






// 2.准备DSL
request.source()
.query(QueryBuilders.matchAllQuery());
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
1.2 解析响应
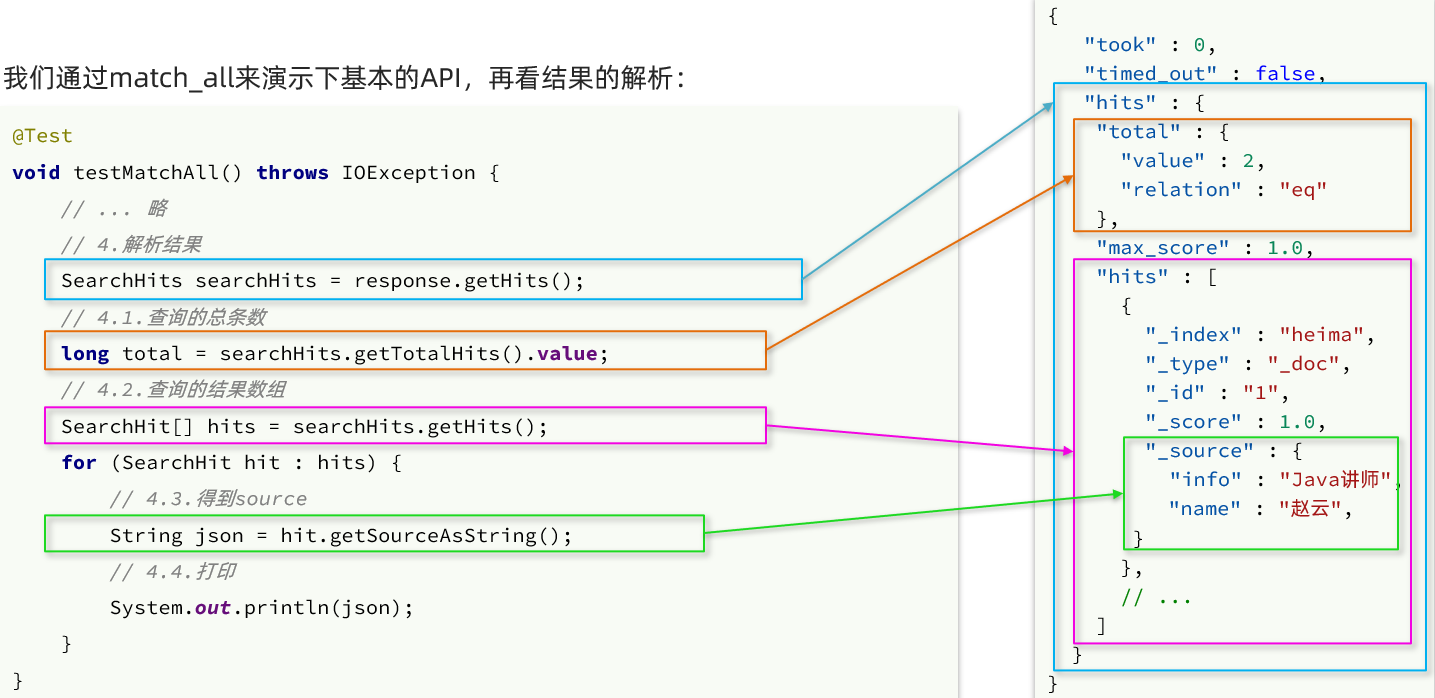
Elasticsearch 返回的结果是一个 JSON 字符串,结构包含:
-
hits:命中的结果 -
total:总条数,其中的value是具体的总条数值 -
max_score:所有结果中得分最高的文档的相关性算分 -
hits:搜索结果的文档数组,其中的每个文档都是一个json对象 -
_source:文档中的原始数据,也是json对象
因此,我们解析响应结果,就是逐层解析 JSON 字符串,流程如下:
-
SearchHits:通过response.getHits()获取,就是 json 中的最外层的 hits,代表命中的结果 -
SearchHits.getTotalHits().value:获取总条数信息 -
SearchHits.getHits():获取 SearchHit 数组,也就是文档数组 -
SearchHit.getSourceAsString():获取文档结果中的_source,也就是原始的 json 文档数据
代码如下:
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println(“共搜索到” + total + “条数据”);
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
全文检索的match和multi_match查询与match_all的API基本一致。差别是查询条件,也就是query的部分:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RZnWRIUT-1637321196523)(file://C:\Users\30287\Desktop\Java%E5%AD%A6%E4%B9%A0%E8%A7%86%E9%A2%91\day03-Docker\day06-Elasticsearch02%E8%AE%B2%E4%B9%89\assets\image-20210721215923060.png?lastModify=1637305637)]](https://img-blog.csdnimg.cn/7ce19c3201de42e8821a77a384636e11.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATEwuTEVCUk9O,size_20,color_FFFFFF,t_70,g_se,x_16)

代码如下:
@Test
void testMatch() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest(“hotel”);
