







对于数据的预处理是sklearn中最重要的一个部分,它涉及到对数据的特征筛选,填补缺失值,修改异常值等等,优秀的数据预处理不仅能够得到更好的预测结果,还能够减少计算算力。这一节涉及到的不仅仅是sklearn的调用,更多的是运用pandas和numpy进行操作。
- 常见数据的操作
newdata.drop(["Sex","Embarked"],axis=1,inplace=True)#删除某一行
newdata = pd.concat([data,pd.DataFrame(result)],axis=1) #合并两个列表
data.shape#(150000, 11)#查看数据的形状
data.drop_duplicates(inplace=True)#去除重复值,inplace=True表示替换原数据
data.index = range(data.shape[0])#删除之后千万不要忘记,恢复索引#numpy的array相加,不能直接append
name2=np.array(["tenure","MonthlyCharges","TotalCharges","Churn"])
name=np.append(name1,name2)
#numel -->tensor中的全部内容数量- 获取数据并查看数据
#导库-数据挖掘三大库
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
#导入数据
#先观察泰坦尼克号的数据集,进行数据的预处理
data=pd.read_csv(".csv")
data.info()#查看数据的详细情况
data.head()#查看数据的前5行
data.describe()#查看数字类型数据的各种参数- 数据预处理
数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程。可能面对的问题有:数据类型不同,比如有的是文字,有的是数字,有的含时间序列,有的连续,有的间断。 也可能,数据的质量不行,有噪声,有异常,有缺失,数据出错,量纲不一,有重复,数据是偏态,数据量太大或太小。数据预处理的目的:让数据适应模型,匹配模型的需求。
1.数据的标准化 - 归一化和正态化
归一化:统一量纲化,把范围压缩至0-1
#备份特征的名称
name = data_.columns
from sklearn.preprocessing import MinMaxScaler
data_ = pd.DataFrame(MinMaxScaler().fit_transform(data_))
data_.columns = name#恢复正态化:统一量纲化,把范围压缩成一个正态分布
name = data_.columns
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit_transform(data)
data_.columns = name如果你对于模型的可解释性有要求的话,我们就尽量不要使用数据的归一化,因为归一化会使数据的可解释性大幅度降低,尽管有反归一化,但是我们还是无法科学地去解释这一过程,这也是逻辑回归至今仍然在金融界占据重要地位的原因。
2.缺失值处理
在数据挖掘和分析中之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的情况。因此,数据预处理中非常重要的一项就是处理缺失值。
- 填补缺失值

from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer() #实例化,默认均值填补
imp_median = SimpleImputer(strategy="median") #用中位数填补
imp_0 = SimpleImputer(strategy="constant",fill_value=0) #用0填补
imp_mean = imp_mean.fit_transform(Age) #fit_transform一步完成调取结果
imp_median = imp_median.fit_transform(Age)
imp_0 = imp_0.fit_transform(Age)
#注意,输入的矩阵必须是二维的,如果提取出一个一维矩阵进行填补时,应该先把它转化为二维矩阵
Age = data.loc[:,"Age"].values.reshape(-1,1) #sklearn当中特征矩阵必须是二维运用numpy其实更加简单:
#用中位数对缺失值进行填补
data.loc[:,"Age"] = data.loc[:,"Age"].fillna(data.loc[:,"Age"].median())- 删除缺失值(当缺失值比较少的时候)
data.dropna(axis=0,inplace=True)
#.dropna(axis=0)删除所有有缺失值的行,.dropna(axis=1)删除所有有缺失值的列
#参数inplace,为True表示在原数据集上进行修改,为False表示生成一个复制对象,不修改原数据,默认False- 编码与哑变量
在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fifit的时候全部要求输入数组或矩阵,也不能够导入文字型数据(其实手写决策树和普斯贝叶斯可以处理文字,但是sklearn中规定必须导入数值型)。
#标签专用
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder().fit(y) #导入数据
label = le.transform(y) #transform接口调取结果
le.classes_ #属性.classes_查看标签中究竟有多少类别
label #查看获取的结果label
le.fit_transform(y) #也可以直接fit_transform一步到位
le.inverse_transform(label) #使用inverse_transform可以逆转
data.iloc[:,-1] = label #让标签等于我们运行出来的结果
#一步到位
from sklearn.preprocessing import LabelEncoder
data.iloc[:,-1] = LabelEncoder().fit_transform(data.iloc[:,-1])#特征专用
from sklearn.preprocessing import OrdinalEncoder
#接口categories_对应LabelEncoder的接口classes_,一模一样的功能
OrdinalEncoder().fit(data_.iloc[:,1:-1]).categories_
data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1])
data_.head()独热编码:OrdinalEncoder可以用来处理有序变量,但对于名义变量,我们只有使用哑变量的方式来处理,才能够尽量向算法传达最准确的信息,所以我们就需要运用到独热编码:
from sklearn.preprocessing import OneHotEncoder
temp=OneHotEncoder(categories='auto').fit(X)
temp.get_feature_names()#获取独热编码的特征名字
X=temp.transform(X).toarray()3.二值化和分段
- 二值化
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。二值化是对文本计数数据的 常见操作,分析人员可以决定仅考虑某种现象的存在与否。它还可以用作考虑布尔随机变量的估计器 的预处理步骤。
from sklearn.preprocessing import Binarizer
X = data_2.iloc[:,0].values.reshape(-1,1) #类为特征专用,所以不能使用一维数组
transformer = Binarizer(threshold=30).fit_transform(X)- 特征选择
1. 方差过滤法(只能用于数值型)
以无论接下来的特征工程要做什么,都要优先消除方差为0的特征。VarianceThreshold有重要参数threshold,表示方差的阈值,表示舍弃所有方差小于threshold的特征,不填默认为0,即删除所有的记录都相同的特征。过滤法可以作为数据预处理的一个有效的尝试,我们可以先进行小幅度的方差过滤,如果模型的精度提高了,可以认为我们过滤掉的是一些噪声,如果降低的话就说明过滤掉了重要特征,不可取,那我们就放弃过滤,使用其他手段来进行特征选择。

