






(5)
这段汇编代码在 .text 段生成一条 lock 指令前缀 0xf0(LOCK指令的操作码是0xF0),在 .smp_locks section 生成四个字节的 lock 前缀的地址,链接的时候,所有的 .smp_locks section合并起来,形成一个所有 lock 指令地址的数组,这样统计 .smp_locks section 就能知道代码里有多少个加锁的指令被生成。
(6)
常见的锁前缀在一个单独的表中作为特殊情况处理,这个表是一个纯地址列表,没有替换的ptr和大小信息。这样可以使表的大小保持较小。也就是将text中将lock指针的地址置于.smp_locks section中。
这样我们就可以从 smp_locks section中知道 text 代码中所有带有 lock 指令前缀信息了。
3、源码分析
3.1 module_finalize
module_finalize是一个与体系架构相关的函数,允许不同体系架构的实现执行特定于系统的结束工作。简单点来说就是模块加载的结束时调用的函数。
// /arch/x86/kernel/module.c
int module\_finalize(const Elf_Ehdr \*hdr,
const Elf_Shdr \*sechdrs,
struct module \*me)
{
const Elf_Shdr \*s, \*text = NULL, \*alt = NULL, \*locks = NULL,
\*para = NULL;
char \*secstrings = (void \*)hdr + sechdrs[hdr->e_shstrndx].sh_offset;
for (s = sechdrs; s < sechdrs + hdr->e_shnum; s++) {
if (!strcmp(".text", secstrings + s->sh_name))
text = s;
if (!strcmp(".altinstructions", secstrings + s->sh_name))
alt = s;
if (!strcmp(".smp\_locks", secstrings + s->sh_name))
locks = s;
if (!strcmp(".parainstructions", secstrings + s->sh_name))
para = s;
}
if (alt) {
/\* patch .altinstructions \*/
void \*aseg = (void \*)alt->sh_addr;
apply\_alternatives(aseg, aseg + alt->sh_size);
}
if (locks && text) {
void \*lseg = (void \*)locks->sh_addr;
void \*tseg = (void \*)text->sh_addr;
alternatives\_smp\_module\_add(me, me->name,
lseg, lseg + locks->sh_size,
tseg, tseg + text->sh_size);
}
if (para) {
void \*pseg = (void \*)para->sh_addr;
apply\_paravirt(pseg, pseg + para->sh_size);
}
/\* make jump label nops \*/
jump\_label\_apply\_nops(me);
return 0;
}
3.2 alternatives_smp_module_add
对于上面这段代码我们重点关注这部分,如果模块有.text 和 .smp_locks section 就调用 alternatives_smp_module_add 函数。
(1)
if (locks && text) {
void \*lseg = (void \*)locks->sh_addr;
void \*tseg = (void \*)text->sh_addr;
alternatives\_smp\_module\_add(me, me->name,
lseg, lseg + locks->sh_size,
tseg, tseg + text->sh_size);
}
(2)
/\* make jump label nops \*/
jump\_label\_apply\_nops(me);
// arch/x86/kernel/alternative.c
#ifdef CONFIG\_SMP
struct smp\_alt\_module {
/\* what is this ??? \*/
struct module \*mod;
char \*name;
/\* ptrs to lock prefixes \*/
const s32 \*locks;
const s32 \*locks_end;
/\* .text segment, needed to avoid patching init code ;) \*/
u8 \*text;
u8 \*text_end;
struct list\_head next;
};
static LIST\_HEAD(smp_alt_modules);
static DEFINE\_MUTEX(smp_alt);
static bool uniproc_patched = false; /\* protected by smp\_alt \*/
void __init_or_module alternatives\_smp\_module\_add(struct module \*mod,
char \*name,
void \*locks, void \*locks_end,
void \*text, void \*text_end)
{
struct smp\_alt\_module \*smp;
mutex\_lock(&smp_alt);
if (!uniproc_patched)
goto unlock;
if (num\_possible\_cpus() == 1)
/\* Don't bother remembering, we'll never have to undo it. \*/
goto smp_unlock;
smp = kzalloc(sizeof(\*smp), GFP_KERNEL);
