







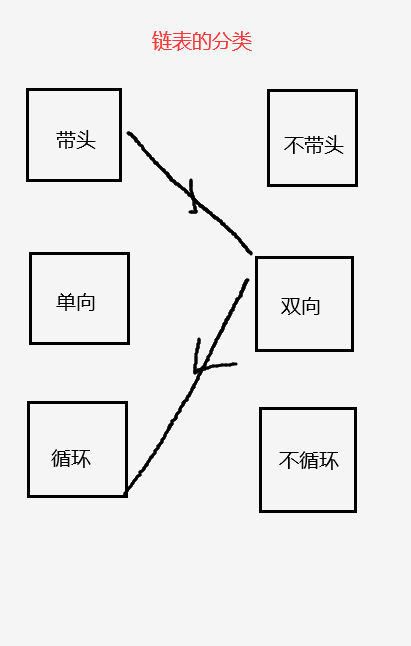
定义
链表分类
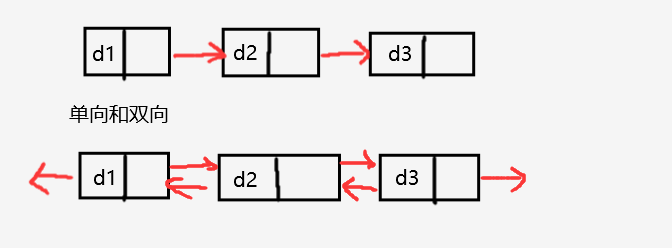
单向和双向
带头和不带头
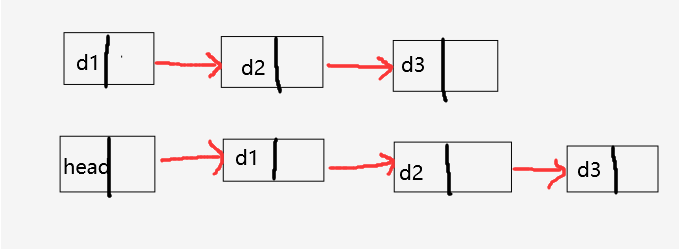
带头是指存在一个头结点(哨兵位),但是不存储任何有效数据,用来占位子
注意:单链表是不带头的,方便理解,有时候称为第一个结点为头结点,实际上是没有头结点的
循环和不循环
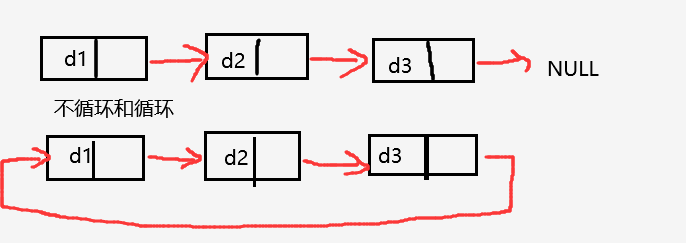
双向链表:带头双向循环链表
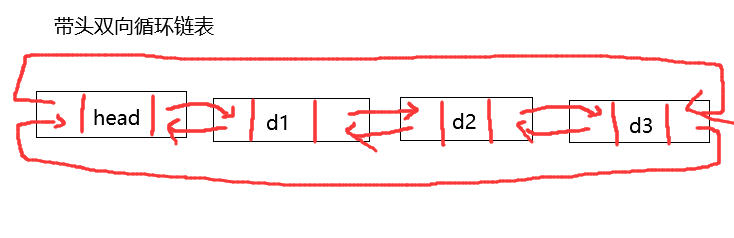
组成:保存的数据 + 指向下一个结点的指针 + 指向上一个节点的指针
单链表为空时,指向第一个节点的指针为空,双链表为空时,链表中只有一个头结点!
