






基于 Python 的锂电池剩余寿命预测
文章目录
_合集:基于LSTM、CNN、BiGRU、TCN、Transformer、CNN-Transformer、Transformer-BiLSTM等系列预测模型,较多实验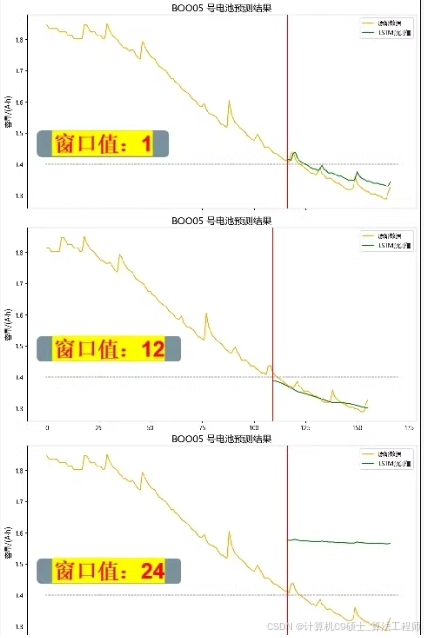
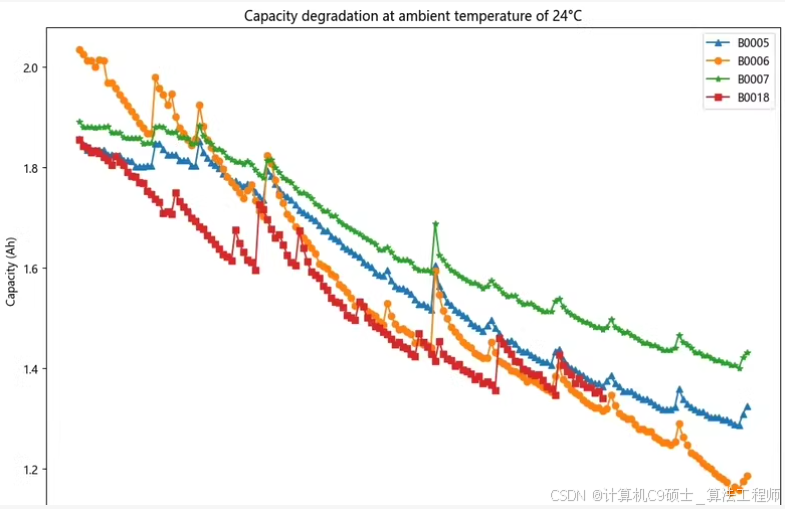
● 数据集:NASA锂离子电池寿命试验公开数据集
● 环境框架:python 3.9 pytorch 2.1 及其以上版本均可运行
● 提供实验:模型对比试验、窗口值对比实验、划分比例对比实验、电池组对比实验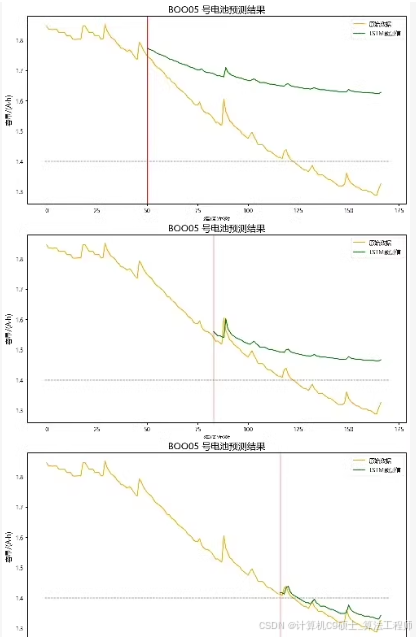
基于Python的锂电池剩余寿命预测合集,我们将使用PyTorch作为深度学习框架,并实现多种预测模型(LSTM、CNN、BiGRU、TCN、Transformer、CNN-Transformer、Transformer-BiLSTM)。该合集将涵盖数据加载、预处理、模型定义、训练、评估以及实验设置。
以下,代码及文字仅供参考
环境搭建
首先,确保你的开发环境已经安装了必要的库。你可以使用以下命令来安装所需的依赖:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
pip install pandas numpy matplotlib scikit-learn tensorboard
项目结构
创建如下项目结构:
battery_lifetime_prediction/
├── data/ # 存放NASA电池数据集
│ ├── B0005.mat # 电池B0005的数据
│ ├── B0006.mat # 电池B0006的数据
│ ├── B0007.mat # 电池B0007的数据
│ └── B0018.mat # 电池B0018的数据
├── main.py # 主程序入口
├── models/ # 不同模型的实现
│ ├── lstm.py # LSTM模型
│ ├── cnn.py # CNN模型
│ ├── bigru.py # BiGRU模型
│ ├── tcn.py # TCN模型
│ ├── transformer.py # Transformer模型
│ ├── cnn_transformer.py # CNN-Transformer模型
│ └── transformer_bilstm.py # Transformer-BiLSTM模型
├── utils/ # 辅助函数
│ ├── data_loader.py # 数据加载与预处理
│ ├── trainer.py # 训练和评估工具
│ └── metrics.py # 模型评估指标计算
└── experiments/ # 实验脚本
├── model_comparison.py # 模型对比实验
├── window_size_experiment.py # 窗口值对比实验
├── split_ratio_experiment.py # 划分比例对比实验
└── battery_group_experiment.py # 电池组对比实验
数据加载与预处理 (utils/data_loader.py)
import os
import pandas as pd
import numpy as np
import scipy.io as sio
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import Dataset, DataLoader
class BatteryDataset(Dataset):
def __init__(self, file_paths, seq_length=30):
self.seq_length = seq_length
self.scaler = MinMaxScaler()
self.data = []
for path in file_paths:
mat_data = sio.loadmat(path)
capacity = mat_data['cycle_life']['capacity'][0][0].flatten()
normalized_capacity = self.scaler.fit_transform(capacity.reshape(-1, 1)).flatten()
self.data.extend(self.create_sequences(normalized_capacity))
def create_sequences(self, capacity):
sequences = []
for i in range(len(capacity) - self.seq_length):
sequences.append((capacity[i:i+self.seq_length], capacity[i+self.seq_length]))
return sequences
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sequence, target = self.data[idx]
return torch.tensor(sequence, dtype=torch.float32), torch.tensor(target, dtype=torch.float32)
def get_dataloaders(data_dir='data', batch_size=32, seq_length=30, test_split=0.2):
file_paths = [os.path.join(data_dir, f) for f in os.listdir(data_dir) if f.endswith('.mat')]
dataset = BatteryDataset(file_paths, seq_length)
train_size = int((1 - test_split) * len(dataset))
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, len(dataset) - train_size])
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
return train_loader, test_loader
LSTM模型 (models/lstm.py)
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, input_size=1, hidden_size=200, num_layers=2, output_size=1):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x)
out = self.fc(out[:, -1, :])
return out