if (NULL == smp)
/\* we'll run the (safe but slow) SMP code then ... \*/
goto unlock;
smp->mod = mod;
smp->name = name;
smp->locks = locks;
smp->locks_end = locks_end;
smp->text = text;
smp->text_end = text_end;
DPRINTK("%s: locks %p -> %p, text %p -> %p, name %s\n",
\_\_func\_\_, smp->locks, smp->locks_end,
smp->text, smp->text_end, smp->name);
list\_add\_tail(&smp->next, &smp_alt_modules);
smp_unlock:
alternatives\_smp\_unlock(locks, locks_end, text, text_end);
unlock:
mutex\_unlock(&smp_alt);
}
#endif /\* CONFIG\_SMP \*/
如果是多处理器:
list\_add\_tail(&smp->next, &smp_alt_modules);
如果是单处理器,将锁前缀转换为DS段覆盖前缀:
if (num\_possible\_cpus() == 1)
/\* Don't bother remembering, we'll never have to undo it. \*/
goto smp_unlock;
smp_unlock:
alternatives\_smp\_unlock(locks, locks_end, text, text_end);
static void alternatives\_smp\_unlock(const s32 \*start, const s32 \*end,
u8 \*text, u8 \*text_end)
{
const s32 \*poff;
mutex\_lock(&text_mutex);
for (poff = start; poff < end; poff++) {
u8 \*ptr = (u8 \*)poff + \*poff;
if (!\*poff || ptr < text || ptr >= text_end)
continue;
/\* turn lock prefix into DS segment override prefix \*/
if (\*ptr == 0xf0)
text\_poke(ptr, ((unsigned char []){0x3E}), 1);
}
mutex\_unlock(&text_mutex);
}
// /arch/x86/include/asm\nops.h
#define NOP\_DS\_PREFIX 0x3e
0xf0 -> 0x3E :把 lock prefix 换成 DS override prefix
从函数名我们就可以知道,如果是单处理器,就将加锁前缀的指令解锁。即:即使内核配置了 smp,但是实际运行到单处理器上时,通过运行期间打补丁,根据 .smp_locks 里的记录,把 lock 指令前缀替换成 DS override prefix(nop指令) 以消除指令加锁的开销。
相对应有一个加锁的函数:
static void alternatives\_smp\_lock(const s32 \*start, const s32 \*end,
u8 \*text, u8 \*text_end)
{
const s32 \*poff;
mutex\_lock(&text_mutex);
for (poff = start; poff < end; poff++) {
u8 \*ptr = (u8 \*)poff + \*poff;
if (!\*poff || ptr < text || ptr >= text_end)
continue;
/\* turn DS segment override prefix into lock prefix \*/
if (\*ptr == 0x3e)
text\_poke(ptr, ((unsigned char []){0xf0}), 1);
}
mutex\_unlock(&text_mutex);
}
把 DS segment override prefix 替换成 lock prefix。
Instruction Prefixes
指令前缀分为四组,每组有一组可允许的前缀码。对于每条指令,只需要从四组(组1、2、3、4)中的每一组中包含一个前缀码就可以了。这里我只关注 LOCK prefix (F0H)和 DS segment override prefix(3EH)。
更多信息可参考:Intel 手册 2.1.1 Instruction Prefixes。
• Group 1
Lock and repeat prefixes:
• LOCK prefix is encoded using F0H.
• Group 2
— Segment override prefixes:
• 3EH—DS segment override prefix (use with any branch instruction is reserved).
3.3 jump_label_apply_nops
遍历该模块的所有jump_entry条目,传递参数:JUMP_LABEL_DISABLE。将模块的jump_entry条目填充nop空字节。

W (write), A (alloc)
// /kernel/jump\_label.c
/\*\*\*
\* apply\_jump\_label\_nops - patch module jump labels with arch\_get\_jump\_label\_nop()
\* @mod: module to patch
\*
\* Allow for run-time selection of the optimal nops. Before the module
\* loads patch these with arch\_get\_jump\_label\_nop(), which is specified by
\* the arch specific jump label code.