// 2.准备DSL
request.source()
.query(QueryBuilders.matchQuery(“all”, “如家”));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
精确查询主要是两者:
-
term:词条精确匹配 -
range:范围查询

布尔查询是用must、must_not、filter等方式组合其它查询,代码示例如下:
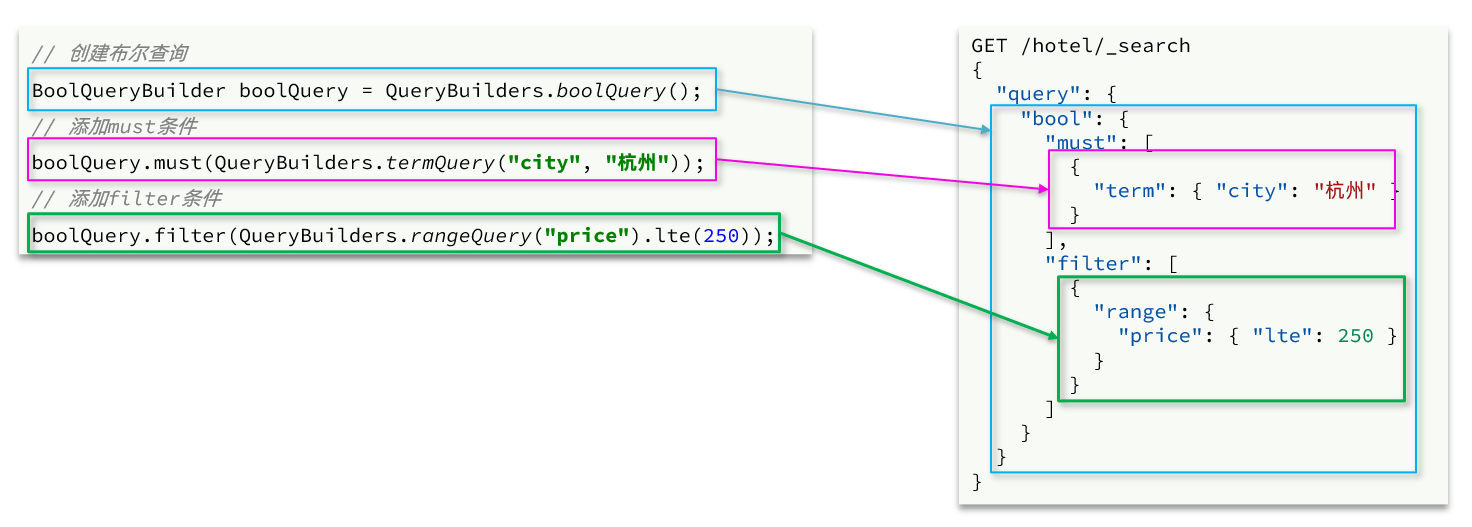
代码如下:
@Test
void testBool() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest(“hotel”);
// 2.准备DSL
// 2.1.准备BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.2.添加term
boolQuery.must(QueryBuilders.termQuery(“city”, “杭州”));
// 2.3.添加range
boolQuery.filter(QueryBuilders.rangeQuery(“price”).lte(250));
request.source().query(boolQuery);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
搜索结果的排序和分页是与query同级的参数,因此同样是使用request.source()来设置。
对应的API如下:

代码如下:
@Test
void testPageAndSort() throws IOException {
// 页码,每页大小
int page = 1, size = 5;
// 1.准备Request
SearchRequest request = new SearchRequest(“hotel”);
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchAllQuery());
// 2.2.排序 sort
request.source().sort(“price”, SortOrder.ASC);
// 2.3.分页 from、size
request.source().from((page - 1) * size).size(5);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
高亮的代码与之前代码差异较大,有两点:
-
查询的DSL:其中除了查询条件,还需要添加高亮条件,同样是与
query同级。 -
结果解析:结果除了要解析
_source文档数据,还要解析高亮结果
6.1 高亮请求构建
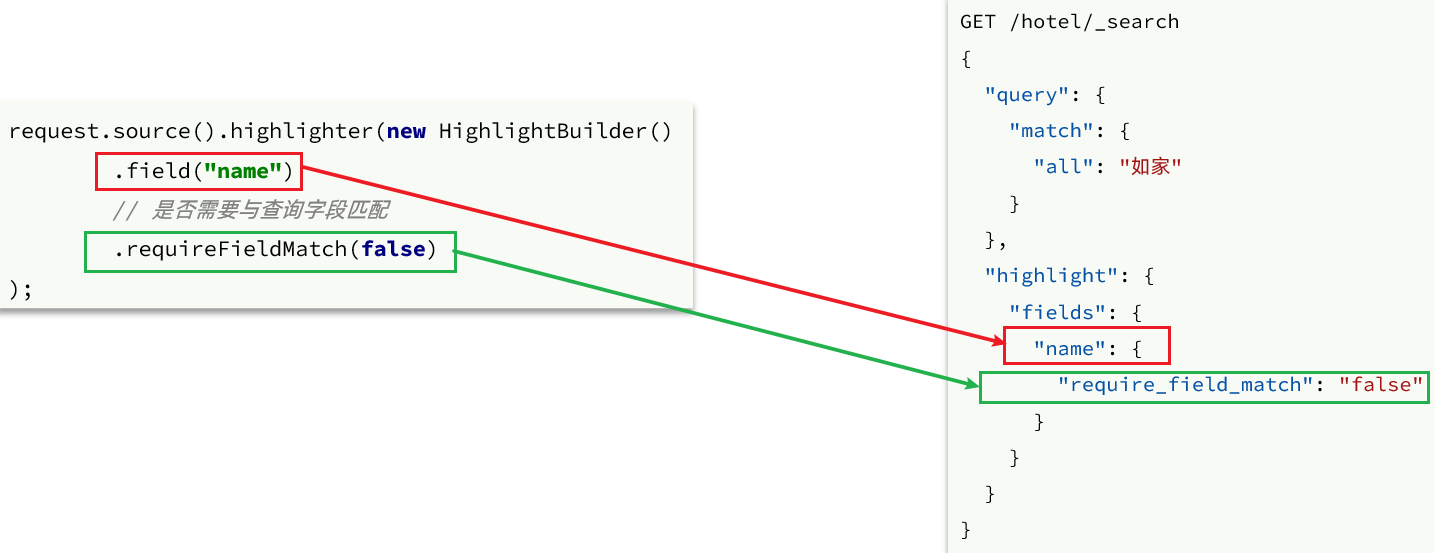