from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold() #实例化,不填参数默认方差为0
X_var0 = selector.fit_transform(X) #获取删除不合格特征之后的新特征矩阵
#也可以直接写成 X = VairanceThreshold().fit_transform(X)
X_var0.shape2.相关性过滤
我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息。如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会给模型带来噪音。在sklearn当中,我们有三种常用的方法来评判特征与标签之间的相关性:卡方,F检验,互信息。我们使用互信息法进行了解:
互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法。和F检验相似,它既可以做回归也可以做分类,并且包含两个类feature_selection.mutual_info_classif(互信息分类)和 feature_selection.mutual_info_regression(互信息回归)。这两个类的用法和参数都和F检验一模一样,不过互信息法比F检验更加强大,F检验只能够找出线性关系,而互信息法可以找出任意关系。互信息法不返回p值或F值类似的统计量,它返回“每个特征与目标之间的互信息量的估计”,这个估计量在[0,1]之间取值,为0则表示两个变量独立,为1则表示两个变量完全相关。以互信息分类为例的代码如下:
#X_fsvar:特征矩阵,result <= 0表示没有关系
from sklearn.feature_selection import mutual_info_classif as MIC
result = MIC(X_fsvar,y) k = result.shape[0] - sum(result <= 0)
#X_fsmic = SelectKBest(MIC, k=填写具体的k).fit_transform(X_fsvar, y)
#cross_val_score(RFC(n_estimators=10,random_state=0),X_fsmic,y,cv=5).mean()
所有特征的互信息量估计都大于0,因此所有特征都与标签相关。
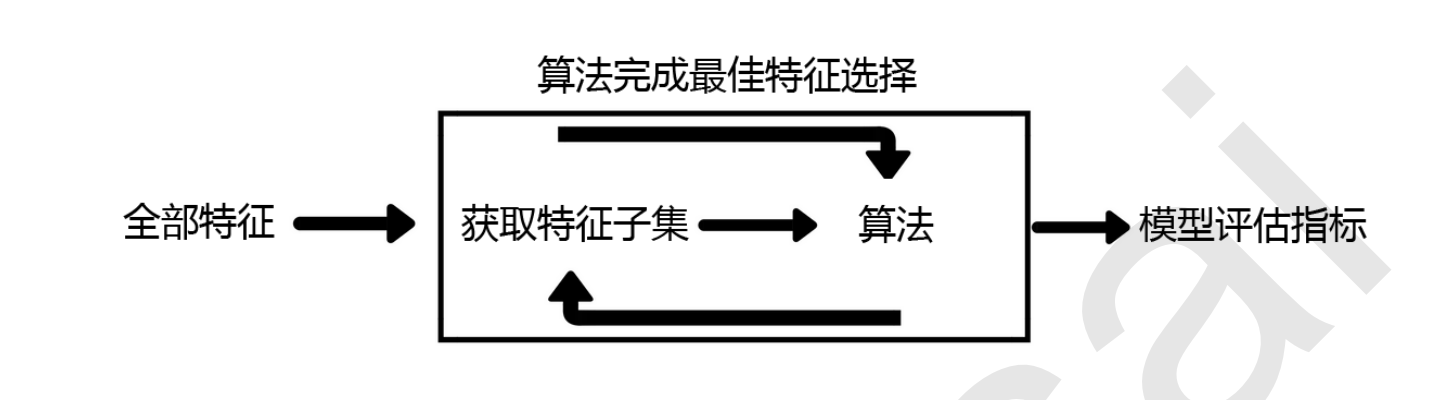
3.Embedded嵌入法
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行。先使
用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。
当你觉得嵌入法非常牛逼,觉得可以吊打过滤法的时候,可以告诉你,嵌入法使用的局限性很大,它不适用于大型的数据集:1.它涉及算法计算,计算量比较大;2.它有一个超参数k(阈值,界定是否选择为特征)很难去界定,如果画学习曲线的话会十分慢。所以我们要灵活使用,看情况来。
嵌入法的参数:

