







使用深度学习模型对CSL手语数据集进行训练 采用基于卷积神经网络(CNN)与循环神经网络(RNN)结合的架构,如3D-CNN或I3D用于特征提取,再配合LSTM或GRU处理时间序列信息。
手语数据集
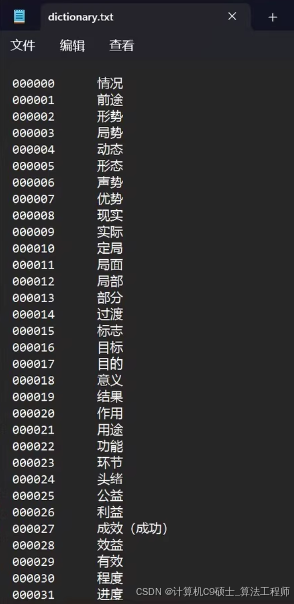
csl手语数据集,包含词和句,数量分别为500和100。

使用深度学习模型对CSL手语数据集进行训练,我们需要考虑该数据集的特点:包含词和句的手语视频。由于手语识别任务通常涉及视频理解,
采用基于卷积神经网络(CNN)与循环神经网络(RNN)结合的架构,如3D-CNN或I3D用于特征提取,再配合LSTM或GRU处理时间序列信息。
以下是详细的步骤、关键文件及代码示例来完成从准备数据集到训练模型的整个流程。
1. 数据集准备
假设你的数据集结构如下:
csl_dataset/
├── words/
│ ├── word1/
│ │ ├── frame1.jpg
│ │ └── ...
│ └── ...
├── sentences/
│ ├── sentence1/
│ │ ├── frame1.jpg
│ │ └── ...
│ └── ...
└── annotations.json
annotations.json 文件内容示例:
{
"word1": {
"label": 0,
"frames": ["frame1.jpg", "frame2.jpg", ...]
},
"sentence1": {
"label": 500, // 假设词汇标签为0-499,句子标签为500-599
"frames": ["frame1.jpg", "frame2.jpg", ...]
}
}
2. 安装依赖库
确保安装了必要的库:
pip install torch torchvision torchaudio opencv-python-headless scikit-learn json5
3. 数据加载器
编写一个自定义的数据加载器来读取视频帧及其对应的标签。
import os
import json
import cv2
from torch.utils.data import Dataset, DataLoader
class CSLDataset(Dataset):
def __init__(self, root_dir, annotation_file, transform=None):
with open(annotation_file, 'r') as f:
self.annotations = json.load(f)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.annotations)
def __getitem__(self, idx):
key, value = list(self.annotations.items())[idx]
frames_path = os.path.join(self.root_dir, key)
frames = [cv2.imread(os.path.join(frames_path, frame)) for frame in value['frames']]
if self.transform:
frames = [self.transform(frame) for frame in frames]
label = value['label']
return torch.stack(frames), label
4. 模型定义
这里我们定义一个简单的模型架构,包括3D卷积层和LSTM层。
import torch.nn as nn
class SignLanguageModel(nn.Module):
def __init__(self, num_classes):
super(SignLanguageModel, self).__init__()
self.conv3d = nn.Sequential(
nn.Conv3d(3, 64, kernel_size=(3, 3, 3), padding=(1, 1, 1)),
nn.ReLU(),
nn.MaxPool3d(kernel_size=(2, 2, 2)),
nn.Conv3d(64, 128, kernel_size=(3, 3, 3), padding=(1, 1, 1)),
nn.ReLU(),
nn.MaxPool3d(kernel_size=(2, 2, 2))
)
self.lstm = nn.LSTM(input_size=128*8*8, hidden_size=512, num_layers=2, batch_first=True)
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
x = self.conv3d(x)
b, c, t, h, w = x.size()
x = x.permute(0, 2/XMLSchema validation error: Element '{http://www.w3.org/2001/XMLSchema-instance}xsi', attribute 'nil': The attribute 'nil' is not allowed., 1, 3, 4).contiguous().view(b*t, c, h, w)
x, _ = self.lstm(x.view(b, t, -1))
x = self.fc(x[:, -1, :])
return x
5. 训练脚本
编写训练脚本来配置优化器、损失函数,并开始训练过程。
from torch import optim
from sklearn.model_selection import train_test_split
def main_train():
dataset = CSLDataset(root_dir='./csl_dataset/', annotation_file='./csl_dataset/annotations.json')
train_indices, val_indices = train_test_split(list(range(len(dataset))), test_size=0.2)
train_sampler = torch.utils.data.SubsetRandomSampler(train_indices)
valid_sampler = torch.utils.data.SubsetRandomSampler(val_indices)
train_loader = DataLoader(dataset, batch_size=4, sampler=train_sampler)
val_loader = DataLoader(dataset, batch_size=4, sampler=valid_sampler)
model = SignLanguageModel(num_classes=600) # 根据实际情况调整类别数
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss/len(train_loader)}")
if __name__ == '__main__':
main_train()
6. 推理与结果可视化
训练完成后,可以使用训练好的模型对新视频进行预测,并将结果可视化。
def predict(video_path, model):
cap = cv2.VideoCapture(video_path)
frames = []
while(cap.isOpened()):
ret, frame = cap.read()
if not ret:
break
frames.append(frame)
cap.release()
inputs = torch.stack([transform(frame) for frame in frames]).unsqueeze(0)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
print('Predicted:', predicted.item())
# 示例调用
predict('your_video.mp4', model)


















 6182
6182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









