






1、session机制
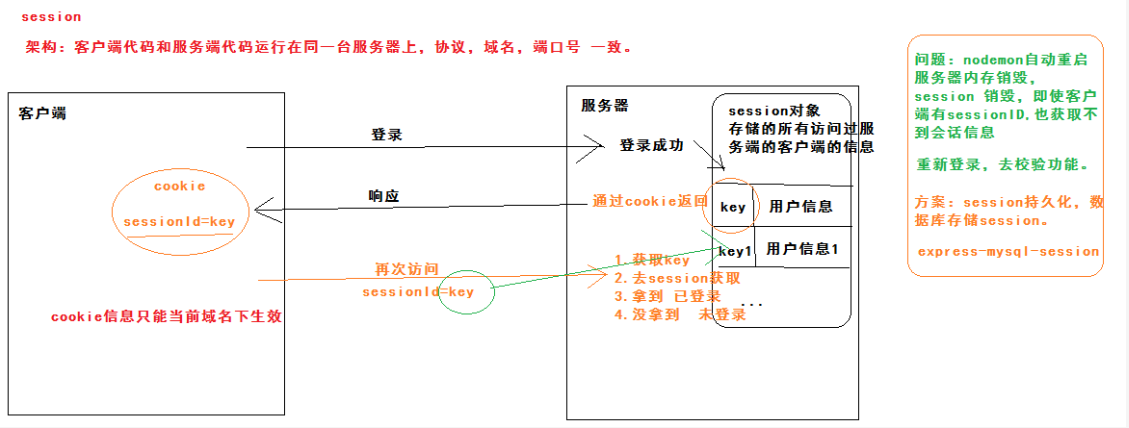
session是服务端存储的一个对象,主要用来存储所有访问过该服务端的客户端的用户信息(也可以存储其他信息),从而实现保持用户会话状态。但是服务器重启时,内存会被销毁,存储的用户信息也就消失了。
不同的用户访问服务端的时候会在session对象中存储键值对,“键”用来存储开启这个用户信息的“钥匙”,在登录成功后,“钥匙”通过cookie返回给客户端,客户端存储为sessionId记录在cookie中。当客户端再次访问时,会默认携带cookie中的sessionId来实现会话机制。
(1)session是基于cookie的。
-
cookie的数据4k左右;
-
cookie存储数据的格式:字符串key=value
-
cookie存储有效期:可以自行通过expires进行具体的日期设置,如果没设置,默认是关闭浏览器时失效。
-
cookie有效范围:当前域名下有效。所以session这种会话存储方式方式只适用于客户端代码和服务端代码运行在同一台服务器上(前后端项目协议、域名、端口号都一致,即在一个项目下)
(2)session持久化
用于解决重启服务器后session消失的问题。在数据库中存储session,而不是存储在内存中。通过包:express-mysql-session。
当客户端存储的cookie失效后,服务端的session不会立即销毁,会有一个延时,服务端会定期清理无效session,不会造成无效数据占用存储空间的问题。
2、token机制
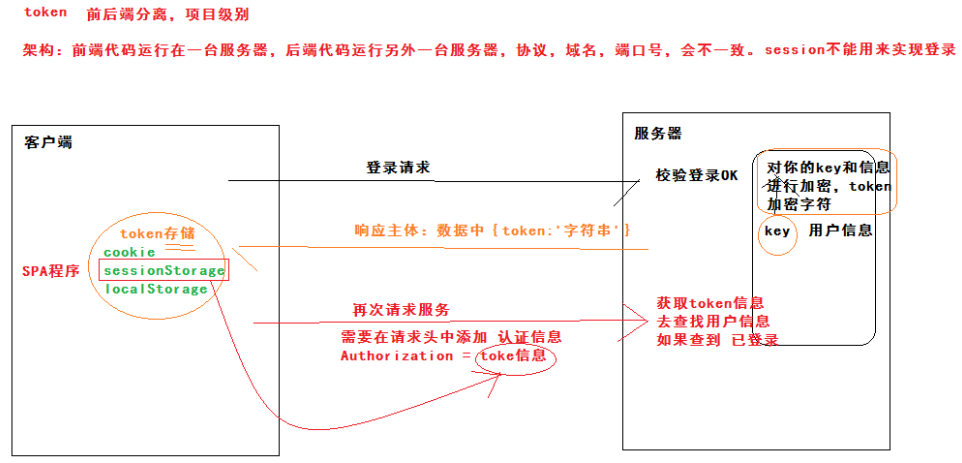
适用于前后端分离的项目(前后端代码运行在不同的服务器下)
请求登录时,token和sessionid原理相同,是对key和key对应的用户信息进行加密后的加密字符,登录成功后,会在响应主体中将{token:“字符串”}返回给客户端。
客户端通过cookie都可以进行存储。再次请求时不会默认携带,需要在请求拦截器位置给请求头中添加认证字段Authorization携带token信息,服务器就可以通过token信息查找用户登录状态。
三、如何设计数据库
1、数据库设计最起码要占用这个项目开发的40%以上的时间
2、数据库设计不仅仅停留在页面demo的表面
页面内容所需字段,在数据库设计中只是一部分,还有系统运转、模块交互、中转数据、表之间的联系等等所需要的字段,因此数据库设计绝对不是简单的基本数据存储,还有逻辑数据存储。
3、数据库设计完成后,项目80%的设计开发都要存在你的脑海中
每个字段的设计都要有他存在的意义,要清楚的知道程序中如何去运用这些字段,多张表的联系在程序中是如何体现的。
4、数据库设计时就要考虑效率和优化问题
数据量大的表示粗粒度的,会冗余一些必要字段,达到用最少的表,最弱的表关系去存储海量的数据。大数据的表要建立索引,方便查询。对于含有计算、数据交互、统计这类需求时,还有考虑是否有必要采用存储过程。
5、添加必要的冗余字段
像创建时间、修改时间、操作用户IP、备注这些字段,在每张表中最好都有,一些冗余的字段便于日后维护、分析、拓展而添加。
6、设计合理的表关联
若两张表之间的关系复杂,建议采用第三张映射表来关联维护两张表之间的关系,以降低表之间的直接耦合度。
7、设计表时不加主外键等约束关联,系统编码阶段完成后再添加约束性关联
8、选择合适的主键生成策略
数据库的设计难度其实比单纯的技术实现难很多,他充分体现了一个人的全局设计能力和掌控能力,最后说一句,数据库设计,很重要,很复杂。