#以随机森林为例子
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
RFC_ = RFC(n_estimators =10,random_state=0)
X_embedded = SelectFromModel(RFC_,threshold=0.005).fit_transform(X,y)4.Wrapper包装法
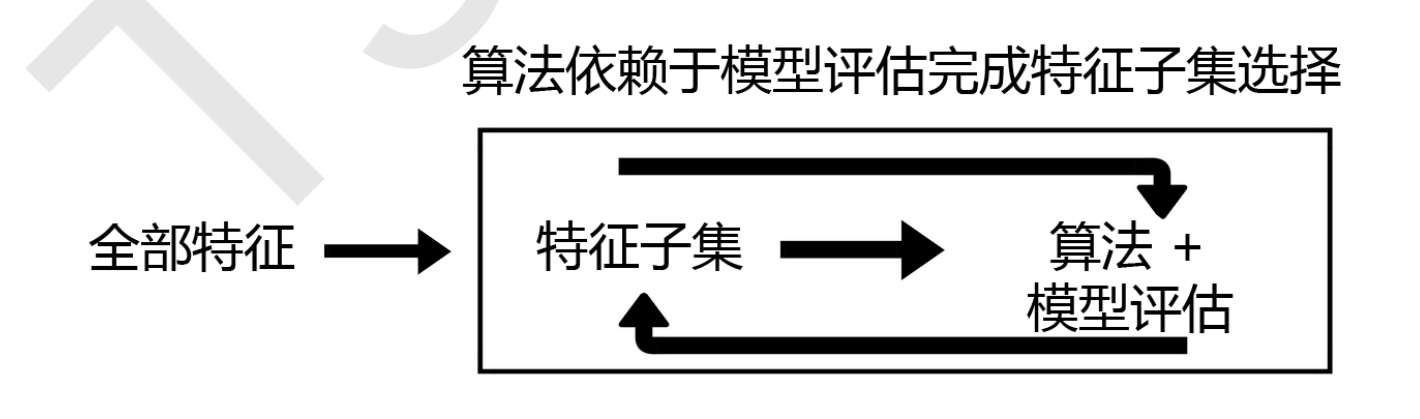
包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,但不同的是,我们往往使用一个目标函数作为黑盒来帮助我们选取特征,而不是自己输入某个评估指标或统计量的阈值。所以,它的时间复杂度和计算力是最高的。
意,在这个图中的“算法”,指的不是我们最终用来导入数据的分类或回归算法(即不是随机森林),而是专业的数据挖掘算法,即我们的目标函数。这些数据挖掘算法的核心功能就是选取最佳特征子集。
重要参数:

from sklearn.feature_selection import RFE
#n_features_to_select:筛选出多少个特征,#step:每次移除多少个特征
selector = RFE(RFC_, n_features_to_select=, step=).fit(X, y)
selector.support_.sum()#特征是否被选择的布尔矩阵
selector.ranking_#返回重要性排名
X_wrapper = selector.transform(X)














 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