\*/
void jump\_label\_apply\_nops(struct module \*mod)
{
struct jump\_entry \*iter_start = mod->jump_entries;
struct jump\_entry \*iter_stop = iter_start + mod->num_jump_entries;
struct jump\_entry \*iter;
/\* if the module doesn't have jump label entries, just return \*/
if (iter_start == iter_stop)
return;
//遍历该模块的所有jump\_entry条目,注意这里传递的参数是JUMP\_LABEL\_DISABLE
for (iter = iter_start; iter < iter_stop; iter++) {
arch\_jump\_label\_transform\_static(iter, JUMP_LABEL_DISABLE);
}
}
// arch/x86/include/asm/jump\_label.h
#ifdef CONFIG\_X86\_64
typedef u64 jump\_label\_t;
#else
typedef u32 jump\_label\_t;
#endif
struct jump\_entry {
jump\_label\_t code;
jump\_label\_t target;
jump\_label\_t key;
};
// /include/linux/jump\_label.h
enum jump\_label\_type {
JUMP_LABEL_DISABLE = 0,
JUMP_LABEL_ENABLE,
};
// /include/linux/module.h
struct module
{
......
#ifdef HAVE\_JUMP\_LABEL
struct jump\_entry \*jump_entries;
unsigned int num_jump_entries;
#endif
......
/\*
\* Update code which is definitely not currently executing.
\* Architectures which need heavyweight synchronization to modify
\* running code can override this to make the non-live update case
\* cheaper.
\*/
void __weak __init_or_module arch\_jump\_label\_transform\_static(struct jump\_entry \*entry,
enum jump\_label\_type type)
{
arch\_jump\_label\_transform(entry, type);
}
// /arch/x86/kernel/jump\_label.c
#define JUMP\_LABEL\_NOP\_SIZE 5
#define ASM\_NOP\_MAX 8
#define NOP\_ATOMIC5 (ASM\_NOP\_MAX+1) /\* Entry for the 5-byte atomic NOP \*/
union jump_code_union {
char code[JUMP_LABEL_NOP_SIZE];
struct {
char jump;
int offset;
} \_\_attribute\_\_((packed));
};
// 由于传递的参数是JUMP\_LABEL\_DISABLE,模块的jump\_entry条目用nop指令替代
static void \_\_jump\_label\_transform(struct jump\_entry \*entry,
enum jump\_label\_type type,
void \*(\*poker)(void \*, const void \*, size\_t))
{
union jump_code_union code;
//如果type == JUMP\_LABEL\_ENABLE,jump\_entry是jump指令
if (type == JUMP_LABEL_ENABLE) {
code.jump = 0xe9;
code.offset = entry->target -
(entry->code + JUMP_LABEL_NOP_SIZE);
//如果type == JUMP\_LABEL\_DISABLE,jump\_entry是nop指令
} else
memcpy(&code, ideal_nops[NOP_ATOMIC5], JUMP_LABEL_NOP_SIZE);
//替换模块jump\_entry的code成员
(\*poker)((void \*)entry->code, &code, JUMP_LABEL_NOP_SIZE);
}
void arch\_jump\_label\_transform(struct jump\_entry \*entry,
enum jump\_label\_type type)
{
get\_online\_cpus();
mutex\_lock(&text_mutex);
\_\_jump\_label\_transform(entry, type, text_poke_smp);
mutex\_unlock(&text_mutex);
put\_online\_cpus();
}
// /arch/x86/kernelalternative.c
/\*\*
\* text\_poke\_smp - Update instructions on a live kernel on SMP
\* @addr: address to modify
\* @opcode: source of the copy
\* @len: length to copy
\*
\* Modify multi-byte instruction by using stop\_machine() on SMP. This allows
\* user to poke/set multi-byte text on SMP. Only non-NMI/MCE code modifying
\* should be allowed, since stop\_machine() does \_not\_ protect code against
\* NMI and MCE.
\*
\* Note: Must be called under get\_online\_cpus() and text\_mutex.