四、性别是否适合做索引
区分度不高的字段不适合做索引,因为索引页是需要有开销的,需要存储的,不过这类字段可以做联合索引的一部分。
五、如何查询重复的数据
1、查询重复的单个字段(group by)
select 重复字段A, count() from 表 group by 重复字段A having count() > 1
2、查询重复的多个字段(group by)
select 重复字段A, 重复字段B, count() from 表 group by 重复字段A, 重复字段B having count() > 1
3、删除所有重复的数据
– 慎重考虑后执行,后悔记得及时回滚。
delete from table group by 重复字段 having count(重复字段) > 1
六、查询网站在线人数
通过监听session对象的方式来实现在线人数的统计和在线人信息展示,并且让超时的自动销毁。
对session对象实现监听,首先必须继承HttpSessionListener类,该程序的基本原理就是当浏览器访问页面的时候必定会产生一个session对象,当关闭该页面的时候必然会删除session对象。所以每当产生一个新的session对象就让在线人数+1,当删除一个session对象就让在线人数-1。
还要继承一个HttpSessionAttributeListener,来实现对其属性的监听。分别实现attributeAdded方法,attributeReplace方法以及attributeRemove方法。
sessionCreated//新建一个会话的时候触发,也可以说是客户端第一次喝服务器交互时触发。
sessionDestroyed//销毁会话的时候,一般来说只有某个按钮触发进行销毁,或者配置定时销毁。
HttpSessionAttributeListener有三个方法需要实现
- attributeAdded//在session中添加对象时触发此操作 笼统的说就是调用setAttribute这个方法时候会触发的
- attributeRemoved//修改、删除session中添加对象时触发此操作 笼统的说就是调用 removeAttribute这个方法时候会触发的
- attributeReplaced//在Session属性被重新设置时
七、Redis取值存值问题
1、先把Redis的连接池拿出来
JedisPool pool = new JedisPool(new JedisPoolConfig(),“127.0.0.1”);
Jedis jedis = pool.getResource();
2、存取值
jedis.set(“key”,“value”);
jedis.get(“key”);
jedis.del(“key”);
//给一个key叠加value
jedis.append(“key”,“value2”);//此时key的值就是value + value2;
//同时给多个key进行赋值:
jedis.mset(“key1”,“value1”,“key2”,“value2”);
3、对map进行操作
Map<String,String> user = new HashMap();
user.put(“key1”,“value1”);
user.put(“key2”,“value2”);
user.put(“key3”,“value3”);
//存入
jedis.hmset(“user”,user);