模型训练与评估工具 (utils/trainer.py)
import torch
from tqdm import tqdm
from .metrics import calculate_metrics
class Trainer:
def __init__(self, model, optimizer, criterion, device='cpu'):
self.model = model.to(device)
self.optimizer = optimizer
self.criterion = criterion
self.device = device
def train(self, train_loader, epoch):
self.model.train()
running_loss = 0.0
for inputs, targets in tqdm(train_loader, desc=f'Training Epoch {epoch}'):
inputs, targets = inputs.unsqueeze(-1).to(self.device), targets.to(self.device)
self.optimizer.zero_grad()
outputs = self.model(inputs)
loss = self.criterion(outputs.squeeze(), targets)
loss.backward()
self.optimizer.step()
running_loss += loss.item()
return running_loss / len(train_loader)
def evaluate(self, test_loader):
self.model.eval()
predictions, actuals = [], []
with torch.no_grad():
for inputs, targets in tqdm(test_loader, desc='Evaluating'):
inputs, targets = inputs.unsqueeze(-1).to(self.device), targets.to(self.device)
outputs = self.model(inputs)
predictions.append(outputs.cpu().numpy())
actuals.append(targets.cpu().numpy())
predictions = np.concatenate(predictions)
actuals = np.concatenate(actuals)
metrics = calculate_metrics(predictions, actuals)
return metrics
模型评估指标 (utils/metrics.py)
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
def calculate_metrics(predictions, actuals):
mse = mean_squared_error(actuals, predictions)
mae = mean_absolute_error(actuals, predictions)
r2 = r2_score(actuals, predictions)
rmse = np.sqrt(mse)
return {'MSE': mse, 'MAE': mae, 'R2': r2, 'RMSE': rmse}
模型对比实验 (experiments/model_comparison.py)
import torch
from models.lstm import LSTMModel
from models.cnn import CNNModel
from models.bigru import BiGRUModel
from models.tcn import TCNModel
from models.transformer import TransformerModel
from models.cnn_transformer import CNNTransformerModel
from models.transformer_bilstm import TransformerBiLSTMModel
from utils.trainer import Trainer
from utils.data_loader import get_dataloaders
def compare_models(models, epochs=100, lr=0.001):
results = {}
train_loader, test_loader = get_dataloaders()
for name, ModelClass in models.items():
print(f'Training {name}...')
model = ModelClass()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = nn.MSELoss()
trainer = Trainer(model, optimizer, criterion)
for epoch in range(epochs):
train_loss = trainer.train(train_loader, epoch)
print(f'Epoch [{epoch+1}/{epochs}], Loss: {train_loss:.4f}')
metrics = trainer.evaluate(test_loader)
results[name] = metrics
print(f'{name} Evaluation Metrics:', metrics)
return results
if __name__ == '__main__':
models = {
'LSTM': LSTMModel,
'CNN': CNNModel,
'BiGRU': BiGRUModel,
'TCN': TCNModel,
'Transformer': TransformerModel,
'CNN-Transformer': CNNTransformerModel,
'Transformer-BiLSTM': TransformerBiLSTMModel
}
results = compare_models(models)
print('All Models Comparison Results:', results)
其他实验脚本
另外呀,同学呢-_可以根据需要编写其他实验脚本,如窗口值对比实验、划分比例对比实验和电池组对比实验。这些实验可以调整get_dataloaders函数中的参数或在compare_models中添加不同的实验逻辑。


















 1379
1379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









