






前言
在Python中,BeautifulSoup(通常通过bs4库引入)是一个用于解析HTML和XML文档的库。它提供了许多方法和功能,其中soup.find()和soup.find_all()是两个最常用的方法,用于从解析的文档树中查找元素。
一、背景
我们在使用python对网页爬虫的时候,经常会得到一些html数据,因此我们就会利用soup.find()和soup.find_all()方法来筛选出想要的数据。
二、用法
1.soup.find()
1.1利用name来查找
代码如下:
from bs4 import BeautifulSoup
html_string = """<div>
<h1 class="item" id="x1">蔡x坤</h1>
<ul class="item" id="x2">
<li>唱</li>
<li>跳</li>
<li>rap</li>
<li>篮球</li>
</ul>
<div class="item "id='x3'>
<span>你干嘛</span>
<a href="www.xxx.com" class='info'>ikun.com</a>
</div>
</div>"""
soup = BeautifulSoup(html_string, features="html.parser")
#利用name来查找
tag_list=soup.find(name="h1")
print(tag_list)
结果如下:
<h1 class="item" id="x1">蔡x坤</h1>1.2利用属性attrs来寻找
代码如下:
html_string = """<div>
<h1 class="item" id="x1">蔡x坤</h1>
<ul class="item" id="x2">
<li>唱</li>
<li>跳</li>
<li>rap</li>
<li>篮球</li>
</ul>
<div class="item "id='x3'>
<span>你干嘛</span>
<a href="www.xxx.com" class='info'>ikun.com</a>
</div>
</div>"""
soup = BeautifulSoup(html_string, features="html.parser")
#利用属性attrs查找
tag_list=soup.find(attrs={"id":"x3"})
print(tag_list)
结果如下:
<div class="item" id="x3">
<span>你干嘛</span>
<a class="info" href="www.xxx.com">ikun.com</a>
</div>1.3利用name和attrs寻找
代码如下:
html_string = """<div>
<h1 class="item" id="x1">蔡x坤</h1>
<ul class="item" id="x1">我是一名练习生</ul>
<ul class="item" id="x2">
<li>唱</li>
<li>跳</li>
<li>rap</li>
<li>篮球</li>
</ul>
<div class="item "id='x3'>
<span>你干嘛</span>
<a href="www.xxx.com" class='info'>ikun.com</a>
</div>
</div>"""
soup = BeautifulSoup(html_string, features="html.parser")
#利用name和attrs寻找
tag_list=soup.find(name="ul",attrs={"id":"x2"})
print(tag_list)
结果如下:
<ul class="item" id="x2">
<li>唱</li>
<li>跳</li>
<li>rap</li>
<li>篮球</li>
</ul>2.soup.find_all()
2.1利用name找多个
代码如下:
html_string = """<div>
<h1 class="item" id="x1">蔡x坤</h1>
<ul class="item" id="x1">我是一名练习生</ul>
<ul class="item" id="x2">
<li>唱</li>
<li>跳</li>
<li>rap</li>
<li>篮球</li>
</ul>
<div class="item "id='x3'>
<span>你干嘛</span>
<a href="www.xxx.com" class='info'>ikun.com</a>
</div>
</div>"""
soup = BeautifulSoup(html_string, features="html.parser")
#利用name找多个
tag_list=soup.find_all(name="li")
for tag in tag_list:
print(tag.name,tag.text)
结果如下:(输出name和text)
li 唱
li 跳
li rap
li 篮球2.2利用attrs找多个
代码如下:
from bs4 import BeautifulSoup
html_string = """<div>
<h1 class="item" id="x1">蔡x坤</h1>
<ul class="item" id="x1">我是一名练习生</ul>
<ul class="item" id="x2">
<li>唱</li>
<li>跳</li>