\*/
void \*__kprobes text\_poke\_smp(void \*addr, const void \*opcode, size\_t len)
{
struct text\_poke\_params tpp;
struct text\_poke\_param p;
p.addr = addr;
p.opcode = opcode;
p.len = len;
tpp.params = &p;
tpp.nparams = 1;
atomic\_set(&stop_machine_first, 1);
wrote_text = 0;
/\* Use \_\_stop\_machine() because the caller already got online\_cpus. \*/
\_\_stop\_machine(stop_machine_text_poke, (void \*)&tpp, cpu_online_mask);
return addr;
}
4、LOCK指令
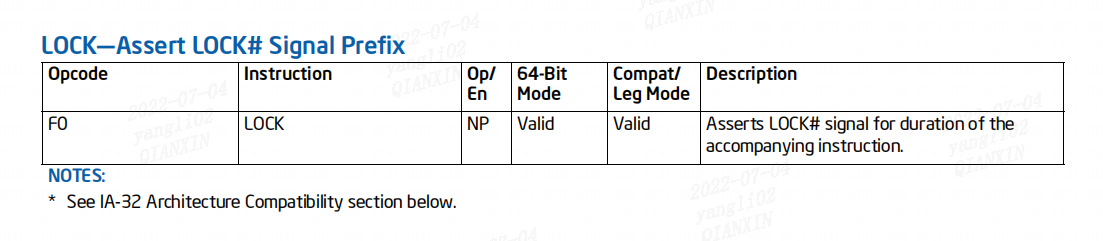
asserted:可以理解为发出信号。
使处理器的 LOCK# 信号在伴随指令的执行期间 be asserted(将指令转换为原子指令)。在多处理器环境中,LOCK# 信号确保处理器在信号被 asserted 时独占使用任何共享内存。
X86 CPU 上都具有锁定一个特定内存地址的能力,当这个特定内存地址被锁定后,它就可以阻止其他的系统总线读取或修改这个内存地址。这种能力是通过 LOCK 指令前缀再加上下面的汇编指令来实现的。当使用 LOCK 指令前缀时,它会使 CPU 发送一个 LOCK# 信号,这样就能确保在多处理器系统或多线程竞争的环境下互斥地使用这个内存地址。当指令执行完毕,这个锁定动作也就会消失。
LOCK 前缀只能添加到以下指令,并且只能添加到目标操作数是内存操作数的那些指令形式:ADD、ADC、AND、BTC、BTR、BTS、CMPXCHG、CMPXCH8B、CMPXCHG16B、DEC、INC、 NEG、NOT、OR、SBB、SUB、XOR、XADD 和 XCHG。如果LOCK前缀与这些指令中的一个一起使用,并且源操作数是内存操作数,则可能会生成一个未定义的操作码异常(#UD)。如果 LOCK 前缀与任何不在上述列表中的指令一起使用,也会产生未定义的操作码异常。无论是否存在 LOCK 前缀,XCHG 指令始终 assert LOCK# 信号。
LOCK 前缀通常与 BTS 指令一起使用,以对共享内存环境中的内存位置执行读-修改-写操作。
LOCK前缀的完整性不受内存字段对齐的影响。内存锁定会观察到任意错位的字段。
5、LOCK 操作对内部处理器缓存的影响
在大多数IA-32和所有Intel 64处理器中,锁可以在没有LOCK#信号 being asserted 的情况下发生:
对于IA-32 Architecture Compatibility,从 P6 系列处理器开始,当 LOCK 前缀作为指令和内存区域的前缀时被访问在处理器内部被缓存,LOCK#信号通常不被asserted。相反,只有处理器的缓存被锁定。 在这里,处理器的缓存一致性机制确保操作在内存方面以原子方式执行。
如果在 LOCK 操作期间被锁定的内存区域作为 write-back 内存缓存在执行 LOCK 操作的处理器中,并且完全包含在 cache line中,则处理器可能不会在总线上 assert LOCK# 信号。相反,它将在内部修改内存位置并允许其缓存一致性机制以确保操作以原子方式执行。此操作称为“cache locking”。缓存一致性机制自动防止缓存了相同内存区域的两个或多个处理器同时修改该区域中的数据。
更多信息请参考Volume 3A- Chapter 8-8.1 Locked Atomic Operations
https://blog.csdn.net/weixin_45030965/article/details/125709626
备注:简单来说,以 addl 指令为例子,就是x86处理器上用一条带有“lock”前缀的addl指令来保证原子变量v加i操作的原子性,“lock”前缀在x86上的作用是在执行 addl 指令时独占系统总线,这样即便系统总线上还有其他的master,在 addl 执行期间也无法修改v->counter的值。
x86处理器带“lock”前缀的指令(只能是上述列出的指令)能保证其原子性。
6、例子说明
硬件级的原子操作:在单处理器系统(UniProcessor)中,能够在单条指令中完成的操作都可以认为是“原子操作”,因为中断只发生在指令边缘。在多处理器结构中就不同了,由于系统中有多个处理器独立运行,即使能在单条指令中完成的操作也有可能受到干扰。在X86平台上,CPU提供了在指令执行期间对总线加锁的手段。CPU上有一根引线#HLOCK pin连到北桥,如果汇编语言的程序中在一条指令前面加上前缀"LOCK",经过汇编以后的机器代码就使CPU在执行这条指令的时候把#HLOCK pin的电位拉低,持续到这条指令结束时放开,从而把总线锁住,这样同一总线上别的CPU就暂时不能通过总线访问内存了,保证了这条指令在多处理器环境中的原子性。