//取出user中key1
List nameMap = jedis.hmget(“user”,“key1”);
//删除其中一个键值
jedis.hdel(“user”,“key2”);
//是否存在一个键
jedis.exists(“user”);
//取出所有的Map中的值:
Iterator iter = jedis.hkeys(“user”).iterator();
while(iter.next()){
jedis.hmget(“user”,iter.next());
}

八、Spring Boot常用注解
九、mybatis一级缓存、二级缓存
1、一级缓存:指的是mybatis中sqlSession对象的缓存,当我们执行查询以后,查询的结果会同时存入sqlSession中,再次查询的时候,先去sqlSession中查询,有的话直接拿出,当sqlSession消失时,mybatis的一级缓存也就消失了,当调用sqlSession的修改、添加、删除、commit()、close()等方法时,会清空一级缓存。
2、二级缓存:指的是mybatis中的sqlSessionFactory对象的缓存,由同一个sqlSessionFactory对象创建的sqlSession共享其缓存,但是其中缓存的是数据而不是对象。当命中二级缓存时,通过存储的数据构造成对象返回。查询数据的时候,查询的流程是二级缓存 > 一级缓存 > 数据库。
3、如果开启了二级缓存,sqlSession进行close()后,才会把sqlSession一级缓存中的数据添加到二级缓存中,为了将缓存数据取出执行反序列化,还需要将要缓存的pojo实现Serializable接口,因为二级缓存数据存储介质多种多样,不一定只存在内存中,也可能存在硬盘中。
4、mybatis框架主要是围绕sqlSessionFactory进行的,具体的步骤:
-
定义一个configuration对象,其中包含数据源、事务、mapper文件资源以及影响数据库行为属性设置settings。
-
通过配置对象,则可以创建一个sqlSessionFactoryBuilder对象。
-
通过sqlSessionFactoryBuilder获得sqlSessionFactory实例。
-
通过sqlSessionFactory实例创建qlSession实例,通过sqlSession对数据库进行操作。
5、代码实例
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8"?>public class MyBatisTest {
public static void main(String[] args) {
try {
//读取mybatis-config.xml文件
InputStream resourceAsStream = Resources.getResourceAsStream(“mybatis-config.xml”);
//初始化mybatis,创建SqlSessionFactory类的实例
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
//创建session实例
SqlSession session = sqlSessionFactory.openSession();
/*
-
接下来在这里做很多事情,到目前为止,目的已经达到得到了SqlSession对象.通过调用SqlSession里面的方法,
-