上述代码省略了查询条件部分,但是大家不要忘了:高亮查询必须使用全文检索查询,并且要有搜索关键字,将来才可以对关键字高亮。
代码如下:
@Test
void testHighlight() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest(“hotel”);
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchQuery(“all”, “如家”));
// 2.2.高亮
request.source().highlighter(new HighlightBuilder().field(“name”).requireFieldMatch(false));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
6.2 高亮结果解析
高亮的结果与查询的文档结果默认是分离的,并不在一起。
因此解析高亮的代码需要额外处理:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zGRCYyYF-1637321196538)(file://C:\Users\30287\Desktop\Java%E5%AD%A6%E4%B9%A0%E8%A7%86%E9%A2%91\day03-Docker\day06-Elasticsearch02%E8%AE%B2%E4%B9%89\assets\image-20210721222057212.png?lastModify=1637306246)]](https://img-blog.csdnimg.cn/c6b14de16b7f42e09b105ba83ff2739a.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATEwuTEVCUk9O,size_20,color_FFFFFF,t_70,g_se,x_16)
代码解读:
-
第一步:从结果中获取source。
hit.getSourceAsString(),这部分是非高亮结果,json字符串。还需要反序列为HotelDoc对象 -
第
二步:获取高亮结果。hit.getHighlightFields(),返回值是一个Map,key是高亮字段名称,值是HighlightField对象,代表高亮值 -
第三步:从map中根据高亮字段名称,获取高亮字段值对象
HighlightField -
第四步:从
HighlightField中获取Fragments,并且转为字符串。这部分就是真正的高亮字符串了 -
第五步:用高亮的结果替换HotelDoc中的非高亮结果
代码如下:
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println(“共搜索到” + total + “条数据”);
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