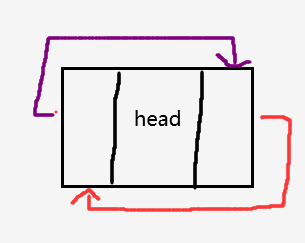
初始化
法一:定义一个双向链表的结构体,然后将指向双向链表的指针plist作为形参开始初始化然后返回
法二:通过函数的返回值来返回
函数的声明
//结构的定义
typedef int LTDataType;
typedef struct ListNode {
LTDataType data;
struct ListNode* next;
struct ListNode* prev;
}LTNode;
//初始化(法一)
void LTInit(LTNode** pphead);
//法二:
//LTNode* LTInit();
函数的实现
#include"List.h"
//申请空间
LTNode* LTBuyNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
if (newnode == NULL)
{
perror("malloc fail!");
exit(1);
}
newnode->data = x;
newnode->next = newnode->prev = newnode;
return newnode;
}
//初始化(法一)
void LTInit(LTNode** pphead)
{
assert(pphead);
*pphead = LTBuyNode(-1);
}
/*法二
LTNode* LTInit()
{
LTNode* phead = LTBuyNode(-1);
return phead;//返回双向链表的头结点
}*/
函数的测试
#include"List.h"
void test01()
{ //法一:
LTNode* plist = NULL;//单链表为空时,指向第一个节点的指针为空
//双链表为空时,链表中只有一个头结点!
LTInit(&plist);
/*法二:
LTNode* plist = LTInit();
*/
}
int main()
{
test01();
return 0;
}
法一:相当于你提着一个空的油桶(一个形参)去买油,然后给你装满油;
法二:相当于你空手去买油,然后连油带桶给你(推荐这种)。
打印
单链表的打印是从第一个结点开始往后遍历,且第一个结点不能为空while(pcur),但是双链表的第一个结点(哨兵位)就不储存数据,所以当还是用相同的办法会陷入死循环,如何解决?
将哨兵位的下一个结点定为pcur,向后遍历,停止的标志为pcur = phead
//打印
void LTPrint(LTNode* phead)
{
LTNode* pcur = phead->next;
while (pcur != phead) //将哨兵位的下一个结点定为pcur,向后遍历,停止的标志为pcur = phead
{
printf("%d -> ", pcur->data);
pcur = pcur->next;
}
printf("\n");
}
尾插
双向链表中尾插,头结点不会发生改变(哨兵位),所以传一级指针。
phead指向链表的第一个结点,通过phead->prev找到尾结点,然后申请一个新结点(newnode),当尾插进来,受到影响的指针有“尾结点的next指针不再指向头结点,而是指向newnode;头结点的prev指针不再指向尾结点,而是指向newnode”,最后newnode的next指针指向头结点。
但是修改的顺序是?先修改对原链表没有影响的结点,因为先修改头结点的prev指针指向newnode后你就找不到原来的尾结点了;通常一般先改变newnodeprev和next指针,最后改头结点受到影响的。
//尾插
void LTPushBack(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* newnode = LTBuyNode(x);
newnode->prev = phead->prev;
newnode->next = phead;
phead->prev->next= newnode;
phead->prev = newnode;
}
头插
newnode放在哨兵位的后面,如果放在哨兵位的前面则相当于尾插。
phead指向链表的第一个结点,通过phead->next找到哨兵位下一个结点,然后申请一个新结点(newnode),当头插进来,受到影响的指针有“头结点的next指针不再指向哨兵位下一个结点,而是指向newnode;哨兵位下一个结点的prev指针不再指向头结点,而是指向newnode”,最后newnode的next指针指向头结点。
但是修改的顺序是?先修改对原链表没有影响的结点,因为先修改头结点的next指针指向newnode后你就找不到原来哨兵位下一个结点了;通常一般先改变newnodeprev和next指针,最后改头结点受到影响的。
//头插
void LTPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* newnode = LTBuyNode(x);
newnode->next = phead->next;
newnode->prev = phead;
phead->next->prev = newnode;
phead->next = newnode;
}
尾删
删除phead->prev指针,思考能不能直接释放掉?