可以测试MyBatis和Dao层接口方法之间的正确性,当然也可以做别的很多事情,在这里就不列举了
*/
//插入数据
User user = new User();
user.setC_password(“123”);
user.setC_username(“123”);
user.setC_salt(“123”);
//第一个参数为方法的完全限定名:位置信息+映射文件当中的id
session.insert(“com.cn.dao.UserMapping.insertUserInformation”, user);
//提交事务
session.commit();
//关闭session
session.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
十、mybatis如何防止sql注入
十一、concurrentHashMap和HashTable有什么区别
concurrentHashMap融合了hashmap和hashtable的优势,hashmap是不同步的,但是单线程情况下效率高,hashtable是同步的同步情况下保证程序执行的正确性。
但hashtable每次同步执行的时候都要锁住整个结构,如下图:
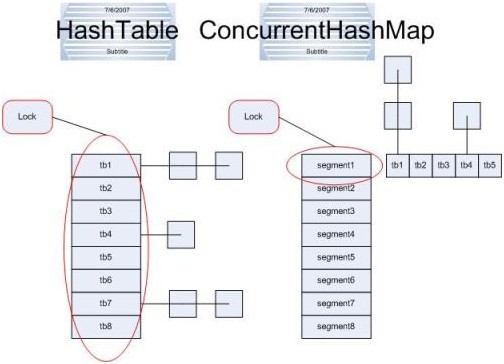
concurrentHashMap锁的方式是细粒度的。concurrentHashMap将hash分为16个桶(默认值),诸如get、put、remove等常用操作只锁住当前需要用到的桶。
concurrentHashMap的读取并发,因为读取的大多数时候都没有锁定,所以读取操作几乎是完全的并发操作,只是在求size时才需要锁定整个hash。
而且在迭代时,concurrentHashMap使用了不同于传统集合的快速失败迭代器的另一种迭代方式,**弱一致迭代器。**在这种方式中,当iterator被创建后集合再发生改变就不会抛出ConcurrentModificationException,取而代之的是在改变时new新的数据而不是影响原来的数据,iterator完成后再讲头指针替代为新的数据,这样iterator时使用的是原来的数据。
十二、hashmap存储的数据结构
数组结构中有数组和链表,实现对数据的存储。
1、数组
数组存储区间是连续的,占用内存严重,故空间复杂度大,但数组的二分查找时间复杂度小,为O(1);
数组的特点是:查找容易,插入和删除困难。
2、链表
链表存储区间离散,暂用内存比较宽松,故空间复杂度小,但时间复杂度大,达到O(N)。
链表的特点:查找困难,插入和删除容易。
3、哈希表
哈希表有多种不同的实现方法,现在介绍一种最常用的方法—拉链法,可以简单的理解为“链表的数组”,如图:
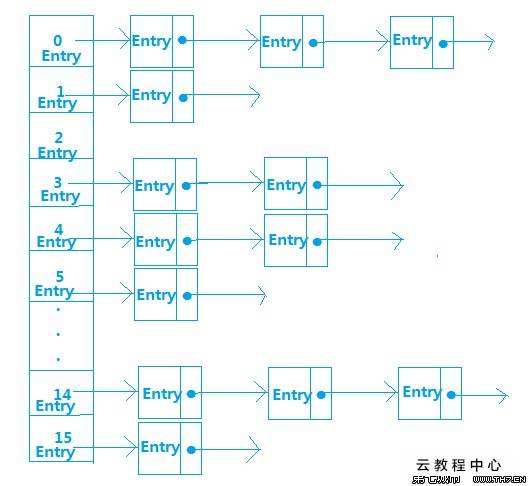
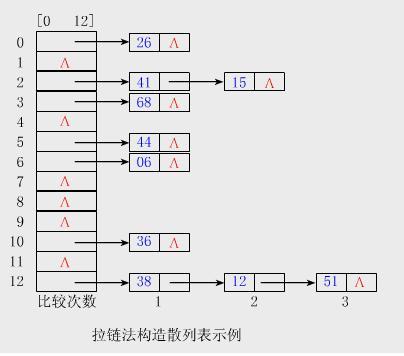
4、HashMap其实就是一个线性的数组
首先HashMap中有一个静态内部类Entry,其重要的属性有key、value、next,key、value构成Entry[],next的指针指向下一个元素的引用,也就构成了链表。

十三、HasmMap和HashSet的区别
1、先了解一下HashCode
Java中的集合有两类,一类是List,一类是Set。















 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









