






- 6)UTF-8:UTF-16统一采用两字节表示一个字符,但有些字符只用一个字节就可表示,浪费存储空间,而UTF-8采用一种变长技术,每个编码区域有不同的字码长度。不同类型的字符可以由1~6个字节组成。
12序列化Serializable和Parcelable的区别
-
**序列化:**将一个对象转换成可存储或可传输的状态,序列化后的对象可以在网络上传输,也可以存储到本地,或实现跨进程传输;
-
**为什么要进行序列化:**开发过程中,我们需要将对象的引用传给其他activity或fragment使用时,需要将这些对象放到一个Intent或Bundle中,再进行传递,而Intent或Bundle只能识别基本数据类型和被序列化的类型。Serializable:表示将一个对象转换成可存储或可传输的状态。
-
**Parcelable:**与Serializable实现的效果相同,也是将一个对象转换成可传输的状态,但它的实现原理是将一个完整的对象进行分解,分解后的每一部分都是Intent所支持的数据类型,这样实现传递对象的功能。
-
**Parcelable实现序列化的重要方法:**序列化功能是由writeToParcel完成,通过Parcel中的write方法来完成;反序列化由CREATOR完成,内部标明了如何创建序列化对象及数级,通过Parcel的read方法完成;内容描述功能由describeContents方法完成,一般直接返回0。
-
**区别:**Serializable在序列化时会产生大量临时变量,引起频繁GC。Serializable本质上使用了反射,序列化过程慢。Parcelable不能将数据存储在磁盘上,在外界变化时,它不能很好的保证数据的持续性。
-
**选择原则:**若仅在内存中使用,如activity\service间传递对象,优先使用Parcelable,它性能高。若是持久化操作,优先使用Serializable
-
**注意:**静态成员变量属于类,不属于对象,固不会参与序列化的过程;用transient关键字编辑的成员变量不会参与序列化过程;可以通过重写writeObject()和readObject()方法来重写系统默认的序列化和反序列化。
13.string转换成integer的方式及原理
1.parseInt(Strings)内部调用parseInt(s,10)默认为10进制。
2.正常判断null\进制范围,length等。
3.判断第一个字符是否是符号位。
4.循环遍历确定每个字符的十进制值。
5.通过*=和-=进行计算拼接。
6.判断是否为负值返回结果。
14.静态代理和动态代理的区别,什么场景使用?
代理是一种常用的设计模式,目的是:为其他对象提供一个代理以控制对某个对象的访问,将两个类的关系解耦。代理类和委托类都要实现相同的接口,因为代理真正调用的是委托类的方法。
区别:
**1)静态代理:**由程序员创建或是由特定工具生成,在代码编译时就确定了被代理的类是哪一个是静态代理。静态代理通常只代理一个类;
**2)动态代理:**在代码运行期间,运用反射机制动态创建生成。动态代理代理的是一个接口下的多个实现类;
**实现步骤:**a.实现InvocationHandler接口创建自己的调用处理器;b.给Proxy类提供ClassLoader和代理接口类型数组创建动态代理类;c.利用反射机制得到动态代理类的构造函数;d.利用动态代理类的构造函数创建动态代理类对象;
**使用场景:**Retrofit中直接调用接口的方法;Spring的AOP机制
15.说说你对Java反射的理解
在运行状态中,对任意一个类,都能知道这个类的所有属性和方法,对任意一个对象,都能调用它的任意一个方法和属性。这种能动态获取信息及动态调用对象方法的功能称为java语言的反射机制。
反射的作用:开发过程中,经常会遇到某个类的某个成员变量、方法或属性是私有的,或只对系统应用开放,这里就可以利用java的反射机制通过反射来获取所需的私有成员或是方法。
1)获取类的Class对象实例Classclz=Class.forName(“com.zhenai.api.Apple”);
2)根据Class对象实例获取Constructor对象ConstructorappConstructor=clz.getConstructor();
3)使用Constructor对象的newInstance方法获取反射类对象ObjectappleObj=appConstructor.newInstance();
4)获取方法的Method对象MethodsetPriceMethod=clz.getMethod(“setPrice”,int.class);
5)利用invoke方法调用方法setPriceMethod.invoke(appleObj,14);
6)通过getFields()可以获取Class类的属性,但无法获取私有属性,而getDeclaredFields()可以获取到包括私有属性在内的所有属性。带有Declared修饰的方法可以反射到私有的方法,没有Declared修饰的只能用来反射公有的方法,其他如Annotation\Field\Constructor也是如此。
1.Java内存模型
1.1 Jvm内存区域是如何划分的?
内存区域划分:
-
程序计数器:当前线程的字节码执行位置的指示器,线程私有。
-
Java虚拟机栈:描述的Java方法执行的内存模型,每个方法在执行的同时会创建一个栈帧,存储着局部变量、操作数栈、动态链接和方法出口等,线程私有。
-
本地方法栈:本地方法执行的内存模型,线程私有。
-
Java堆:所有对象实例分配的区域。
-
方法区:所有已经被虚拟机加载的类的信息、常量、静态变量和即时编辑器编译后的代码数据。
1.2 Jvm内存模型是怎么样的?
1.Java规定所有变量的内存都需要存储在主内存。
2.每个线程都有自己的工作内存,线程中使用的所有变量以及对变量的操作都基于工作内存,工作内存中的所有变量都从主内存读取过来的。
3.不同线程间的工作内存无法进行直接交流,必须通过主内存完成。