<li>rap</li>
<li>篮球</li>
</ul>
</div>"""
soup = BeautifulSoup(html_string, features="html.parser")
#用attrs找多个
tag_list=soup.find_all(attrs={"class":"item"})
for tag in tag_list:
print(tag.name,tag.text)
结果如下:(输出name和text)
h1 蔡x坤
ul 我是一名练习生
ul
唱
跳
rap
篮球2.3利用recursive判断是否递归寻找,默认为True
代码如下:(recursive=False 只找儿子)
from bs4 import BeautifulSoup
html_string = """<div>
<div id='x1'>
<span>你干嘛</span>
<a href="www.xxx.com" class='info'>ikun.com</a>
<div>
<span>这是一句话</span>
<span>这是一句话的一句话</span>
<span>这也是一句话</span>
</div>
</div>
</div>"""
soup = BeautifulSoup(html_string, features="html.parser")
#找儿子
tag_list1=soup.find(attrs={"id":"x1"})
for tag in tag_list1.find_all(recursive=False):
print(tag)
结果如下(recursive=False 只找儿子):
<span>你干嘛</span>
<a class="info" href="www.xxx.com">ikun.com</a>
<div>
<span>这是一句话</span>
<span>这是一句话的一句话</span>
<span>这也是一句话</span>
</div>
代码如下:(recursive=True 找子子孙孙)
from bs4 import BeautifulSoup
html_string = """<div>
<div id='x1'>
<span>你干嘛</span>
<a href="www.xxx.com" class='info'>ikun.com</a>
<div>
<span>这是一句话</span>
<span>这是一句话的一句话</span>
<span>这也是一句话</span>
</div>
</div>
</div>"""
soup = BeautifulSoup(html_string, features="html.parser")
#找子子孙孙
tag_list1=soup.find(attrs={"id":"x1"})
for tag in tag_list1.find_all(recursive=True):
print(tag)
结果如下(recursive=True 找子子孙孙):
<span>你干嘛</span>
<a class="info" href="www.xxx.com">ikun.com</a>
<div>
<span>这是一句话</span>
<span>这是一句话的一句话</span>
<span>这也是一句话</span>
</div>
<span>这是一句话</span>
<span>这是一句话的一句话</span>
<span>这也是一句话</span>
————————————————
三、案例
爬取易车网的车品牌为例子(本例子参考python讲师武沛齐老师)
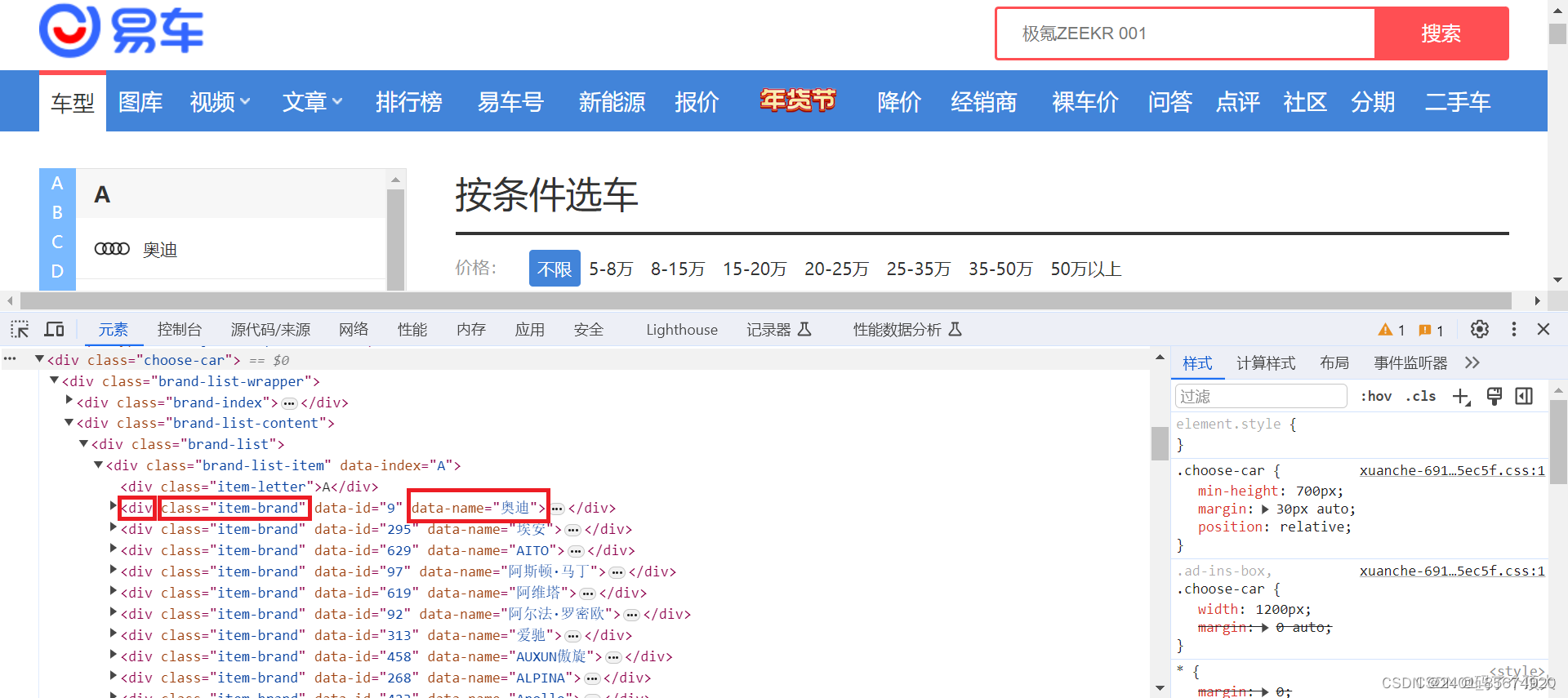
1.分析网页
用chrome的无痕网页打开https://car.yiche.com/并分析网页
分析发现车牌的名字在 name="div", attrs={"class": "item-brand"}里面
2.模拟请求,获取HTML文本
import requests
from bs4 import BeautifulSoup
# 获取HTML文本
res = requests.get(
url="https://car.yiche.com/"
)
3.筛选数据
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text, features="html.parser")
#创一个列表存
result_list=[]
#筛选数据
tag_list = soup.find_all(name="div", attrs={"class": "item-brand"})
for tag in tag_list:
result_list.append(tag.attrs["data-name"])
print(result_list)
————————————————
总结
soup.find():在解析的HTML/XML文档树中查找第一个匹配的元素,并返回它。如果没有找到,返回None。soup.find_all():在解析的HTML/XML文档树中查找所有匹配的元素,并返回一个包含它们的列表。如果没有找到,返回一个空列表。
这两个方法都接受类似的参数,如标签名、属性、CSS选择器等,用于指定要查找的元素。使用这些参数,您可以精确地控制从HTML/XML文档中提取哪些信息。















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









