







机器学习` `深度学习入门

无论即将到来的是大数据时代还是人工智能时代,亦或是传统行业使用人工智能在云上处理大数据的时代,作为一个有理想有追求的程序员,不懂深度学习(Deep Learning)这个超热的技术,会不会感觉马上就out了?现在救命稻草来了,《零基础入门深度学习》系列文章旨在讲帮助爱编程的你从零基础达到入门级水平。零基础意味着你不需要太多的数学知识,只要会写程序就行了,没错,这是专门为程序员写的文章。虽然文中会有很多公式你也许看不懂,但同时也会有更多的代码,程序员的你一定能看懂的(我周围是一群狂热的Clean Code程序员,所以我写的代码也不会很差)。
往期回顾
在上一篇文章中,我们介绍了循环神经网络以及它的训练算法。我们也介绍了循环神经网络很难训练的原因,这导致了它在实际应用中,很难处理长距离的依赖。在本文中,我们将介绍一种改进之后的循环神经网络:长短时记忆网络(Long Short Term Memory Network, LSTM),它成功的解决了原始循环神经网络的缺陷,成为当前最流行的RNN,在语音识别、图片描述、自然语言处理等许多领域中成功应用。但不幸的一面是,LSTM的结构很复杂,因此,我们需要花上一些力气,才能把LSTM以及它的训练算法弄明白。在搞清楚LSTM之后,我们再介绍一种LSTM的变体:GRU (Gated Recurrent Unit)。 它的结构比LSTM简单,而效果却和LSTM一样好,因此,它正在逐渐流行起来。最后,我们仍然会动手实现一个LSTM。
长短时记忆网络是啥
我们首先了解一下长短时记忆网络产生的背景。回顾一下零基础入门深度学习(5) - 循环神经网络中推导的,误差项沿时间反向传播的公式:
我们可以根据下面的不等式,来获取的模的上界(模可以看做对中每一项值的大小的度量):
我们可以看到,误差项从t时刻传递到k时刻,其值的上界是的指数函数。分别是对角矩阵和矩阵W模的上界。显然,除非乘积的值位于1附近,否则,当t-k很大时(也就是误差传递很多个时刻时),整个式子的值就会变得极小(当乘积小于1)或者极大(当乘积大于1),前者就是梯度消失,后者就是梯度爆炸。虽然科学家们搞出了很多技巧(比如怎样初始化权重),让的值尽可能贴近于1,终究还是难以抵挡指数函数的威力。
梯度消失到底意味着什么?在零基础入门深度学习(5) - 循环神经网络中我们已证明,权重数组W最终的梯度是各个时刻的梯度之和,即:
假设某轮训练中,各时刻的梯度以及最终的梯度之和如下图:
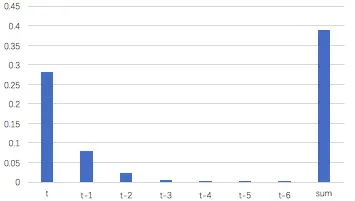
我们就可以看到,从上图的t-3时刻开始,梯度已经几乎减少到0了。那么,从这个时刻开始再往之前走,得到的梯度(几乎为零)就不会对最终的梯度值有任何贡献,这就相当于无论t-3时刻之前的网络状态h是什么,在训练中都不会对权重数组W的更新产生影响,也就是网络事实上已经忽略了t-3时刻之前的状态。这就是原始RNN无法处理长距离依赖的原因。
既然找到了问题的原因,那么我们就能解决它。从问题的定位到解决,科学家们大概花了7、8年时间。终于有一天,Hochreiter和Schmidhuber两位科学家发明出长短时记忆网络,一举解决这个问题。
其实,长短时记忆网络的思路比较简单。原始RNN的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。那么,假如我们再增加一个状态,即c,让它来保存长期的状态,那么问题不就解决了么?如下图所示:
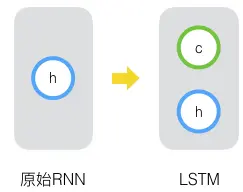
新增加的状态c,称为单元状态(cell state)。我们把上图按照时间维度展开:
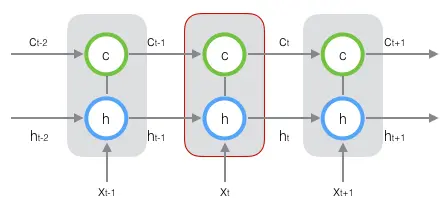
上图仅仅是一个示意图,我们可以看出,在t时刻,LSTM的输入有三个:当前时刻网络的输入值、上一时刻LSTM的输出值、以及上一时刻的单元状态;LSTM的输出有两个:当前时刻LSTM输出值、和当前时刻的单元状态。注意、、都是向量。
LSTM的关键,就是怎样控制长期状态c。在这里,LSTM的思路是使用三个控制开关。第一个开关,负责控制继续保存长期状态c;第二个开关,负责控制把即时状态输入到长期状态c;第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。三个开关的作用如下图所示:
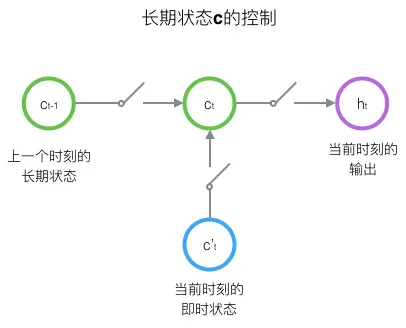
接下来,我们要描述一下,输出h和单元状态c的具体计算方法。
长短时记忆网络的前向计算
前面描述的开关是怎样在算法中实现的呢?这就用到了门(gate)的概念。门实际上就是一层全连接层,它的输入是一个向量,输出是一个0到1之间的实数向量。假设W是门的权重向量,是偏置项,那么门可以表示为:
门的使用,就是用门的输出向量按元素乘以我们需要控制的那个向量。因为门的输出是0到1之间的实数向量,那么,当门输出为0时,任何向量与之相乘都会得到0向量,这就相当于啥都不能通过;输出为1时,任何向量与之相乘都不会有任何改变,这就相当于啥都可以通过。因为(也就是sigmoid函数)的值域是(0,1),所以门的状态都是半开半闭的。
LSTM用两个门来控制单元状态c的内容,一个是遗忘门(forget gate),它决定了上一时刻的单元状态有多少保留到当前时刻;另一个是输入门(input gate),它决定了当前时刻网络的输入有多少保存到单元状态。LSTM用**输出门(output gate)**来控制单元状态有多少输出到LSTM的当前输出值。
我们先来看一下遗忘门:
式
上式中,是遗忘门的权重矩阵,表示把两个向量连接成一个更长的向量,是遗忘门的偏置项,是sigmoid函数。如果输入的维度是,隐藏层的维度是,单元状态的维度是(通常),则遗忘门的权重矩阵维度是。事实上,权重矩阵都是两个矩阵拼接而成的:一个是,它对应着输入项,其维度为;一个是,它对应着输入项,其维度为。可以写为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