主内存和工作内存之间的交互协议,即变量如何从主内存传递到工作内存、工作内存如何将变量传递到主内存,Java内存模型定义了8种操作来完成,并且每一种操作都是原子的,不可再分的。

1.3 Strings1="abc"和Strings2=newString(“abc”)的区别,生成对象的情况
1.指向方法区:"abc"是常量,所以它会在方法区中分配内存,如果方法区已经给"abc"分配过内存,则s1会直接指向这块内存区域。
2.指向Java堆:newString(“abc”)是重新生成了一个Java实例,它会在Java堆中分配一块内存。
所以s1和s2的内存地址肯定不一样,但是内容一样。
2. GC机制
2.1如何判断对象可回收?
判断一个对象可以回收通常采用的算法是引用几算法和可达性算法。由于互相引用导致的计数不好判断,Java采用的可达性算法。
可达性算法的思路是:通过一些列被成为GCRoots的对象作为起始点,自上往下从这些起点往下搜索,搜索所有走过的路径称为引用链,如果一个对象没有跟任何引用链相关联的时候,则证明该对象不可用,所以这些对象就会被判定为可以回收。
可以被当作GCRoots的对象包括:
-
Java虚拟机栈中的引用的对象
-
方法区中静态属性引用的对象
-
方法区中常量引用的对象
-
本地方法中JNI引用的对象
2.2 GC的常用算法?
-
标记-清除:首先标记出需要回收的对象,标记完成后统一回收所有被标记的对象。容易产生碎片空间。
-
复制算法:它将可用的内存分为两块,每次只用其中的一块,当需要内存回收的时候,将存活的对象复制到另一块内存,然后将当前已经使用的内存一次性回收掉。需要浪费一半的内存。
-
标记-整理:让存活的对象向一端移动,之后清除边界外的内存。
-
分代搜集:根据对象存活的周期,Java堆会被分为新生代和老年代,根据不同年代的特性,选择合适的GC收集算法。
2.3MinarGC和FullGC的区别?
-
MinarGC:频率高、针对新生代。
-
FullGC:频率低、发生在老年代、通常会伴随一次MinarGC和速度慢。
2.4说一下四种引用以及他们的区别?
-
强引用:强引用还在,垃圾搜集器就不会回收被引用的对象。
-
软引用:对于软引用关联的对象,在系统发生内存溢出异常之前,将会把这些对象列进回收范围进行第二次回收,如果这次回收还没有足够的内存,才会抛出内存溢出异常。
-
弱引用:被若引用关联的对象只能存活到下一次GC之前。
-
虚引用:为对象设置虚引用的目的仅仅是为了GC之前收到一个系统通知。
3.类加载
3.1 类加载的过程?
类加载的过程可以分为:
1.加载:将类的全限定名转化为二进制流,再将二进制流转化为方法区中的类型信息,从而生成一个Class对象。
2.验证:对类的验证,包括格式、字节码、属性等。
3.准备:为类变量分配内存并设置初始值。
4.解析:将常量池的符号引用转化为直接引用。
5.初始化:执行类中定义的Java程序代码,包括类变量的赋值动作和构造函数的赋值。
6.使用
7.卸载
只有加载、验证、准备、初始化和卸载的这个五个阶段的顺序是确定的。
3.2类加载的机制,以及为什么要这样设计?
类加载的机制是双亲委派模型。大部分Java程序需要使用的类加载器包括:
-