LOCK前缀作用于单个指令上,它对中断没有任何影响,因为中断只能在指令之间产生。LOCK前缀的真正作用是保持对系统总线的控制,直到整条指令执行完毕。它在一条指令多次访问内存的时候相当有用。
比如一个简单的共享资源计数器,我们需要对它进行原子递增操作,需要做如下工作:
1)从内存读取该计数器的值,临时将其保存在CPU内部寄存器中。
2)在寄存器中将读取到的值加1。
3)将被修改后的值写回内存。
在x86体系结构中,这个递增操作可以在单个指令中完成,因此中断不会对该递增操作产生影响。但是该指令有两次内存访问操作,读和写,另外一个CPU可能同时对该计数器进行递增操作。如果另外一个CPU在第1步完成后,第3步完成前读取该计数器的值,那么两个CPU都使用被修改之前的计数器值并对其进行递增操作。这样就出现了错误的情况。
如果在此时使用了LOCK前缀,一个CPU在对该计数器进行操作的时候,保持对总线的控制权,直到递增操作完毕,也就是在这期间,其它的CPU不能访问该变量,直到该CPU完成所有操作为止。
备注:单处理器系统中,单条指令是“原子操作”。多处理器系统,单条指令的操作执行也会被其它CPU打断,因此在多处理器系统中单条指令并不是原子操作。在x86系统,通过在单条指令加上前缀"LOCK",保证了这条指令在多处理器环境中的原子性。
7 、ARM架构下的原子操作实现
7.1 API简介
接下来介绍下ARM64(armv8.0)架构下的原子操作实现。
armv8.0时的实现,此时系统没有LSE扩展(Large System Extension)。
备注:LSE是armv8.1增加的特性,7.5章会介绍。
// /arch/arm64/include/asm/atomic.h
/\*
\* AArch64 UP and SMP safe atomic ops. We use load exclusive and
\* store exclusive to ensure that these are atomic. We may loop
\* to ensure that the update happens.
\*/
static inline void atomic\_add(int i, atomic\_t \*v)
{
unsigned long tmp;
int result;
asm volatile("// atomic\_add\n"
"1: ldxr %w0, %2\n"
" add %w0, %w0, %w3\n"
" stxr %w1, %w0, %2\n"
" cbnz %w1, 1b"
: "=&r" (result), "=&r" (tmp), "+Q" (v->counter) // input+output
: "Ir" (i) // input
: "cc");
}
(1)ldxr %w0, %2:w0 = %2(v->counter) //使用ldxr指令把原子变量v的值加载到32位通用寄存器中
(2)add %w0, %w0, %w3: w0 = w0 + w3 //把32位通用寄存器的值加上i
(3)stxr %w1, %w0, %2:%2(v->counter) = w0 //使用stxr指令把32位寄存器的值写到原子变量v,执行结果存储在w1
(4)cbnz %w1, 1b:若w1 != 0,跳转到标号1 //果stxr指令返回1,表示存储失败,回到上述这行 “1: ldxr %w0, %2\n”
static inline void atomic\_sub(int i, atomic\_t \*v)
{
unsigned long tmp;
int result;
asm volatile("// atomic\_sub\n"
"1: ldxr %w0, %2\n"
" sub %w0, %w0, %w3\n"
" stxr %w1, %w0, %2\n"
" cbnz %w1, 1b"
: "=&r" (result), "=&r" (tmp), "+Q" (v->counter)
: "Ir" (i)
: "cc");
}
ARM64 使用 ldxr 和 stxr 指令 来保证add指令的原子性。
load exclusive
store exclusive
7.2 Load-Exclusive/Store-Exclusive简介
Load-Exclusive/Store-Exclusive指令只支持一种寻址模式:
Load/store addressing modes:
A64 指令集中的 Load/store addressing modes 需要来自通用寄存器 X0-X30 或当前堆栈指针 SP 的 64 位基地址,以及可选的立即数或寄存器偏移量。
Base register with no offset.
