package):
"""安装指定的Python包"""
try:
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
return True
except subprocess.CalledProcessError:
return False
def convert_pinyin(text):
"""将拼音标注转换为可发音的文本"""
pattern = re.compile(r'\(\w+\)')
return pattern.sub(lambda m: m.group().strip('()'), text)
def replace_multi_pronunciation(text, dictionary):
"""根据字典替换多音字"""
for word, pron in dictionary.items():
text = text.replace(word, pron)
return text
def excel_to_speech_offline(input_file, output_dir):
"""
将Excel第2列和第4列内容组合后转为多个MP3文件
参数:
input_file: Excel文件路径
output_dir: 输出目录路径
"""
try:
# 检查并安装所需库
try:
import pyttsx3
except ImportError:
print("pyttsx3库未安装,正在尝试自动安装...")
if not install_package('pyttsx3'):
print("无法自动安装pyttsx3,请手动运行: pip install pyttsx3")
return False
import pyttsx3
try:
import pandas as pd
except ImportError:
print("pandas库未安装,正在尝试自动安装...")
if not install_package('pandas'):
print("无法自动安装pandas,请手动运行: pip install pandas")
return False
import pandas as pd
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 读取Excel文件,跳过第一行
df = pd.read_excel(input_file, header=None)
# 获取第2列和第4列数据(索引为1和3),跳过第一行
texts_col1 = df.iloc[1:, 1].dropna().astype(str).tolist()
texts_col3 = df.iloc[1:, 3].dropna().astype(str).tolist()
# 确保两个列的长度相同
min_length = min(len(texts_col1), len(texts_col3))
combined_texts = [f"{texts_col1[i]}小朋友,{texts_col3[i]}" for i in range(min_length)]
# 定义多音字字典
multi_pronunciation_dict = {
'曾': 'Zēng',
# 添加其他多音字及其正确发音
}
# 替换多音字并转换拼音标注
processed_texts = []
for text in combined_texts:
text = replace_multi_pronunciation(text, multi_pronunciation_dict)
text = convert_pinyin(text)
processed_texts.append(text)
# 初始化语音引擎
engine = pyttsx3.init()
engine.setProperty('rate', 180) # 语速
engine.setProperty('volume', 0.9) # 音量
# 为每行文本生成语音
success_count = 0
for i, text in enumerate(processed_texts, 1):
try:
clean_text = text.strip()
if not clean_text:
continue
# 生成文件名(替换特殊字符)
safe_text = "".join([c for c in clean_text if c.isalnum() or c in (' ', '_')])[:20]
output_file = os.path.join(output_dir, f"{i:03d}.mp3")
# _{safe_text}.mp3")
# 保存为音频文件
engine.save_to_file(clean_text, output_file)
engine.runAndWait()
# 验证文件是否生成
if os.path.exists(output_file):
print(f"已生成: {output_file}")
success_count += 1
else:
print(f"生成失败: {clean_text}")
except Exception as e:
print(f"处理文本'{text}'时出错: {e}")
continue
print(f"\n转换完成!共成功生成 {success_count}/{len(processed_texts)} 个MP3文件")
print(f"保存路径: {output_dir}")
return True
except Exception as e:
print(f"发生错误: {e}")
return False
# 使用示例
if __name__ == "__main__":
# 设置输入输出路径
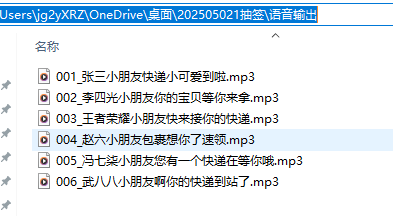
input_excel = r'C:\Users\jg2yXRZ\OneDrive\桌面\202505021抽签\名字.xlsx'
output_directory = r'C:\Users\jg2yXRZ\OneDrive\桌面\202505021抽签\语音输出'
# 执行转换
success = excel_to_speech_offline(input_excel, output_directory)
if success:
print("转换成功完成!")
else:
print("转换过程中出现问题")
生成结果:6个独立音频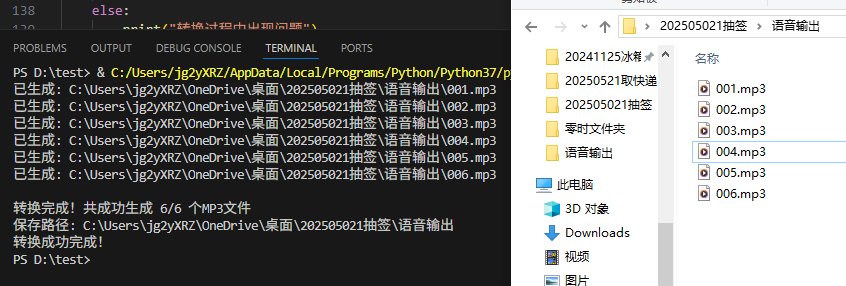
视频展示:
20250522python读取excle每格文批量转mp3


















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