启动类加载器:由C++语言实现,负责加载Java中的核心类。
-
扩展类加载器:负责加载Java扩展的核心类之外的类。
-
应用程序类加载器:负责加载用户类路径上指定的类库。
双亲委派模型如下:
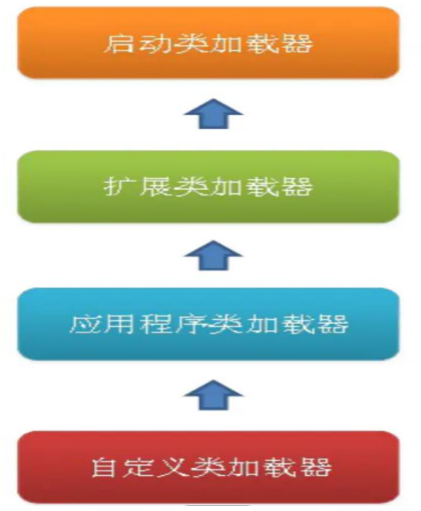
双亲委派模型要求出了顶层的启动类加载器之外,其他的类加载器都有自己的父加载器,通过组合实现。
双亲委派模型的工作流程:
当一个类加载的任务来临的时候,先交给父类加载器完成,父类加载器交给父父类加载器完成,知道传递给启动类加载器,如果完成不了的情况下,再依次往下传递类加载的任务。
这样设计的原因:
双亲委派模型能够保证Java程序的稳定运行,不同层次的类加载器具有不同优先级,所有的对象的父类Object,无论哪一个类加载器加载,最后都会交给启动类加载器,保证安全。
1. TCP与UDP的区别。
2.三次握手、四次挥手。为啥是三次不是两次?
3.HTTPS和HTTP的区别。HTTP2.0,3.0?
关于网络部分这里就不细说了,有想看的小伙伴可以看看这位博主写的关于面试的博文https://blog.csdn.net/weixin_47933729/article/details/117120255
建议
当我们出去找工作,或者准备找工作的时候,我们一定要想,我面试的目标是什么,我自己的技术栈有哪些,近期能掌握的有哪些,我的哪些短板 ,列出来,有计划的去完成,别看前两天掘金一些大佬在驳来驳去 ,他们的观点是他们的,不要因为他们的观点,膨胀了自己,影响自己的学习节奏。基础很大程度决定你自己技术层次的厚度,你再熟练框架也好,也会比你便宜的,性价比高的替代,很现实的问题但也要有危机意识,当我们年级大了,有哪些亮点,与比我们经历更旺盛的年轻小工程师,竞争。
-
无论你现在水平怎么样一定要 持续学习 没有鸡汤,别人看起来的毫不费力,其实费了很大力,这四个字就是我的建议!!!!!!!!!
-
准备想说怎么样写简历,想象算了,我觉得,技术就是你最好的简历
-
我希望每一个努力生活的it工程师,都会得到自己想要的,因为我们很辛苦,我们应得的。
-
有什么问题想交流,欢迎给我私信,欢迎评论
【附】相关架构及资料


内含往期Android高级架构资料、源码、笔记、视频。高级UI、性能优化、架构师课程、NDK、混合式开发(ReactNative+Weex)微信小程序、Flutter全方面的Android进阶实践技术
,我觉得,技术就是你最好的简历
-
我希望每一个努力生活的it工程师,都会得到自己想要的,因为我们很辛苦,我们应得的。
-
有什么问题想交流,欢迎给我私信,欢迎评论
【附】相关架构及资料
[外链图片转存中…(img-opFFS7Ht-1719243780019)]
[外链图片转存中…(img-aZ0gIIPq-1719243780020)]
内含往期Android高级架构资料、源码、笔记、视频。高级UI、性能优化、架构师课程、NDK、混合式开发(ReactNative+Weex)微信小程序、Flutter全方面的Android进阶实践技术















 2850
2850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