Load-Exclusive 指令将被访问的物理地址标记为独占访问。 此独占访问标记由 Store-Exclusive 指令检查,允许在共享内存变量、信号量、互斥锁和自旋锁上构建原子读-修改-写操作。
如果未实现 FEAT_LSE2,则:
(1)Load-Exclusive/Store-Exclusive 指令(除了Load-Exclusive pair and Store-Exclusive pair)需要自然对齐,未对齐的地址会产生对齐错误。
(2)由 Load-Exclusive pair 或 Store-Exclusive pair 指令生成的内存访问必须与 pair 的大小对齐,否则访问会产生对齐错误。
7.3 Load Exclusive register简介
LDXR(ldxr):Load Exclusive register
Load Exclusive Register从基址寄存器值 derives 地址,从内存加载 32 位字或 64 位双字,并将其写入寄存器。 内存访问是原子的。 PE 将被访问的物理地址标记为独占访问。 这个独占访问标记由Store Exclusive instructions检查。
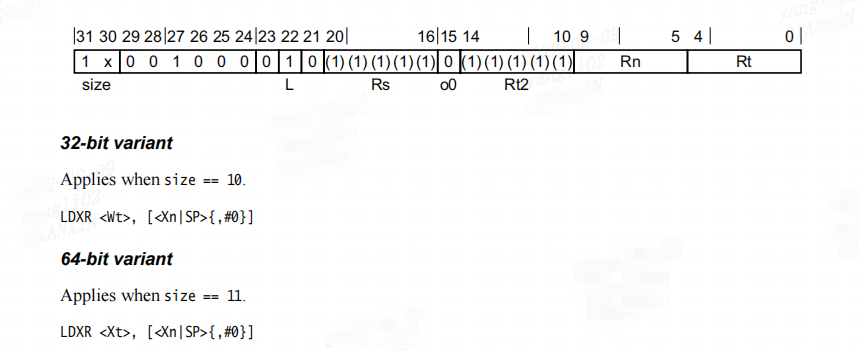
Decode for all variants of this encoding
integer n = UInt(Rn);
integer t = UInt(Rt);
integer elsize = 8 << UInt(size);
integer regsize = if elsize == 64 then 64 else 32;
boolean tag_checked = n != 31;
Assembler symbols
:是要传输的通用寄存器的 32 位名称,编码在“Rt”字段中。
:是要传输的通用寄存器的 64 位名称,编码在“Rt”字段中。
<Xn|SP>:是通用基址寄存器或堆栈指针的 64 位名称,编码在“Rn”字段中。
#0:偏移,只能是0,可以省略。变量的虚拟地址是基准地址加上偏移
备注:ARM64中32 位是通用寄存器Wn,64 位通用寄存器是Xn。
7.4 Store Exclusive register简介
STXR(stxr):Store Exclusive register
如果 PE 对内存地址具有独占访问权,则 Store Exclusive Register 将寄存器中的 32 位字或 64 位双字存储到内存中。如果存储成功,则返回状态值 0,如果未执行存储,则返回 1。

Decode for all variants of this encoding
integer n = UInt(Rn);
integer t = UInt(Rt);
integer s = UInt(Rs); // ignored by all loads and store-release
integer elsize = 8 << UInt(size);
boolean tag_checked = n != 31;
boolean rt_unknown = FALSE;
boolean rn_unknown = FALSE;
if s == t then
Constraint c = ConstrainUnpredictable();















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