如果直接释放掉,phead->prev和phead->prev->prev->next均会变成野指针,所以要先将phead->prev->prev->next指向头结点,然后将头结点的prev指针指向phead->prev->prev->next。删除之前要将此结点存起来del = phead->prev,执行完上述操作后释放掉,并且置位空。
//判断链表是否为空:只有一个头结点,记得在头文件声明
bool LTEmpty(LTNode* phead)
{
assert(phead);
return phead->next == phead;
} // 返回true为空,反回flase不为空
//尾删
void LTPopBack(LTNode* phead)
{
assert(!LTEmpty(phead));
LTNode* del = phead->prev;
del->prev->next = phead;
phead->prev = del->prev;
free(del);
del = NULL;
}
头删
删除phead->next指针,先将del->next->prev指向头结点,然后将头结点的next指针指向del->next。删除之前要将此结点存起来del = phead->next,执行完上述操作后释放掉,并且置位空。
//判断链表是否为空:只有一个头结点
bool LTEmpty(LTNode* phead)
{
assert(phead);
return phead->next == phead;
} // 返回true为空,反回flase不为空
//头删
void LTPopFront(LTNode* phead)
{
assert(!LTEmpty(phead));
LTNode* del = phead->next;
del->next->prev = phead;
phead->next = del->next;
free(del);
del = NULL;
}
以上时间复杂度全是O(1),不需要遍历
查找
定义一个pcur为phead的next结点,然后进行遍历查找,找到了就返回查找的值,没有找到就返回空,循环的条件是pcur不走到头结点。
//查找,记得添加到头文件
LTNode* LTFind(LTNode* phead, LTDataType x)
{
LTNode* pcur = phead->next;
while (pcur != phead)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
在pos(指定位置)之后插入结点
先修改对原链表没有影响的结点
受到影响的结点:pos,pos->next这两个结点
还是先改newnode指针的指向,然后改pos->next指向的结点,最后改pos结点
//在pos位置后插入结点
void LTInsertBack(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* newnode = LTBuyNode(x);
newnode->next = pos->next;
newnode->prev = pos;
pos->next->prev = newnode;
pos->next = newnode;
}
在pos(指定位置)之前插入结点
先修改对原链表没有影响的结点
受到影响的结点:pos,pos->prev这两个结点
还是先改newnode指针的指向,然后改pos->prev指向的结点,最后改pos结点
//在pos位置前插入结点
void LTInsertFront(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* newnode = LTBuyNode(x);
newnode->next = pos;
newnode->prev = pos->prev;
pos->prev->next = newnode;
pos->prev = newnode;
}
删除pos(指定位置)的结点
//删除pos位置的结点
void LTErase(LTNode* pos)
{
assert(pos);
pos->next->prev = pos->prev;
pos->prev->next = pos->next;
free(pos);
pos = NULL;
}
销毁
定义一个pcur指向头结点的下一个结点的地址,当pcur不等于头结点(哨兵位)时,进入循环,将pcur的下一个结点先保存下来,然后销毁pcur,然后让pcur走到刚刚保存的下一个结点,就这样进行遍历,最后销毁完全部后在手动销毁头结点并且置位空。
//链表的销毁,因为形参会影响实参,所以传二级指针
void LTDestroy(LTNode** pphead)
{
LTNode* pcur = (*pphead)->next;
while (pcur != *pphead)
{
LTNode* next = pcur->next;
free(pcur);
pcur = next;
}
free(*pphead);
*pphead = NULL;
}
void test01()
{
LTDestroy(&plist);
}
但是这个定义的函数违背了接口一致性?因为其他的所有函数都是传的一级指针,此处传的二级,如何解决?
void LTDestroy(LTNode* phead)
{
LTNode* pcur = phead->next;
while (pcur != phead)
{
LTNode* next = pcur->next;
free(pcur);
pcur = next;
}
free(phead);
phead = NULL;
}
因为这样不能改变形参的值,需要手动置空
void test01()
{
LTDestroy(plist);
plist = NULL;
}
顺序表与链表的分析
| 对比维度 | 顺序表 | 单链表 | 双向链表 |
|---|---|---|---|
| 存储结构 | 物理连续(数组) | 节点 + 单向指针 | 节点 + 前驱/后继双指针 |
| 随机访问效率 | O(1) | O(n) | O(n) |
| 头插/头删效率 | O(n)(需移动元素) | O(1) | O(1) |
| 尾插/尾删效率 | O(1)(若预留空间) | O(n)(需遍历) | O(1)(直接访问尾节点) |
| 任意位置插入删除 | O(n) | O(n)(需找前驱节点) | O(1)(已知位置时) |
| 空间开销 | 仅数据 | 数据 + 1个指针/节点 | 数据 + 2个指针/节点 |
| 内存灵活性 | 需预分配,可能浪费 | 动态分配,无浪费 | 动态分配,无浪费 |
| 逆向遍历 | 支持(但效率同正向) | 不支持 | 支持(O(n)) |
| 适用场景 | 高频访问、数据量稳定 | 频繁头操作、未知数据量 | 需要双向操作(如LRU缓存) |

















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









